
逼近GPT-4,AI编程要革命!Meta开源史上最强代码工具Code Llama

新智元报道
新智元报道
编辑:编辑部
【新智元导读】史上最强开源代码工具Code Llama上线了,Llama-2唯一的编程短板被补平,34B参数的模型已接近GPT-4。
凭借开源Llama杀疯的Meta,今天又放大招了!
专用编程版的Code Llama正式开源上线,可以免费商用和研究。

Code Llama是从Llama-2基础模型微调而来,共有三个版本:基础版、Python版、以及指令遵循。
每个版本都有3种参数:7B、13B、34B。值得一提的是,单个GPU就能跑7B模型。
在评测基础上,Code Llama的性能与GPT-3.5打平,同时34B参数的模型在HumanEval基准上,接近GPT-4。
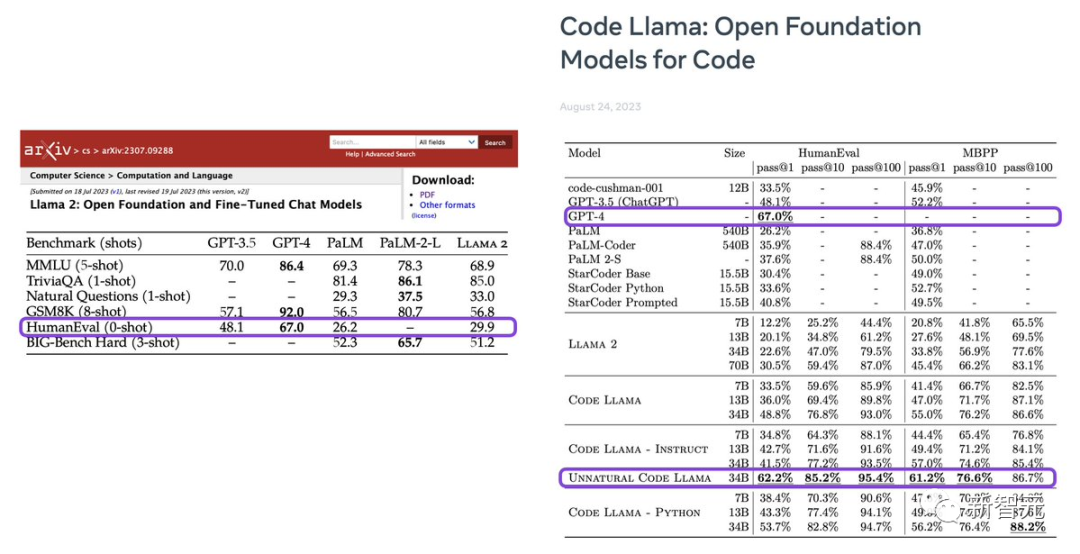
不知道,大家有没有注意到其中一个模型:Unnatural Code Llama。
OpenAI科学家Karpathy,乍一看,非常nice!
但是关于这个Unnatural Code Llama,有着神秘名字,含糊的描述、秘而不宣、碾压其他所有模型,多么诱人啊!


Code Llama发布后,LeCun也是疯狂点赞转发自家的科研成果。
英伟达科学家Jim Fan称,Llama-2几乎达到了GPT-3.5的水平,但在编程方面却大大落后,这真的很让人失望。现在,Code Llama终于弥补了与GPT-3.5之间的这一差距!
编程无疑是最重要的LLM任务。它是强大推理引擎和像Voyager这样的强大AI智能体的基石。

Code Llama的横空出世,标志着AI在编程中的重大飞跃,人人都可以利用这个模型进行复杂精确的编程开发任务。
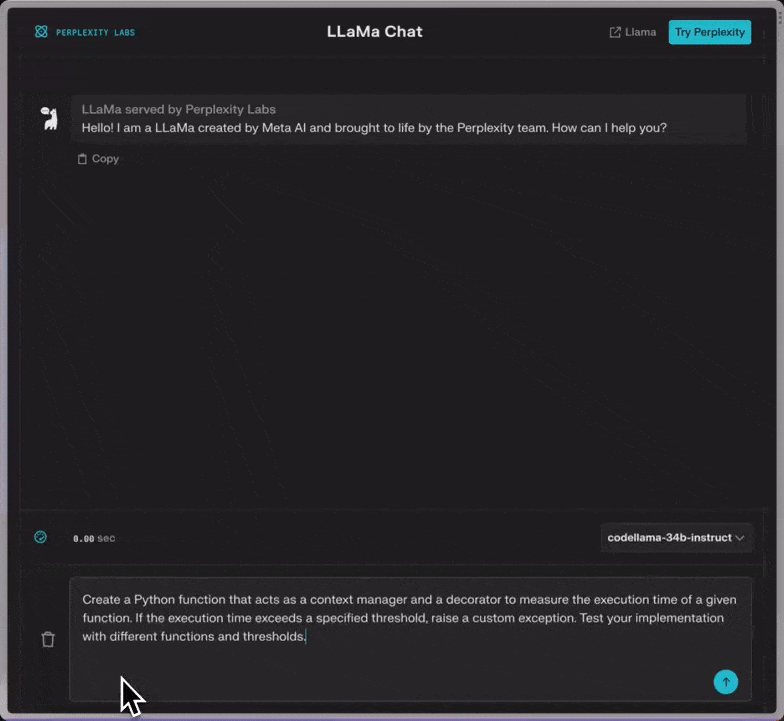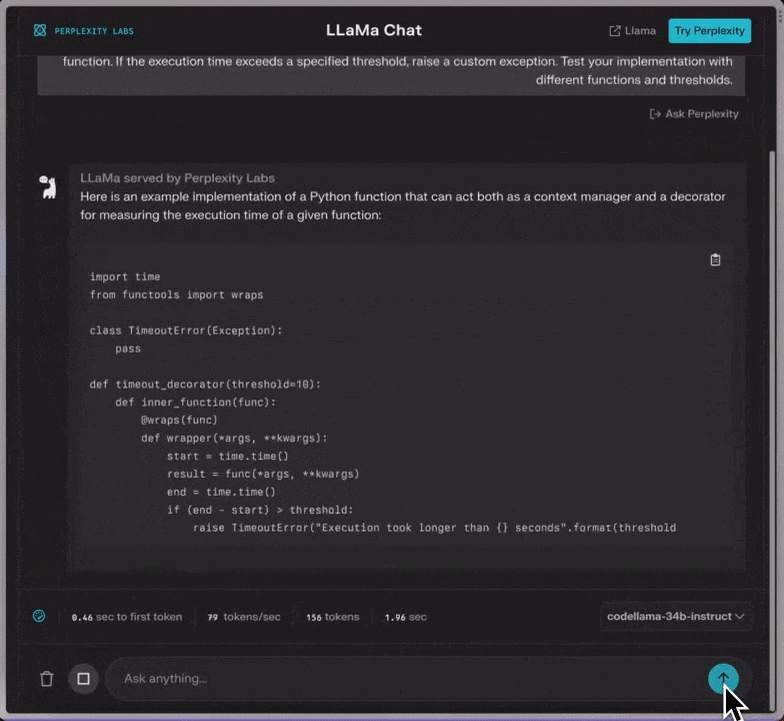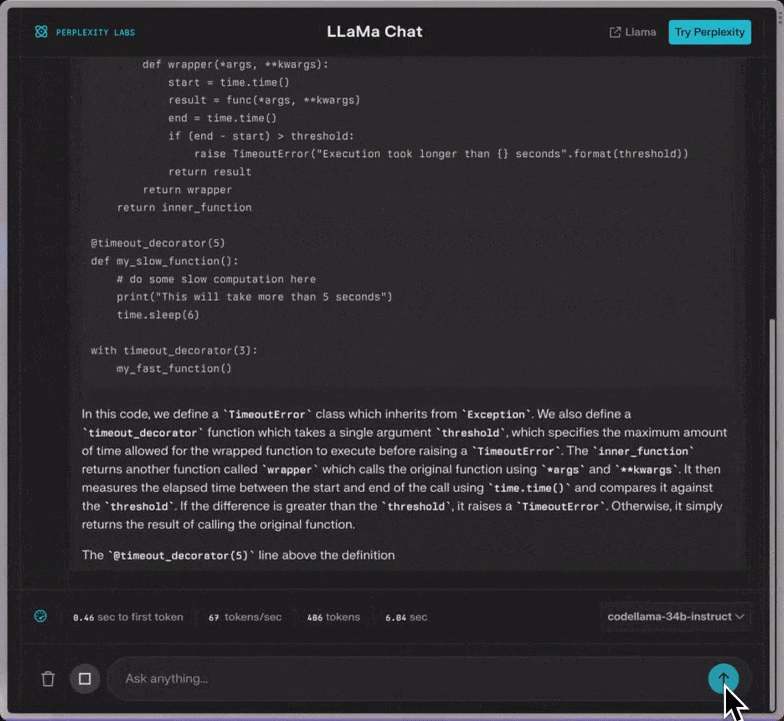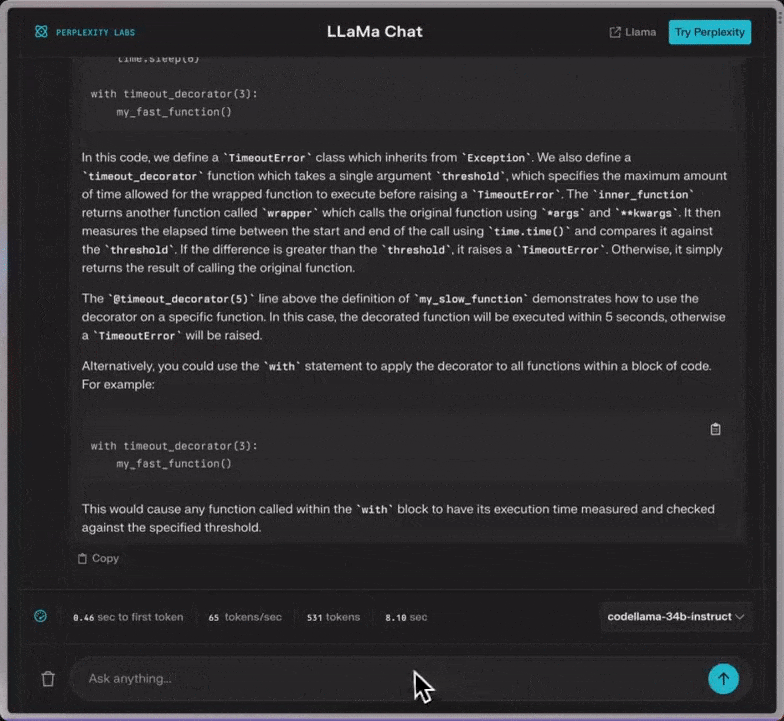
另外,值得一提的,Perplexity的聊天工具,现在就可以用上Code Llama了。
快来一试:
https://labs.perplexity.ai/?utm_content=first_codellama&s=u&utm_source=twitter&utm_campaign=labs
Code Llama是如何练成的?
Meta宣称,在代码任务中,Code Llama是目前公开可用的LLM中最先进的模型。它能够使开发人员的工作流程更加快速高效,并降低学习编程的门槛。
Code Llama可以作为生产力和教育工具,帮助程序员编写更加稳定、更加符合编码规范的软件。
Meta认为开源策略能够促进AI领域的创新,是开发安全和负责任的AI工具的最佳途径。
所以Code Llama与Llama2的社区许可协议是完全相同的,学术和商用都免费。
Code Llama是Llama 2强化了代码能力的版本。

论文地址:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Meta从训练Llama 2代码能力的数据集中提取了更多的数据,训练了更长的时间,得到了Code Llama。
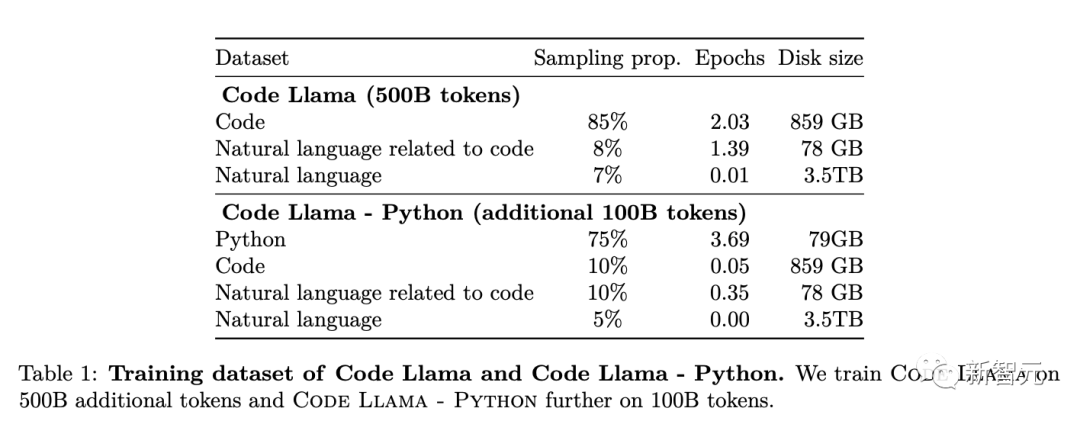
它可以根据代码和自然语言提示(比如「编写一个输出斐波那契数列的函数」)生成代码和与代码有关的自然语言描述。
它还可以用于代码补全和Debug,支持当今最流行的编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。
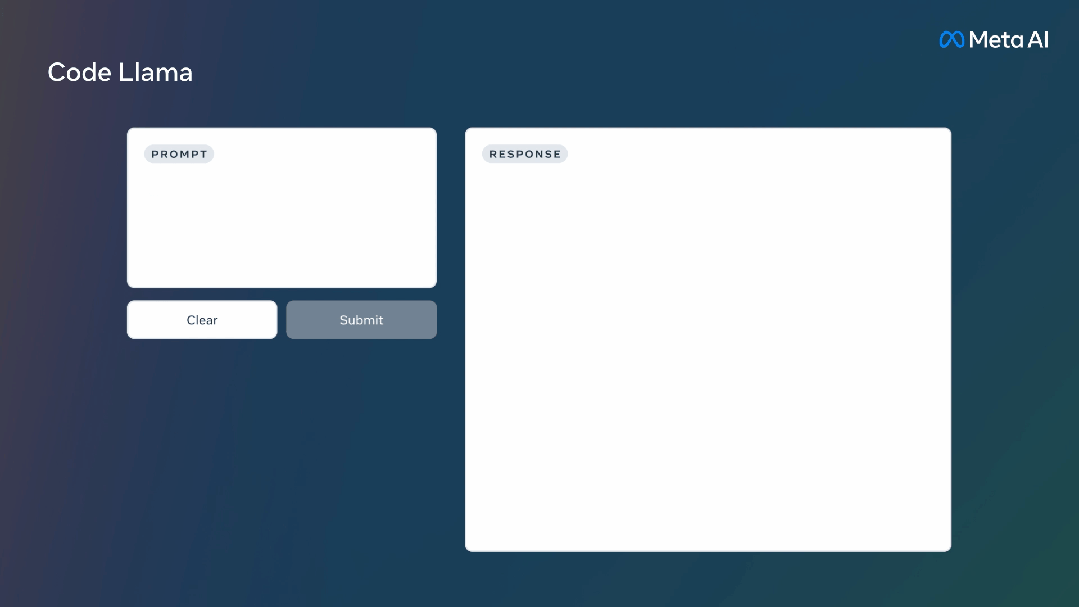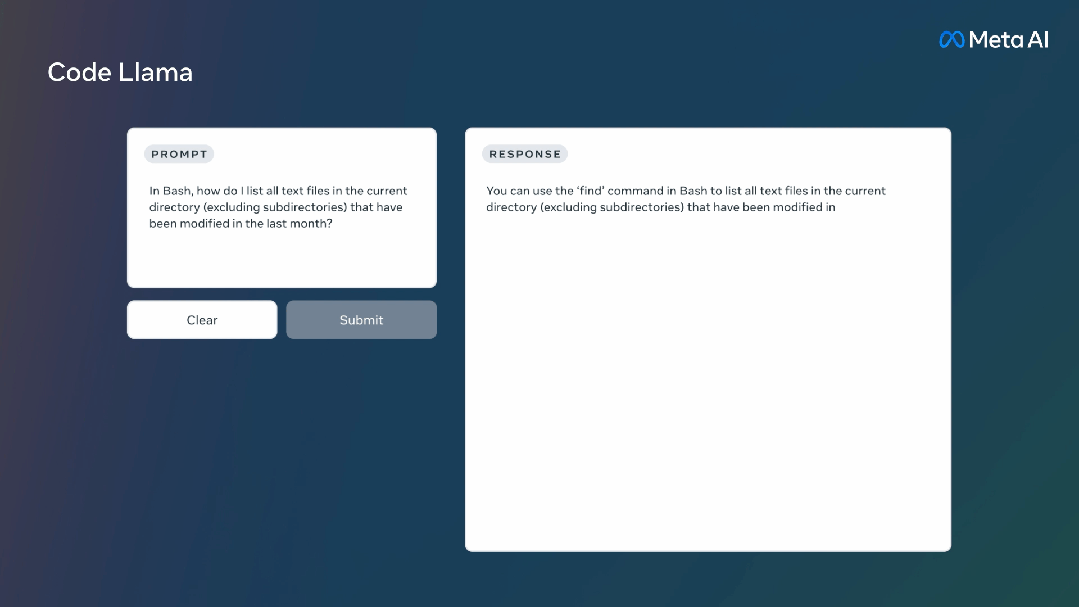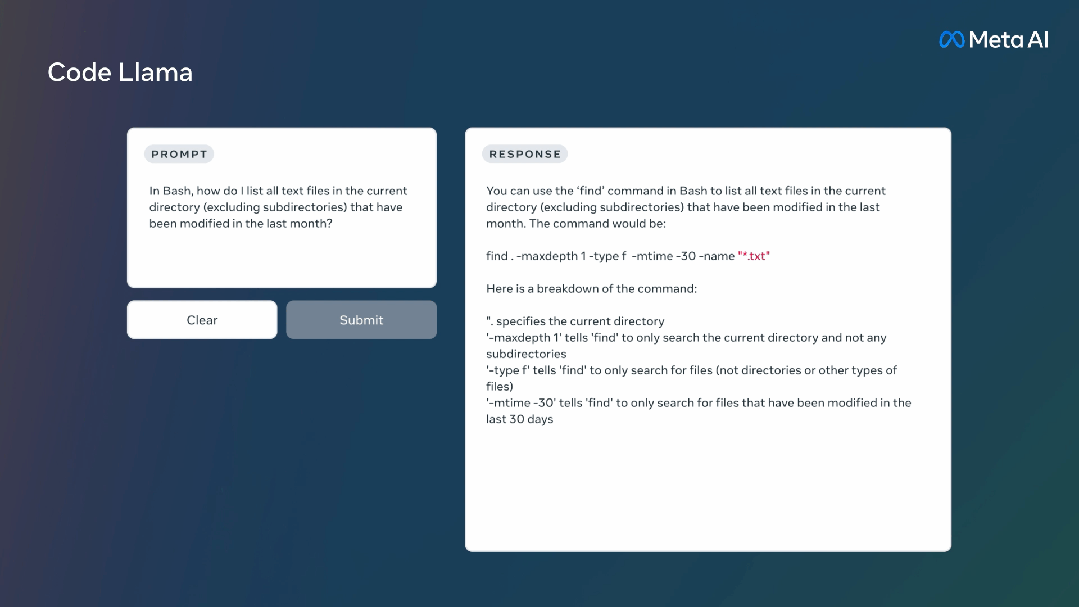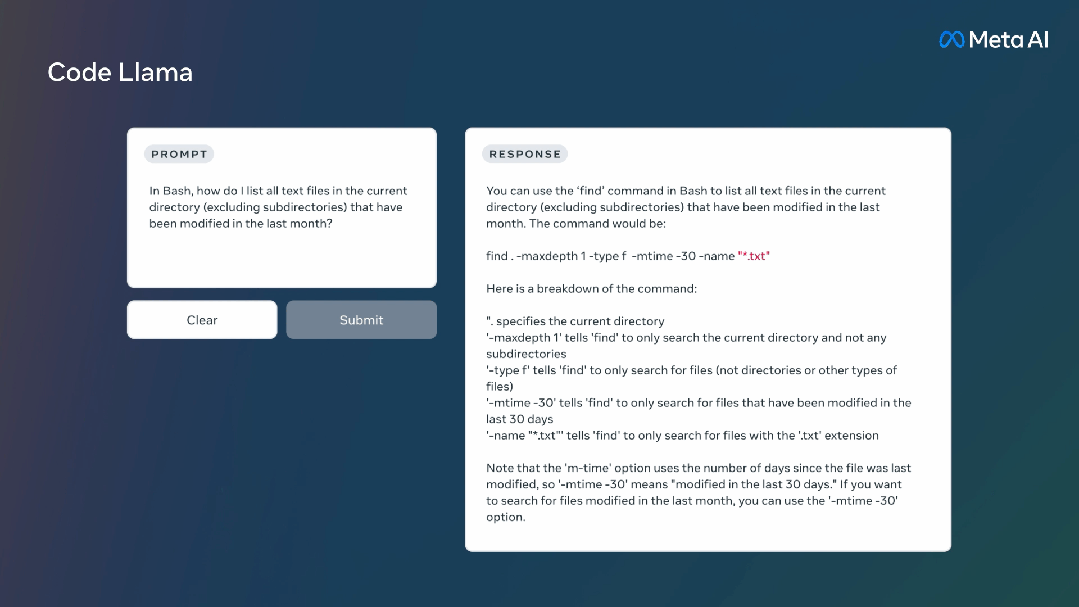
Meta发布了三个不同规模的Code Llama,分别拥有7B、13B和34B的参数。
每个模型都使用了500B token的代码和与代码相关的数据进行训练。
其中,7B和13B的基础模型以及Instruct模型还经过了Fill-In-the-Middle(FIM)能力的训练,使它们能够将代码插入到现有代码中,使得它们能够完成代码补全相关的任务。
这三个模型可以满足不同的服务场景和延迟的需求。
7B模型单个GPU就能跑。
34B模型生成结果最好,编码辅助的效果也最好。但规模较小的7B和13B的模型运行速度更快,更适合需要低延迟的任务,比如实时的代码补全。
Code Llama模型能稳定支持最多10万token的上下文。而且所有模型都是基于16k的token序列进行训练的,在最高10万token的输入中显示出了改进效果。
拥有更长的上下文能力除了能生成更长的程序,还为代码大语言模型带来了许多新的用途。
它使得用户能向模型喂更长的代码库上下文,让生成的结果与原先的代码相关性更高。
这也使得模型在「Debug大型代码库」这样的场景中能发挥更大的作用。
因为在这种情况下,想要跟踪「与某个具体问题相关」的所有代码,对于开发人员来说是一项很令人头疼的任务。
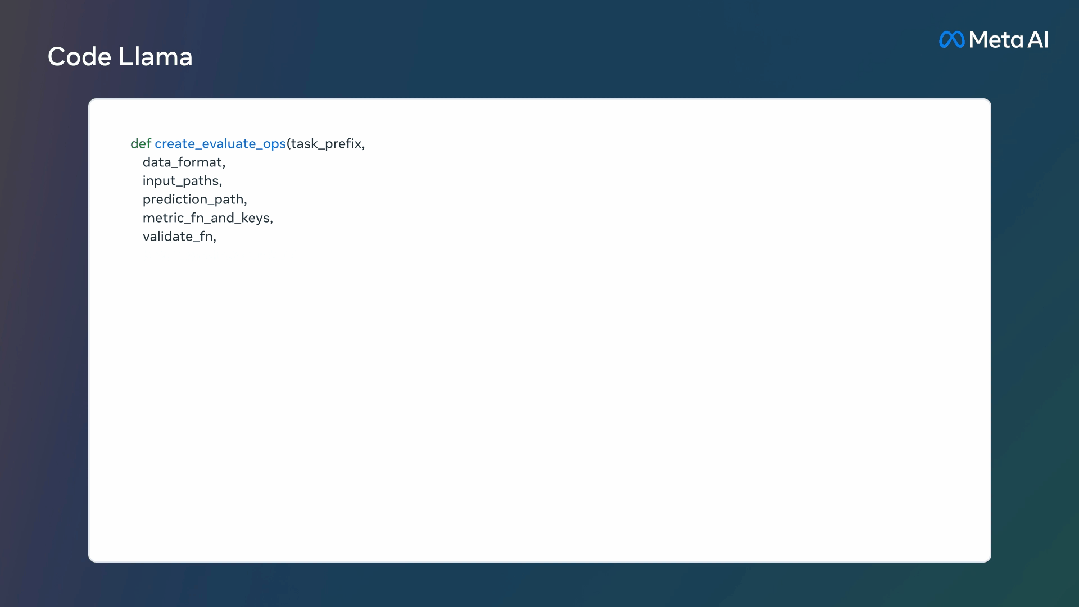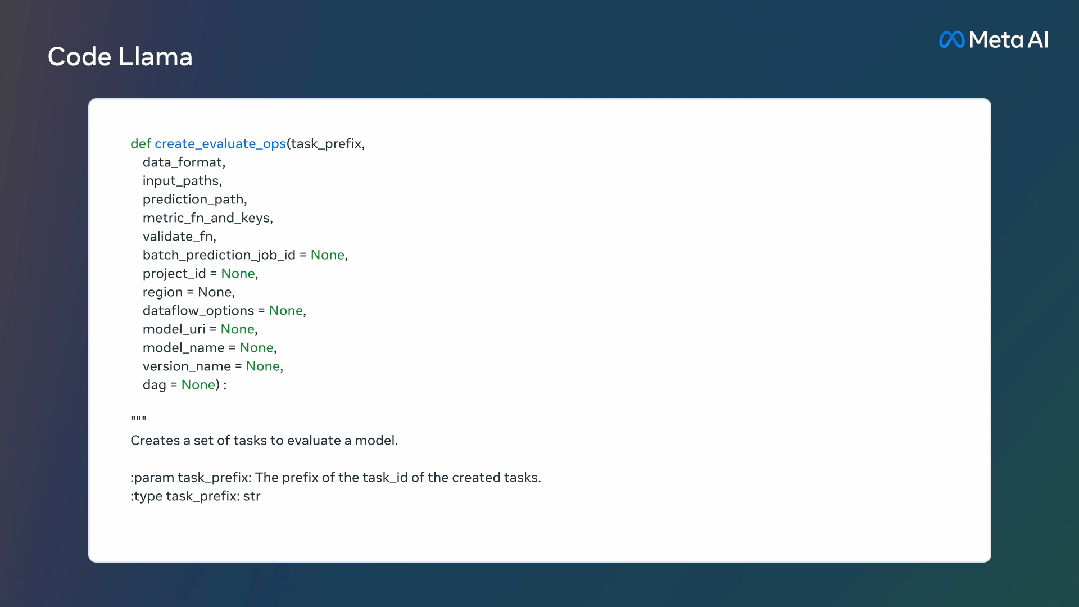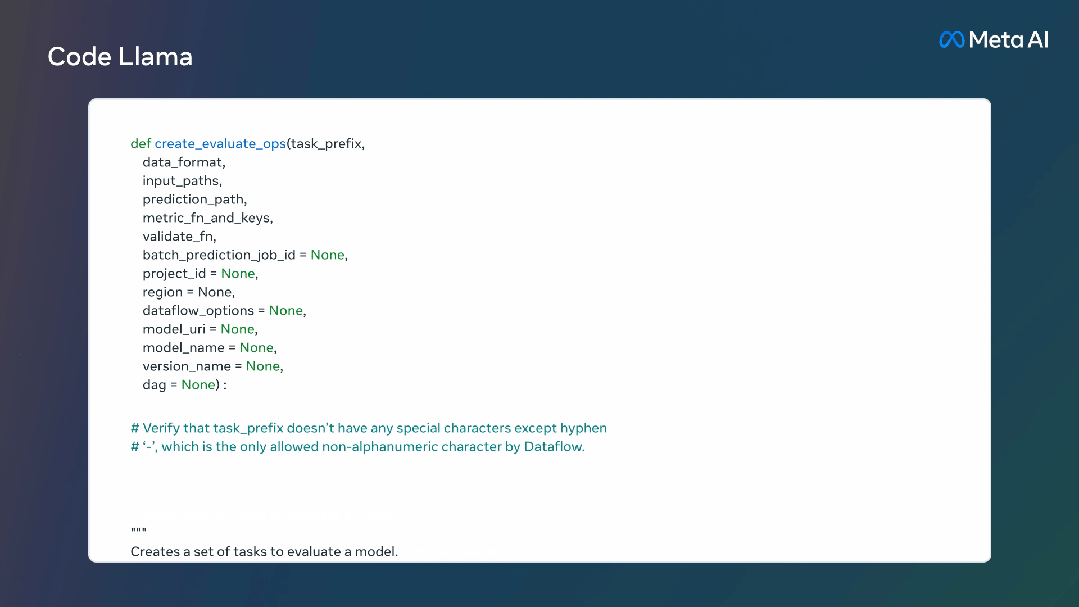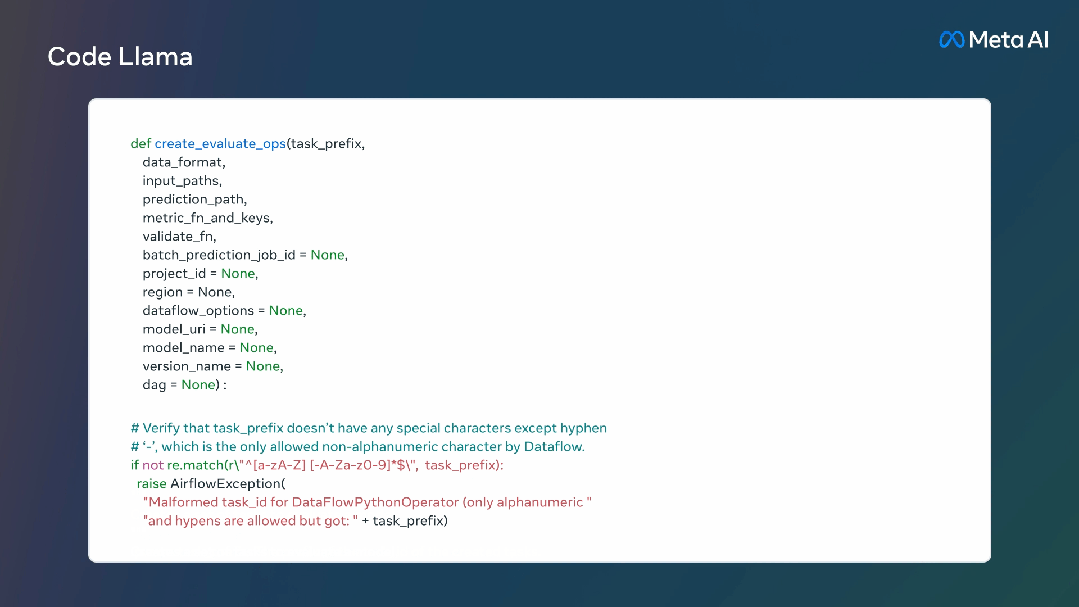
当开发人员需要Debug大量代码时,他们可以将整个代码片段的直接喂给模型。
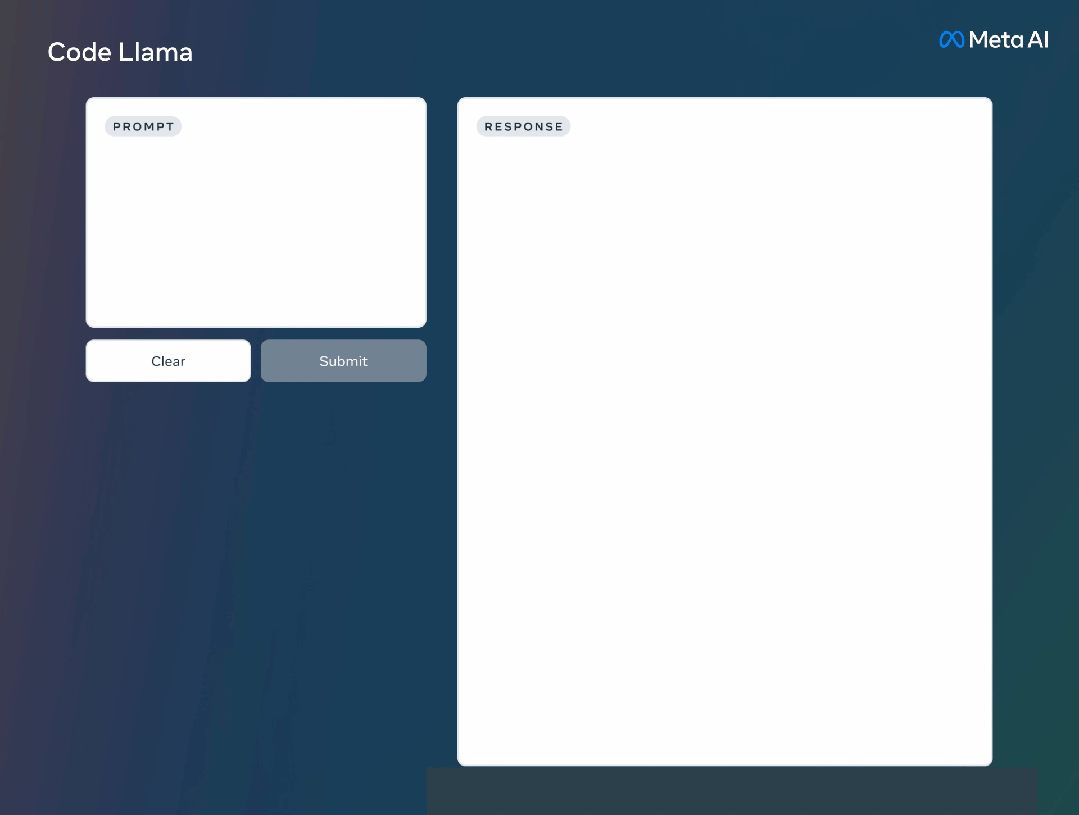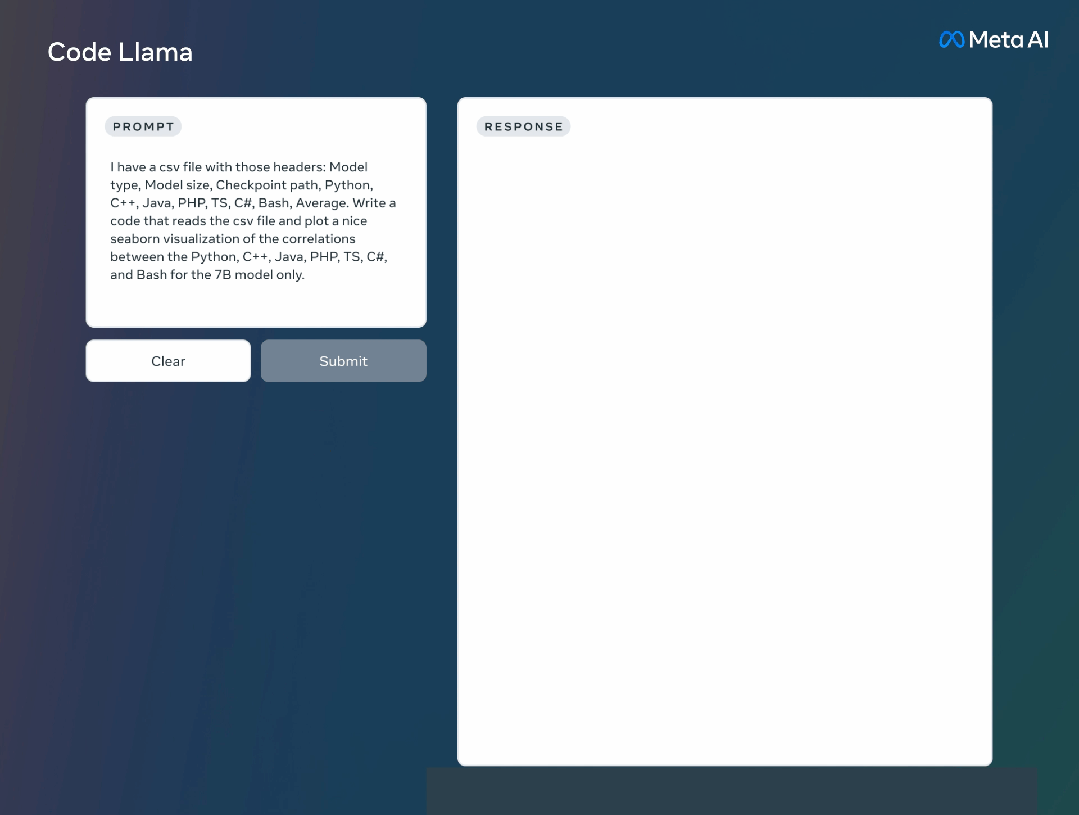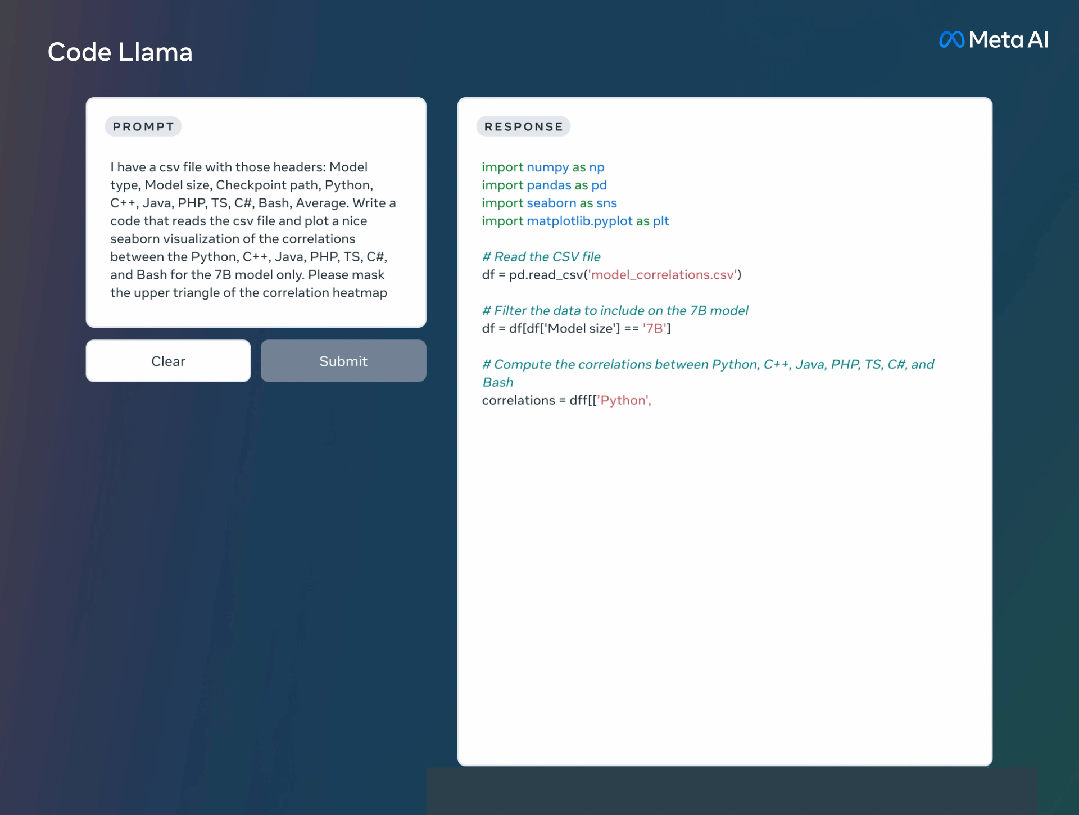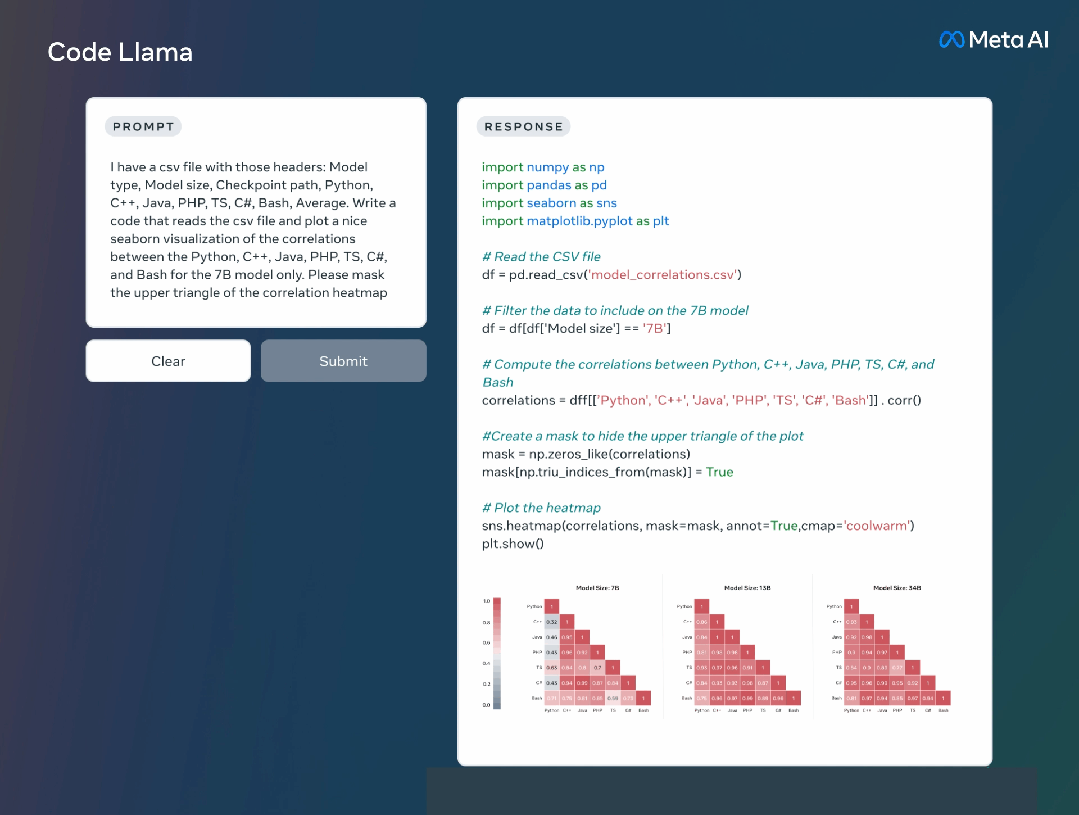
此外,Meta还进一步微调了Code Llama的两个子版本:
Code Llama - Python和Code Llama - Instruct。
Code Llama - Python是用Code Llama在100B的Python代码token上进一步微调的产物。
由于Python是代码生成任务中最常用的语言,并且Python和PyTorch在AI社区中具有举足轻重的地位,专门训练一个能对Python提供更好支持的模型能够大大增强模型的实用性。
而Code Llama - Instruct则是经过指令微调和对齐的Code Llama。
Meta将「自然语言指令」喂给了模型,并且给出了期望的输出。这个过程使得模型更擅长理解人类提示的预期结果。
Meta建议在使用Code Llama-Instruct进行代码生成任务,因为Code Llama - Instruct经过微调后,可以生成更加有用且更加安全的自然语言回复。
Meta不建议直接使用Code Llama或Code Llama - Python来执行一般的自然语言任务,因为这两个模型的设计初衷都不是遵循自然语言指令。
而且Code Llama也只专门用于代码相关的任务,不适合作为其他任务的基础模型。
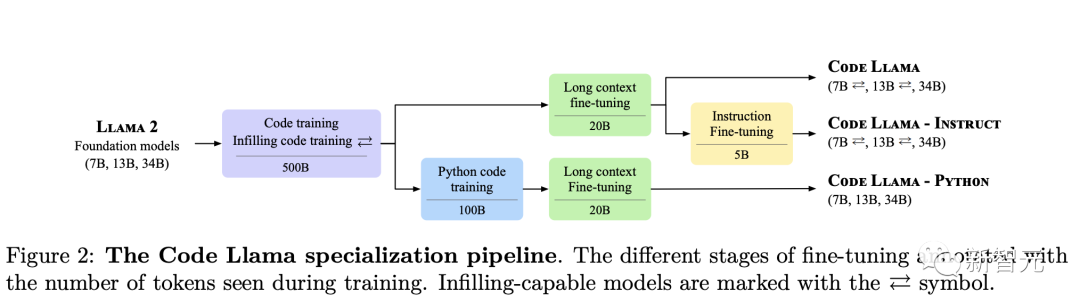
刷新SOTA,碾压开源专用代码模型
Code Llama表现如何?
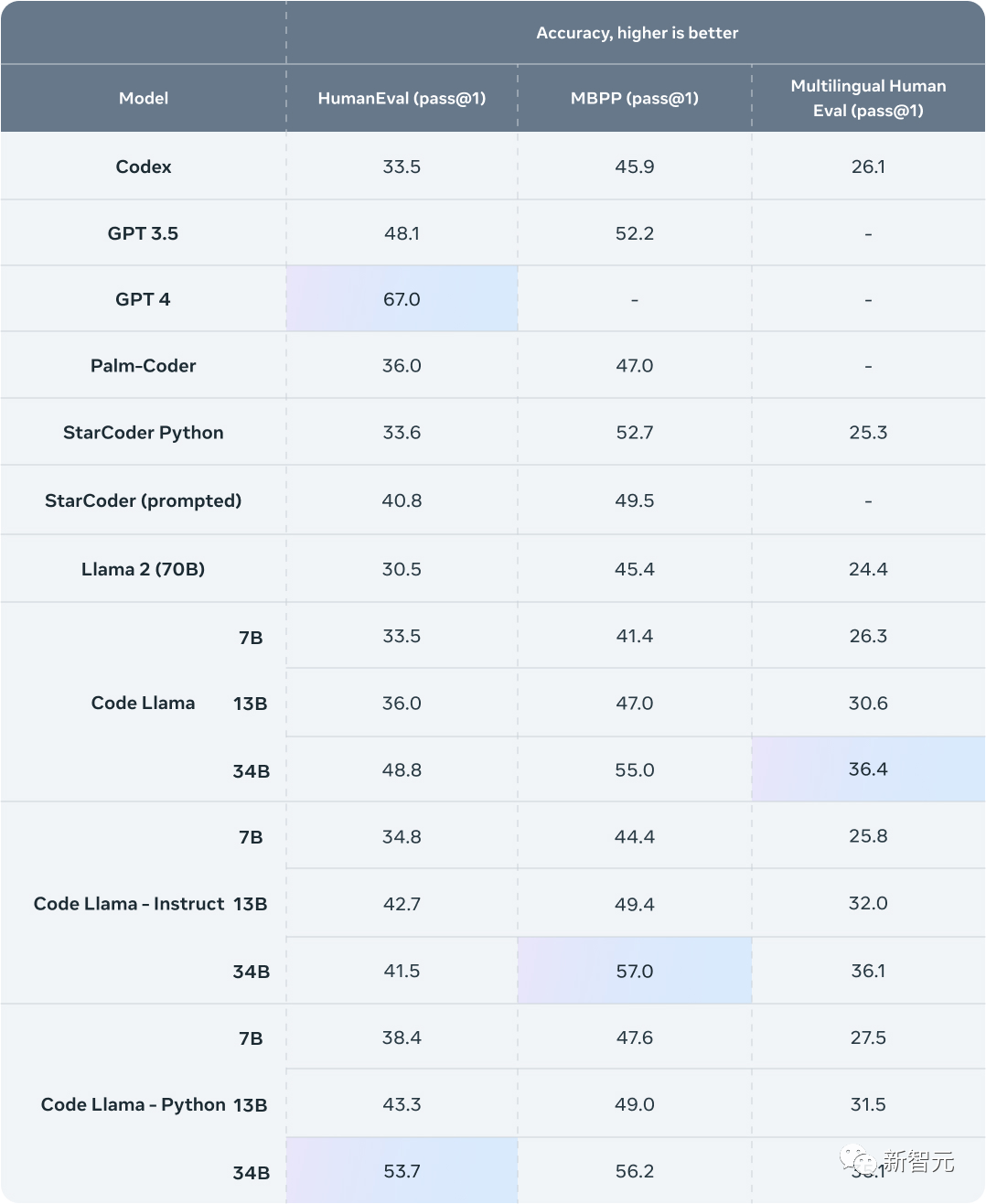
Meta采用了了两个流行的编码基准测试:HumanEval和Mostly Basic Python Programming(MBPP)。
HumanEval是测试模型根据文档字符串完成代码的能力,而MBPP测试模型根据描述编写代码的能力。
结果显示,Code Llama的性能优于开源代码专用LLM,并且超越了Llama 2。
Code Llama 34B在HumanEval上得分为53.7%,在MBPP上得分为56.2%,与ChatGPT几乎打平。
同样,Code Llama作为大模型,同样存在不可知的风险。
为了负责任地构建AI模型至关,Meta在发布Code Llama之前,采取了多项措施,包括红队测试。
研究人员对Code Llama生成恶意代码的风险进行了定量评估。

通过创建试图引导生成具有明确意图的恶意代码的提示,将Code Llama对这些提示的响应与ChatGPT(GPT3.5 Turbo)的响应进行了评分比较。
结果表明,Code Llama 给出了更安全的响应。
代码开源
今天,Meta也发布了Code Llama源代码,由此整个社区都可以评估其能力,发现问题,并修复漏洞。

模型下载
要下载模型权重和标记器,请访问Meta AI网站并接受许可。
一旦请求被批准,将会在电子邮件收到一个URL。然后运行download.sh脚本,在提示开始下载时传递提供的URL。确保复制URL文本,不要使用右键单击URL时的「复制链接地址」选项。
如果复制的URL文本以:https://download.llamameta.net开头,则复制正确。如果复制的URL文本以:https://l.facebook.com开头,则复制错误。
先决条件:确保你已安装wget和md5sum。然后运行脚本:bash download.sh。
请记住,链接会在24小时和一定数量的下载后过期。如果你开始看到诸如403: Forbidden之类的错误,你可以随时重新请求链接。
设置
在具有PyTorch/CUDA可用的conda环境中,克隆repo并在顶级目录中运行:
pip install -e .
推理
不同的模型需要不同的MP值:
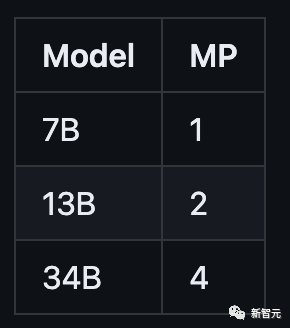
所有模型都支持高达100,000个token的序列长度,但Meta会根据max_seq_len和max_batch_size值预先分配缓存。
因此,请根据你的硬件和用例进行设置。
预训练代码模型
Code Llama和Code Llama-Python模型没有微调指令遵循。在提示时,应使预期答案成为提示的自然延续。
有关一些示例,请参阅example_completion.py。为了说明,请参阅下面的命令以使用CodeLlama-7b模型运行它(nproc_per_node需要设置为MP值):
torchrun --nproc_per_node 1 example_code_completion.py \--ckpt_dir CodeLlama-7b/ \--tokenizer_path CodeLlama-7b/tokenizer.model \--max_seq_len 128 --max_batch_size 4
预训练的代码模型是:Code Llama模型CodeLlama-7b、CodeLlama-13b、CodeLlama-34b和Code Llama-Python模型CodeLlama-7b-Python、CodeLlama-13b-Python、CodeLlama-34b-Python。
代码填充
Code Llama和Code Llama-Instruct7B和13B模型能够根据周围环境填充代码。
有关一些示例,请参阅example_infilling.py。可以运行CodeLlama-7b模型以使用以下命令进行填充(nproc_per_node需要设置为MP值):
torchrun --nproc_per_node 1 example_text_infilling.py \--ckpt_dir CodeLlama-7b/ \--tokenizer_path CodeLlama-7b/tokenizer.model \--max_seq_len 192 --max_batch_size 4
预训练的填充模型是:Code Llama模型CodeLlama-7b和CodeLlama-13b以及Code Llama-Instruct模型CodeLlama-7b-Instruct、CodeLlama-13b-Instruct。
指令微调模型
Code Llama-指令模型经过微调遵循指令。
要获得预期的功能和性能,需要遵循chat_completion中定义的特定格式,包括INST和<<SYS>>标记、BOS和EOS token,以及中间的空格和换行符(建议在输入上调用strip()以避免双格)。
你还可以部署额外的分类器来过滤掉被认为不安全的输入和输出。有关如何将安全检查器添加到推理代码的输入和输出的示例,请参阅llama-recipe存储库。
使用CodeLlama-7b-Instruct的示例:
torchrun --nproc_per_node 1 example_instructions.py \--ckpt_dir CodeLlama-7b-Instruct/ \--tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \--max_seq_len 512 --max_batch_size 4
微调指令遵循模型是:Code Llama - Instruct models CodeLlama-7b-Instruct、CodeLlama-13b-Instruct 、 CodeLlama-34b-Instruct 。
负责任使用
Meta的研究论文披露了更多的Code Llama开发细节,以及进行基准测试的具体方法。
论文还包括了模型现有局限的具体信息,遇到的已知挑战,以及Meta采取的应对措施和未来的挑战。
Meta还更新了负责任使用指南,其中包括如何负责地开发下游模型的指导,包括:
定义内容策略和缓解措施
准备数据
对模型进行微调
评估和改进性能
解决输入和输出级别的风险
在用户互动中建立透明度和报告机制
开发人员应该使用代码特定的评估基准来评估他们的模型,并对代码特定用例,针对生成恶意软件、计算机病毒或恶意代码等问题进行安全性研究。
编码生成式AI的未来
Code Llama的设计目标是辅助各个领域的软件工程师的日常工作,可以在研究、工业、开源项目、非营利组织和企业中发挥重要作用。
但是,基础模型和Instruct模型能够发挥作用的领域还远不止这些。
Meta希望Code Llama能激发大众对于Llama 2的进一步开发,成为研究和商业产品创建新的创造性工具。
网友操刀
Code Llama一发布后,已经有人迫不及待跑开了。
Code Llama-34B在4个3090显卡上跑,49ms每token。

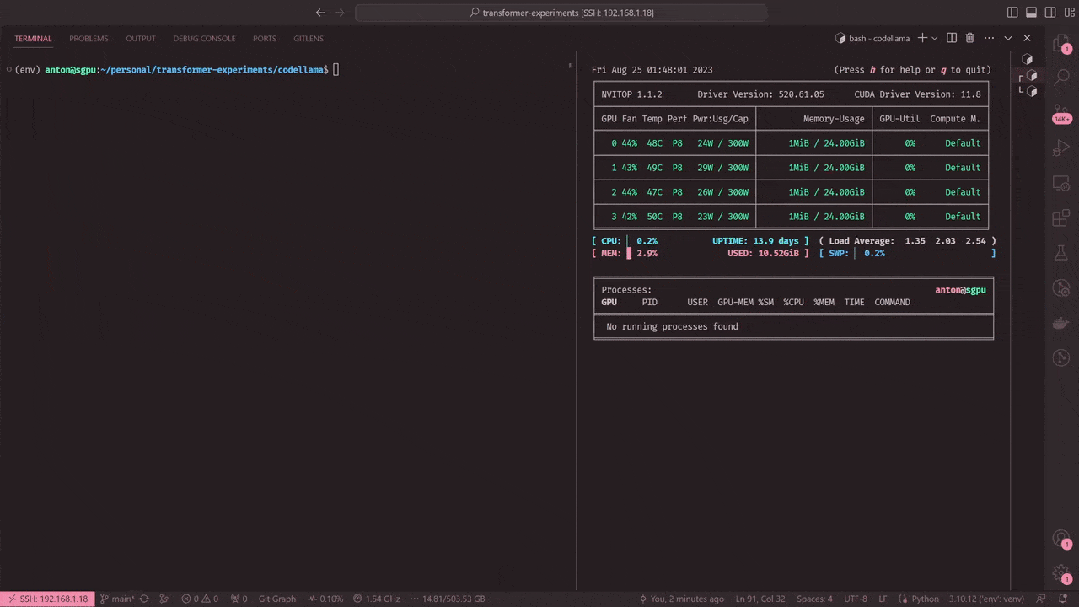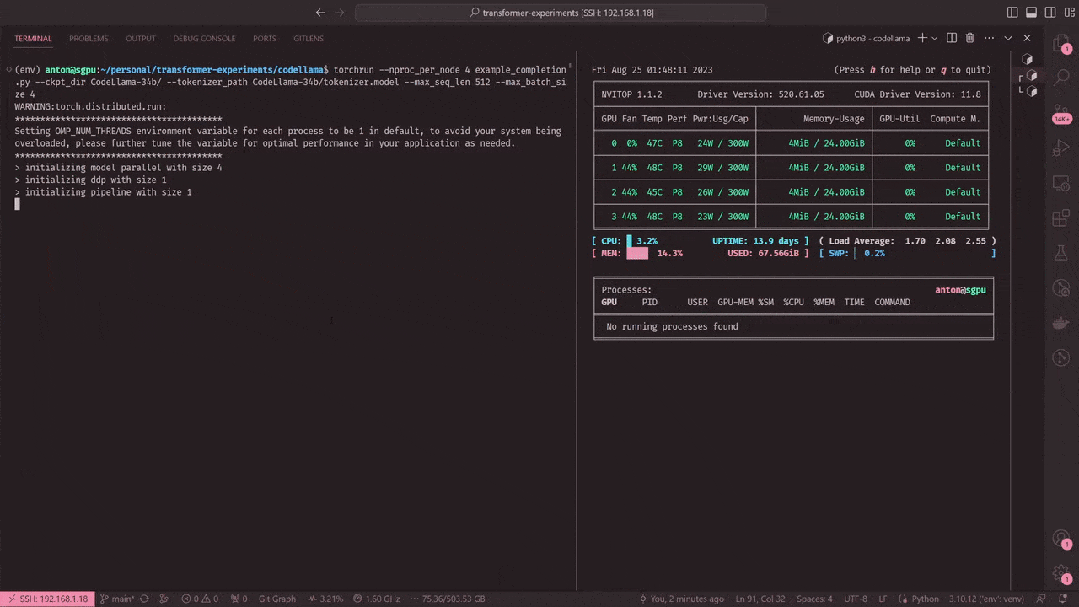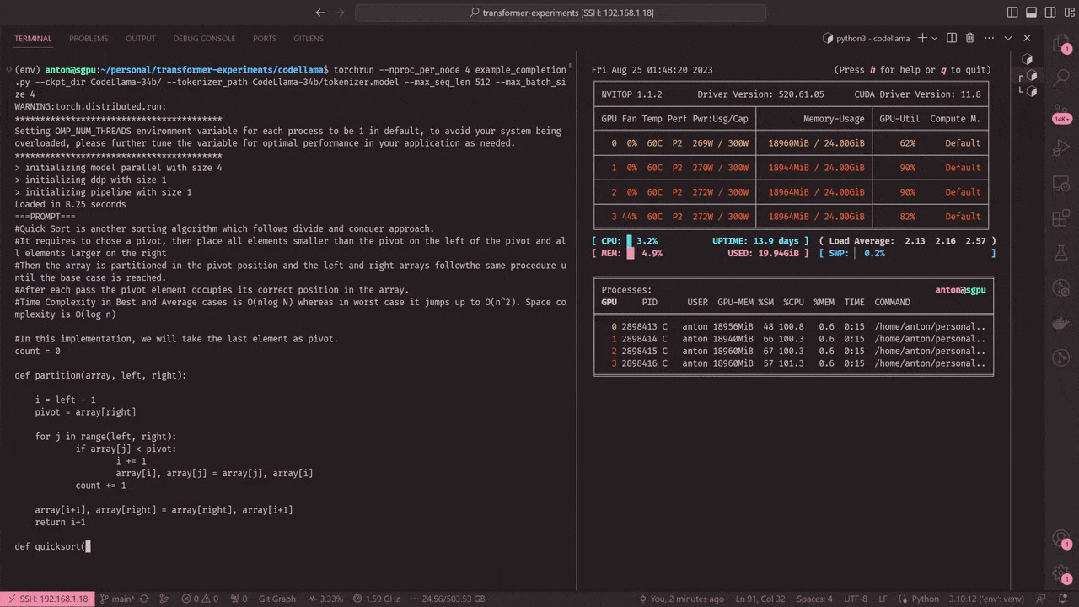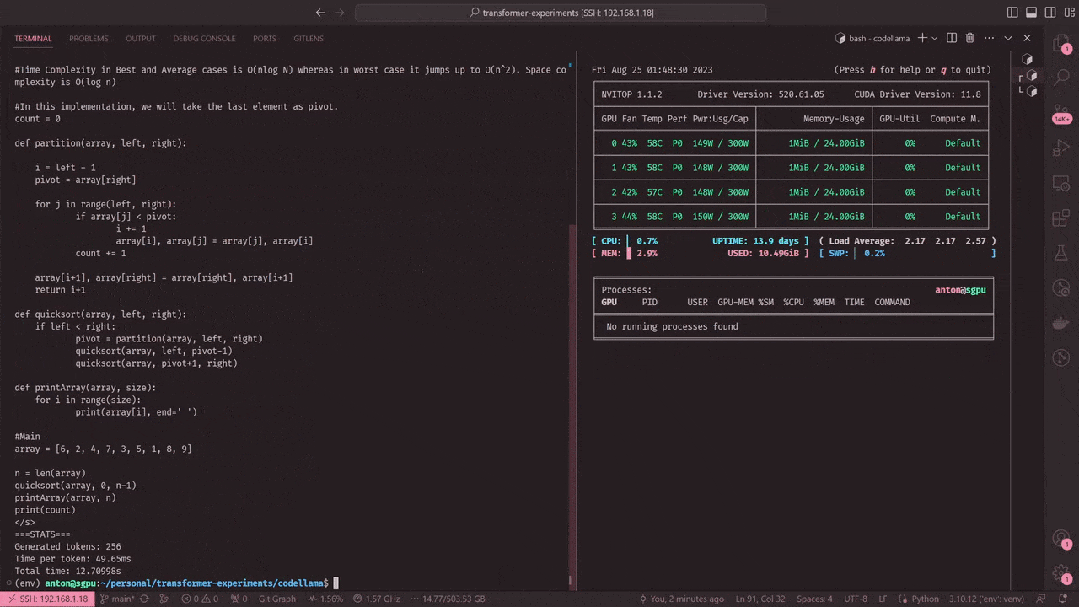
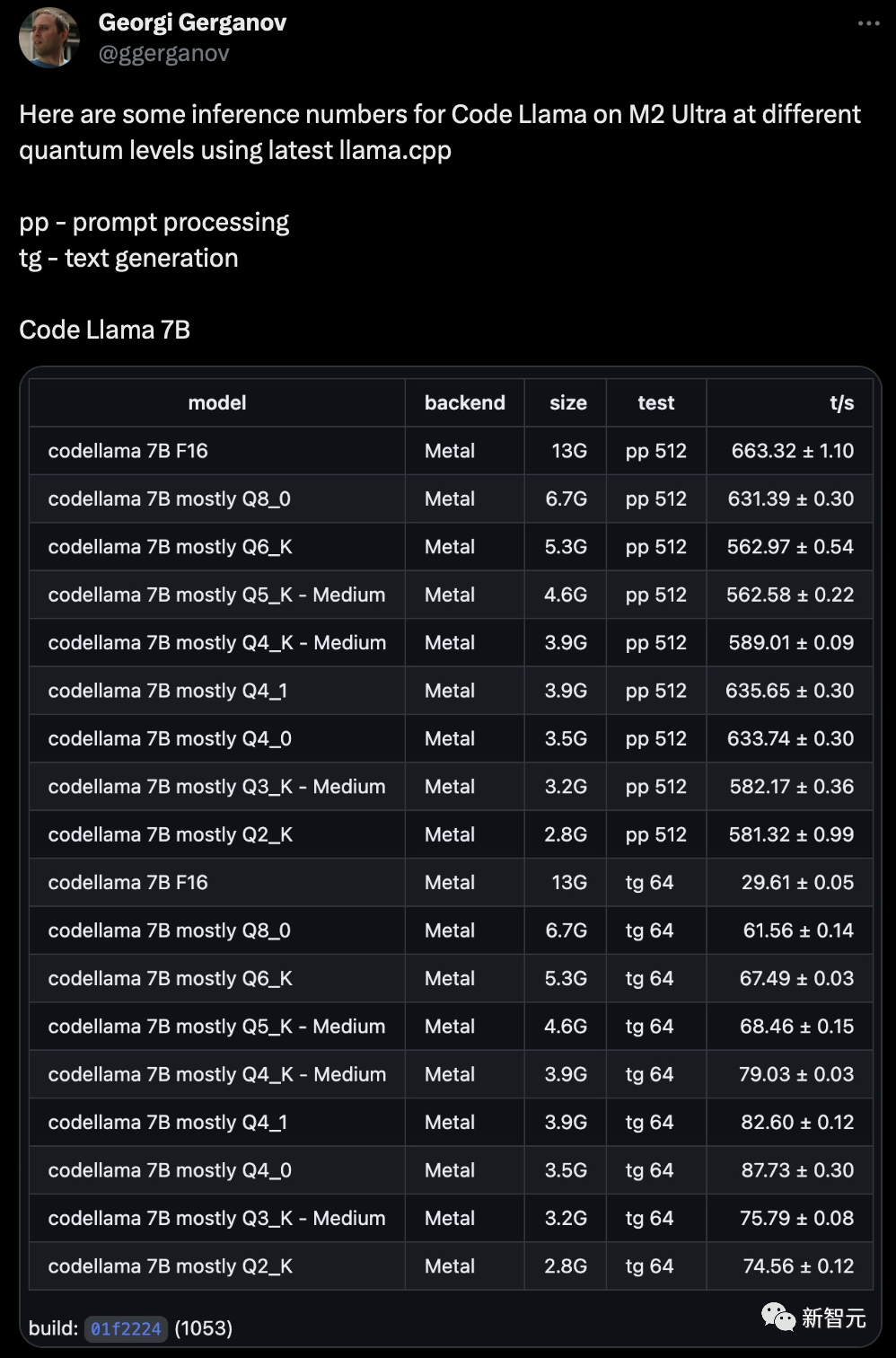
以下是使用最新的llama.cpp在M2 Ultra上对Code Llama不同参数大小模型进行推理的一些数据。
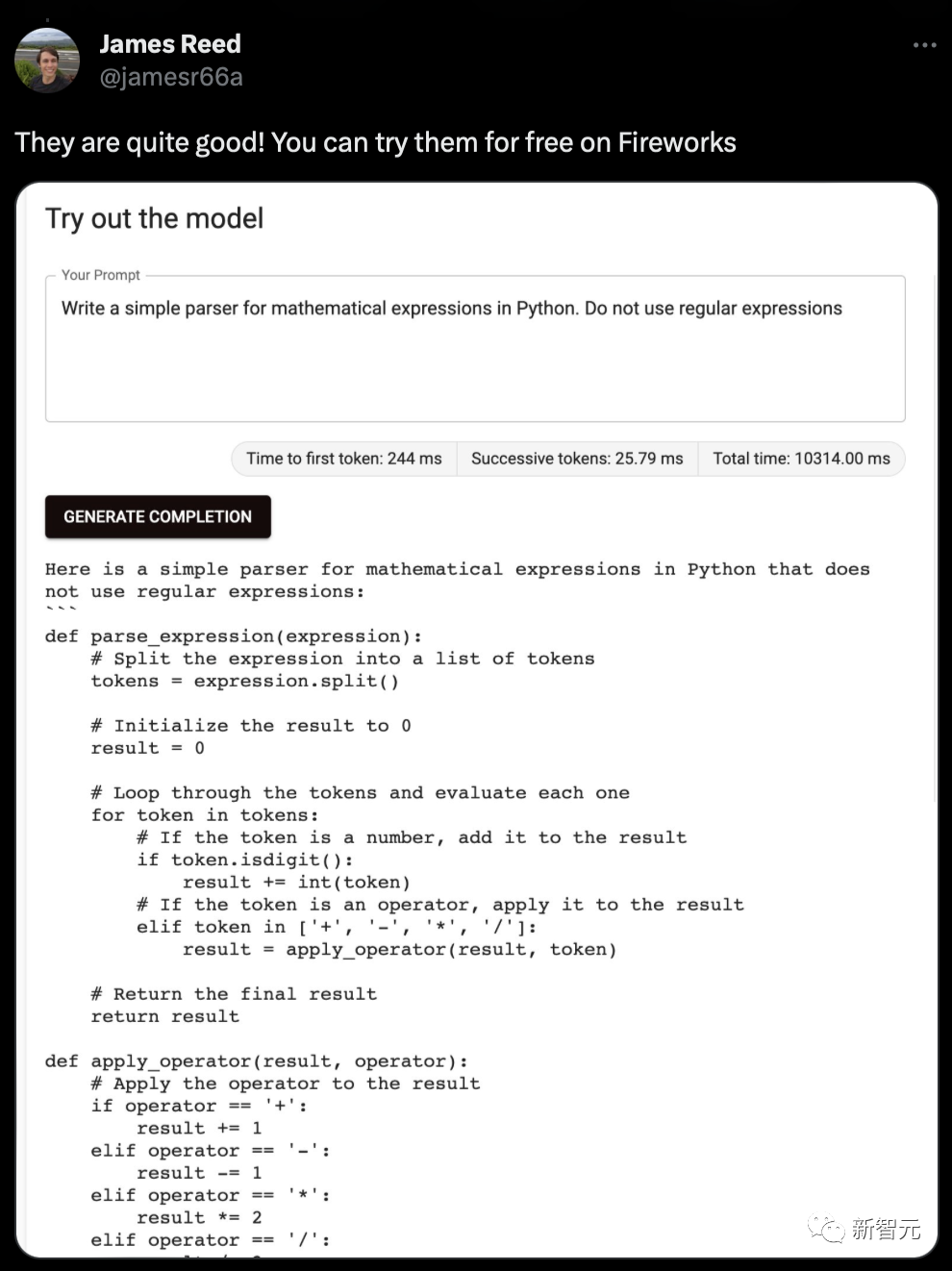
除了代码补全和代码生成,它还能帮助你查找错误或程序配对。


参考资料:
https://ai.meta.com/blog/code-llama-large-language-model-coding/


