
数据仓库实践-拉链表设计
1 写在开头的话
拉链表,学名叫缓慢变化维(Slowly Changing Dimensions),简称渐变维(SCD),俗称拉链表,是为了记录关键字段的历史变化而设计出来的一种数据存储模型,常见于维度表设计,在数据仓库相关的面试中,也经常有被问到。但是在工程实践中,拉链表真是太麻烦了,而且是在模型设计、初始化、ETL 开发、运维、日常取数等各个环节都很麻烦,而麻烦的设计通常都容易出错,或者对团队成员能力要求高些。
使用拉链表,需要考虑的问题很多,我先简单列几个,大家可以先思考下,真的必须用拉链表吗?
新建的拉链表,历史数据要不要补充;
新建的拉链表,主键怎么设置,需要引入代理键吗;
构建好的拉链表,更新的时候只能逐天往后计算,中间有一天计算错误,后续的都得重刷;
运维的时候,更新的时候如果部分数据 update 错误,如何更正?
关系型数据库还好可以 update,那大数据环境下呢,如何处理增量数据?
使用的时候,什么时候取最新快照,什么时候取历史某一时刻的数据?
使用的时候,事实表关联拉链表,join 该怎么写,会不会写错?
2 先分享一篇类似的文章
漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
https://blog.csdn.net/zhaodedong/article/details/54177686
上边是木东居士在前些年分享在 CSDN 的一篇文章,目前已有 3.9 万浏览。写的非常棒,思路清晰、简单易懂,也是是网络上流传的常规拉链表设计思路。
3 对于变化数据的处理方案
我们常说,数据模型设计一定要切合实际业务需求。对于变化数据的处理,常见需求有以下三种:
需求一:保护第一个值
在广告投放的业务场景中,有个很重要的概念叫广告归因,这就是一个典型的必须保护第一个值的案例。就是说一个安装归属到渠道 1 后,就应该永远绑定在该渠道上。
该需求实现最简单,只需要追加新数据就好了。
需求二:保留最新值
当我们不需要记录历史变化的时候,就可以只保留最新值。比如用户修改了出生日期,有可能之前给的是系统默认值。
该需求处理会稍微复杂,需要 update 用户维表,同时如果有对于用户年龄相关的分析,还要重刷相关的事实表数据。
需求三:记录历史变化
我们需要回溯主体历史某一时点的状态的时候,就必须记录历史变化了。比如某一天,某业务员转岗了,那么部门业绩月度汇总的时候,就需要知道该业务员过去在哪些部门待过以及起始日期。
需求三处理起来比较麻烦,方案如下:
方案一:每天记录一份快照,快照在木东居士文章里称为切片。
方案二:增加新的列,比如只需要存最近 3 次变化,那么我们新增三列就好了。
方案三:增加新的行,核心属性变化一次,新增一条,同时新增 2 列(数据开始日期、数据截止日期)。
方案一:
好处是写入和查询特别方便。但如果数据量巨大,数仓场景,您至少得存三年吧,由此带来存储、计算成本,都将是非常巨大的。
互联网时代的快餐模式,大家都没时间建模了,同时主流大数据数仓组件基本不支持 Update ,或者目前的存储还吃的消,又或者数据量没那么大,因此该方案被采用的还是比多的。
方案二:
对于某些特定的使用场景,该方案还是蛮香的。再次强调,数据开发者一定要懂业务,许多技术上实现非常复杂的,换一种业务角度会简单太多了,
方案三:
这是多数人都能想到的处理思路,即拉链表。适用场景必须是缓慢变化,例如一张表有 10 亿数据,每天变化的只有几万、几十万才能称为缓慢变化,反之如果 10 亿的表每天有 7 亿都会发生变化,那这还适合用拉链表吗?
拉链表的优点是,相对于快照表可以极大的节省存储空间,缺点也很明显就是太麻烦了。
4 实现方法
大数据数仓不支持 Update ,因此跟传统数仓实现还是有区别的。(当然这是个伪命题,因为 ODPS 从 2021 年 3 月份已经开始支持 Update,虽然是试用阶段但未来可期。)
另外,有些需求,纯 SQL 实现确实很难。大家不要太迷恋 SQL,时代不同了,拉链表的计算,有时候写 MR 反而更容易理解。有时候多写几个 UDF、UDAF、UDTF,SQL 写起来反而更方便、执行效率反而会更好。
4.1 数据模型设计-传统数仓设计方案
因为数量不大,通常也就几万几十万的数据量,业务系统和数仓 ODS 层也不太需要启用数据删除策略。因此不用考虑分区设计。
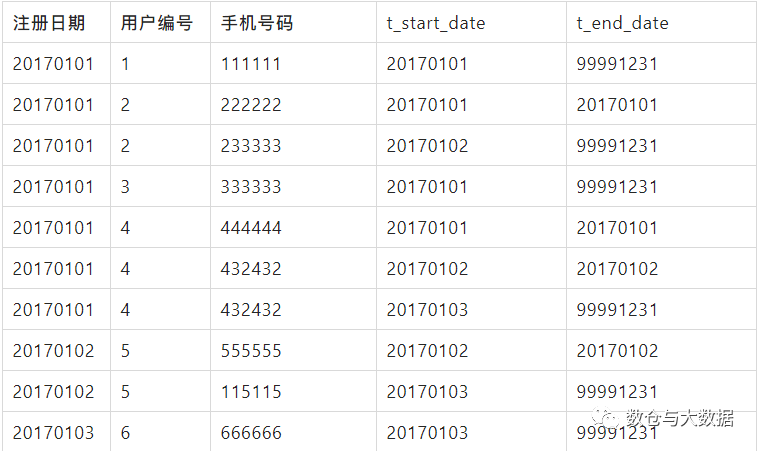
4.2 数据模型设计-大数据数仓设计方案
网络上分享出来的文章,还是沿用关系型数据的模型设计思路。所有数据都放一个分区或者干脆不建分区,往往会带来一系列问题。比如:
随着存储时间的拉长,这张表势必会越来越大,查询效率会越来越底,然而大部分查询场景只需要查询快照或者最近一段时间的历史变化。
如果某次更新,由于误操作造成拉链表数据错误,已经存放五年历史变化的拉链表该怎么恢复?存储备份肯定是不可能的,如果我们每次都将全量数据写入新的分区,至少得存近三天的全量拉链表数据吧?这又会带来存储空间的消耗。
例如,
有这么一个场景,需要存储 SDK 上报的手机硬件信息,主键是设备 ID,关键的设备属性大概 30 个,设备数量 40 亿,在只存储一份快照的情况下,需占用 400 G 存储空间,一开始用的是快照表方式,考虑存储开销我们只存最近 7 天快照,带来的问题是设备历史变化的 imei 、mac、os、品牌、机型等重要属性都会丢失。所以,最好的方案应该是使用拉链表。由于数据已经累积了三四年,使用拉链表数据的话,数据条数会从 40 亿膨胀到 60 亿,需占 600 G 存储空间。
==========设计思路、更新办法=======================
分区列:
day comment '生成日期。如果 is_latest_row=0,则 day=t_end_date。如果 is_latest_row=1,则day='99991231'。如果day=t_start_date,则说明该用户是今日新增的。'
is_latest_row comment '是否最新一条数据。1是0否。如果标记为 0 说明该条数据不会再被更新'
20170101 这一天的数据
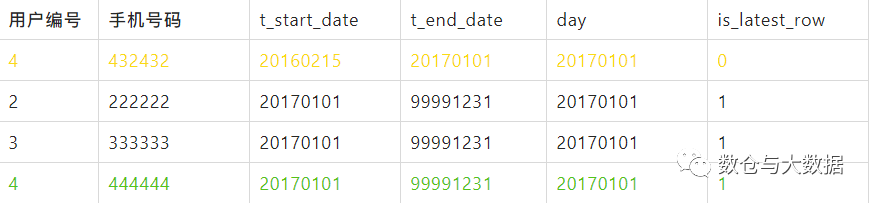
相比于前一天,用户2、3没变化,用户4更新了手机号。
用户2、用户3没变化,直接从前一天的分区里移过来放到当天的 is_latest_row='1' 分区下。
用户4 修改了手机号码,更新库里已有的那条数据 t_end_date='20170101',然后放入当天的 is_latest_row='0' 分区下,说明该条数据因为失效被归档了。新增的那条用户4 数据 t_start_date='20170101' ,t_end_date='99991231',放入当天的 is_latest_row='1' 分区下。
20170102 这一天生成的数据
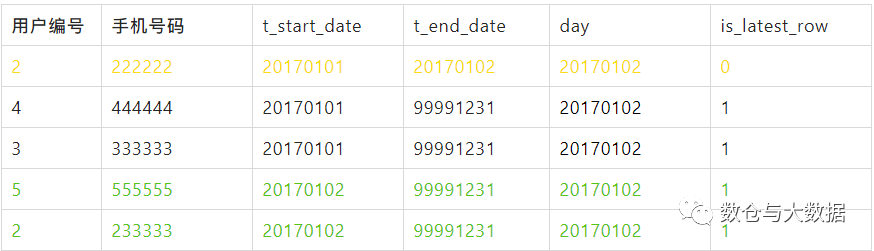
用户5是新增的,该条数据的失效日期是永久,所以 is_latest_row = '1'。 相比于前一天,新增了用户5,同时更新了用户2的手机号码,用户3、4无变化。
用户3、4没变化,直接从前一天的分区里移过来放到当天的 is_latest_row='1' 分区下。
用户2 修改了手机号码,更新库里已有的那条数据 t_end_date='20170102',然后放入当天的 is_latest_row='0' 分区下,说明该条数据因为失效被归档了。新增的那条用户2 数据 t_start_date='20170102' ,t_end_date='99991231',放入当天的 is_latest_row='1' 分区下。
==========使用方法=========
假如数据已经更新到了 20170102 这一天。
is_latest_row = '0' 的分区绝对不允许删除,保证历史变化都能记录下来。
is_latest_row = '1' 的分区只保留最近 7 天或最近 3 天的数据,节省存储空间的同时,就是某一天更新错误也能很快的修正数据。
可以查最新快照:
select * from dim_user_history where day='20170102' and is_latest_row='1' ;
可以查历史任意一天[20161002]的快照:
select t.*
from
(
select t.*
,row_number() over (partition by user_id order by t_end_date) rn
from dim_user_history
where (day>='20161002' and is_latest_row='0') or (day='20170102' and is_latest_row='1')
) t
where t.rn=1
;
可以查指定时间范围内的[20161002-20161101]的所有状态:
select t.*
from dim_user_history
where (day<'20161101' and is_latest_row='0' and t_start_date>'20161002')
or (day='20170102' and is_latest_row='1' and t_start_date>'20161002')
;
拉链表虽然能解决很多问题,但是,只要一个日期卡错,就会出问题。使用起来真的太太太难了。。。。
4.3 历史数据初始化
上边,我们了解到,拉链表的使用有多麻烦。这一节我们接着讨论下写入。
如果我们构建拉链表的时候,历史数据已经沉淀一段时间了,那么大概率我们是需要全量加工处理,并一次性写入进来的。当然,我们可以从第一天开始、一天一天的往后计算。
但是,总觉得吧,这不是我们技术该干的事儿,因为这也太 lower 了吧。一天一天算,那得等多久啊,技术不能提高效率,要技术干嘛?
这个时候 SQL Boy 该上场了。有啥事情是一条 SQL 搞不定的呢?如果有,那就两条吧。哈哈哈。。。
接下来先说一下思路吧:
增量更新相对简单些,我们直接拿上一次统计周期的全量快照,关联本次统计周期的变化量即可。
历史数据初始化,由于存在某一个业务主键对应的属性可能会变化多次的情况,处理起来就会复杂很多:
相邻两个统计周期的数据如果没有变化,需要去重。
剩下的数据,需要按时间正序排列,第一条的数据止期=第二条的数据起期、第二条的数据止期=第三条的数据起期,以此类推。
而 SQL 对于行间数据的处理常常无能为力,那我们能否把行间数据计算转化成行内数据计算呢?
结合以上分析,实现步骤如下(以统计周期为天来举例):
原始数据表。
user_id | user_name | other_column | update_date | update_time |
1 | aaa | 11 | 20210101 | 2021/1/1 12:00 |
1 | bbb | 22 | 20210101 | 2021/1/1 15:00 |
1 | aaa | 33 | 20210102 | 2021/1/2 12:00 |
1 | aaa | 44 | 20210103 | 2021/1/3 12:00 |
1 | aaa | 55 | 20210104 | 2021/1/4 12:00 |
1 | bbb | 66 | 20210105 | 2021/1/5 12:00 |
1 | bbb | 77 | 20210106 | 2021/1/6 12:00 |
1 | bbb | 88 | 20210107 | 2021/1/7 12:00 |
按更新时间,每天只保留最后一条数据,数据起期为当天,止期为无限大。
create table dws.user_his_mid_01 as
select user_id,user_name,update_day b_date,'99990101' e_date
,row_number() over (partition by user_id order by update_day ) rn
from
(
select update_day,user_id,user_name
,row_number() over (partition by update_day,user_id order by update_time desc ) rn
from ods.user
) t
where rn=1
;
前两条数据会只留下一条
user_id | user_name | b_date | e_date | rn |
1 | bbb | 20210101 | 99990101 | 1 |
1 | aaa | 20210102 | 99990101 | 2 |
1 | aaa | 20210103 | 99990101 | 3 |
1 | aaa | 20210104 | 99990101 | 4 |
1 | bbb | 20210105 | 99990101 | 5 |
1 | bbb | 20210106 | 99990101 | 6 |
1 | bbb | 20210107 | 99990101 | 7 |
修正数据起止期。
create table dws.user_his_mid_02 as
select t1.user_id,t1.user_name
,t1.b_date
,nvl(t2.b_date,t1.e_date) e_date
from dws.user_his_mid_01 t1
left join dws.user_his_mid t2 on t1.user_id=t2.user_id and t1.rn=t2.rn-1
;

user_id | user_name | b_date | e_date |
1 | bbb | 20210101 | 20210102 |
1 | aaa | 20210102 | 20210103 |
1 | aaa | 20210103 | 20210104 |
1 | aaa | 20210104 | 20210105 |
1 | bbb | 20210105 | 20210106 |
1 | bbb | 20210106 | 20210107 |
1 | bbb | 20210107 | 99990101 |
相邻两条数据,属性无变化的去重。
上表数据,会合并为三条。
user_id | user_name | b_date | e_date |
1 | bbb | 20210101 | 20210102 |
1 | aaa | 20210102 | 20210105 |
1 | bbb | 20210105 | 99990101 |
好吧。历史数据初始化,当时是有写过 SQL 的,好多年过去实在想不起来,当时的 SQL 也找不到了。
本想重现当时的 SQL,不过写到第三条实在写不动了,因为太难了。
换做现在的我,其实更愿意写 MR 或者 UDAF 去实现这一业务逻辑的。思路特简单,就是将相同业务主键的数据放到一个 Reduce 里,按 update_time 排序后,循环遍历,返回结果。
4.4 增量更新
木东居士这条 SQL 写的非常简介、实用,借过来给大家看看。
ods.user_update 表应该存的是前一天的变化量(新增 + Update)。
这是关系型数据库的写法,具体到大数据场景,大家还得参照上文,加上分区列,直接 overwrite 总感觉心里不踏实。
INSERT OVERWRITE TABLE dws.user_his
SELECT * FROM
(
SELECT A.user_num,
A.mobile,
A.reg_date,
A.t_start_time,
CASE
WHEN A.t_end_time = '9999-12-31' AND B.user_num IS NOT NULL THEN '2017-01-01'
ELSE A.t_end_time
END AS t_end_time
FROM dws.user_his AS A
LEFT JOIN ods.user_update AS B
ON A.user_num = B.user_num
UNION
SELECT C.user_num,
C.mobile,
C.reg_date,
'2017-01-02' AS t_start_time,
'9999-12-31' AS t_end_time
FROM ods.user_update AS C
) AS T
;
下边是我之前写的,每月计算 IP 地址经纬度历史变化的拉链表。
牵涉到部分计算逻辑,会稍微有点复杂,大家看核心代码段即可。
第一条 SQL 是,这个月的变化量,关联上个月的全量快照,更新这个月变化量的起止日期,暂时放到这个月的全量快照分区里(类似上边 SQL 的 ods.user_update 作用)。
第二条 SQL 是,上个月的全量快照,关联这个月的变化量,得到这个月的全量快照+这个月失效的数据(数据止期='$1')。
奥,看了好久,下边 SQL 的数据止期有问题。因为当时的需求跟拉链表的不太一样。数据止期用的不是一个无限大的日期,而是(数据止期='$1') 。意味着,如果某ip只在其中一个月份出现过,那么起止日期都是一样的,如果连续出现过2个月,数据起期是第一月,数据止期是第二月。
insert OVERWRITE table bds_ip_info partition(month='$1',is_latest_row='1')
select a.ip,
if(size(split(lgt_list,';'))=1,split(lgt_list,';')[0],if(size(split(lgt_list,';'))=2,(split(lgt_list,';')[0]+split(lgt_list,';')[1])/2,b.lgt_center)) lgt_center,
if(size(split(ltt_list,';'))=1,split(ltt_list,';')[0],if(size(split(ltt_list,';'))=2,(split(ltt_list,';')[0]+split(ltt_list,';')[1])/2,b.ltt_center)) ltt_center,
if(size(split(lgt_list,';'))=1,0,if(size(split(lgt_list,';'))=2,lipb_GetDistance(concat(split(lgt_list,';')[0],',',split(ltt_list,';')[0]),concat(split(lgt_list,';')[1],',',split(ltt_list,';')[1]))/2,b.radius)) radius,
a.b_month,
a.e_month,
size(split(a.geo_list,',')) geo_num,
a.geo_list,
month_from_list
from
(
select t1.ip
,if(t2.ip is null,substring(t1.month,1,6),t2.b_month) b_month
,substring(t1.month,1,6) e_month
,if(t2.ip is null,t1.month,concat(t1.month,';',t2.month_from_list)) month_from_list
,if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500')) geo_list
,split(SplitGeoList(if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500'))),',')[0] ltt_list
,split(SplitGeoList(if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500'))),',')[1] lgt_list
from ods_ip_info_m t1
left join
(
select *
from bds_ip_info t2
where month=to_char(dateadd(dateadd(dateadd(to_date('$1','yyyymmdd'),1,'dd'),-1,'mm'),-1,'dd'),'yyyymmdd')
and is_latest_row='1'
) t2
on t1.ip=t2.ip
and abs(t1.radius-t2.radius)<=200
and lipb_GetDistance(concat(t1.lgt_center,',',t1.ltt_center),concat(t2.lgt_center,',',t2.ltt_center))<=400
where t1.month='$1'
) a lateral view MapMedianRadius(ltt_list,lgt_list,';') b as ltt_center,lgt_center,radius
;
insert overwrite table bds_ip_info partition(month,is_latest_row)
select a.ip,
a.lgt_center,
a.ltt_center,
a.radius,
a.b_month,
a.e_month,
a.geo_num,
a.geo_list,
a.month_from_list,
'$1' month,
if(b.ip is null,'1',if(a.e_month<>b.e_month,'0','1')) is_latest_row
from
(
select * from bds_ip_info t1
where month=to_char(dateadd(dateadd(dateadd(to_date('$1','yyyymmdd'),1,'dd'),-1,'mm'),-1,'dd'),'yyyymmdd')
and is_latest_row='1'
) a
left join
(
select t1.ip,e_month from bds_ip_info t1 where t1.month='$1' and is_latest_row='1'
) b on a.ip=b.ip
union all
select * from bds_ip_info t1 where t1.month='$1' and is_latest_row='1'
;
5 典型案例
拉链表概念来源于数仓,数仓的面试也经常会被问到。拉链表也切实解决了数仓四大特性之一的反应历史变化这一诉求。
但是,拉链表在数仓之外是否还有用武之地呢?事实上,数仓体系内的各种方法论、规范、核心技术等,在整个数据开发流程内始终有着巨大的指导借鉴意义。
数仓人不应局限于数仓,可以跳出数仓来看问题。我是数仓人,但我一定要建数仓吗?我们更应该思考的是如何让组织内的数据能够相对低成本、高效率的使用起来,发挥更大的价值,我们构建的是组织内的一整套数据流转体系。
案例一:记录设备库核心属性的历史变更
上边提到过,我们有一个设备库,需要记录核心属性的历史变更。记录历史变更有什么用呢?比如识别假冒设备,一部手机,imei、mac地址经常变化,很可能它不是一个真实的设备。
由于设备库非常大,4.2 大数据数仓设计方案 是更好的选择。
案例二:记录商品成本价格的变化
我们有销售订单,订单里只有销售价格,我们想要计算毛利润,就必须要有对应商品的成本价格,而商品的成本价,是随着每一次进货入库实时变更的(当时用到一个移动加权平均算法),比如该笔订单是昨天下午2点整完成的,那么我必须拿到该商品昨天下午2点整的时点值价格。
该场景,我们的数据起止日期(t_start_date、t_end_date)就不适用了,因为理论上,商品价格一天可能会变更多次,必须改成数据起止时间(t_start_time、t_end_time),由此带来的数据处理逻辑的变化,上边 4.4 增量更新的处理逻辑就不适用了,必须改用 4.3 历史数据初始化方式了。
商品成本价格维表,数据量大概也就几万条数据吧,可以采用 4.1 传统数仓设计方案存储。当然也可以使用两张表,热表存放近一个月或近7天的成本价格数据,其它的都归档到冷表。
案例三:拉链表确实能解决你的问题,但是有没有别的方案呢?

上边是一位网友的问题,很快彭总的群里也有人问到了拉链表的设计,风大佬还在发言了,这让我回忆起曾经跟拉链表的各种纠葛,联想到网上这类文章太过零碎,就想尝试着写一下。但,写文章真的太难啦,就这简单的一个拉链表,从早八点写到凌晨两点。。。
言归正传,简单几句闲聊,隐约感觉到,这个需求根本不需要采用拉链表的。但本着实时求实的态度,了解详情后,给他了他更好的解决方案。经得本人同意,脱敏后,特分享给大家。
业务上有一张贷款详情表,记录了大概七八个属性状态,每一次业务事件会导致状态发生变化,其实吧数仓也可以自己算的,但太麻烦还容易造成数据不一致,所以还是每日从业务库取时点值。业务库是主从结构,其中一个从库,当天的数据同步结束后会自动断开跟主库的连接,零点以后的状态变更会等待 ETL 抽数完成后重新开启。
业务库贷款详情表属性状态没有更新时间这个时间戳,业务系统也不愿意加字段,说是该表数据量太大,加这个字段可能会影响业务。这么大一顶帽子扣过来,咱也拿他没办法,只能每天全量抽。
但是吧,数据抽取,每天都是全量抽,后续 ETL 处理不能也也这么干呀。比如每天存一份全量快照,后续直接从快照出结果,有时候还要拿最近好多天的快照去跟别的表关联。好长一段时间的快照都得存着,因为独此一份啊,删了数据就丢了。由此带来了大量的存储、计算资源的开销,并且随着该表的持续膨胀,里边数据也没有清退机制,快照会越滚越大,而且还清贷款的数据,所有属性状态是不会再变动的。
以上是网友的困惑,为了提高计算效率,降低存储成本,他想要使用拉链表,记录历史变化。
说实话,拉链表确实能解决他的问题,但引进董卓消灭了外戚,万一袁绍降不住大魔头咋办?
下面是不用拉链表的问题解决思路。以截图开始,就让我们以截图结束吧。
 我们点开一个文件夹后:
我们点开一个文件夹后:
Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。