
澎湃新闻网站全站新闻爬虫及各大新闻平台聚合爬虫发布
点击上方 月小水长 并 设为星标,第一时间接收干货推送
idea of startproject
对于 web 开发者而言,目前各大新闻门户网站,新浪新闻,百度新闻,腾讯新闻,澎湃新闻,头条新闻并没有提供稳定可用的 feed api。
对于 nlper,缺乏足够的新闻语料数据集来供训练。
对于新闻传播/社会学/心理学等从业者,缺乏获取新闻数据的简单易用途径来供分析。
如果上面三点是某见识所限,其实并不存在的话,第 4 点,则是某的私心,某以为互联网的记忆太短了,热搜一浪盖过一浪,所以试图定格互联网新闻的某些瞬间,最后会以网站的形式发布出来。
project 的 Github:https://github.com/Python3Spiders/AllNewsSpider
澎湃新闻爬虫
全自动爬取澎湃新闻全站新闻内容,包括时事、财经、思想、生活四大 channel 。
速度较快,容错高,对各种异常做了对应处理,目前开源的 pyd 测试抓取 w 级数据正常(如果碰到新异常,请提 issue)。
字段齐全,包括 recode_time(该条新闻被抓取的时间)、news_url 以及其他各个新闻的必要字段,共计 12 个。
将仓库 pengpai 文件夹下的 pengpai_news_spider.pyd 文件下载到本地,新建项目,把 pyd 文件放进去
项目根目录下新建 runner.py,写入以下代码即可运行并抓取
import pengpai_news_spider
pengpai_news_spider.main()
https://www.thepaper.cn/newsDetail_forward_10623559 可能是 h5 或者 公众号文章或者 视频之类的说明该条新闻不在我们的目标爬取范围内,不会被保存起来。澎湃新闻.xlsx文件,里面保持了四个 channel 的所有网站上可浏览的文本新闻,一个 channel 对应一个 sheet_name,如下图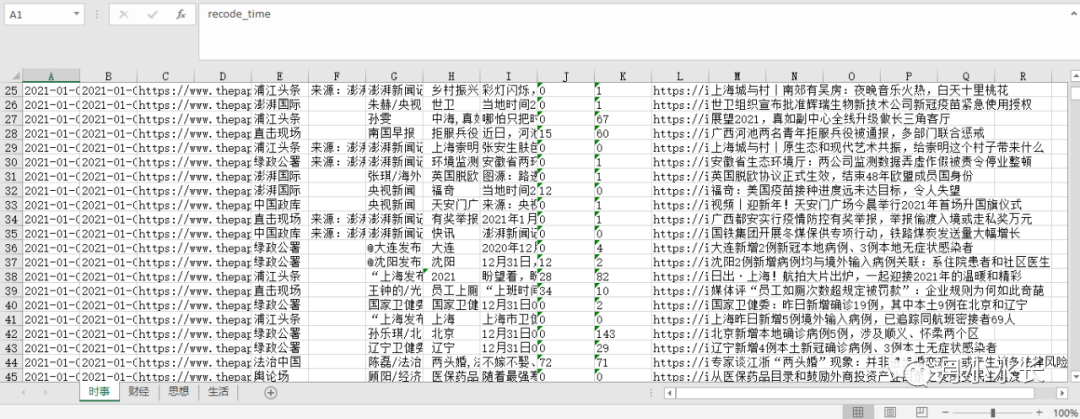
Todo
实现增量更新,初步思路是使用布隆过滤器去 news_url 的重。
阅读原文 即可直达 project 的 Github 地址。
最后,新年第一天,元旦快乐!
评论