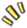跨出前端智能化的第一步-tensorflow的应用

第一部分、引言
一、阅读本篇文章你能得到什么
1、了解tensorflow及关键社区资源;2、能够自主训练和应用自己想要的模型(主要);3、开阔前端智能化的思考与认知;
二、什么是对象识别
简单来说,在图片或视频识别出你关注的对象类别、坐标就是对象识别,你可以通过以下视频加深认知:1、Ai采摘机器人:www.bilibili.com/video/BV1YE…
2、英雄联盟血条识别:www.bilibili.com/s/video/BV1…
3、车辆识别:www.bilibili.com/video/BV1si…
4、人物识别:www.bilibili.com/video/BV1Es…
5、卫星船舶检测
www.bilibili.com/s/video/BV1…
三、前端为什么需要对象识别能力
1、通过对象识别可以做到D2C,也就是设计稿识别产出代码;2、他带给了前端更多可能性、效率提升、可控能力;
四、带着目标看流程
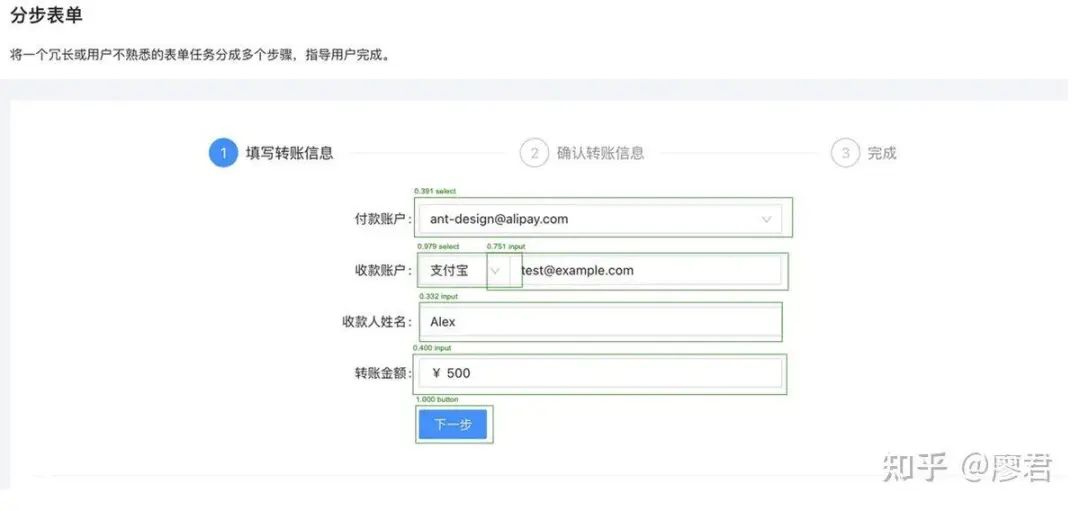
我简单训练了一个antd ui识别模型,可以将图片中的ui组件坐标和类别识别出来,同时附带识别的分数,下面将详细为大家介绍如何训练一个自己的object_detection模型。
第二部分、object_detection完整实践
分为以下几个环节:1、搭建环境;2、创建数据集;3、选择预训练算法模型;4、调整参数开始训练;5、验证训练成果;6、导出并转换模型给前端使用(浏览器/node环境);
一、搭建环境
参考:www.tensorflow.org/install
准备最新python环境; 安装tensorflow2; 通过pip安装tensorflowjs(这个主要用于转换最终导出的模型供js环境使用); 注意Python Package Installation这一步:github.com/tensorflow/… 可通过conda做环境管理(可选);
注意:直接使用tensorflow2就行了,没有太多必要使用tensorflow1;安装和使用过程中应该会遇到一些pip包缺失的问题,这个需要自己看提示解决,其实跟npm类似。建议用主机进行环境搭建及训练,配置当然越高越好。
二、创建数据集
tensorflow对象识别需要使用tfrecord格式数据集
推荐的标注平台:app.labelbox.com/
推荐的制作导出平台:app.roboflow.com/
创建数据集的方式有很多种,可以通过python语言创建自定义tfrecords数据集,也可以通过各类数据集标注平台;
注:
tfrecords是tensorflow定义的一种数据格式,直接用于数据训练; 通过收集大量训练图片进行人工标注(也有半自动标注、自动标注,如通过UI组件生产页面进行自动标注); 标注的分类数量需要尽可能均匀一些,减少准确性偏差;
这里简单介绍一下通过平台标注流程(labelbox+roboflow):labelbox 部分
准备一些含ui的图片,尺寸和名称没有特别要求,可以直接截图保存;
在labelbox新建项目并批量上传图片;
编辑分类

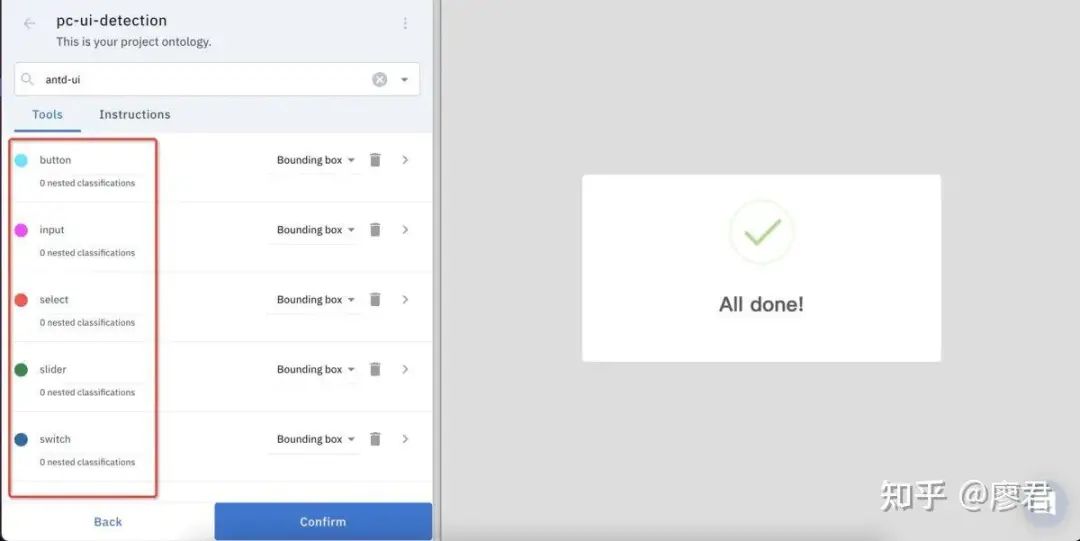
4.开始标注(start labeling)
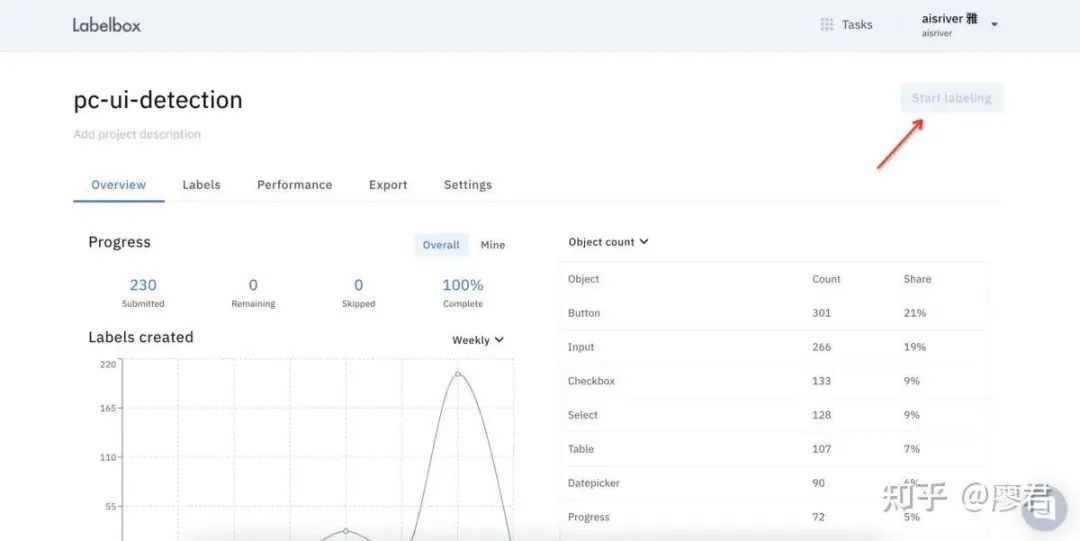

5、完成所有标注,导出JSON文件
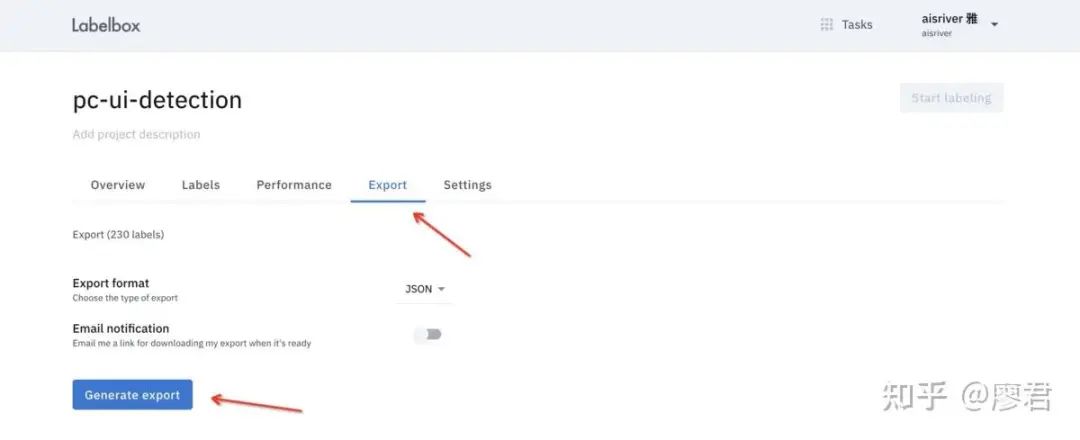
roboflow 部分
创建数据集
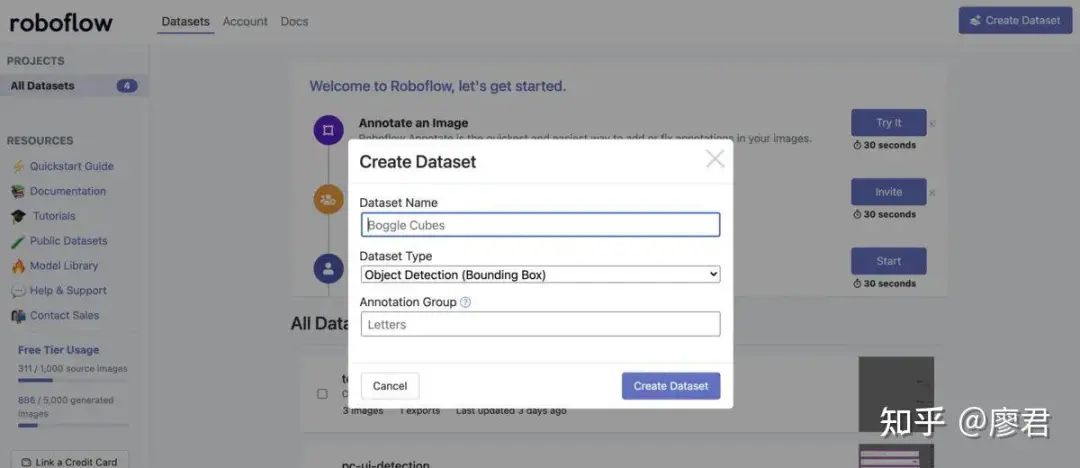
2.按提示上传刚刚导出的json文件,根据提示继续操作
3.在导入数据集基础上,进行自定义图片处理
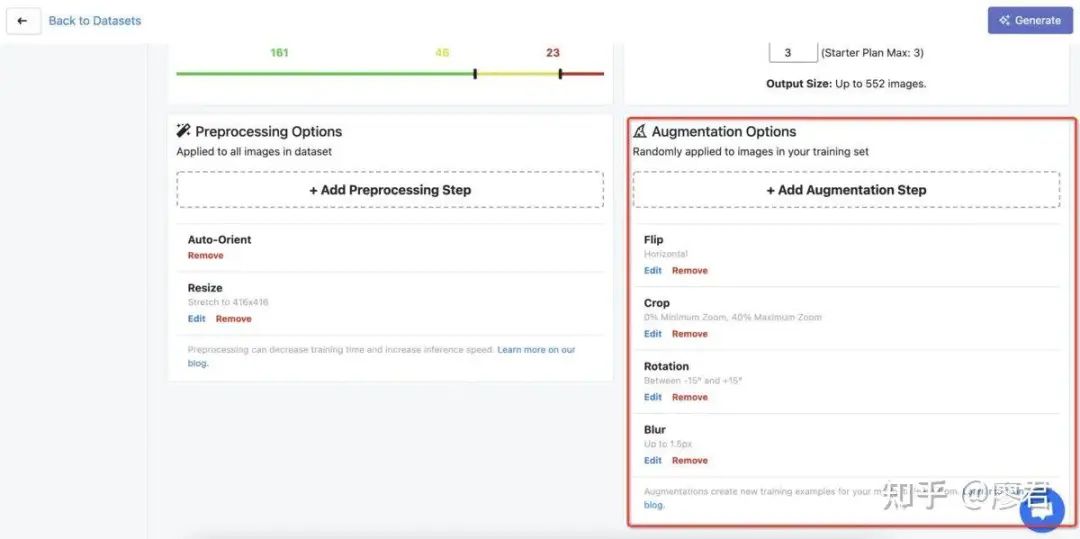
注意:这里可能包含旋转、模糊、翻转等操作,你可以通过最终模型识别目标来判断是否有必要加入某一步骤;比如:如果你识别的全部都是方方正正的UI设计稿,则旋转就没有太多必要了。他的作用在于帮你自动处理扩充数据集,以便适应各类识别场景。
点击generate、查看健康检查
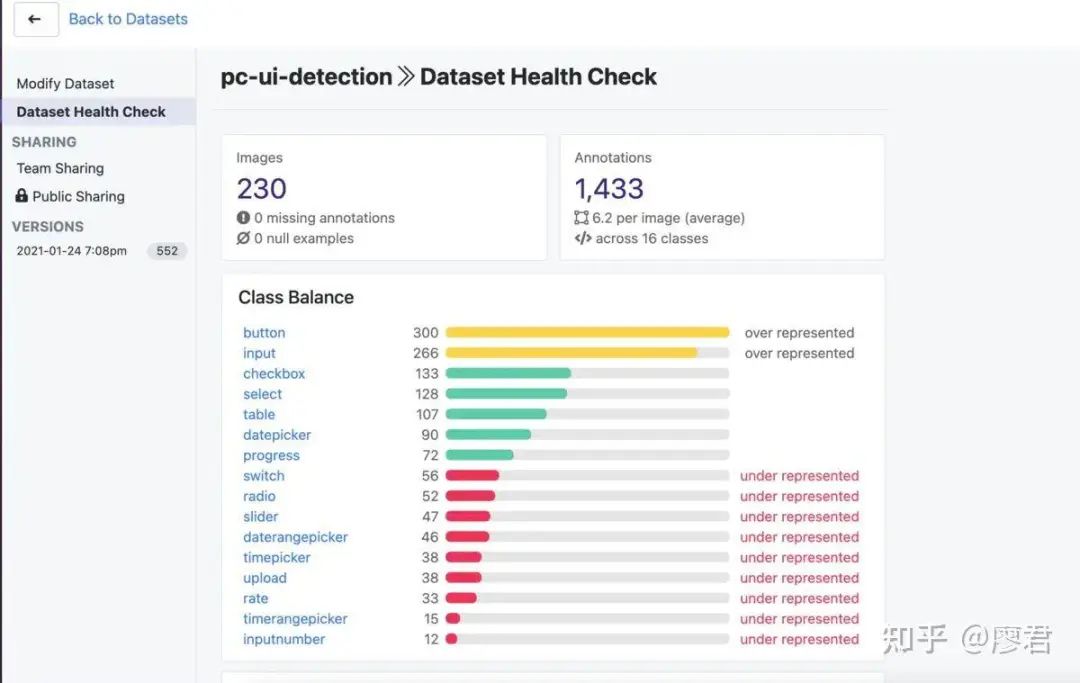
注意:上文提到过,尽量不要让标注的分类数量相差太多。
下载数据集
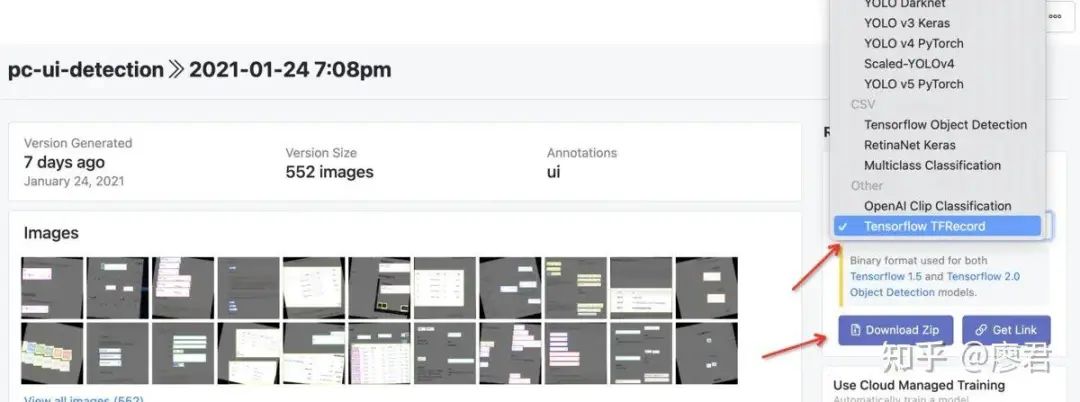
注意:这里选择tensorflow tfrecord格式下载即可。
三、选择预训练算法模型
tensorflow拥有很完善的文档,大家直接在对应的官网或github寻找即可
github.com/tensorflow/…
目前使用的是(训练容易/导出的文件不算太大):SSD MobileNet V2 FPNLite 640x640
选择模型的时候需要考虑以下几点:
识别速度;
识别准确率;
训练难度(尺寸越大训练难度越大,主要体现在对机器性能上);
前端解析识别数据(重要);
注意:多数模型都提供了入参(处理后的图片)和出参(一个tensor格式的数组),不同模型最终产出的结果是不一样的,但一般都包含对象分数score、对象尺寸及位置boxes、数量等,这些需要自行判断。
四、调整参数开始训练
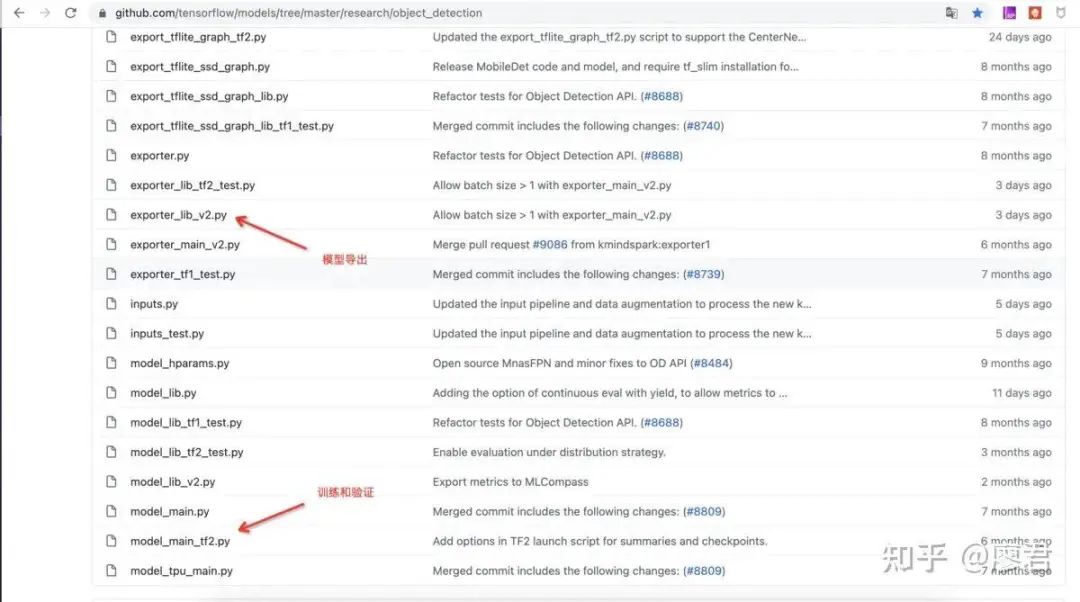
github.com/tensorflow/…

主要有以下几个参数需要调整:
num_classes 代表数据集的分类数量; fine_tune_checkpoint 指向下载预训练模型中的checkpoint(根据这个文件的model_checkpoint_path来就行); fine_tune_checkpoint_type 改成detection(实际分类模型tf2也有提供,如不改容易出现内存问题中断训练); label_map_path 都指向导出tfrecords里面生成的就行(其实就是标注的分类); tf_record_input_reader 分别对应train/test目录的tfrecord文件; 关键点train_config配置,batch_size训练批次(即一次训练所抓取的数据样本数量)、total_steps、num_steps调整,这部分既要考虑机器性能又要考虑数据量,需要根据自己的实际情况而定(位数的调整可能引起成倍的训练时间);
注意:
建议找个性能不错的主机进行训练,用自己的mac大概率会失败(下一步验证训练结果会提及)。 批次大小机器允许的情况可以设置大一些,但也不是越大越好哈,可以自己另外了解一下; total step根据loss曲线做调整; 二次训练场景(有了一个训练好的优质模型,里面已经储备了大量知识,当前训练的数据比较少,可以尝试在已有模型基础上二次训练),如果不确定建议都从0开始; 训练时长受数据、算法模型、批次、step、机器效率等影响,可以通过本地编译、使用gpu加速等方式减少训练时间;
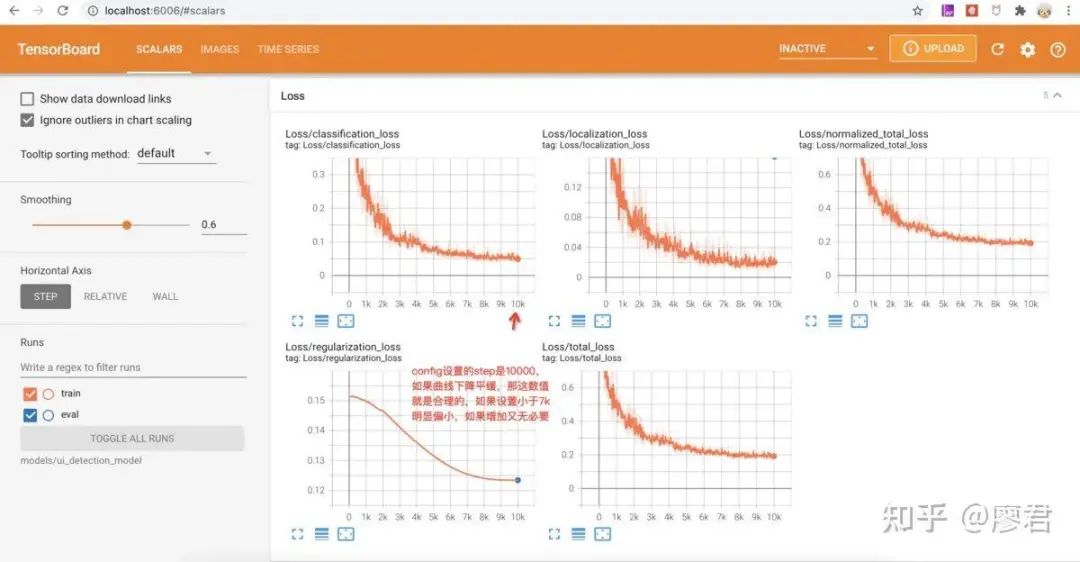
五、验证训练成果
执行:tensorboard --logdir model_dir
打开启动的地址:http://localhost:6006/
观察loss曲线,判断step设置是否合理
2.查看图片验证结果
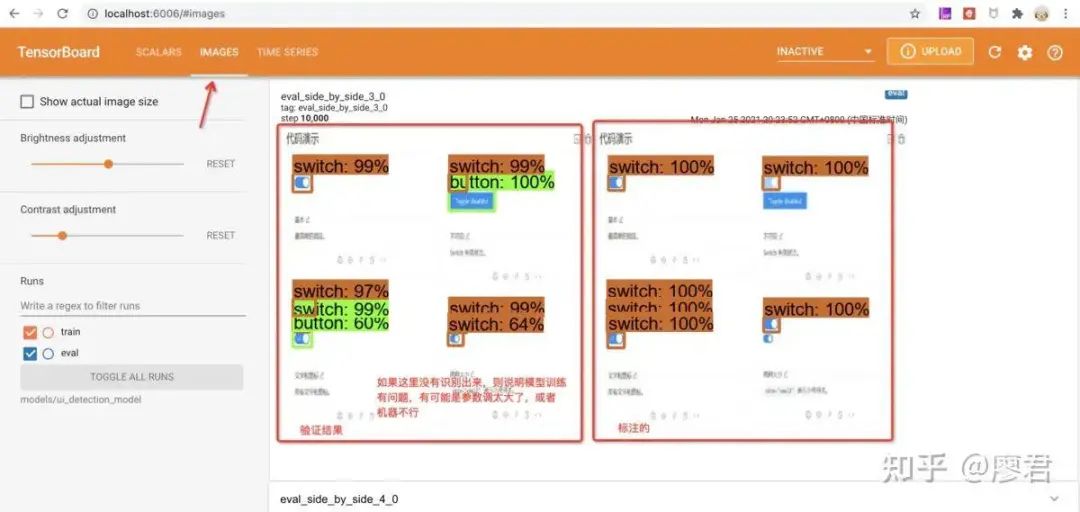
注意:通过以上2点基本可以确定模型是否可用,大家也可以学习一下其他分析技巧,互相分享。
六、导出并转换模型给前端使用(浏览器/node环境)
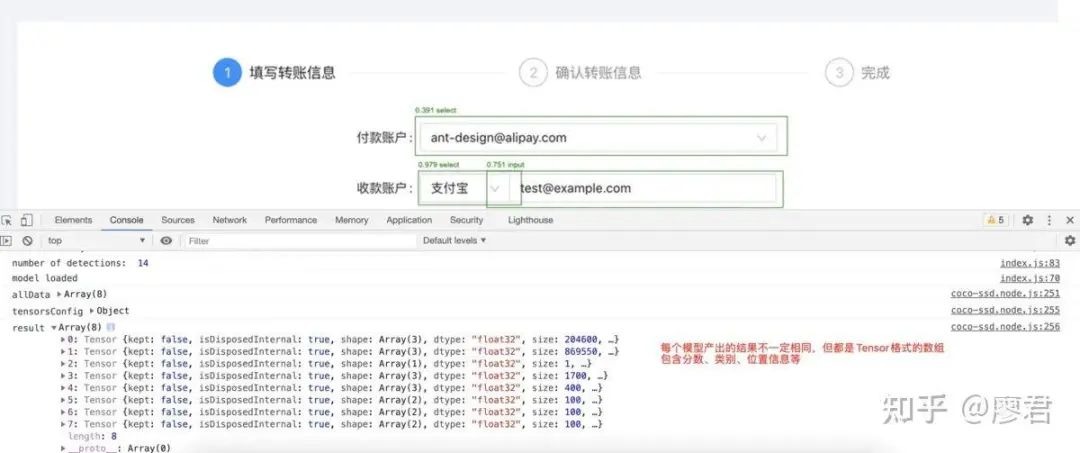
exporter_main_v2.py 导出saved_model; 记得pip install tensorflowjs,然后使用tensorflowjs_converter转换成前端可用模型 参考coco-ssd的模型导入与识别:github.com/tensorflow/…
注意:后面其实就是通过@tensorflow/tfjs-core等库进行模型加载和图片识别了,也可以参考我这个库github.com/aisriver/tf…,里面包括了一些训练代码和使用示例。
第三部分、结合tensorflow的其他前端实践
可直接投入前端使用的模型和演示:github.com/tensorflow/…
其他能力:图像分类、文本识别、语音识别、视频识别,并可以直接在社区找到对应资源;
前端应用:
组件识别/D2C(如imgcook:www.imgcook.com/)、 图表库识别(大屏设计稿识别)、搜图(antd的图表搜索)、 手势识别(大屏手势交互:www.bilibili.com/video/BV1ET…)、语言指令、恶意评论检测、敏感图片/视频识别、智能家居、物联领域的环境安全检测等
大屏通过手势进行互动,想想都觉得很酷,而且实现起来也没有那么难。
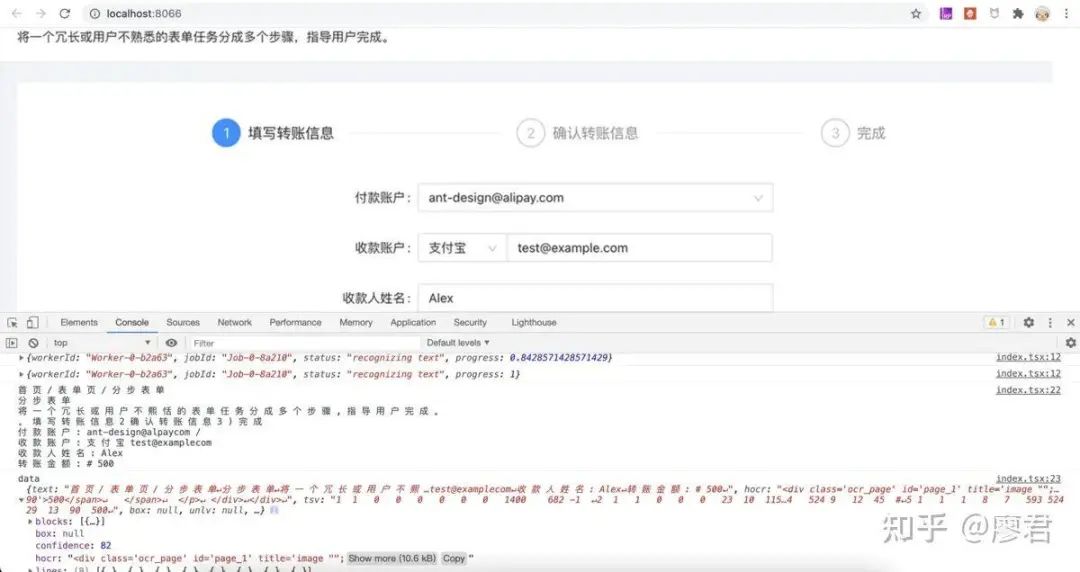
推荐一个直接可用的文本ocr识别
ocr识别比训练一个对象识别模型更加复杂,需要考虑语言、字体等因素,所以我没有选择自己训练,太麻烦。推荐使用:www.npmjs.com/package/tes…
支持多国家语言
智能化让前端拥有更多可能性!
最后,帮大家整合一下社区资源
官网:tensorflow.google.cn/ 模型库可数据集(重要):www.tensorflow.org/resources/m… 对象识别github(核心):github.com/tensorflow/… 训练和评估(重要):github.com/tensorflow/… js相关已有模型库及应用(参考):github.com/tensorflow/… 数据标注平台(重要):app.labelbox.com/ 数据集订制与导出平台(重要):app.roboflow.com/ 模型分析工具(了解就行):github.com/lutzroeder/… 文本OCR识别(推荐):www.npmjs.com/package/tes…
github
github.com/aisriver
最后
欢迎加我微信(winty230),拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...