
深入线程池的问题连环炮
JVM中的一个线程即对应一个操作系统的线程,也就是JVM的线程是由操作系统创建而来,创建线程和销毁线程这些都需要操作系统来分别赋予资源和释放资源等
也就意味着创建线程变成了一个比较重的操作
我们可以利用多线程去进行不同的工作,更高效的利用CPU资源,但是这并不意味着线程数量越多越好
我们的时代已经由原来的单核时代变成现在的多核时代了,这个核指的就是CPU,在原来的单核时代,如果一个线程一直是运算的逻辑过程,也就不涉及到线程的切换,因为这个线程一直在占用CPU,也就是属于计算密集型
但是如果这个线程属于IO密集型,也就是这个线程很多的时间都是在等待IO操作和处理IO操作,这样就浪费了CPU这个大脑的处理能力了
于是就有了多线程,一个线程等待IO操作,另一个线程可以顶上,充分利用了CPU的资源
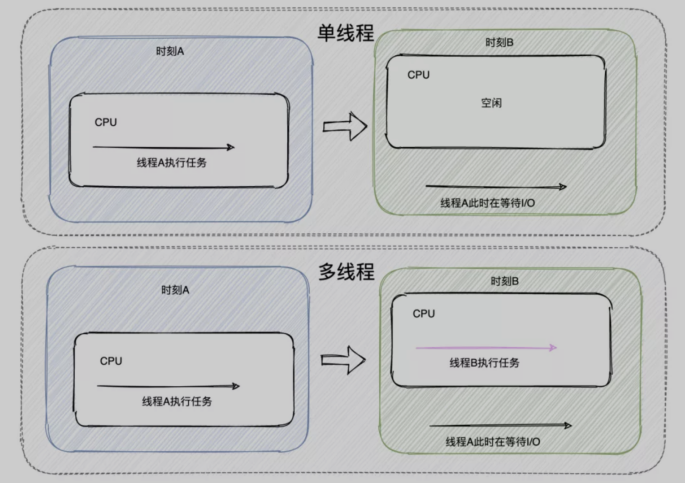
随着多核时代的到来,对于这个CPU高效利用也就变得更加迫切,CPU的核心越来越多,能同时运行的线程数越来越多了,也就意味着此时的多线程并不只是去提高单核的处理能力,更是为了充分利用这个多核的大脑
但 CPU 的核心数有限,同时能运行的线程数有限,所以需要根据调度算法切换执行的线程,而线程的切换需要开销,比如替换寄存器的内容、高速缓存的失效等等。
如果线程数太多,切换的频率就变高,可能使得多线程带来的好处抵不过线程切换带来的开销,得不偿失。
因此线程的数量需要得以控制

2、什么是线程池
线程的数量太少无法充分利用CPU,线程数太多的话会导致频繁切换线程,上下文切换消耗资源,我们需要根据系统资源和业务性能来决定线程数量
而线程的创建又是属于一个比较重的操作,所以我们想到的就是缓存一批线程,这种思想大家都明白应该,就像是数据库某张表需要经常查询,造成DB压力过大,我们就先把经常访问访问的数据放入到缓存中,用于缓解对于DB的访问压力
这个也是类似的道理,每次去新建和销毁线程比较重,我们就可以通过缓存这些线程来减轻不必要的消耗
线程的数量我们需要根据硬件的资源和线程要执行的任务这些等综合来决定
高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
并发不高、任务执行时间长的业务要分情况来讨论
假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务
假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,线程数设置为CPU核数+1,线程池中的线程数设置得少一些,减少线程上下文的切换
并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,参考上面的设置即可。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
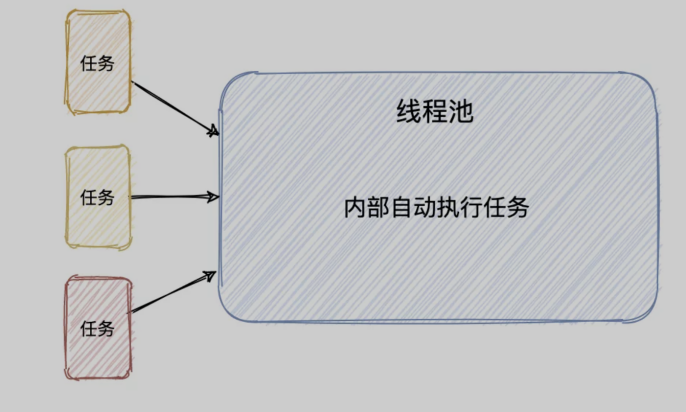
大家应该都听过对象池、连接池这些,池化的技术就是通过在池子里取出资源,然是使用完再放回到池子里,而线程池这一点稍微不太一样,这里线程池相对来说更黑盒一些
不是我们从线程池中取线程使用,而是直接往线程池里扔任务,然后线程池帮我们去执行
3、实现线程池
线程池内部也是一个典型的生产者-消费者模型
线程池内部有一个存放任务列表的队列,而内部会不断的有线程去队列中取任务来执行,用来消费
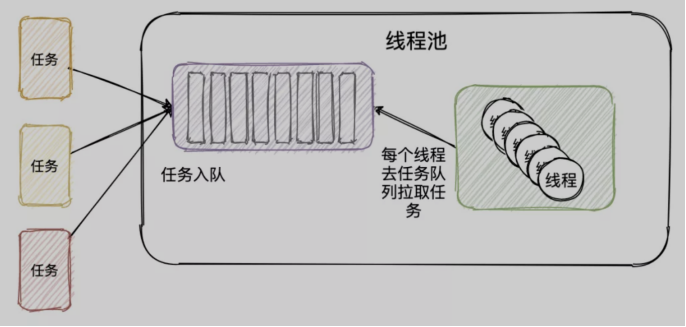
来看一个简易版的线程池实现,这段代码同样来源于上面的博文
首先线程池内需要定义两个成员变量,分别是阻塞队列和线程列表,然后自定义线程使它的任务就是不断的从阻塞队列中拿任务然后执行。
4jpublic class YesThreadPool {BlockingQueuetaskQueue; //存放任务的阻塞队列 Listthreads; //线程列表 YesThreadPool(BlockingQueuetaskQueue, int threadSize) { this.taskQueue = taskQueue;threads = new ArrayList<>(threadSize);// 初始化线程,并定义名称IntStream.rangeClosed(1, threadSize).forEach((i)-> {YesThread thread = new YesThread("yes-task-thread-" + i);thread.start();threads.add(thread);});}//提交任务只是往任务队列里面塞任务public void execute(Runnable task) throws InterruptedException {taskQueue.put(task);}class YesThread extends Thread { //自定义一个线程public YesThread(String name) {super(name);}public void run() {while (true) { //死循环Runnable task = null;try {task = taskQueue.take(); //不断从任务队列获取任务} catch (InterruptedException e) {logger.error("记录点东西.....", e);}task.run(); //执行}}}}
当然,这只是个最简易版的,也有很多可以优化的点
4、线程池核心参数

第1个参数:设置核心线程数。默认情况下核心线程会一直存活
第2个参数:设置最大线程数。决定线程池最多可以创建的多少线程
第3个参数和第4个参数:用来设置线程空闲时间,和空闲时间的单位,当线程闲置超过空闲时间就会被销毁。可以通过AllowCoreThreadTimeOut方法来允许核心线程被回收
第5个参数:设置缓冲队列,图中左下方的三个队列是设置线程池时常使用的缓冲队列
其中Array Blocking Queue是一个有界队列,就是指队列有最大容量限制。Linked Blocking Queue是无界队列,就是队列不限制容量。最后一个是Synchronous Queue,是一个同步队列,内部没有缓冲区
第6个参数:设置线程池工厂方法,线程工厂用来创建新线程,可以用来对线程的一些属性进行定制,例如线程的Group、线程名、优先级等。一般使用默认工厂类即可
第7个参数:设置线程池满时的拒绝策略
ThreadPoolExecutor默认有四个拒绝策略:
ThreadPoolExecutor.AbortPolicy() 直接抛出异常RejectedExecutionException,这个是默认的拒绝策略
ThreadPoolExecutor.CallerRunsPolicy() 直接在提交失败时,由提交任务的线程直接执行提交的任务
ThreadPoolExecutor.DiscardPolicy() 直接丢弃后来的任务
ThreadPoolExecutor.DiscardOldestPolicy() 丢弃在队列中最早提交的任务
5、线程池原理
我们向线程提交任务时可以使用Execute和Submit,区别就是Submit可以返回一个Future对象,通过Future对象可以了解任务执行情况,可以取消任务的执行,还可获取执行结果或执行异常。Submit最终也是通过Execute执行的

线程池提交任务时的执行顺序如下:
向线程池提交任务时,会首先判断线程池中的线程数是否大于设置的核心线程数,如果不大于,就创建一个核心线程来执行任务。
如果大于核心线程数,就会判断缓冲队列是否满了,如果没有满,则放入队列,等待线程空闲时执行任务。
如果队列已经满了,则判断是否达到了线程池设置的最大线程数,如果没有达到,就创建新线程来执行任务。
如果已经达到了最大线程数,则执行指定的拒绝策略。这里需要注意队列的判断与最大线程数判断的顺序,不要搞反
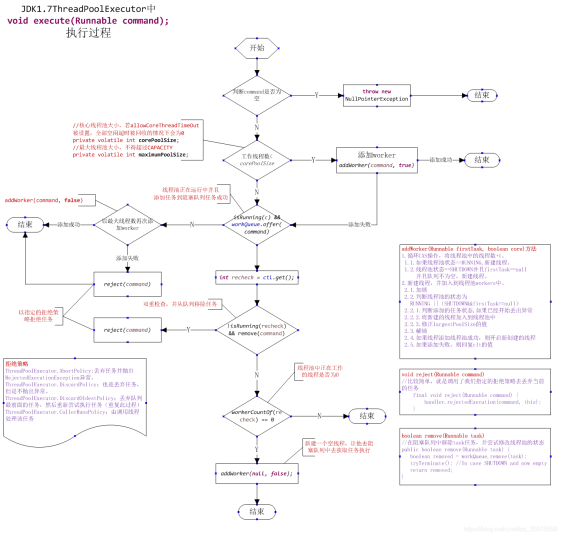
线程池中的线程并不是一开始就将活跃线程直接拉满的,而是随着用的数量的增加,才会逐步增加线程的,这是一种懒加载思想
但是这里有一个灵魂问题,没研究的小伙伴肯定是不知道的
6、当线程数小于活跃线程数的时候,并且线程数都处于空闲状态,现在提交一个任务,是新起一个线程还是用之前的线程来执行该任务?
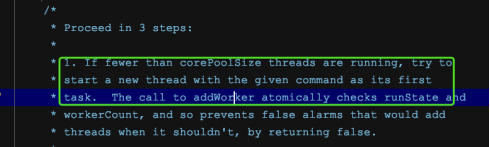
李老是这样说的:
If fewer than corePoolSize threads are running, try to starta new thread with the given command as its first task.
也就是无论其余线程是否空闲,只要此时线程数量小于核心线程数量,就会通过启动一个线程来执行该任务
线程池是懒加载的,但是这里又显得很勤快
也就是线程池是想要快速拥有核心线程数量的线程,这个作为线程池的中坚力量
而最大线程数其实是为了应付突发状况。
举个装修的例子,正常情况下施工队只要 5 个人去干活,这 5 人其实就是核心线程,但是由于工头接的活太多了,导致 5 个人在约定工期内干不完,所以工头又去找了 2 个人来一起干,所以 5 是核心线程数,7 是最大线程数。
平时就是 5 个人干活,特别忙的时候就找 7 个,等闲下来就会把多余的 2 个辞了

7、看到这里你可能会觉得核心线程在线程池里面会有特殊标记?
并没有,不论是核心还是非核心线程,在线程池里面都是一视同仁,当淘汰的时候不会管是哪些线程,反正留下核心线程数个线程即可
8、你是怎么理解 KeepAliveTime 的?
线程池的重点是保留核心数量的线程,但是会预留一些线程来用于突发情况,当突发情况过去之后,还是只想保留核心线程,所以这个时候就通过这个时间来控制
当线程数量大于核心线程数量的时候,并且空闲时间超过KeepAliveTime的时候,就回收线程,直到线程数量和核心数量持平为止
看了上面的线程池的逻辑,不知道大家有没有产生一个疑问
为什么要把任务先放在任务队列里面,而不是把线程先拉满到最大线程数?
这里我先说下我的个人理解
线程池的重点应该是核心线程池,而当线程数量不够处理的时候,先放到队列中也是属于一种缓冲的思想,因为我们在设计核心线程数量的时候都是考虑的尽可能的最优的数量,所以重点也就变成了尽力去维持核心线程的数量
而队列是可以自定义数量的,我们可以通过控制队列的长度,来控制我们可以接受的任务堆积的程度,只有当任务堆积无法忍受的时候,才会继续去启动新的线程来执行这些任务
当我看了Yes大佬的看法之后,发现也是这样理解的,但是解释的更深一些,我来和大家解释下
原生版线程池的实现可以认为是偏向 CPU 密集的,也就是当任务过多的时候不是先去创建更多的线程,而是先缓存任务,让核心线程去消化,从上面的分析我们可以知道,当处理 CPU 密集型任务的时,线程太多反而会由于线程频繁切换的开销而得不偿失,所以优先堆积任务而不是创建新的线程。
而像 Tomcat 这种业务场景,大部分情况下是需要大量 I/O 处理的情况就做了一些定制,修改了原生线程池的实现,使得在队列没满的时候,可以创建线程至最大线程数。
9、如何修改原生线程池,使得可以先拉满线程数再入任务队列排队?
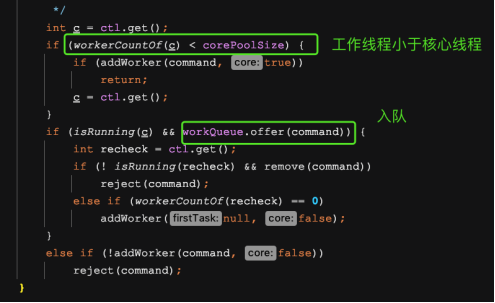
这里的逻辑其实上面也说过了,大家看一下源码就懂了,首先判断的是工作线程是否小于核心线程,当工作线程小于核心线程时,直接增加线程数量来执行任务
当达到核心线程数量的时候,则判断线程池是否在运行中,在运行中即执行入队操作
接下来一起看看Tomcat实现线程池的逻辑
public class ThreadPoolExecutor extends java.util.concurrent.ThreadPoolExecutor可以看到先继承了 JUC 的线程池,然后我们重点关注一下 execute 这个方法

这里可以看到增加了submittedCount作为任务数的统计,统计所有未完成的任务数量
首先调用原生过程,如果捕获到拒绝的异常,则判断队列类型,不正确,丢弃该任务,任务数量减一。
然后执行再次入队列,试图增加一次挽救的机会,入队失败,任务数量减一,最后处理捕获异常,任务数量减一
然后我们再来看下代码里出现的 TaskQueue,这个就是上面提到的定制关键点了。
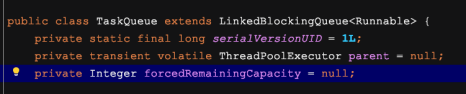
可以看到这个任务队列继承了 LinkedBlockingQueue,并且有个 ThreadPoolExecutor 类型的成员变量 parent ,我们再来看下 offer 方法的实现,这里就是修改原来线程池任务提交与线程创建逻辑的核心了。
这里就是对于offer逻辑进行了加强,我们看一下
先是如果没有线程实例,则直接按照原方法执行
接着判断如果线程数量是最大线程数量,直接入队
未完成的任务数小于线程数,证明此时还有闲着摸鱼的线程,直接入队即可,会自动消费
到最后,也就意味着此时核心线程都在运行,此时判断线程数量是否小于最大线程数量,如果小于,这里就直接返回false即可,这个false就映射了上面ThreadPoolExecutor中的execute方法中的offer,然后便会执行相应的增加线程的操作,而不是先选择入队
10、原生线程池的核心线程一定要伴随着任务慢慢创建吗
既然这么问了,答案肯定是否定的,线程池中提供了
线程池提供了两个方法:
prestartCoreThread:启动一个核心线程
prestartAllCoreThreads :启动所有核心线程
不要小看这个预创建方法,预热很重要,不然刚重启的一些服务有时是顶不住瞬时请求的,就立马崩了,所以有预热线程、缓存等等操作。
/*** Starts a core thread, causing it to idly wait for work. This* overrides the default policy of starting core threads only when* new tasks are executed. This method will return {@code false}* if all core threads have already been started.* @return {@code true} if a thread was started*/public boolean prestartCoreThread() {return workerCountOf(ctl.get()) < corePoolSize &&addWorker(null, true);}/*** Starts all core threads, causing them to idly wait for work. This* overrides the default policy of starting core threads only when* new tasks are executed.* @return the number of threads started*/public int prestartAllCoreThreads() {int n = 0;while (addWorker(null, true))++n;return n;}
11、线程池的核心线程在空闲的时候一定不会被回收吗?
有个allowCoreThreadTimeOut方法,把它设置为true ,则所有线程都会超时,不会有核心数那条线的存在。

12、线程池的关闭方法shutdown和shutdownNow
关闭线程池的方法,一个是安全的关闭线程池,会等待任务都执行完毕,一个是粗暴的直接咔嚓了所有线程,管你在不在运行,两个方法分别调用的就是 interruptIdleWorkers() 和 interruptWorkers() 来中断线程
/*** Initiates an orderly shutdown in which previously submitted* tasks are executed, but no new tasks will be accepted.* Invocation has no additional effect if already shut down.*This method does not wait for previously submitted tasks to
* complete execution. Use {@link #awaitTermination awaitTermination}* to do that.* @throws SecurityException {@inheritDoc}public void shutdown() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();advanceRunState(SHUTDOWN);interruptIdleWorkers();onShutdown(); // hook for ScheduledThreadPoolExecutor} finally {mainLock.unlock();}tryTerminate();}/*** Attempts to stop all actively executing tasks, halts the* processing of waiting tasks, and returns a list of the tasks* that were awaiting execution. These tasks are drained (removed)* from the task queue upon return from this method*This method does not wait for actively executing tasks to
* terminate. Use {@link #awaitTermination awaitTermination} to* do that.*There are no guarantees beyond best-effort attempts to stop
* processing actively executing tasks. This implementation* cancels tasks via {@link Thread#interrupt}, so any task that* fails to respond to interrupts may never terminate* @throws SecurityException {@inheritDoc}*/public ListshutdownNow() { Listtasks; final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();advanceRunState(STOP);interruptWorkers();tasks = drainQueue();} finally {mainLock.unlock();}tryTerminate();return tasks;}
这又可以引申出一个问题,shutdownNow 了之后还在任务队列中的任务咋办?眼尖的小伙伴应该已经看到了,线程池还算负责,把未执行的任务拖拽到了一个列表中然后返回,至于怎么处理,就交给调用者了
13、你肯定知道线程池里的 ctl 是干嘛的咯?
其实看下注释就很清楚了,ctl 是一个涵盖了两个概念的原子整数类,它将工作线程数和线程池状态结合在一起维护,低 29 位存放 workerCount,高 3 位存放 runState
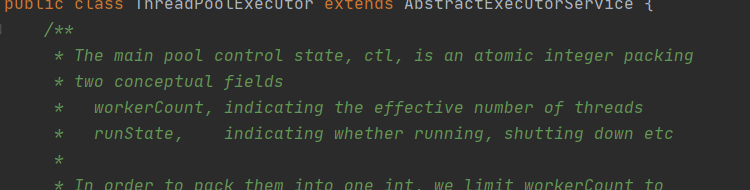
其实并发包中有很多实现都是一个字段存多个值的,比如读写锁的高 16 位存放读锁,低 16 位存放写锁,这种一个字段存放多个值可以更容易的维护多个值之间的一致性,也算是极简主义

13、线程池有几种状态吗?
注解说的很明白,我再翻译一下:
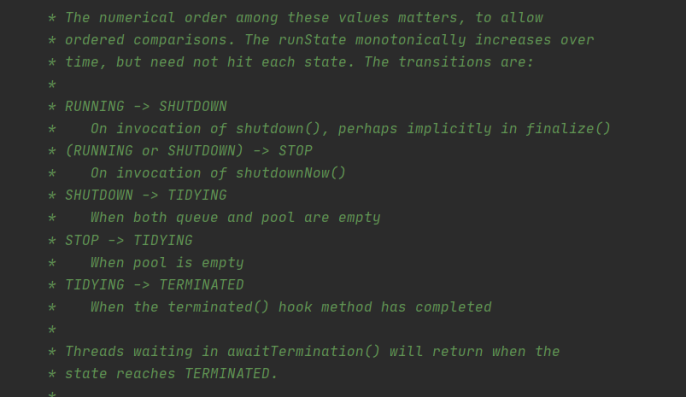
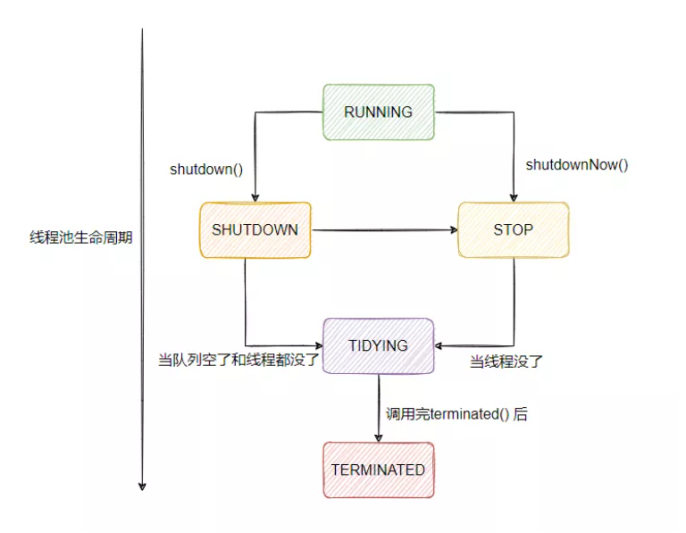
RUNNING:能接受新任务,并处理阻塞队列中的任务
SHUTDOWN:不接受新任务,但是可以处理阻塞队列中的任务
STOP:不接受新任务,并且不处理阻塞队列中的任务,并且还打断正在运行任务的线程,就是直接撂担子不干了!
TIDYING:所有任务都终止,并且工作线程也为0,处于关闭之前的状态
TERMINATED:已关闭
13、线程池的状态是如何变迁的吗?
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️