
Redis夺命十二问,差点没抗住!
大家好,我是二哥呀。
Redis 是面试中绕不过的槛,只要在简历中写了用过 Redis,肯定逃不过。今天我们就来模拟一下面试官在 Redis 这个话题上是如何一步一步深入,全面考察候选人对于 Redis 的掌握情况。
小二:面试官,你好。我是来参加面试的。
面试官:你好,小二。我看了你的简历,熟练掌握 Redis,那么我就随便问你几个 Redis 相关的问题吧。首先我的问题是,Redis 是单线程还是多线程呢?
小二:
Redis 不同版本之间采用的线程模型是不一样的,在 Redis4.0 版本之前使用的是单线程模型,在 4.0 版本之后增加了多线程的支持。
在 4.0 之前虽然我们说 Redis 是单线程,也只是说它的网络 I/O 线程以及 Set 和 Get 操作是由一个线程完成的。但是 Redis 的持久化、集群同步还是使用其他线程来完成。
4.0 之后添加了多线程的支持,主要是体现在大数据的异步删除功能上,例如 unlink key、flushdb async、flushall async 等
面试官:回答的很好,那为什么 Redis 在 4.0 之前会选择使用单线程?而且使用单线程还那么快?
小二:
选择单线程个人觉得主要是使用简单,不存在锁竞争,可以在无锁的情况下完成所有操作,不存在死锁和线程切换带来的性能和时间上的开销,但同时单线程也不能完全发挥出多核 CPU 的性能。
至于为什么单线程那么快我觉得主要有以下几个原因:
Redis 的大部分操作都在内存中完成,内存中的执行效率本身就很快,并且采用了高效的数据结构,比如哈希表和跳表。 使用单线程避免了多线程的竞争,省去了多线程切换带来的时间和性能开销,并且不会出现死锁。 采用 I/O 多路复用机制处理大量客户端的 Socket 请求,因为这是基于非阻塞的 I/O 模型,这就让 Redis 可以高效地进行网络通信,I/O 的读写流程也不再阻塞。
面试官:不错,那 Redis 是如何实现数据不丢失的呢?
小二:
Redis 数据是存储在内存中的,为了保证 Redis 数据不丢失,那就要把数据从内存存储到磁盘上,以便在服务器重启后还能够从磁盘中恢复原有数据,这就是 Redis 的数据持久化。Redis 数据持久化有三种方式。
1)AOF 日志(Append Only File,文件追加方式):记录所有的操作命令,并以文本的形式追加到文件中。
2)RDB 快照(Redis DataBase):将某一个时刻的内存数据,以二进制的方式写入磁盘。
3)混合持久化方式:Redis 4.0 新增了混合持久化的方式,集成了 RDB 和 AOF 的优点。
面试官:那你分别说说 AOF 和 RDB 的实现原理吧。
小二:
AOF 采用的是写后日志的方式,Redis 先执行命令把数据写入内存,然后再记录日志到文件中。AOF 日志记录的是操作命令,不是实际的数据,如果采用 AOF 方法做故障恢复时需要将全量日志都执行一遍。
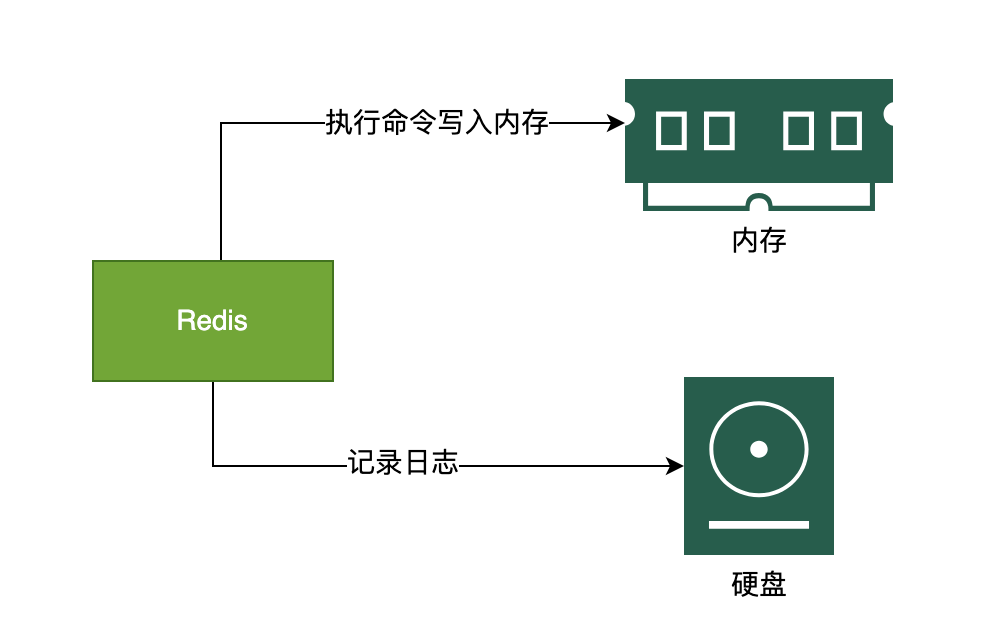
RDB 采用的是内存快照的方式,它记录的是某一时刻的数据,而不是操作,所以采用 RDB 方法做故障恢复时只需要直接把 RDB 文件读入内存即可,实现快速恢复。
面试官:你刚提到了 AOF 采用的是 “写后日志” 的方式,我们平时用的 MySQL 则采用的是 “写前日志”,那 Redis 为什么要先执行命令,再把数据写入日志呢?
小二:这个主要是由于 Redis 在写入日志之前,不对命令进行语法检查,所以只记录执行成功的命令,避免出现记录错误命令的情况,而且在命令执行后再写日志不会阻塞当前的写操作。
面试官:那后写日志又有什么风险呢?
小二:我... 这个我不会。
面试官:
好吧,后写日志主要有两个风险可能会发生:
数据可能会丢失:如果 Redis 刚执行完命令,此时发生故障宕机,会导致这条命令存在丢失的风险。 可能阻塞其他操作:AOF 日志其实也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
我还有个问题是 RDB 做快照时会阻塞线程吗?
小二:Redis 提供了两个命令来生成 RDB 快照文件,分别是 save 和 bgsave。save 命令在主线程中执行,会导致阻塞。而 bgsave 命令则会创建一个子进程,用于写入 RDB 文件的操作,避免了对主线程的阻塞,这也是 Redis RDB 的默认配置。
面试官:RDB 做快照的时候数据能修改吗?
小二:save 是同步的会阻塞客户端命令,bgsave 的时候是可以修改的。
面试官:那 Redis 是怎么解决在 bgsave 做快照的时候允许数据修改呢?
小二:额,这个我不太清楚...

面试官:
这里主要是利用 bgsave 的子线程实现的,具体操作如下:
如果主线程执行读操作,则主线程和 bgsave 子进程互相不影响; 如果主线程执行写操作,则被修改的数据会复制一份副本,然后 bgsave 子进程会把该副本数据写入 RDB 文件,在这个过程中,主线程仍然可以直接修改原来的数据。
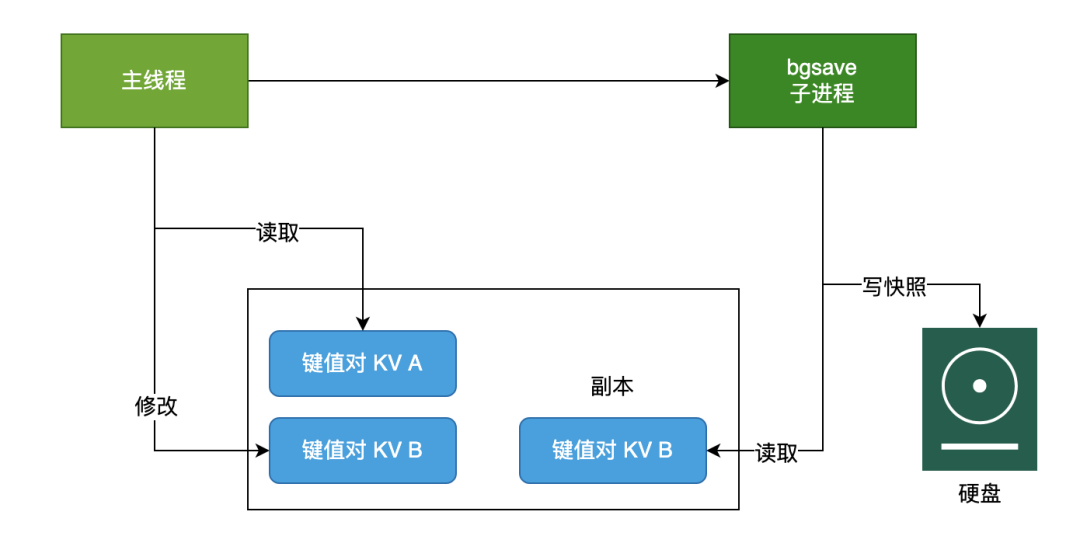
要注意,Redis 对 RDB 的执行频率非常重要,因为这会影响快照数据的完整性以及 Redis 的稳定性,所以在 Redis 4.0 后,增加了 AOF 和 RDB 混合的数据持久化机制:把数据以 RDB 的方式写入文件,再将后续的操作命令以 AOF 的格式存入文件,既保证了 Redis 重启速度,又降低数据丢失风险。
小二:学到了学到了。
面试官:那你再跟我说说 Redis 如何实现高可用吧?
小二:Redis 实现高可用主要有三种方式:主从复制、哨兵模式,以及 Redis 集群。
1)主从复制
将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,这个跟 MySQL 主从复制的原理一样。

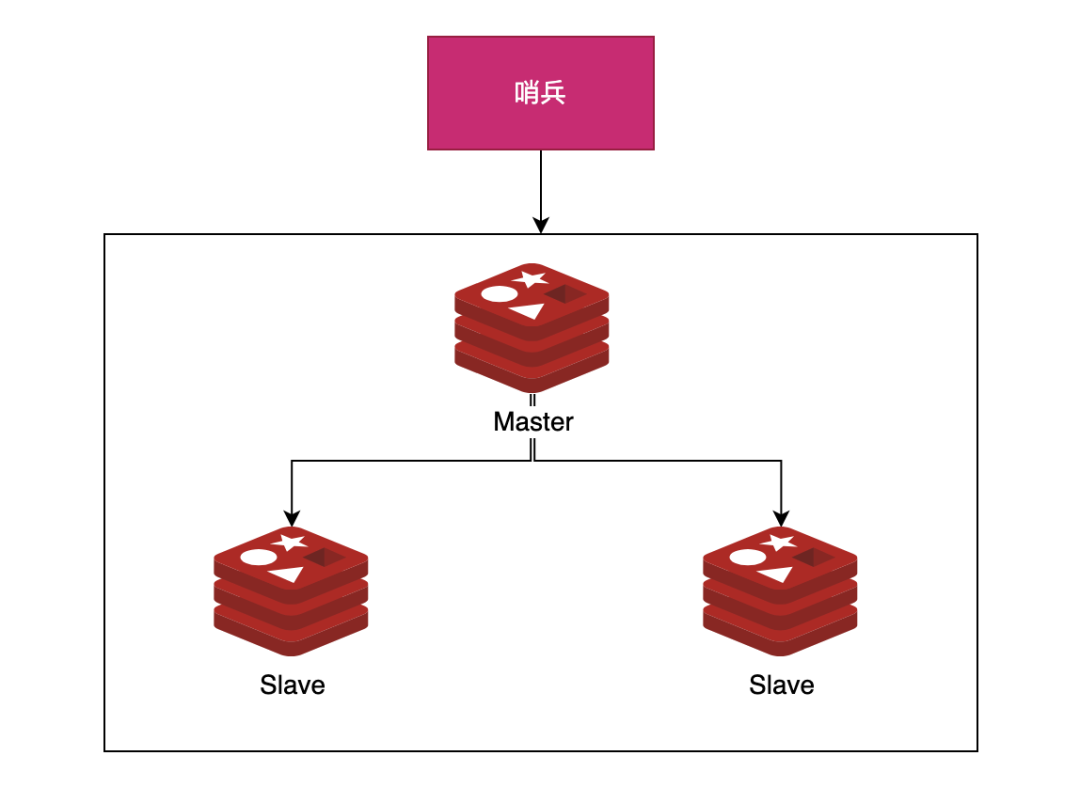
2)哨兵模式
使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复,为了解决这个问题,Redis 增加了哨兵模式(因为哨兵模式做到了可以监控主从服务器,并且提供自动容灾恢复的功能)。
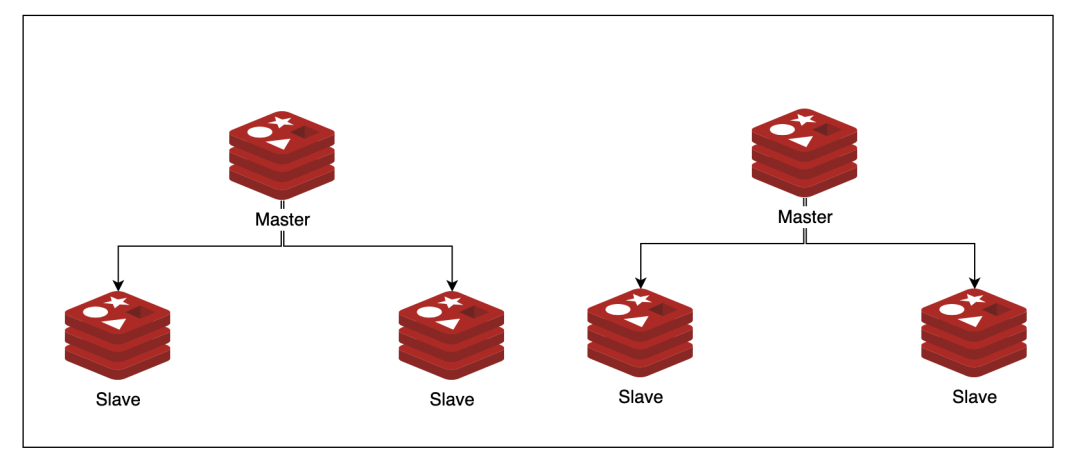
3)Redis Cluster(集群)
Redis Cluster 是一种分布式去中心化的运行模式,是在 Redis 3.0 版本中推出的 Redis 集群方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
面试官:使用哨兵模式在数据上有副本数据做保证,在可用性上又有哨兵监控,一旦 master 宕机会选举 salve 节点为 master 节点,这种已经满足了我们的生产环境需要,那为什么还需要使用集群模式呢?
小二:哨兵模式归根节点还是主从模式,在主从模式下我们可以通过增加 salve 节点来扩展读并发能力,但是没办法扩展写能力和存储能力,存储能力只能是 master 节点能够承载的上限。所以为了扩展写能力和存储能力,我们就需要引入集群模式。
面试官:集群中那么多 Master 节点,Redis Cluster 在存储的时候如何确定选择哪个节点呢?
小二:这应该是使用了某种 hash 算法,但是我不太清楚。。。

面试官:那好,今天的面试就到这里吧,你先回去等我们的面试通知。
小二:好的,谢谢面试官,你能告诉我 Redis Cluster 怎么实现节点选择的吗?
面试官:
Redis Cluster 采用的是类一致性哈希算法实现节点选择的,至于什么是一致性哈希算法你自己回去看看。
Redis Cluster 将自己分成了 16384 个 Slot(槽位),哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步。
1)根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。
2)再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
每个 Redis 节点负责处理一部分槽位,假如你有三个 master 节点 ABC,每个节点负责的槽位如下:
| 节点 | 处理槽位 |
|---|---|
| A | 0-5000 |
| B | 5001 - 10000 |
| C | 10001 - 16383 |
这样就实现了 cluster 节点的选择。
好了,今天关于 Redis 的面试就到这里了,你们觉得如何,都能答对吗?
本篇已收录至 GitHub 上星标 1.4k+ star 的开源专栏《Java 程序员进阶之路》,该专栏风趣幽默、通俗易懂,对 Java 爱好者极度友好和舒适😄,内容包括但不限于 Java 基础、Java 集合框架、Java IO、Java 并发编程、Java 虚拟机、Java 企业级开发(Git、SSM、Spring Boot)等核心知识点。
https://github.com/itwanger/toBeBetterJavaer
star 了这个仓库就等于你拥有了成为了一名优秀 Java 工程师的潜力。
「阅读原文」可以跳转到《Java 程序员进阶之路》的官网网址,开始愉快的学习之旅吧。

没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。