
腾讯的 Tendis 能否干掉 Redis,用了什么牛逼的技术呢?

来源:jingjunli,腾讯 IEG 后台开发工程师
Redis 作为高性能缓存被广泛应用到各个业务, 比如游戏的排行榜, 分布式锁等场景。
经过在 IEG 的长期运营, 我们也遇到 Redis 一些痛点问题, 比如内存占用高, 数据可靠性差, 业务维护缓存和存储的一致性繁琐。
由 腾讯互娱 CROS DBA 团队 & 腾讯云数据库团队联合研发的 Tendis 推出了: 缓存版 、 混合存储版 和 存储版 三种不同产品形态, 针对不同的业务需求, 本文主要介绍 混合存储版 的整体架构, 并且详细揭秘内部的原理。
导语
本文首先介绍腾讯 IEG 运营 Redis 遇到的一些痛点问题, 然后介绍由 腾讯互娱 CROS DBA 团队 & 腾讯云数据库团队联合研发的 Tendis 的三种不同的产品形态。最后重点介绍冷热混合存储版的架构, 并且重点介绍各个组件的功能特性。
背景介绍
Redis 有哪些痛点 ?
在使用的过程中, 主要遇到以下一些痛点问题:
内存成本高
业务不同阶段对 QPS 要求不同 比如游戏业务, 刚上线的新游戏特别火爆, 为了支持上千万同时在线, 需要不断的进行扩容增加机器。运营一段时间后, 游戏玩家可能变少, 访问频率(QPS)没那么高, 依然占用大量机器, 维护成本很高。 需要为 Fork 预留内存 Redis 保存全量数据时, 需要 Fork 一个进程。Linux 的 fork 系统调用基于 Copy On Write 机制, 如果在此期间 Redis 有大量的写操作, 父子进程就需要各自维护一份内存。因此部署 Redis 的机器往往需要预留一半的内存。 缓存一致性的问题 对于 Redis + MySQL 的架构需要业务方花费大量的精力来维护缓存和数据库的一致性。
数据可靠性 Redis 本质上是一个内存数据库, 用户虽然可以使用 AOF 的 Always 来落盘保证数据可靠性, 但是会带来性能的大幅下降, 因此生产环境很少有使用。另外 不支持 回档, Master 故障后, 异步复制会造成数据的丢失。
异步复制 Redis 主备使用异步复制, 这个是异步复制固有的问题。主备使用异步复制, 响应延迟低, 性能高, 但是 Master 故障后, 会造成数据丢失。
Tendis 是什么 ?
Tendis 是集腾讯众多海量 KV 存储优势于一身的 Redis 存储解决方案, 并 100% 兼容 Redis 协议和 Redis4.0 所有数据模型。作为一个高可用、高性能的分布式 KV 存储数据库, 从访问时延、持久化需求、整体成本等不同维度的考量, Tendis 推出了 缓存版 、 混合存储版和 存储版 三种不同产品形态,并将存储版开源。感兴趣的小伙伴 可以去 Github 关注我们的项目: Tencent/Tendis
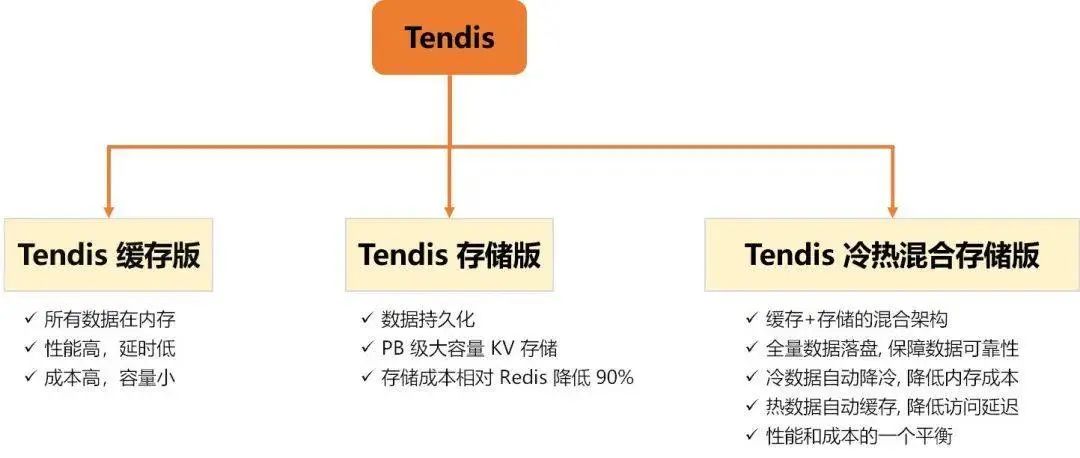
Tendis 缓存版 适用于对延迟要求特别敏感, 并且对 QPS 要求很高的业务。基于社区 Redis 4.0 版本进行定制开发。
Tendis 存储版 适用于大容量, 延迟不敏感型业务, 数据全部存储在 磁盘, 适合温冷数据的存储。Tendis 存储版是腾讯互娱 CROS DBA 团队 & 腾讯云数据库团队 自主设计和研发的开源分布式高性能 KV 存储系统。另外在 可靠性、复制机制、并发控制、gossip 实现以及数据搬迁等做了大量的优化, 并且解决了一些 Redis cluster 比较棘手的问题。完全兼容 Redis 协议, 并使用 RocksDB 作为底层存储引擎。
Tendis 冷热混合存储版 冷热混合存储 综合了缓存版和存储版的优点, 缓存层存放热数据, 全量数据存放在存储层。这既保证了热数据的访问性能,同时保证了全量数据的可靠性,同时热数据支持自动降冷。
Tendis 冷热混合存储版 整体架构
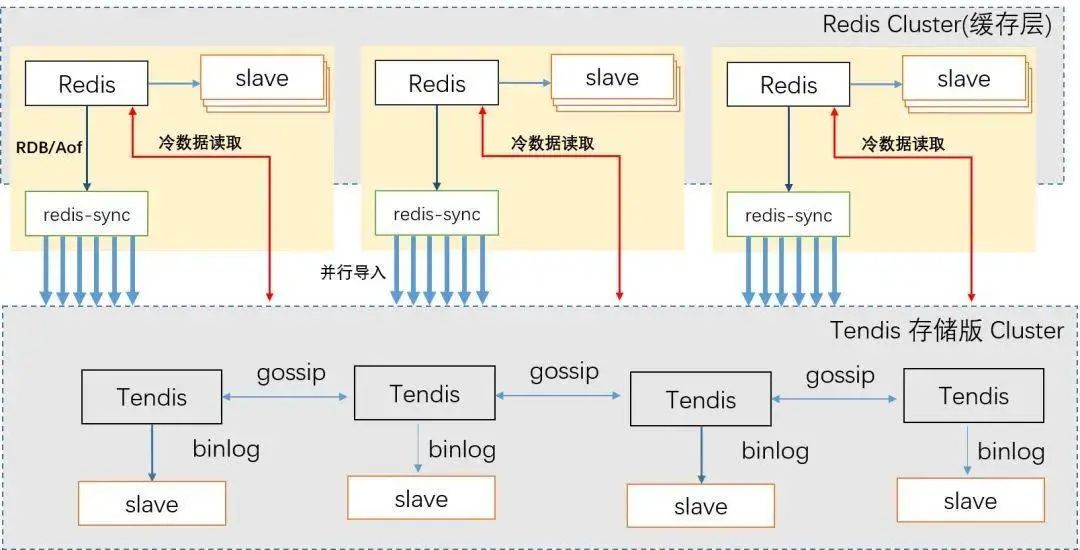
Tendis 冷热混合存储版主要由 Proxy 、缓存层 Redis 、 存储层 Tendis 存储版 和 同步层 Redis-sync 组成, 其中每个组件的功能如下:
Proxy 组件 : 负责对客户端请求进行路由分发,将不同的 Key 的命令分发到正确的分片,同时 Proxy 还负责了部分监控数据的采集,以及高危命令在线禁用等功能。
缓存层 Redis Cluster : 缓存层 Redis 基于 社区 Redis 4.0 进行开发。Redis 具有以下功能: 1) 版本控制 2) 自动将 冷数据从缓存层中淘汰, 将热数据从存储层加载到缓存层; 3) 使用 Cuckoo Filter 表示全量 Keys, 防止缓存穿透; 4) 基于 RDB+AOF 扩缩容方式, 扩缩容更加高效便捷。
存储层 Tendis Cluster : Tendis 存储版 是腾讯基于 RocksDB 自研的 兼容 Redis 协议的 KV 存储引擎, 该引擎已经在腾讯集团内部运营多年, 性能和稳定性得到了充分的验证。在混合存储系统中主要负责全量数据的存储和读取, 以及数据备份, 增量日志备份等功能。
同步层 Redis-sync : 1) 并行数据导入 存储层 Tendis; 2) 服务无状态, 故障重新拉起; 3) 数据自动路由。
Tendis 冷热混合存储的一些重要特性介绍:
缓存层 Redis Cluster和存储层 Tendis Cluster分别进行扩缩容, 集群自治管理等。冷数据自动降冷, 降低内存成本; 热数据自动缓存, 降低访问延迟
缓存层 Redis Cluster
冷热混合存储缓存层 Redis 在社区版的基础上增加了以下功能:
版本控制 冷热数据交互 Cuckoo Filter 避免缓存穿透 智能淘汰算法 基于 RDB+AOF 扩缩容
下面分别对这几个特性进行详细的讲解。
版本控制
首先基于社区版 Redis 改动是版本控制。我们为每个 Key 和 每条 Aof 增加一个 Version , 并且 Version 是单调递增的。在每次更新/新增一个 Key 后, 将当前节点的 Version 赋值给 Key 和 Value, 然后对全局的 Version++; 如下所示, 在 redisObject 中添加 64bits, 其中 48bits 用于版本控制。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
/* for hybrid storage */
unsigned flag:4; /* OBJ_FLAG_... */
unsigned reserved:4;
unsigned counter:8; /* for cold-data-cache-policy */
unsigned long long revision:REVISION_BITS; /* for value version */
void *ptr;
} robj;
引入版本控制主要带来以下优势:
增量 RDB
社区版 Redis 主备在断线重连后, 如果 slave 发送的 psync_offset 对应的数据不在当前的 Master 的 repl_backlog 中, 则主备需要重新进行全量同步。再引入 Version 之后, slave 断线重连, 给 Master 发送 带 Version 的
PSYNC replid psync_offset version命令。如果出现上述情况, Master 将大于等于 Version 的数据生成增量 RDB, 发给 Slave, 进而解决需要增量, 同步比较慢的问题。
Aof 的幂等
如果同步层 Redis-sync 出现网络瞬断(短暂的和缓存层或者存储层断开), 作为一个无状态的同步组件, Redis-sync 会重新拉取未同步到 Tendis 的增量数据, 重新发送给 Tendis。每条 Aof 都具有一个 Version, Tendis 在执行的时候仅会执行比当前 Version 大的 Aof, 避免 aof 执行多次导致的数据不一致。
冷热数据交互
冷数据的恢复指当用户访问的 Key 不在缓存层, 需要将数据从存储层重新加载到缓存层。数据恢复这里是缓存层直接和存储层直接交互, 当冷 Keys 访问的请求比较大, 数据恢复很容易成为瓶颈, 因此为每个 Tendis 节点建立一个连接池, 专门负责与这个 Tendis 节点进行冷热数据恢复。
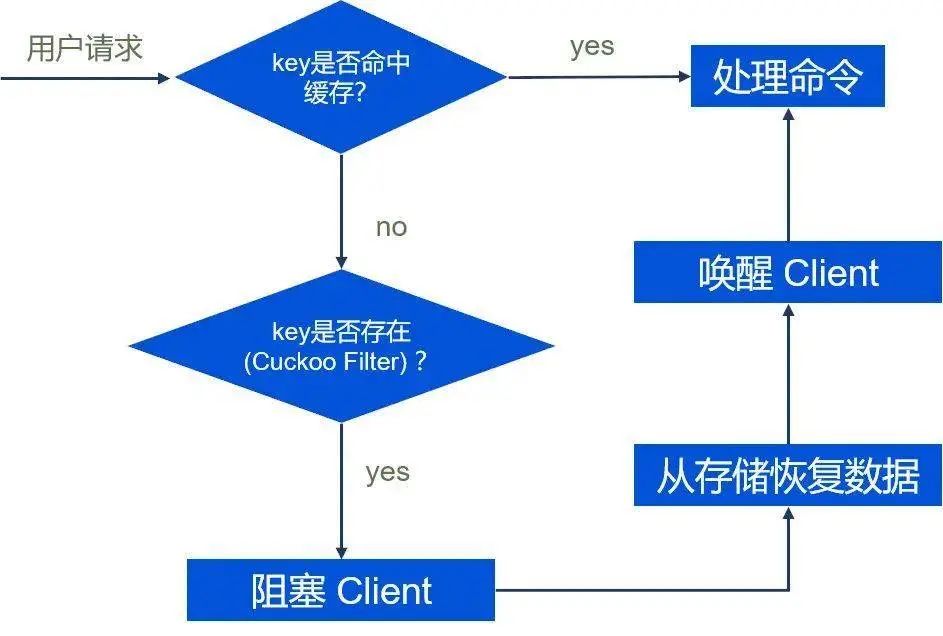
用户访问一个 Key 的具体流程如下:
首先判断 Key 是否在缓存层, 如果缓存层存在, 则执行命令; 如果缓存层不存在, 查询 Cuckoo Filter, 判断 Key 是否有可能在存储层; 如果 Key 可能在存储层, 则向存储层发送 dumpx dbid key withttl命令尝试从存储层获取数据, 并且阻塞当前请求的客户端;存储层收到 dumpx , 如果 Key 在存储层, 则向缓存层返回 RESTOREEX dbid key ttl value; 如果 Key 不在存储层(Cuckoo Filter 的误判), 则向缓存层返回DUMPXERROR key;存储层收到 RESTOREEX 或者 DUMPXERROR 后, 将冷数据恢复。然后就可以唤醒阻塞的客户端, 执行客户端的请求。
Key 降冷 与 Cuckoo Filter
这里主要讲解混合存储从 1:1 版的缓存层缓存全量 Keys, 到 N:M 版的缓存层将 Key 和 Value 同时驱逐的演进, 以及我们引入 Cuckoo Filter 避免缓存穿透, 同时节省大量内存。
Key 降冷的背景介绍 2020 年 6 月份上线的 1:1 版的冷热混合存储, 缓存层 Redis 存储全量的 Keys 和热 Values(All Keys + Hot values ), 存储层 Tendis 存储全量的 Keys 和 Values(All Keys + All values )。在上线运行了一段时间后, 发现全量 Keys 的内存开销特别大, 冷热混合的收益并不明显。为了进一步释放内存空间, 提高缓存的效率, 我们放弃了 Redis 缓存全量 Keys 的方案, 驱逐的时候将 key 和 Value 都从缓存层淘汰。 Cuckoo Filter 解决缓存击穿和缓存穿透 如果缓存层不存储全量的 Keys, 就会出现缓存击穿和缓存穿透的问题。为了解决这一问题, 缓存层引入 Cuckoo Filter 表示全量的 keys 。我们需要一个支持删除、可动态伸缩并且空间利用率高的 Membership Query 结构, 经过我们的调研和对比分析, 最终选择 Dynamic Cuckoo Filter。Dynamic Cuckoo Filter 实现 项目初期参考了 RedisBloom 中 Cuckoo Filter 的实现, 在开发的过程中也遇到了一些坑, RedisBloom 实现的 Cuckoo Filter 在删除的时候会出现误删, 最终给 RedisBloom 提 PR(Fix Cuckoo filter compact cause deleted by mistake #260 ) 修复了问题。 Key 降冷的收益 最终采用将 Key 和 Value 同时从缓存层淘汰, 降低内存的收益很大。比如现网的一个业务, 总共有 6620 W 个 Keys , 在缓存全量 Keys 的时候 占用 18408 MB 的内存, 在 Key 降冷后 仅仅占用 593MB 。
智能淘汰/加载策略
作为冷热混合存储系统, 热数据在缓存层, 全量数据在存储层。关键的问题是淘汰和加载策略, 这里直接影响缓存的效率, 细分主要有两点: 1) 当缓存层内存满时, 选择哪些数据淘汰; 2) 当用户访问存储层的数据时, 是否需要将其放入缓存层 。
首先介绍混合存储的淘汰策略, 主要有以下两个淘汰策略:
maxmemory-policy 当缓存层 Redis 内存使用到达 maxmemory, 系统将按照 maxmemory-policy 的内存策略将 Key/Value 从缓存层驱逐, 释放内存空间。(驱逐是指将 Key/Value 从缓存层中淘汰掉, 存储层 和 缓存层的 Cuckoo Filter 依然存在该 Key; ) value-eviction-policy 如果配置 value-eviction-policy, 后台会定期将用户 N 天未访问的 Key/Value 被驱逐出内存;
缓存加载策略 为了避免缓存污染的问题(比如类似 Scan 的访问, 遍历存储层的数据, 将缓存层真正的热数据淘汰, 从而造成了缓存效率低下) 。我们实现缓存加载策略: 仅仅将规定时间内访问频率超过某个阈值的数据加载到缓存中, 这里的时间和阈值都是可配置的。
基于 RDB+AOF 扩缩容
社区版 Redis 的扩容流程:
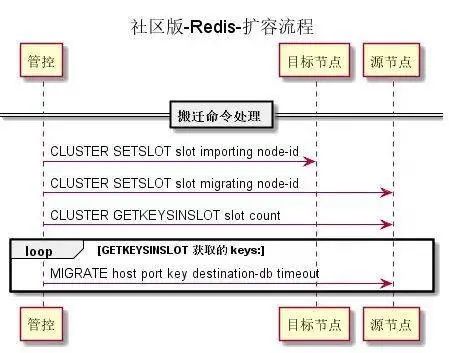
社区版 Redis 扩容存在的一些问题:
importing 和 migrating 的设置不是原子的
先设置目标节点 slot 为 importing 状态, 再设置源节点的 slot 为 migrating 状态。如果反过来, 由于两次操作非原子: 源节点设置为 migrating , 目标节点还未设置 migrating 状态, 请求在这两个节点间反复 Move 。
搬迁以 Key 为粒度, 效率较低
Migrate 命令每次搬迁一个或者多个 Keys, 将整个 Slot 搬迁到目标节点需要多次网络交互。
大 Key 问题
由于 Migrate 命令是同步命令, 在搬迁过程中是不能处理其他用户请求的, 因此可能会影响业务。(延迟时间波动较大)
由于社区版 Redis 存在的上述问题, 我们实现了基于 RDB+Aof 的扩缩容方式, 大致流程如下:
管控添加新节点, 规划待搬迁 slots; 管控端向目标节点下发 slot 同步命令: cluster slotsync beginSlot endSlot [[beginSlot endSlot]...]目标节点向源节点发送 sync [slot ...], 命令请求同步 slot 数据源节点生成指定 slot 数据的一致性快照全量数据(RDB), 并将其发送给目标节点 源节点开始持续发送增量数据(Aof) 管控端定位获取源节点和目标节点的落后值 (diff_bytes), 如果落后值在指定的阈值内, 管控端向目标节点发送 cluster slotfailover(流程类似 Redis 的 cluster failover, 首先阻塞源节点写入, 然后等待目标节点和源节点的落后值为 0, 最后将 搬迁的 slots 归属目标节点)
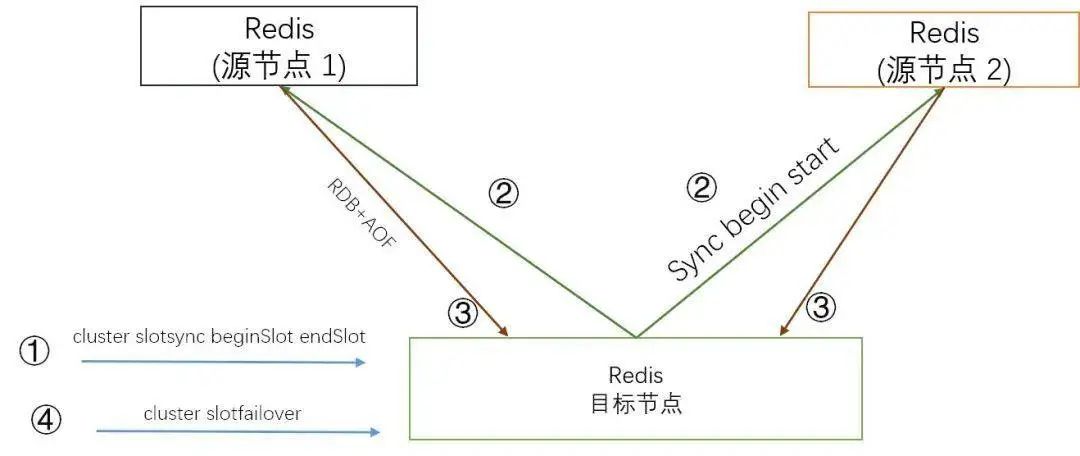
同步层 Redis-sync
同步层 Redis-sync 模拟 Redis Slave 的行为, 接收 RDB 和 Aof, 然后并行地导入到存储层 Tendis。同步层主要需要解决以下问题:
并发地导入到存储层 Tendis, 如何保证时序正确 ? 特殊命令的处理, 比如 FLUSHALL/FLUSHDB/SWAPDB/SELECT/MULTI 等 ? 作为一个无状态的同步组件, 如何保证故障后, 数据断点续传 ? 缓存层和存储层 分别进行扩缩容, 如何将请求路由到正确的 Tendis 节点 ?
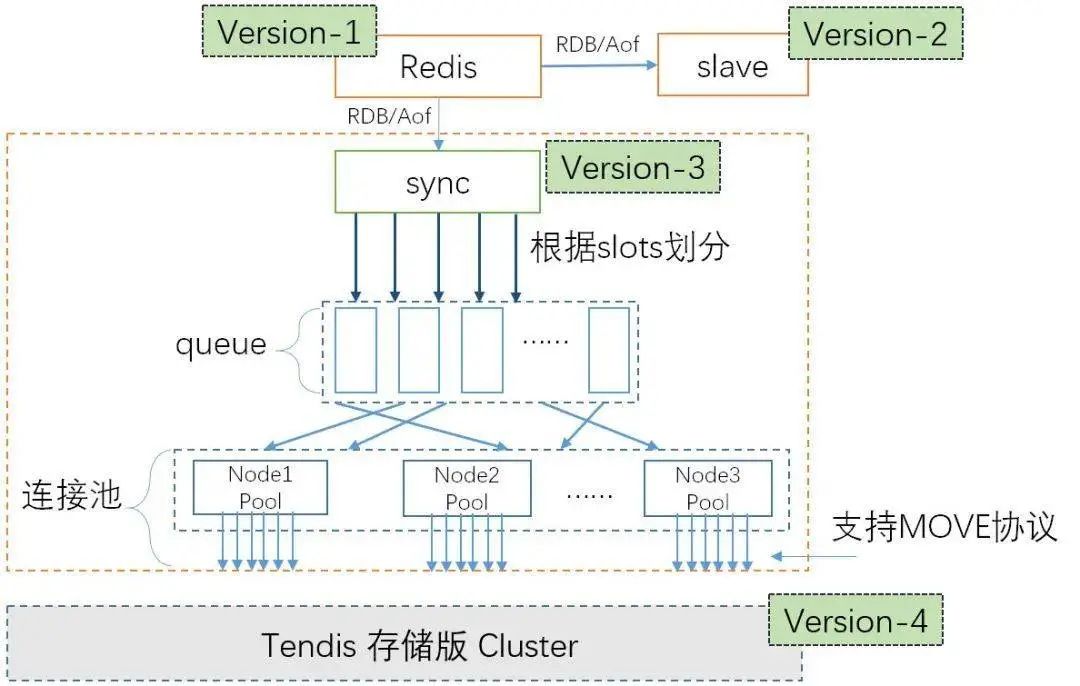
为了解决上述的三个问题, 我们实现了下面的功能:
Slot 内串行, Slot 间并行 针对问题 1, Redis-sync 中采用与 Redis 相同的计算 Slot 的算法, 解析到具体的命令后, 根据 Key 所属的 slot, 将其放到对应的 队列中( slot%QueueSize )。因此同一个 Slot 的数据是串行写入, 不同 slot 的数据可以并行写入, 不会出现时序错乱的行为。 串并转换 针对问题 2, Redis-sync 会在并行和串行模式之间进行转换。比如收到 FLUSHDB 命令, 这是需要将 FLUSHDB 命令 前的命令都执行完, 再执行 FLUSHDB 命令。 定期上报 针对问题 3, Redis-sync 会定期将已发送给存储层的 aof 的 Version 持久化到 存储层。如何 Redis-sync 故障, 首先从 存储层获取上次已发送的位置, 然后向对应的 Redis 节点发送 psync, 请求同步。 数据自动路由 针对问题 4, Redis-sync 会定期从存储层获取 Slot到Tendis 节点的映射关系, 并且维护这些 Tendis 节点的连接池。请求从 缓存层到达, 然后计算请求所属的 slot, 然后发送到正确的 Tendis 节点。
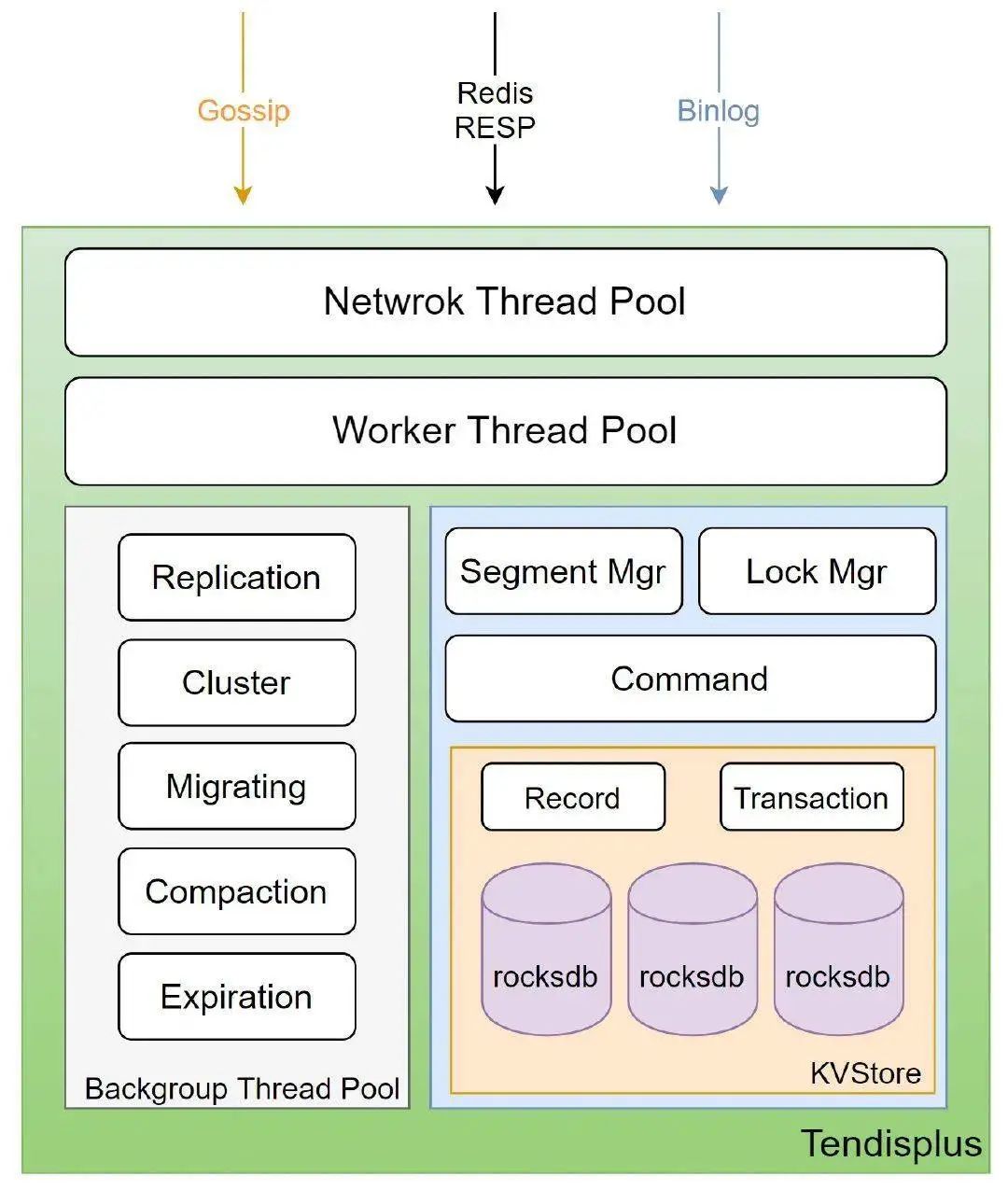
存储层 Tendis Cluster
Tendis 是兼容 Redis 核心数据结构与协议的分布式高性能 KV 数据库, 主要具有以下特性:
兼容 Redis 协议 完全兼容 redis 协议,支持 redis 主要数据结构和接口,兼容大部分原生 Redis 命令。 持久化存储 使用 rocksdb 作为存储引擎,所有数据以特定格式存储在 rocksdb 中,最大支持 PB 级存储。 去中心化架构 类似于 redis cluster 的分布式实现,所有节点通过 gossip 协议通讯,可指定 hashtag 来控制数据分布和访问,使用和运维成本极低。 水平扩展 集群支持增删节点,并且数据可以按照 slot 在任意两节点之间迁移,扩容和缩容过程中对应用运维人员透明,支持扩展至 1000 个节点。 故障自动切换 自动检测故障节点,当故障发生后,slave 会自动提升为 master 继续对外提供服务。

最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^