
【硬核】秒杀活动技术方案,Redis申请32个G,被技术总监挑战了...
大家好,我是Tom哥~
作为一名技术从业人员,性能优化是每个人的必修课
就像大学时期给漂亮妹子修电脑的绝招就是“重启电脑一样”,性能优化也有自己的必杀技

你一定听过一句话:性能不够,缓存来凑!对,你没听错,就是缓存。
但是,哈哈,也不是拿来主义,张手就来。
这不,小王接到一个秒杀活动任务,设计技术方案,大量的数据扔到缓存里,想借助Redis的高吞吐量来抗住峰值压力。
这个思路也没错,这不一评估缓存内容占用的空间大小,需要30来个G。
你觉得有没有问题?
觉得没问题的同学,可以去打游戏了
我们知道Redis集群有主从模式或者哨兵模式
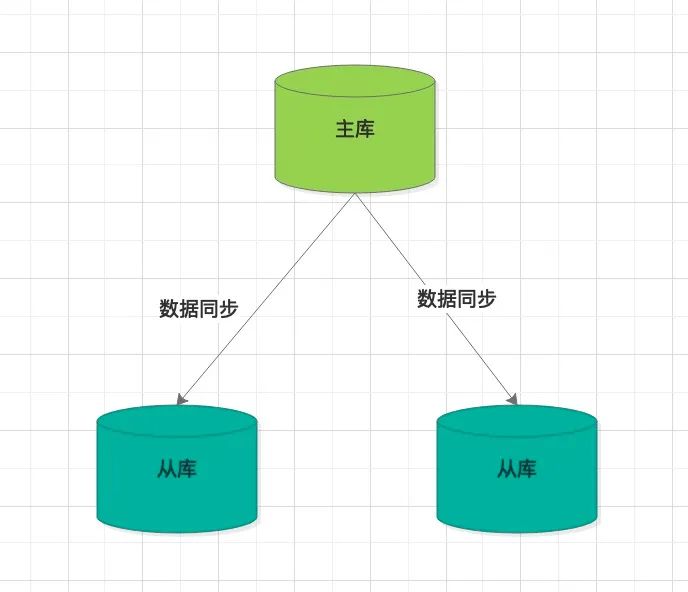
无论采用采用那种模式,从节点同步数据时,开始需要fork子进程,生成RDB文件,如果数据容量过大,那么占用的时间会很长。如果主节点再开启持久化机制,那性能就更没法保证。
为了解决这个问题,Redis 又提出了一个新的解决方案,将大数据碎片化
假如原来一个节点存了30G的数据,现在我们拆分6个实例,每个实例的数据就只有5个G,压力一下小了很多
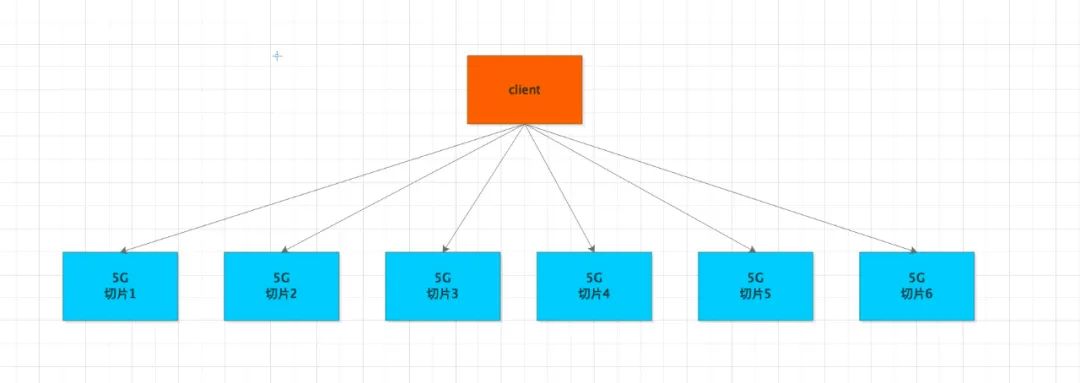
特别说明:由于key的路由规则基于特殊的负载算法,实际上并不是均等分配。
接下来,我们重点讨论的是,这个拆分方案要如何设计?
民间方案
Redis 3.0 版本之前,官方还没有提供集群方案,但是单台实例受内存限制,无法实现垂直扩展,怎么办?
一些人提出了基于客户端的分区方案。
比如:基于客户端分区的 ShardedJedis,基于代理的 Codis、Twemproxy 等,后面挂载着若干个Redis实例,不同实例间完全隔离,互不通信。通过客户端代理组成了一个逻辑上的集群。从而解决庞大的数据容量问题。
官方方案
Redis 官方在 3.0 版本 提出一个集群方案,称为 Redis Cluster。
Redis Cluster 核心设计引入一个哈希槽(Hash Slot),将整个集群切成了 16384 个哈希槽,你可以理解成一个个小的数据分区。
当我们操作Redis 时,根据传入的 key ,按照 CRC16算法计算出一个16位的二进制值,然后再对16384取模,便得到一个哈希槽编号。
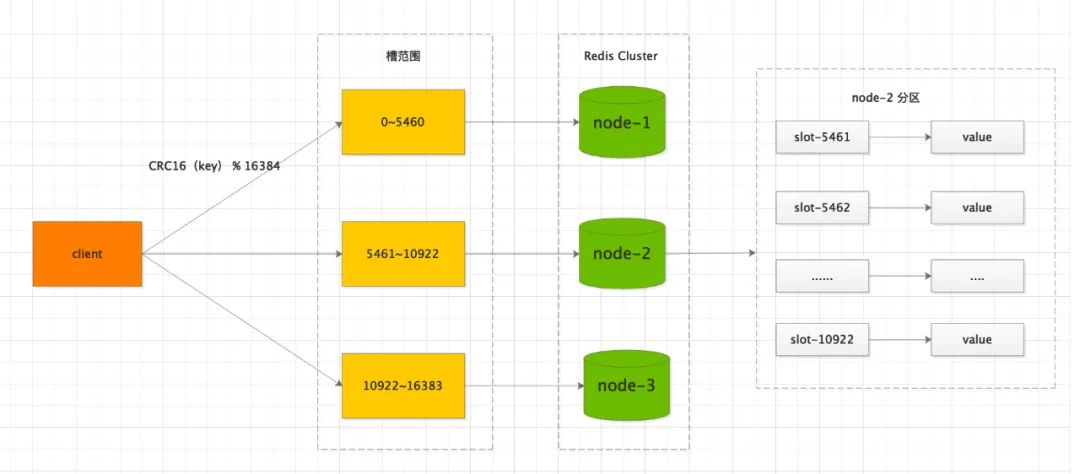
注意:如果手动分配哈希槽,一定要把16384全部分配完,否则 Redis 集群无法工作。
Redis Cluster 如何构建
分为手动搭建和自动搭建
我们先来看下纯手动如何搭建一个Redis Cluster集群。
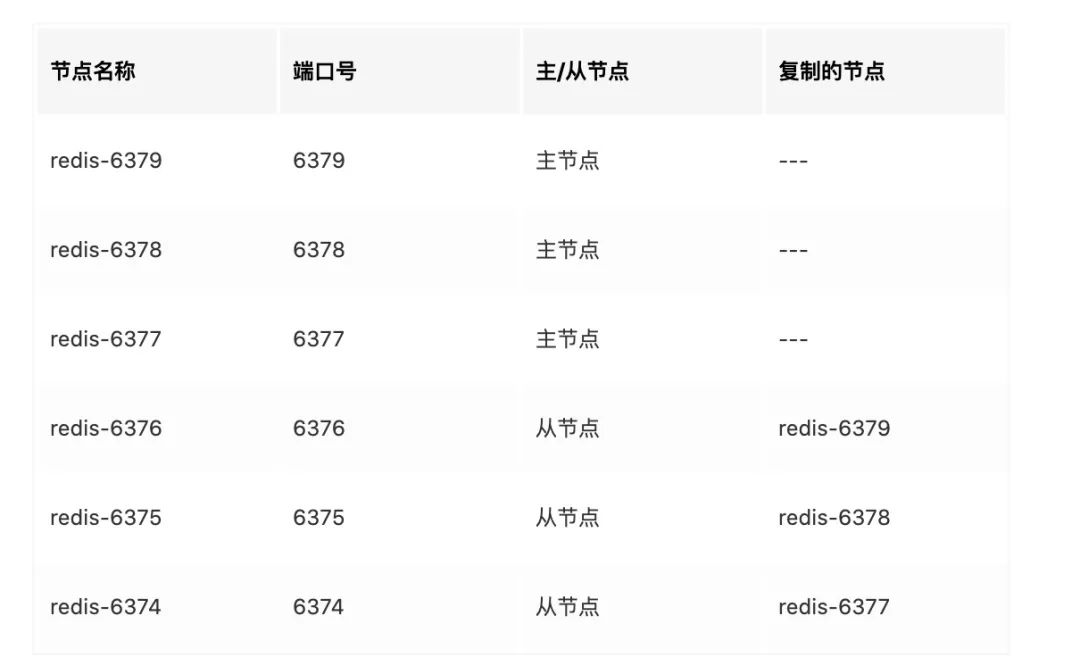
首先,准备机器,为了方便测试,我们只用一台,通过不同端口模拟出 6个Redis 实例
1、构建三个目录:conf、data、log,分别存放 配置、数据 和 日志 相关文件。
修改conf配置文件如下
# redis后台运行
daemonize yes
# 数据存放目录
dir /usr/local/redis-cluster/data/redis-6379
# 日志文件
logfile /usr/local/redis-cluster/log/redis-6379.log
# 端口号
port 6379
# 开启集群模式
cluster-enabled yes
# 集群的配置,配置文件首次启动自动生成
# 这里只需指定文件名即可,集群启动成功后会自动在data目录下创建
cluster-config-file "nodes-6379.conf"
# 请求超时,设置10秒
cluster-node-timeout 10000
2、启动节点
sudo redis-server conf/redis-6379.conf
3、集群中各个节点握手通信,组成集群,握手命令 cluster meet {ip} {port}。握手成功后该状态通过Gossip协议在集群中传播,其它节点就会自动发现新节点并发起握手,最后所有节点都彼此感知并组成集群)
127.0.0.1:6379> cluster meet 127.0.0.1 6378
127.0.0.1:6379> cluster meet 127.0.0.1 6377
127.0.0.1:6379> cluster meet 127.0.0.1 6376
127.0.0.1:6379> cluster meet 127.0.0.1 6375
127.0.0.1:6379> cluster meet 127.0.0.1 6374
4、分配哈希槽,总共有16384个槽位,每个节点实例分配了一定数量的哈希槽
redis-cli -p 6379 cluster addslots {0..5461}
redis-cli -p 6378 cluster addslots {5462..10922}
redis-cli -p 6377 cluster addslots {10922..16383}
5、三个主节点分配完槽位后,每个主节点挂载相应的从节点,用于紧急情况下故障转移。从节点负责复制主节点槽信息和业务数据
# 进入从节点客户端
redis-cli -p 6376
127.0.0.1:6376> cluster replicate 7d480c106752e0ba4be3efaf6628bd7c8c124013(6379主节点的实例ID)述:详细步骤:https://juejin.cn/post/6844904057044205582
6、执行命令 cluster slots,查看集群各个节点的槽位分布
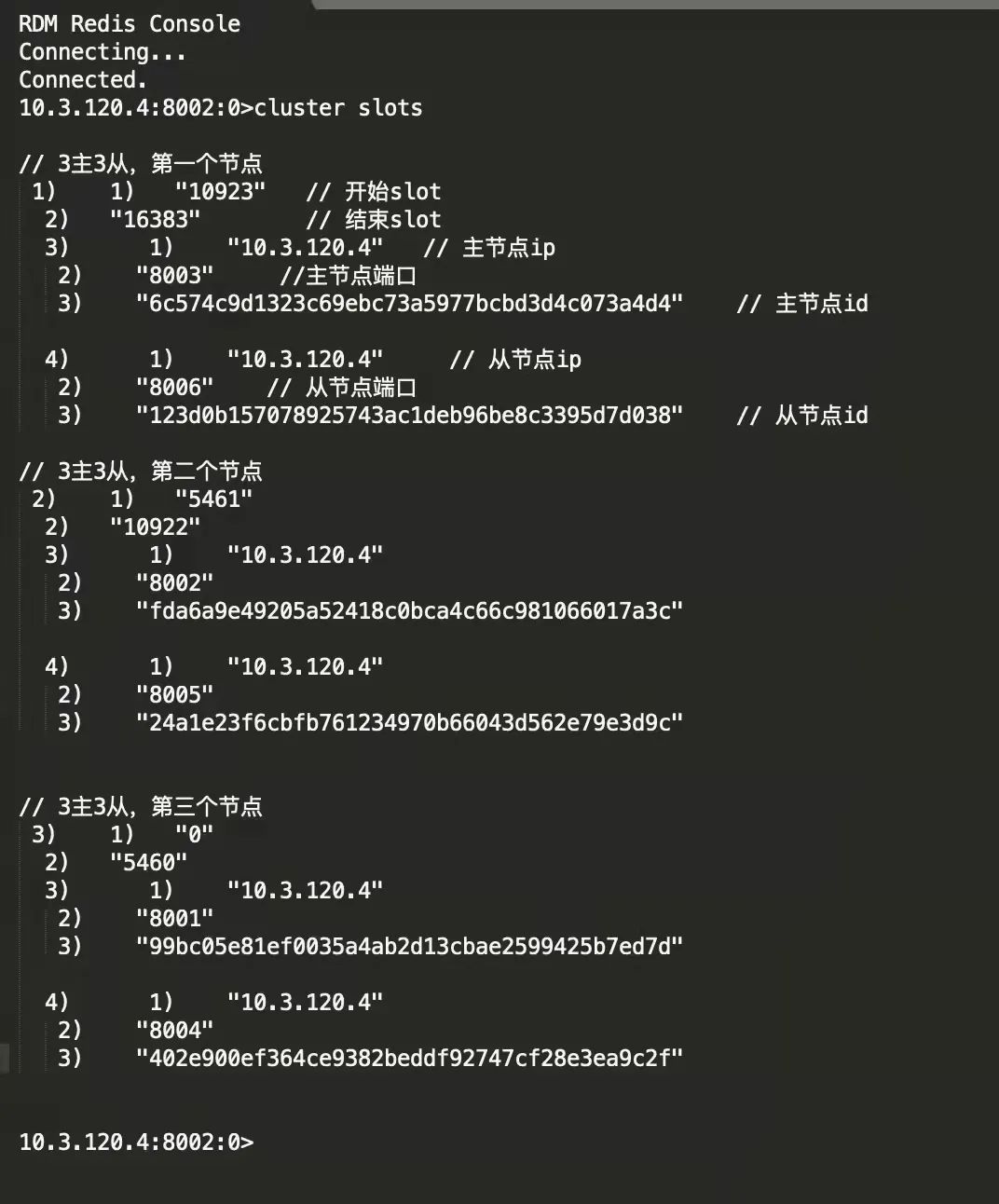
客户端如何知晓一个key归属于哪个Redis切片实例
Redis Cluster集群采用分片,虽然每个实例只有部分的槽位数据,但是整个槽位分布会彼此间同步,有点类似病毒扩散。
最后,每个实例都有了全部的slot哈希槽与实例的映射关系。
应用启动后,客户端与Redis建立关联,会从一台Redis实例拉取全部的槽位映射关系,并缓存在本地。
当接到key操作命令时,先计算key的哈希槽,然后将命令发送给对应的Redis实例,从而完成了分布式路由逻辑。
当然,也有特殊情况发生,比如集群扩容、缩容,会打乱原有的哈希槽分布

如果slot与实例的映射关系发生了变化,客户端要如何处理?
没关系,Redis 官方也想到这个问题
解决方案,就是采用重定向机制。
当客户端执行一个key命令时,如果指向的实例位置已经变化,会响应 MOVED 结果,里面带有新目标实例的地址。
此时客户端会更新本地缓存,后续对于该槽位的请求直接打到新实例上。
但是如果此时槽位的key较多,部分key还没迁移完,怎么办?
GET Tom哥:key
(error) ASK 6504 127.0.0.1:6379
客户端请求key时,会收到一条 ASK 错误信息。此时,并不会更新客户端本地缓存的哈希槽映射关系。
客户端给新的目标实例发送 ASKING 命令,然后再发送原来的get命令,这一次的命令操作会在新实例上执行,但是仅限这一次。
同一个key下次再操作时,还是路由到老的实例,直到该槽位全部迁移完成。
Redis Cluster 主节点宕机,如何是好?
只要是系统,就有宕机的风险。哨兵模式,通过单独部署哨兵集群,对整个Redis集群进行监控,具体的操作流程之前文章有介绍过。
Redis Cluster 并没有单独部署哨兵节点,而是通过master节点之间的心跳来彼此监控。
简单来说,针对A节点,某一个节点认为A宕机了,那么此时是主观下线。而如果集群内超过半数的节点认为A挂了, 那么此时A就会被标记为客观下线。
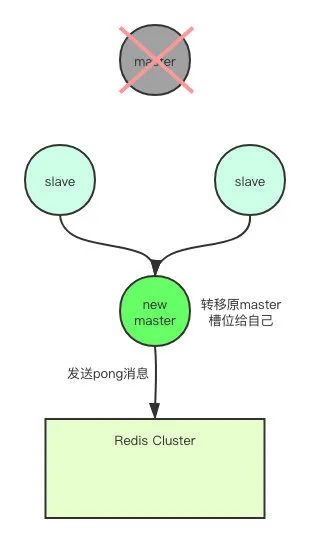
一旦节点A被标记为了客观下线,集群就会开始执行故障转移。其余正常运行的master节点会进行投票选举,从A节点的slave节点中选举出一个,将其切换成新的master对外提供服务。当某个slave获得了超过半数的master节点投票,就成功当选。
来源:https://segmentfault.com/a/1190000038528812
当选成功之后,新的master会执行slaveof no one来让自己停止复制A节点,使自己成为master。然后将A节点所负责处理的slot,全部转移给自己,然后就会向集群发PONG消息来广播自己的最新状态。
注意:Redis Cluster中的读、写请求都是在master上完成,从节点只是用于数据的容灾备份。
关于我:Tom哥,前阿里P7技术专家,出过专利,多年大厂实战经验。欢迎关注,我会持续输出更多经典原创文章,为你大厂助力。
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。