
百度打造全新存储引擎,用持久内存搭配SPDK功效爆表
导语
为了应对信息技术高速发展对存储系统提出的新挑战,百度在英特尔的支持下打造了新一代用户态单机存储引擎。该引擎借助傲腾™持久内存以更优成本实现了更大容量以及与DRAM相似的性能,并通过PMDK和SPDK分别在缓存层和后端实施时延优化和资源整合,从而大幅升级存储服务。
百度用户态单机存储引擎是一款创新的应用于存算分离架构的存储系统,可以为百度的在线和离线产品提供稳定、高效的存储服务;通过与英特尔的紧密合作,引入英特尔®傲腾™持久内存、存储性能开发套件(SPDK),软硬协同,大幅提升单机引擎的性能。
——百度基础架构部主任架构师王雁鹏
当今信息技术高速发展,人工智能、云计算、大数据等应用场景对数据存储提出了新的要求;高爆发性增长,实时读写,随机访问超大规模数据集成为如今数据存储的普遍特征,研发一款性能高效、稳定安全、扩展能力强的数据存储系统成为推动业务增长与创新的关键。
在此背景下,百度与英特尔深度合作,通过搭载大容量、低延迟的英特尔®傲腾™持久 内存,推出全新一代用户态单机存储引擎,为百度离线与部分在线业务提供高效稳定、低延迟、低成本、可扩展的存储服务,竭力挖掘数据价值。
挑战:传统数据引擎遭遇瓶颈
随着百度业务产品的不断丰富与发展,在线与离线产品对存储系统的性能、可靠性、运维成本、扩展性都提出新的要求。
性能提升遭遇瓶颈
最近几年存储介质得到了快速发展,单位存储介质的性能越来越高,原来HDD机械硬盘读写速度不足100 IOPS,如今NVMe SSD可以达到50万IOPS,时延从毫秒压缩到微秒,系统的性能瓶颈也由存储硬件本身逐渐转移到网络及处理器上,传统文件系统、调度器等方法无法充分发挥新存储介质的性能,成为存储系统的新瓶颈。
随着存储介质的发展,传统内核态存储引擎的设计中,数据与元数据的存储也带来许多问题。
当磁盘分区时,需要将磁盘分区对齐,分区不齐会导致磁盘性能的明显下降。机械硬盘通常512 Byte对齐,SSD以4K对齐,但文件系统接收的用户数据往往不能严格保证以固定大小对齐,为了简化上层软件设计,并且充分利用存储空间,存储系统不得不允许用户以任意Byte更新数据,自身却使用对齐的IO来读写存储硬件,这种访问方式会带来巨大的性能浪费。

解决这一问题可以将非对齐的数据暂时存入PageCache中,待数据量达到基本对齐大小后统一存入存储介质,但这种方法存有弊端:PageCache的数据回写依靠内核周期性扫描或用户手动触发,这都需要间隔一个时间段进行执行,如果在这一间断周期里发生系统掉电,未及时写回的数据就会面临丢失的风险。
元数据在存储系统中大多是为索引而存在的。当数据写入后,有效期内数据几乎很少移动,但是元数据却需要频繁整理和移动。每次数据的变动,都会改变索引结构,因此需要频繁、及时的更新索引,以保证数据的高效和正确。
在现有的索引结构中,索引的重建和重组,会面对有效索引记录、失效索引标记、索引空间回收等问题;在索引重建时还会出现时间开销,这些消耗,在复杂的存储系统里会被逐渐放大,影响整个系统的性能。
业务运维遭遇难题
能够推出一款通用的存储系统,为百度大多数业务产品提供数据存储支持,一直是单机数据引擎团队研发的目标。从内部分布式到云上动态分布,从离线存储到在线实时,从系统的架构到系统的性能,百度的业务产品对存储系统的运维要求不断提高。
与此同时传统内核态存储系统中的几个弊端,也使系统的维护难度加大,运维成本增加。首先在产品业务量较大的场景下,内核态存储容易造成CPU资源消耗过高。这是因为在内核中,CPU资源是抢占式调度,每个进程都需要等待CPU空闲时才能调度 处理,因此业务量增大、进程增多CPU资源就会被过高占用。
其次在存储系统工作中,会出现因为单节点故障而造成整个系统停摆的风险;在内核态系统中,单机如果出现内核错误或漏洞,需要停掉主机,寻找原因修复补丁或升级内核,主机下线 会对运行在上层的业务造成严重影响。
第三在内核的日常维护中,如需升级内核组件,需要下线主机,停止主机上的所有业务,对内核或者驱动进行升级;除此之外内核或驱动的升级,有可能会给系统带来新的系统性风险。这些问题给系统的维护带来极大的不便,运维成本也显著升高。
解决方案:基于英特尔®傲腾™持久内存+SPDK的新一代用户态单机存储引擎
为了实现存储系统的可靠性、扩展性、高性能,低运维成本,百度单机引擎开发团队推出了基于英特尔®傲腾™持久内存和存储性能开发套件的用户态存储引擎,用以满足各业务产品对数据存储的挑战。
新单机存储引擎支持KV、file、block等多种应用接口,可应用于块存储、文件存储、对象存储等多种应用场景,满足不同业务的存储需求。该单机引擎还研发了创新的存储计算分离结构,领先的分布式架构,灵活的数据分层、用户态软件栈、本地/远程多种存储设备的兼容等等。
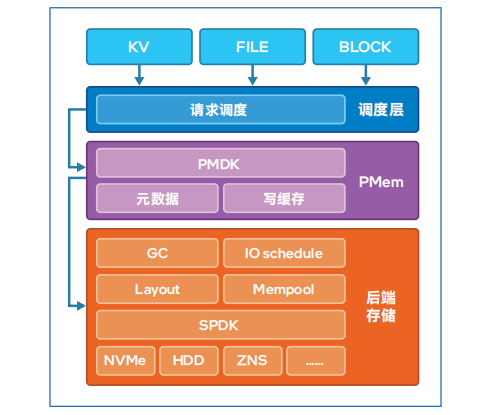
图1 用户态存储引擎架构
从架构图中可以看出整个单机引擎可以分为上下三层:调度层,PMem缓存层,后端存储层。
PMem缓存层
研发团队选择使用英特尔®傲腾™持久内存作为引擎缓存层的存 储介质。
英特尔®傲腾™持久内存【1】(以下简称“持久内存”或者“PMem”)是一种颠覆传统的内存产品,基于3DXpoint介质,具有高速、 低延迟、高性价比、大容量、持久数据保护、高级加密等优势。
它改变了原有的存储层次结构(图2),可以提供类似于DDR内存(简称“DRAM”)的性能,并且可以像SSD那样持久地存储数据,同时持久内存比DRAM容量更大,价格也更为便宜。
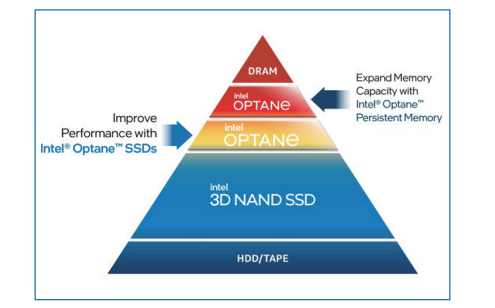
图2 在存储层级中,英特尔®傲腾™ 持久内存位于DRAM下方
图3显示了新的存储层次结构在容量、价格和性能上的对比情况。
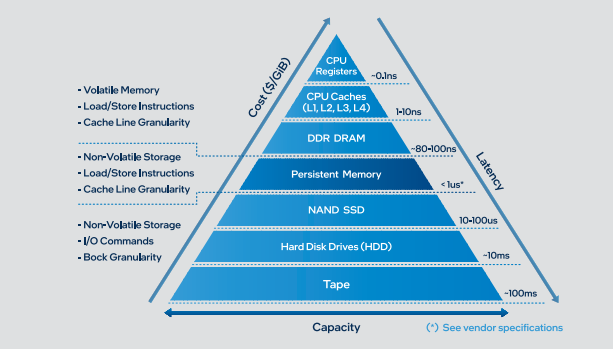
图3 存储层次结构在容量、价格、性能情况
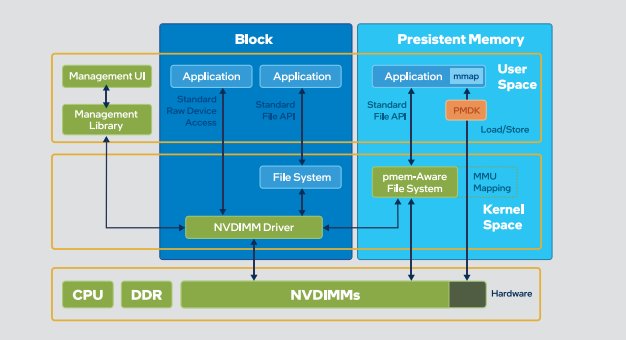
图4 持久内存SNIA编程模型和PMDK
持久内存设备遵循SNIA编程模型,同时英特尔为其提供了一套 持久内存开发套件PMDK。PMDK可以帮助应用来直接访问持久 内存设备而不需要经过文件系统的页高速缓存系统、系统调用和驱动,减少了许多流程,避免了数据输入/输出(I/O)产生的开销,大大降低数据延迟。
后端存储层
新单机引擎,使用持久内存存储元数据、缓存和索引,通过结合SPDK提供的多种后端存储支持,提供不同的解决方案。
SPDK【2】 提供了一组工具、库和方案,用于编写高性能和可扩展的 用户态存储应用程序。
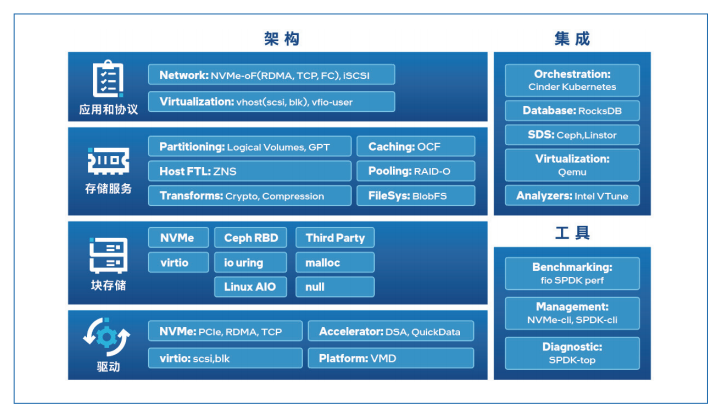
图5 SPDK架构
它通过使用多种关键技术来实现高性能和高扩展,诸如将一些驱动程序移至用户空间,避免了系统调用,并允许从应用程序进行零拷贝访问,通过无锁化、消息机制和异步编程来实现高性能应用框架,同时提供统一的用户态通用块设备来高效管理不同的存储后端设备。
使用SPDK之后,用户态的驱动通过轮询硬件而不是依赖中断来完成,这可以降低总延迟和减少延迟差异,并且和内核驱动相比,在每个CPU内核的IOPS上具有更明显的性能优势;此外,SPDK具备I/O路径的无锁高性能模式,避免了所有在I/O关键 路径中的锁,而是依靠消息传递在多个线程中共享资源,从而提高了并行性。
SPDK可以高效整合英特尔的CPU处理、存储和网络技术,将高性能存储介质的性能潜力充分发挥出来,同时高性能框架提供统一的设备管理来支持多种多样的存储后端。
新引擎带来优势
基于英特尔®傲腾™持久内存+SPDK的新一代用户态单机存储引擎,可以通过不同的配置,为各种应用场景提供解决方案。
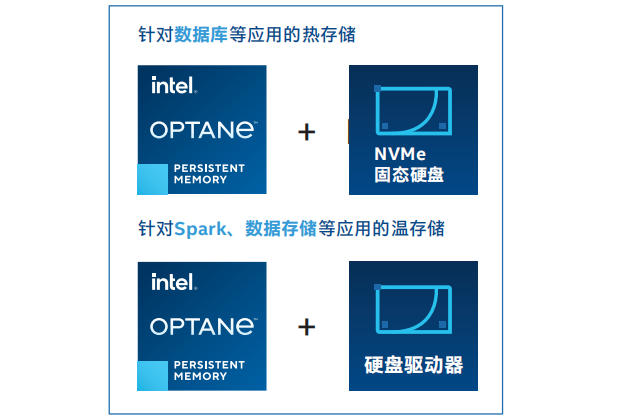
图6 单机引擎的多种应用
单机存储引擎的另一核心是要解决存储弹性的问题,在本地盘的存储架构下,存储资源被束缚在单台节点上:存储需要与机器内其他资源根据应用场景进行配比,无法充分利用存储资源;此外单主机节点的存储资源有限,对业务部署的实例大小有空间要求,无法实现单一实例的动态无限扩展。新单机引擎的出现,从本质上为百度解决了原有分布式系统,扩展性欠缺、本地存储资源使用不充分等问题。
优化:英特尔软硬件新技术加持,提升用户态存储引擎潜能
在新单机引擎的研发过程中,英特尔工程师与百度团队密切合作,依据单机引擎的性能特点,匹配最新技术的硬件产品,通过反复优化充分发挥硬件潜能。
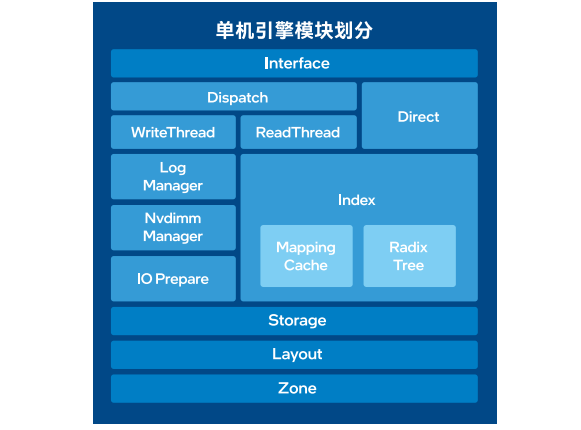
图7 单机引擎的模块划分
单机引擎的模块划分中(图7)可以看出,索引(Index)、LogManager(LogBuffer管理)、NvdimmManager(Log Manager和Index分配空间)、IOPrepare等模块都在由持久内存作为存储介质的缓存层。
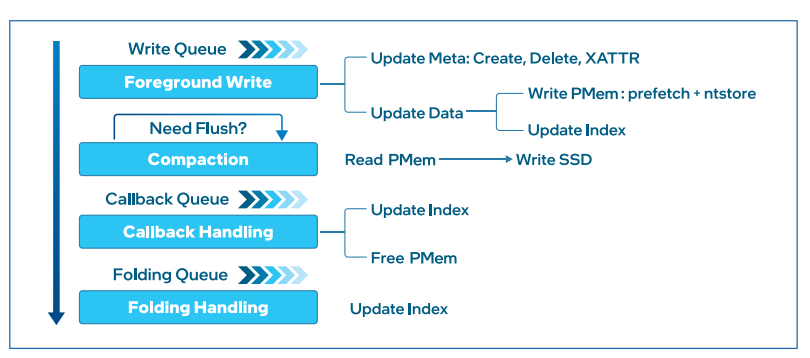
图8 工作线程
从新引擎的工作线程中我们看到,在系统读写的过程中会频繁的修改和整理索引,由此引发的索引重建、重组等时间开销会大量占用系统资源。使用应用直接访问模式下的持久内存作为缓存层,将索引数据存储在持久内存上,通过持久内存开发工具包(PMDK)进行内存调度,可以加速元数据的读写,最大程度减少资源损耗。
在传统的存储系统中,Buffer会被写入文件系统的PageCache中, PageCache的空间大小直接影响系统写的性能。如果存储 系统碰到突然爆发的写入压力,PageCache受空间所限,堆积在内的数据还未来得及写入磁盘,新增加的数据无法写入Buffer, 最终导致数据延迟性能下降。而在新单机引擎中,Buffer被写入 大容量的持久内存中,数据的读写能力与DRAM相近。
为了验证实际效果,研发团队对写入Buffer数据进行了测试。随机写入一个4K的数据,通过工具统计的延迟是4.5us,如下表所示,图中NTstore为写入持久内存的时间消耗,大约只有1us, 其余时间消耗都为软件其它开销;如果将PMem换成内存,延迟 大约1us的1/10,100ns,4K数据写入的时间在3us左右,与PMem延迟相差不大。
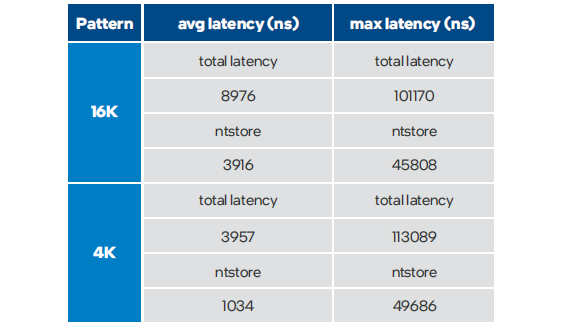
表1 测试结果
性能相近,总拥有成本却降低很多。相同的成本投入,PMem的空间是DRAM的三倍,因此可以缓存更多数据,提高存储系统性能;此外通过PMem缓存数据后,会以更加合理的方式存盘, 可以有效提高后端存储设备的IO效率。
在百度温存储单机引擎的解决方案中,使用成本更低的HDD作为底层存储介质,为了提高引擎性能,在缓存层和存储层间设计使用NVMe盘作为引擎的Cache。
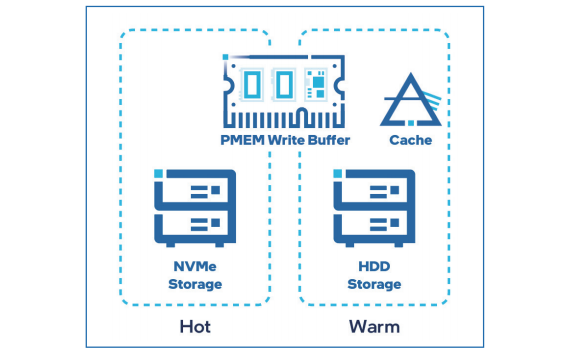
图9 NVMe加速温引擎
NVMe固态盘的Nandflash介质有许多缺点。首先,NandFlash有擦写次数限制,在Cache设计时需要增加额外的逻辑限制加载Cache的频率,防止频繁的Cache加载导致Nvme盘使用寿命大大缩短;其次NandFlash读延迟在100us级别,相比DRAM和3D XPOINT介质延迟表现一般。
英特尔®傲腾™固态盘采用与持久内存相同的3D XPOINT介质, 没有擦写次数限制,延迟在10+us级别,是作为Cache存储介质的最优选择,同时英特尔存储性能开发套件SPDK可以发挥出英特尔®傲腾™ 固态盘的高性能,运用到单机存储引擎中,解决 更多高性能存储需求。
新引擎性能优势
为了验证新单机引擎的性能,百度对单机引擎的两种应用进行了测试:
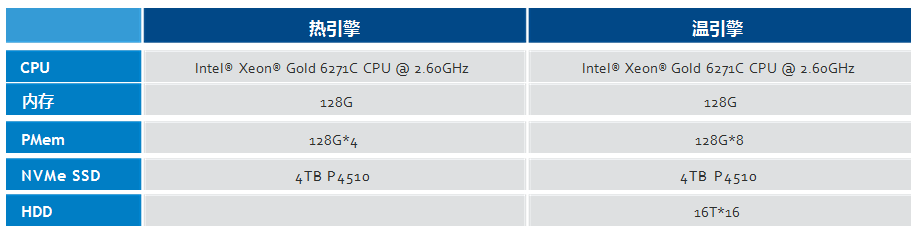
硬件环境【3】:
引擎性能:
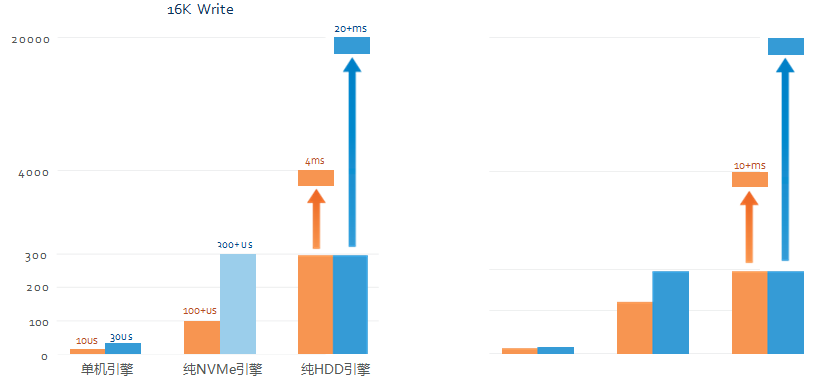

* 数值越低,性能越高 * 数值越低,性能越高
测试中分别对使用持久内存的新单机引擎,纯NVMe和纯HDD的传统引擎进行随机16K 数据的读写测试(QD为线程数量),从测试结果可以看出,新单机引擎的读写性能提升了10-20倍,在性能提高的同时,控制了总体拥有成本。
未来展望
在不久的将来,百度用户态单机存储引擎将会搭载第二代英特尔®傲腾™持久内存Optane PMem200系列产品和第三代英特尔®至强®可扩展处理器,配合系统性能的全面提升和新的CLWB指令,全新的CLWB指令在将数据刷新进持久内存后,仍然能够保持数据在CPU缓存中有效,相同数据的可以直接从缓存获取,从而增加缓存命中率,提升workload的性能。届时新单机引擎将会更安全、更高效,总体拥有成本更低,可以为百度全线产品提供高延展性、高可靠性、高附加值的存储服务。而百度也将携手英特尔, 致力于推动存储技术的创新和可持续发展,引领数据存储的未来。
【1】
https://www.intel.cn/content/www/cn/zh/architecture-and-technology/optane-dc-persistent-memory.html
【2】https://spdk.io/cn/
【3】数据援引自百度内部测试与评估,测试时间2020年6月,更多详情请咨询百度。
