
刨根问底,看我如何处理 Too many open files 错误!
如果你的项目中支持高并发,或者是测试过比较多的并发连接。那么相信你一定遇到过“Too many open files”这个错误。
这个错误的出现其实是正常的,因为每打开一个文件(包括socket),都需要消耗一定的内存资源。为了避免个别进程不受控制地打开了过多的文件而让整个服务器崩溃,Linux 对打开的文件描述符数量有限制。
但是解决这个错误“奇葩”的地方在于,竟然需要修改三个参数:fs.nr_open、nofile(其实 nofile 还分 soft 和 hard) 和 fs.file-max。这几个参数里有的是进程级的、有的是系统级的、有的是用户进程级的,说一遍都觉得好乱。而且另外这几个参数还有依赖关系,着实比较复杂。
不知道你,反正飞哥我是根本记不住哪个是哪个。每次遇到这种问题,还是都得再继续 Google 一遍。但由于复杂性,所以其实网上的很多帖子里也都并没有真正搞清楚。如果照搜索出来的文章改,稍有不慎就会踩雷,把机器搞出问题。
我在测试最大TCP连接数的时候就踩过两次坑。
第一次是当时开了二十个子进程,每个子进程开启了五万个并发连接兴高采烈准备测试百万并发。结果倒霉催地忘了改 file-max 了。实验刚开始没多大一会儿就开始报错“Too many open files”。但问题是这个时候更悲催的是发现所有的命令包括 ps、kill也同时无法使用了。因为它们也都需要打开文件才能工作。后来没办法,重启系统解决的。
另外一次是重启机器完了之后发现无法 ssh 登录了。后来找运维工程部的同学报障以后才算是修复。最终发现是因为 hard nofile 比 fs.nr_open 高了,直接导致无法登陆。(其实我把 fs.nr_open 加大过,但是用的是 echo 命令 修改的。系统一重启,还原了)。
一、找到源代码
对于这三个家伙,我真的是无法言语更多了。所以我下定了决心,一定要把它们彻底搞清楚。怎么搞?那没有比把它的源码扒出来能看的更准确了。我们就拿创建 socket 来举例,首先找到 socket 系统调用的入口
//file: net/socket.c
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
if (retval < 0)
goto out_release;
}
我们看到 socket 调用 sock_map_fd 来创建相关内核对象。接着我们再进入 sock_map_fd 瞧瞧。
//file: net/socket.c
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
//在这里会判断打开文件数是否超过 soft nofile 和 fs.nr_open
//获取 fd 句柄号
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0))
return fd;
//在这里会判断打开文件数是否超过 fs.file-max
//创建 sock_alloc_file对象
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
为什么创建一个socket又要申请 fd,又要申请 sock_alloc_file 呢?我们看一个进程打开文件时的内核数据结构图就明白了
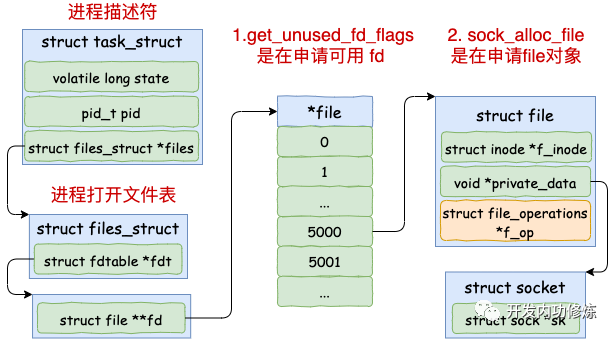
结合上图,就能轻松理解这两个函数的作用
get_unused_fd_flags:申请 fd,这只是一个在找一个可用的数组下标而已 sock_alloc_file:申请真正的 file 内核对象
二、找到进程级限制 nofile 和 fs.nr_open
接下来,我们再回到最大文件数量的判断上。这里我直接把结论抛出来。get_unused_fd_flags 中判断了 nofile、和 fs.nr_open。如果超过了这两个参数,就会报错。请看!
//file: fs/file.c
int get_unused_fd_flags(unsigned flags)
{
// RLIMIT_NOFILE 是 limits.conf 中配置的 nofile
return __alloc_fd(
current->files,
0,
rlimit(RLIMIT_NOFILE),
flags
);
}
在get_unused_fd_flags 中,调用了 rlimit(RLIMIT_NOFILE)。这个是读取的 limits.conf 中配置的 soft nofile,代码如下:
//file: include/linux/sched.h
static inline unsigned long task_rlimit(const struct task_struct *tsk,
unsigned int limit)
{
return ACCESS_ONCE(tsk->signal->rlim[limit].rlim_cur);
}
通过当前进程描述访问到 rlim[RLIMIT_NOFILE],这个对象的 rlim_cur 是 soft nofile(rlim_max 对应 hard nofile )。
紧接着让我们进入 __alloc_fd() 中来
//file: include/uapi/asm-generic/errno-base.h
#define EMFILE 24 /* Too many open files */
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
...
error = -EMFILE;
//看要分配的文件号是否超过 end(limits.conf 中的 nofile)
if (fd >= end)
goto out;
error = expand_files(files, fd);
if (error < 0)
goto out;
...
}
在__alloc_fd() 中会判断要分配的句柄号是不是超过了 limits.conf 中 nofile 的限制。fd 是当前进程相关的,是一个从 0 开始的整数。如果超限,就报错 EMFILE (Too many open files)。
这里注意个小细节,那就是进程里的 fd 是一个从 0 开始的整数。只要确保分配出去的 fd 编号不超过 limits.conf 中 nofile,就能保证该进程打开的文件总数不会超过这个数。
接着我们看到调用又会进入 expand_files:
static int expand_files(struct files_struct *files, int nr)
{
//2. 判断打开文件数是否超过 fs.nr_open
if (nr >= sysctl_nr_open)
return -EMFILE;
}
在 expand_files 我们看到,又到 nr (就是 fd 编号) 和 fs.nr_open 相比较了。超过这个限制,返回错误 EMFILE (Too many open files)。
由上可见,无论是和 fs.nr_open,还是和 soft nofile 比较,都用的是当前进程的文件描述符序号在比较的,所以这两个参数都是进程级别的。
有意思的是和这两个参数的比较几乎是前后脚进行的,所以它两的作用也基本一样。Linux之所以分两个参数来控制,那是因为 fs.nr_open 是系统全局的,而 nofile 则可以分用户来分别控制。
所以,现在我们可以得出第一个结论。
结论1:soft nofile 和 fs.nr_open的作用一样,它两都是限制的单个进程的最大文件数量。区别是 soft nofile 可以按用户来配置,而 fs.nr_open 所有用户只能配一个。
三、找到系统级限制 fs.nr_open
我们在回过头来看 sock_map_fd 中调用的另外一个函数 sock_alloc_file,在这个函数里我们发现它会和 fs.file-max 这个系统参数来比较。用啥比的呢?
//file: fs/file_table.c
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
{
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
&socket_file_ops);
}
struct file *alloc_file(struct path *path, fmode_t mode,
const struct file_operations *fop)
{
file = get_empty_filp();
...
}
struct file *get_empty_filp(void)
{
//files_stat.max_files就是 fs.file-max参数
if (get_nr_files() >= files_stat.max_files
&& !capable(CAP_SYS_ADMIN) //注意这里root账号并不受限制
) {
}
}
可见是用 get_nr_files() 来和 fs.file-max来比较的。根据该函数的注释我们能看到它是当前系统打开的文件描述符总量。如下:
/*
* Return the total number of open files in the system
*/
static long get_nr_files(void)
{
...
另外注意下 !capable(CAP_SYS_ADMIN) 这行。看完这句,我才恍然大悟,原来 file-max 这个参数只限制非 root 用户。开篇中我提到的文件打开过多时无法使用 ps,kill 等命令,是因为我用的非 root 账号操作的。哎,下次再遇到这种文件直接用 root 去 kill 就行了。之前竟然丢脸地采用了重启机器大法。。
所以现在我们可以得出另一个结论了。
结论2:fs.file-max: 整个系统上可打开的最大文件数,但不限制 root 用户
总结一下
我们总结一下,其实在 Linux 上能打开多少个文件,限制有两种:
第一种,进程级别的,限制的是单个进程上可打开的文件数。具体参数是 soft nofile 和 fs.nr_open。它们两个的区别是 soft nofile 可以不同用户配置不同的值。而 fs.nr_open 在一台 Linux 上只能配一次。
第二种,系统级别的,整个系统上可打开的最大文件数,具体参数是fs.file-max。但是这个参数不限制 root 用户。
另外这几个参数之间还有耦合关系,因此还要注意以下三点:
1、如果你想加大 soft nofile, 那么 hard nofile 也需要一起调整。因为如果 hard nofile 设置的低, 你的 soft nofile 设置的再高都没用,实际生效的值会按二者里最低的来。
2、如果你加大了 hard nofile,那么 fs.nr_open 也都需要跟着一起调整。如果不小心把 hard nofile 设置的比 fs.nr_open 大了,后果比较严重。会导致该用户无法登陆。如果设置的是 * 的话,那么所有的用户都无法登陆。
3、还要注意如果你加大了 fs.nr_open,但是用的是 echo "xx" > ../fs/nr_open 的方式,刚改完你可能觉得没问题。只要机器一重启你的 fs.nr_open 设置就会失效,还是会无法登陆。
假如你想让你的进程可以打开 100 万个文件描述符,我觉得比较稳妥点的修改方法是干脆都直接用 conf 文件的方式来改。这样比较统一,也比较安全。
# vi /etc/sysctl.conf
fs.nr_open=1100000 //要比 hard nofile 大一点
fs.file-max=1100000 //多留点buffer
# sysctl -p
# vi /etc/security/limits.conf
* soft nofile 1000000
* hard nofile 1000000
通过这种方式修改,你就可以绕过飞哥踩过的坑了。