
编程小技巧之 Linux 文本处理命令(二)
点击上方"程序员历小冰",选择“置顶或者星标”
你的关注意义重大!
合格的程序员都善于使用工具,正所谓君子性非异也,善假于物也。合理的利用 Linux 的命令行工具,可以提高我们的工作效率。
本篇文章是《Linux 文本处理命令》 续篇,在前文的基础上再介绍几款有用的 Linux 命令行工具和使用场景。
再啰嗦几句,工具能提供效率,但是有一定的学习曲线和学习成本。很多同学临时想用时,可能会陷入了不会用的尴尬境地,再去网上搜索学习,最终要花费更长时间,还不如使用笨方法处理,这是很多同学不使用这些工具的原因之一。
而且更难的是,思维上改变原有的做事习惯,一个文件中有20多行数据要生成 SQL,好像用手工处理也就是1,2分钟;快捷键记不住,我鼠标移动一下点点也挺快。但是当行数量变大或者复杂性提高时,这些手段的弊端就会显现,逼迫我们去使用正确的手段。
所以,为什么不一开始就使用更快,而且可以处理更加复杂场景的手段呢?
本文主要以两个场景为引子,介绍 join、sort、uniq 命令和 sed 编辑器。
合并两个文件中的关联行
简单说一下场景,有两个文件,里边都是固定格式的行,代表着数据库的一行数据,一个文件是用户相关的数据,有 user_id、username 和 gender 三列,另外一个文件是订单相关的数据,有order_id、price、user_id,time四行,现在要按照 user_id 将两个文件按行合并,也就是user_id相同的行组合成一个新行,如下图所示。
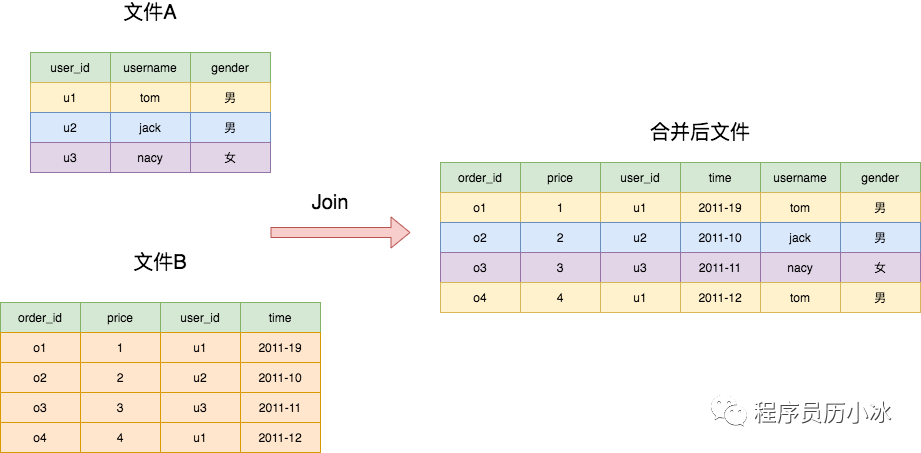
上述两个文件的内容如下所示:
// order.txt user_id是第三列
o1 1 u1 2011-9
o2 2 u2 2011-10
o3 3 u3 2011-10
o4 4 u1 2011-12
// user.txt user_id是第一列
u1 tom 男
u2 jack 男
u3 nacy 女
我们准备使用 join,发现具体命令格式已经忘记了。这时,既可以去网上搜寻,也可以去询问 man

通过 man 你可以了解到 join 的功能描述和参数介绍,一般来说看 DESCRIPTION 一栏下的即可。
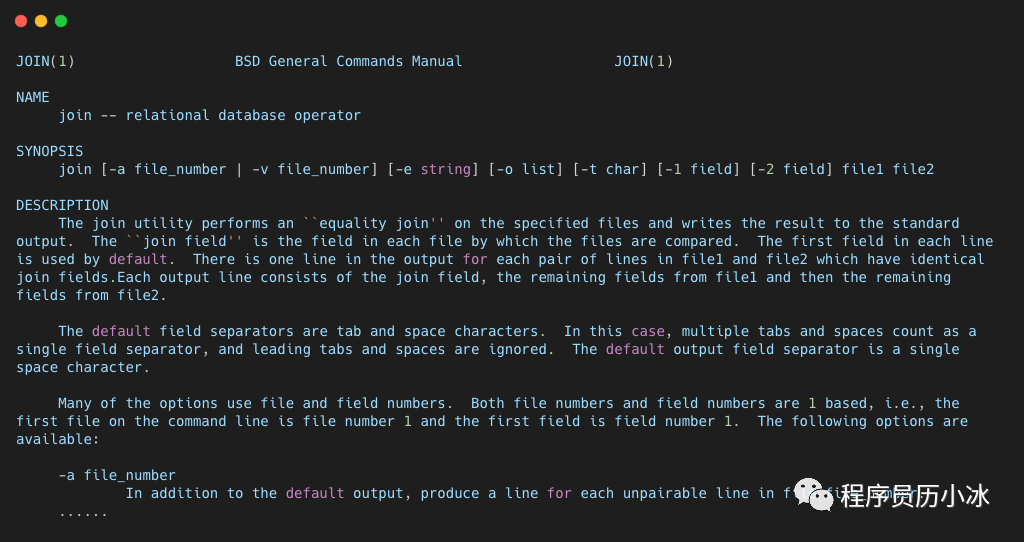
从上边的 man 文档可以很清楚的了解到 join 命令使用 equality join 操作对特定的文件进行合并,并输出到标准输出流上。join filed 就是用于合并文件时进行比较的列,默认是两个文件的第一列。可以使用 -1 和 -2 分别制定第一个文件和第二个文件要对比的列。
$ join -1 3 -2 1 order.txt user.txt
# 指定以order.txt的第三列和user.txt的第一列来进行对比join
u1 o1 1 2011-9 tom 男u2 o2 2 2011-10 jack 男
u3 o3 3 2011-10 nacy 女
会发现,输出中少了一行,order.txt 明明是四行,这是为什么呢?我们再来细看 man 文档,发现了端倪。

两个合并文件的行必须先按照对比列进行排序,否则可能会导致缺失部分行。user.txt 已经按照其第一列排序了,所以,我们只需要使用 sort 命令对 order.txt 按照其第三列进行排序。
sort 命令将以默认的方式将文本文件的第一列以ASCII 码的次序排序,并将结果输出到标准输出。-k 参数可以指定其根据第几列进行排序。
$ sort -k 3 order.txt
# 按照数字排序则使用 -n 如果反序则用 -r
o4 4 u1 2011-12o1 1 u1 2011-9
o2 2 u2 2011-10
o3 3 u3 2011-10
我们将上述两个命令结合起来使用,现将 sort 的结果存入 sorted_order.txt,然后再进行 join,就能得到最终的结果。
$ sort -k 3 order.txt > sorted_order.txt
$ join -1 3 -2 1 sorted_order.txt user.txt
u1 o4 4 2011-12 tom 男
u1 o1 1 2011-9 tom 男
u2 o2 2 2011-10 jack 男
u3 o3 3 2011-10 nacy
另外,上述命令默认的列分隔符都是\t和空格,可以使用 -t 参数来制定字符作为分隔符。
通过上述命令的组合,我们就完成了按照相同列合并两个文件的操作,这也体现了 Linux 的 KISS 思想,每个工具只做一小件事情。
还是基于上述的场景,突然需要统计一下 order.txt 中每个用户购买的订单数量,然后按照订单数进行从大到小排序,这又该如何处理呢?
我们可以将 sort 和 uniq 两个工具结合起来。uniq 命令一般用于检查和删除文件中重复出现的行,我们可以使用它来计算 order.txt 中用户出现的次数。
$ sort -k 3 order.txt | uniq -f 3 -c
# -f 表示按照第三列进行统计
1 o4 4 u1 2011-121 o1 1 u1 2011-9
2 o2 2 u2 2011-10
删除 Markdown 文件中的超链接
另外一个场景是我编辑文章时遇到的,当时 markdown 格式的文档中有很多超链接,也就是[描述](链接)格式,希望全部把超链接去掉,也就是去掉方括号、圆括号和圆括号中的内容。因为文档中还有很多代码,包含很多圆括号语句,所以必须先准确超链接格式,然后再进行替换。

这里,我们可以使用 sed 命令。sed 的全名叫 stream editor 流编辑器,可以使用程序的方式来编辑文本。想要全面学习它的小伙伴可以阅读 《SED 简明教程》或 《sed 手册》,我们这里只介绍一下最基础的功能,向大家展示使用它的可能性。使用 sed 一般要了解正则表达式,推荐《正则表达式30分钟入门教程》。
sed 最简单的使用方法就是替换文本。比如,我们要将上述的 order.txt 中的 u全部替换为user,则可以使用如下命令。
$ sed 's/u/user/g' order.txt
# u是被替换的词 user是替换词
o1 1 user1 2011-9o2 2 user2 2011-10
o3 3 user3 2011-10
o4 4 user1 2011-12
sed 还能轻易实现 sublime 或者 vscode 经常使用的多行光标编辑的功能。比如在 order.txt 的每行前头前添加文字。
$ sed 's/^/#/g' order.txt
# ^在正则表达式中表示一行开头,所以表示是在行开头上加上#字符
#o1 1 u1 2011-9#o2 2 u2 2011-10
#o3 3 u3 2011-10
#o4 4 u1 2011-12
下面,我们直接来看如何将超链接格式转换为纯文本。
$ echo "[链接](http://http://remcarpediem.net/)" | sed -E "s/\[(.*)]\(.*\)/\1/g"
链接
首先,识别[描述](链接) 格式的正则表达式是\[.*\]\(.*\),其中 \[和\( 分别表示匹配文本的[和( 符号。. 表示任何单个字符,*表示某个字符出现了0次或多次, 二者组合 .* 则表示出现0次或者多次任何字符。
综上,上述正则表达的含义就是先出现一个[,再出现0次或者多次任意字符,在出现一个],在出现一个(,在出现0次或者多次任意字符,最后出现一个)。
其次,我们希望用[描述]中的描述文本来替换整个超链接文本,所以需要先识别出方括号中的内容,则需要将其用()单独括起来,表示一个子表达式,也就是\[(.*)\]\(.*\)。
最后,sed 的 s///g 模式下,s 表示替换模式,g 表示匹配每一行有行首到行尾的所有字符,加 g 则一行有多个链接可以匹配处理,不加只能匹配第一个。\1代表第一个子表达式,也就是方括号中的描述内容。
-关注我
推荐阅读
感谢搓一下”在看“ 