
神秘的“无服务器”架构,怎么秃然火了?
如果问云计算有哪些很火技术趋势,那么“无服务器”架构必属其一。但这个词儿很多人乍听都会一脸“懵逼”…

今天,我们把这项神秘的技术,聊深、聊透~~
 到底什么是“无服务器”架构?
到底什么是“无服务器”架构?
“无服务器”架构,又称为“Serverless”,但它并非没有服务器,确切地说,根本离不开服务器。
只是,这种架构可以让使用者,不必再关注“服务器”:❶ 用了多少服务器 ❷ 用了什么样的服务器 ❸ 如何配置和管理这些服务器…
使用者只需要关注业务逻辑、关注代码本身,其它的事情,统统由“云老母亲”搞定!

这,是“无服务器”架构的初衷,也代表了云计算“进化”的最新方向。
从集中式、本地化部署的传统数据中心,到以服务器虚拟化为标志的IaaS服务,再到容器和K8S引领的云原生架构,云厂商们用“保姆式”的托管服务,把用户从IT基础设施的部署和运维中逐步“解放”出来。
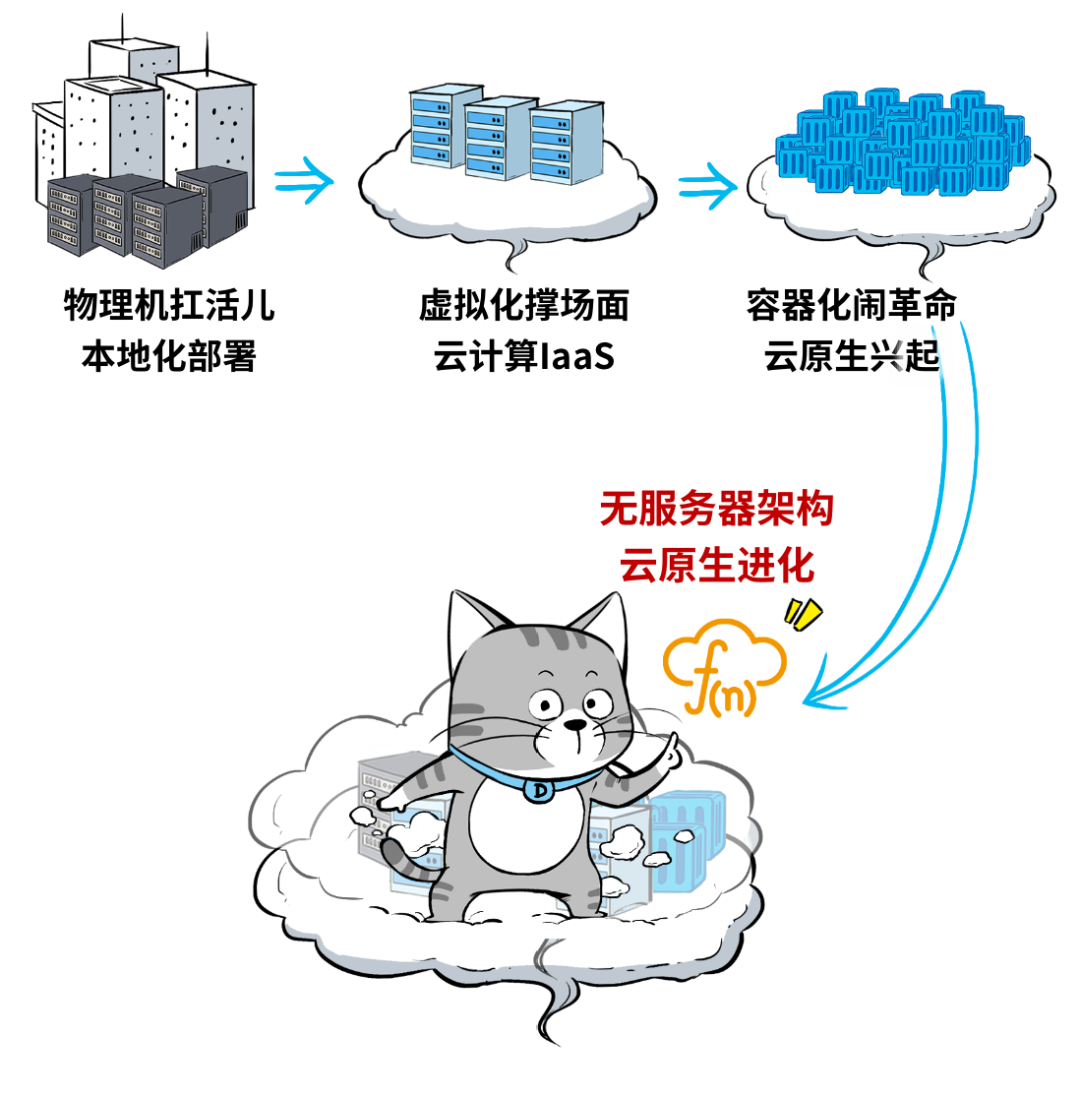
而“无服务器”架构,更是几乎做到了“彻底解放”,用户只需要关注代码和业务流程,其它的统统不用管!(哦,不对,还要管付费 ~)
~)
但典型Serverless服务的收费方式,跟我们以前可大不一样!
从前,租个虚机或者搭个K8S容器集群,不管你用不用,不管你系统开销是100%还是1%,只要租了,就要掏钱(关了机也得收钱 )。
)。
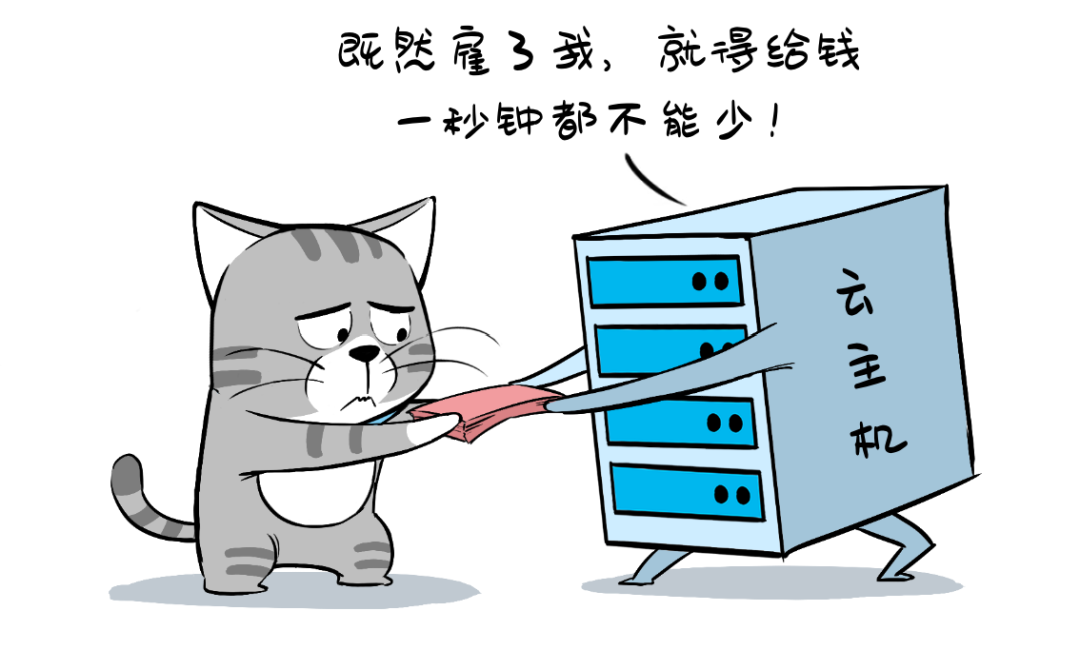
而“无服务器”架构,则采用“事件触发”的方式,来调用服务。你有活儿的时候,让工头(比如API网关)喊它过来搬砖,一堆砖搬完用了几次,那就按次数给工钱。

Serverless服务在搬砖的时候,会不会摸鱼怠工呢?完全不用担心!
Serverless一个更重要的特征,就是“快”——
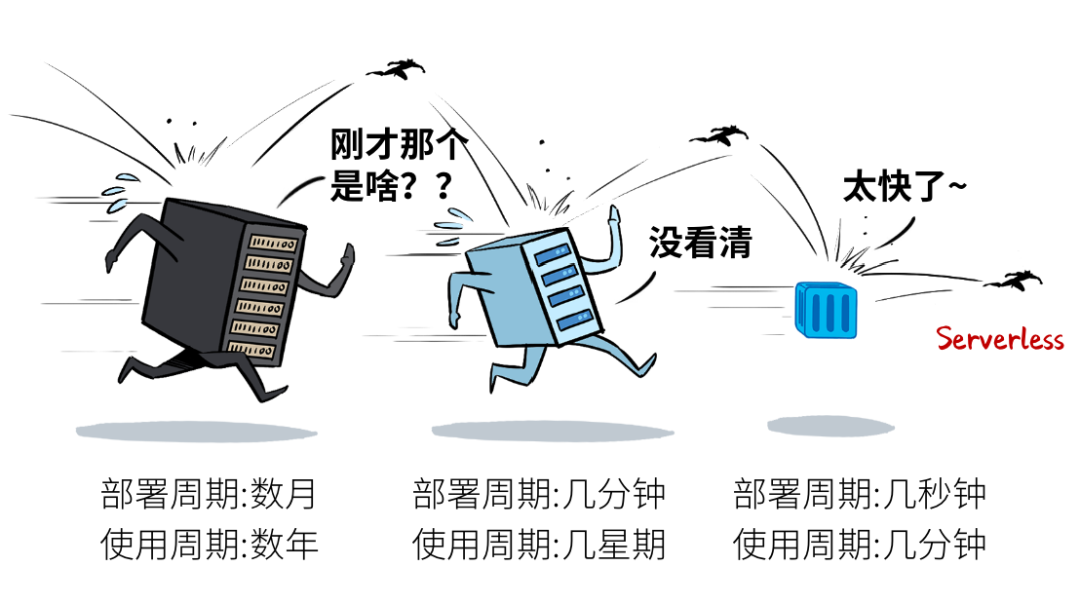
跟前辈们相比,Serverless玩的就是极致弹性,前所未有滴“快”:服务加载,毫秒级!运行周期,秒级!
你还没看清怎么回事,人家已经“嗖嗖嗖”把砖都搬完了。

但有人会担心,砖堆太大,一次搬不完,要是搬个成千上万次,岂不亏大了?还不如雇个云主机“长工”划算,毕竟能保底啊。
好像有点儿道理,但这种思维惯性明显不符合「现代云计算」的趋势,越是云资源用量大的客户、越是深度实践云计算的客户,越强调对云资源的极致调度,绝不多用,绝不滥用。
而成熟的云服务公司,在这方面跟客户的追求是一致的,比如像亚马逊等云大厂,他们的销售和云架构师,都千方百计地想着帮用户省钱,而不是忽悠客户多买点云资源。

落实到产品设计上,也是如此,Serverless服务比容器更加“呼之则来挥之则去”,在计费上也更加科学,一分钱都不让你多花。
比如Amazon Lambda函数计算服务的定价策略,每月前100万次调用,免费!
同时,根据内存占用的不同,会将这种函数计算服务的搬砖能力,分为三六九等,用户评估一下自己的“砖垛”,雇不同档次的人来搬就行了。

干完活,算工钱的时候,总共搬了多少次,是一笔钱,用了多大的内存+累计多少秒,再算一笔钱。两笔钱相加,就是最后的账单。
前面我们说过,Amazon Lambda每月前100万次调用免费,同时,每月40万GB*秒的时长,也免费。
这就意味着,对于很多低频业务来说,你可以完全“白嫖”了!

当然,你有巨量搬砖需求也不用怕,举个例子,你“雇佣”了一个128M内存的Lambda函数,每月运行3000万次,每次运行200毫秒,一个月下来要花多少钱呢?11块6毛3(美金)
而且,这些钱是为你真正使用的资源在买单,一分冤枉钱都没花!
 无服务器架构,都包含什么产品形态?
无服务器架构,都包含什么产品形态?由于Serverless的概念还比较新,所以具体涵盖的范畴,还有很多争议。很多人认为,Serverless等同于FaaS——Function as a Service,也就是函数计算。
Amazon Lambda、Azure Functions、Google Functions 都是典型的函数计算服务,有点像我们以前学编程时用的函数,我们把代码写到里面,平常放在那里备着,调用的时候,传递个参数进去,就给你返回计算结果。

本质上讲,函数计算(FaaS)其实只是计算资源的“无服务器化”交付,并不能代表Serverless架构的全部。
如果你看公有云市场老大“亚马逊”的产品架构,就会发现,它家的Serverless产品非常丰富,除函数计算Lambda外,还包括消息服务、身份认证、数据库…,甚至还包括了著名的对象存储S3。

所以,我们可以这样理解Serverless的范畴:它应该包含FaaS+BaaS,其中负责计算的FaaS是核心。
围绕FaaS函数计算,还需要一系列配套的后端服务(消息推送、数据存储与分析、身份管理、监控与同步…等等),也就是BaaS——Backend as a Service。

再引申总结下,云上所有全托管的、无缝扩展的、基于事件触发和API调用的服务,都可以算作是“无服务器”架构 。按照这个定义,你会发现,Amazon S3对象存储完美符合 。
。
再比如云数据库,我们通常都把云数据库,归入到PaaS的范畴,但Amazon DynamoDB是个另类——

Amazon DynamoDB 完全托管、无缝扩展。容量有多大?根本摸不到底 ,吞吐量支持使用者任意设定,数据的查询和写入全部通过API来完成。所以,它划入了Serverless的行列。
,吞吐量支持使用者任意设定,数据的查询和写入全部通过API来完成。所以,它划入了Serverless的行列。
看到这里,有些同学可能冒出个想法来:这Serverless怎么看着有点像PaaS呢?

关于这个问题,我想引用亚马逊云架构战略副总裁Adrian Cockcroft的一句话:“如果你的PaaS能够有效地在20毫秒内启动实例并只运行半秒,那么就可以称之为Serverless”。
说白了,Serverless还是强调极致的“弹性”,细如发丝的颗粒度和摸不到天花板的扩展上限!
因此,在“无服务器”架构的大趋势下,我们再搞web建站,就不应该是“租台云主机、搭个LAMP架构”的常规思路了,而是要与时俱进,尝试一下“现代应用开发”新套路。
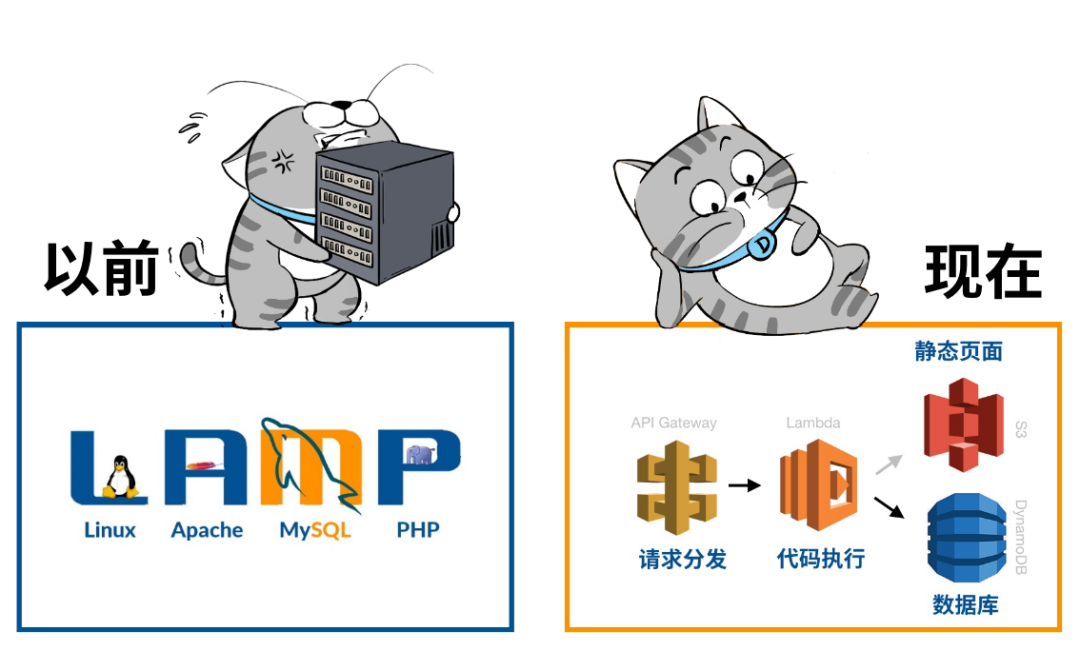
尝完你会发现,搭建了一个庞大的网站,后台竟然不再需要一台web服务器…,惊不惊喜,意不意外?
下面呢,我们就用Amazon Web Services来举例,看看各种Serverless组件是如何配合,来支撑一个“现代应用”。
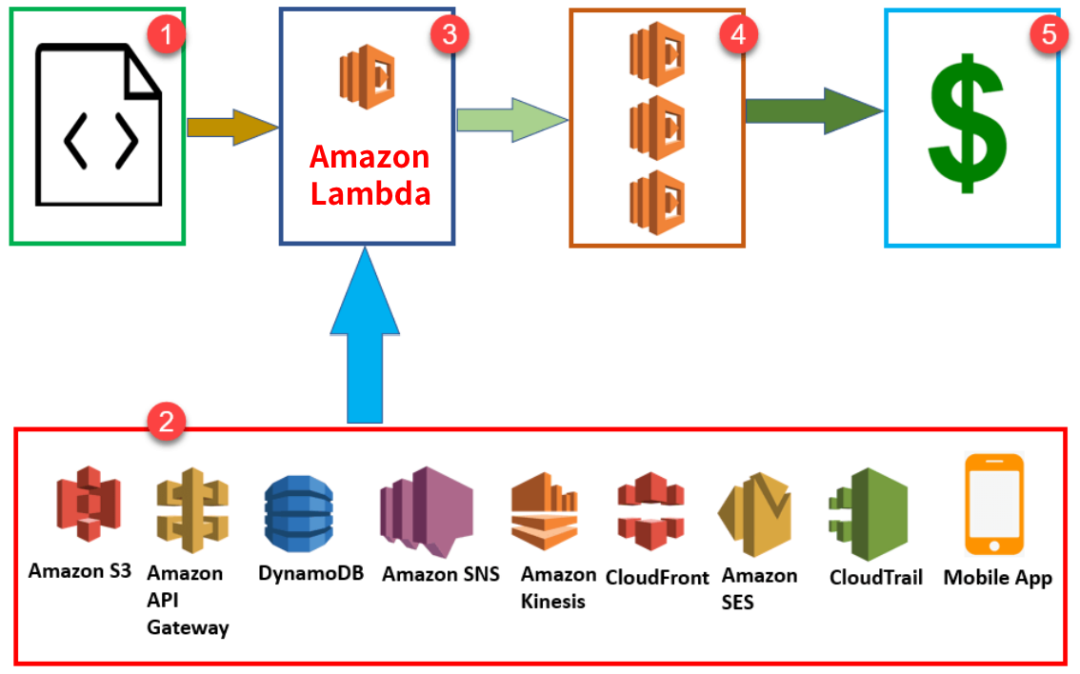
②下面这些五花八门的服务(应用网关、存储/分析、消息服务等),会响应你的各种需求,并“唤醒Lambda干活”,比如API Gateway会响应APP客户端的访问要求,进而去触发Lambda。
③Lambda收好代码,整装待发。
④收到“唤醒”(trigger)需求后,Lambda开始“搬砖”,此时它也会通过API跟下面其他服务互动,比如从S3读写数据,从DynamoDB查询数据……
⑤“搬完砖”才找你收钱,不搬不要钱。
咋样?这种“静如处子动如脱兔”的体验,是不是很棒
 “无服务器”架构无所不能吗?
“无服务器”架构无所不能吗?
就像我们前面“安利”的那样,Serverless架构“成本低、弹性高、0运维”,是云原生时代的“大杀器”。
但Serverless架构也并非无所不能,我们不妨先来看看它最适合干什么?
负载波动大、平均利用率低、业务逻辑和工作流程复杂的场景,都非常适合用Serverless架构。
比如说,IoT业务,大部分时刻,都是“低频请求”,如果全天候“支棱”着一台服务器,守在那里,实在是暴殄天物。
此时如果使用“无服务器”架构,平常不占任何算力资源,有业务请求的时候,立刻触发一个“函数计算”任务,干完活,瞬间释放掉。
当“低频”突然变“高频”,也完全没问题,毫秒级拉起一堆兄弟来干活,即便海量的IoT终端一起来“挤兑”,那都不是事儿,比虚机、容器的AutoScaling更快。
同理,对于一些流量突发型的互联网业务,比如电商秒杀,用Serverless架构来实现,是最科学的。

但是,有一类场景,就不太适合使用函数计算:那就是在线直播类的业务,需要保持一个长连接,持续时间可能长达几个小时。
以Amazon Lambda函数计算为例,每个“计算”任务的最长生存期是15分钟,(15分钟都还没干完,您可以考虑用容器或VM了),所以,就不适合承载这样的业务。

当然,函数计算不合适,并不代表其它Serverless都不合适,这种场景,可以使用AWS Batch或者Fargate创建Serverless容器来运行,时间就没有限制了。
总结一句话,Serverless虽好,但也不要中毒太深、非Serverless不用。在实际生产环境,可以多种架构混搭,各取所长。弹性、突发的任务,交给“无服务器”架构,恒定的重体力劳动,交给“有服务器“架构。
 “无服务器架构”哪家强?
“无服务器架构”哪家强?
Serverless哪家强?那当然是亚马逊“灯塔云”呀
数据库:DynamoDB、Aurora Serverless…
存储与数据处理:S3、Athena、Kinesis、Glue…消息:SQS、SNS…
应用集成:API Gateway、AppSync…管理与工具:IAM、SSO、CloudTrail…
亚马逊自身就是“无服务器架构”的深度实践者,早在2014年就随着Amazon Lambda的推出,提出了“无服务器”的概念,目前他们正在朝着“全面普及无服务器模式”努力。
如今,无服务器架构的招牌式产品“Lambda”,已经走过了7个年头,来看一个统计数据,就知道它有多火。
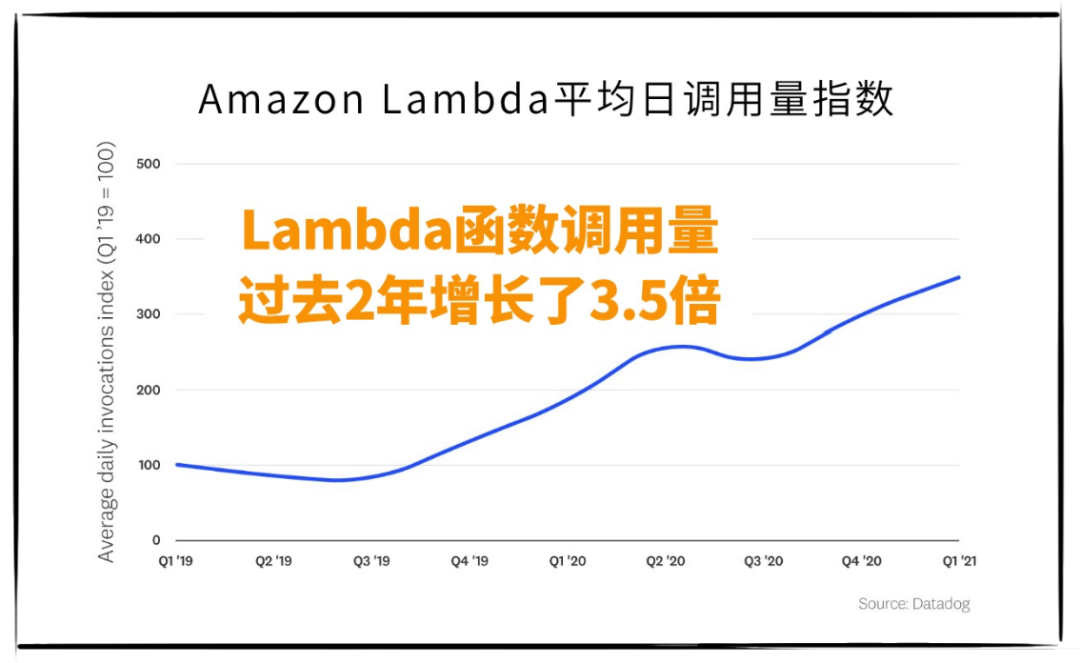
增长的背后,是大量企业开始将核心业务“无服务器化”改造,很多客户日均各函数运行总时长达到900个小时。(而且,没有1分钟、没有1丁点儿资源是在摸鱼哦)
至于深度使用亚马逊“无服务器”架构的客户,就更多了,无法一一列举,索性我就晒个Logo墙吧

“灯塔云”在无服务器架构上的统治力,不止体现在服务全、实践深、客户多等层面,在打消开发者顾虑、帮助用户填坑方面,也操碎了心。
比如,有开发者担心学习成本高,而Lambda就索性一股脑支持了几乎所有的流行语言;有客户担心Serverless不好移植,会被锁定,亚马逊就打通了一大票可移植的开源工具。



