
一道基础题,多种解题思路,引出Pandas多个知识点
小小明:「凹凸数据」专栏作者,Pandas数据处理高手,致力于帮助无数数据从业者解决数据处理难题。
源于林胖发出的一道基础题:

基础解法explode函数
这道题最简单的解法,相信大部分用过pandas的朋友都会,林胖也马上发出了自己的答案:
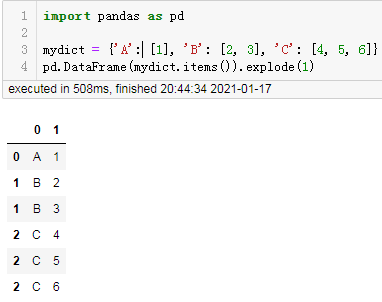
import pandas as pd
mydict = {'A': [1], 'B': [2, 3], 'C': [4, 5, 6]}
pd.DataFrame(mydict.items()).explode(1)
结果:
详解
mydict.items()是python基础字典的内容,它返回了这个字典键值对组成的元组列表:
mydict.items()
返回:
dict_items([('A', [1]), ('B', [2, 3]), ('C', [4, 5, 6])])
将这个内部是元组的可迭代对象传入DataFrame的构造函数中:
pd.DataFrame(mydict.items())
返回结果:
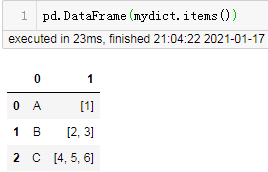
这是pandas最基础的开篇知识点使用可迭代对象构造DataFrame,列表的每个元素都是整个DataFrame对应的一行,而这个元素内部迭代出来的每个元素将构成DataFrame的某一列。
然后再看看这个explode函数,它是pandas 0.25版本才出现的函数,只有一个参数可以传入列名,然后该函数就可以把该列的列表每个元素扩展到多行上。
效果与hive使用lateral view+explode实现的效果几乎一致,类似于:
select a,b_i from df lateral view explode(b) tmp as b_i;
可以参考很早之前的一篇文章:https://blog.csdn.net/as604049322/article/details/105985770
没有exlode函数如何解决这个问题
但是,黄佬说版本太低没有这个函数,于是我给群友们出了一道题:

在黄佬的邀请下,一位经过我多次辅导的群友率先使用了循环法解题:
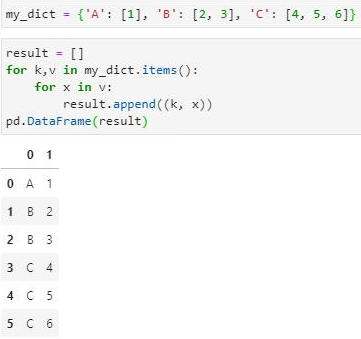
我觉得非常棒,但我也希望看到有人再用变形法实现一次。林胖和一位群友再次给出了简化版本的循环解法:
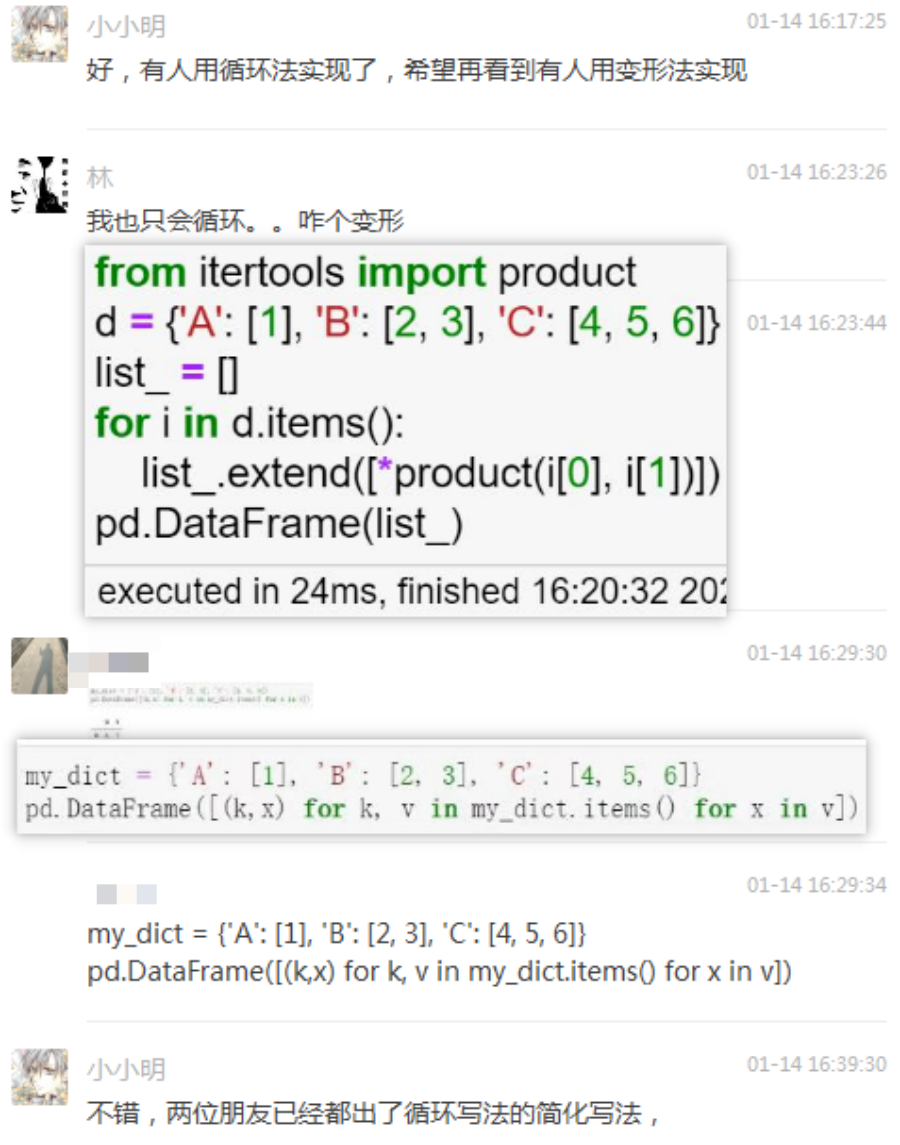
经过一番提示后,小五哥和林胖终于给出了变形法的解法:
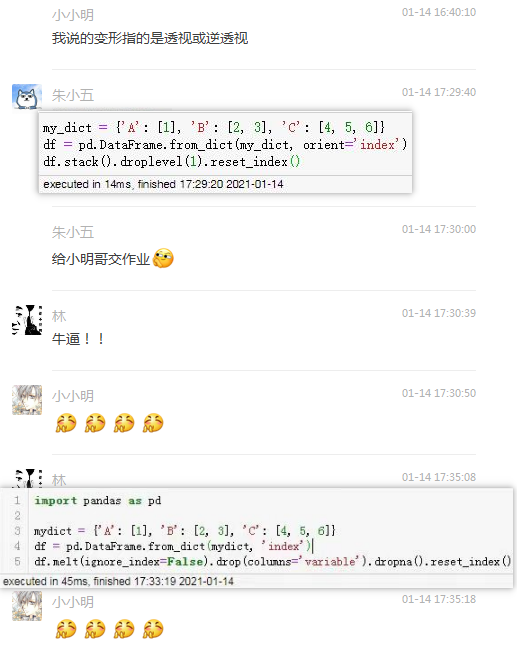
非常不错,群友们终于独立的多思路解决了这个问题,真的要撒花呀!!!
下面我们详细分析一下,循环法和变形法的解法吧:
循环法解题
基本写法:
result = []
for k, vs in mydict.items():
for v in vs:
result.append((k, v))
pd.DataFrame(result)
本质上就是实现了一个笛卡尔积的拉平操作,将mydict.items这个可迭代对象的元组构造笛卡尔积并按照整体拉平。
上面的基本写法,应该99%以上的朋友都能看懂,但 林胖 的循环简化解法:
import itertools
result = []
for k, v in mydict.items():
result.extend(itertools.product(k, v))
pd.DataFrame(result)
部分朋友可能没有看明白,这个就需要查询一下product方法的官方文档(https://docs.python.org/zh-cn/3.7/library/itertools.html?highlight=product#itertools.product):
product(*iterables, repeat=1) --> product object
参数:
iterables 为可迭代对象 可选参数repeat 表示重复次数
用于生成可迭代对象输入的笛卡儿积,相当于生成器表达式中的嵌套循环。
例如:product(A, B) 中的元素A和B将共同构成可迭代元素[A, B]作为iterables传入和 ((x,y) for x in A for y in B) 返回结果一样。
返回示例:
product(‘ab’, range(3)) --> (‘a’,0) (‘a’,1) (‘a’,2) (‘b’,0) (‘b’,1) (‘b’,2) product((0,1), (0,1), (0,1)) --> (0,0,0) (0,0,1) (0,1,0) (0,1,1) (1,0,0) …
也可以传入可选参数 repeat 表示重复的次数:例如,product(A, repeat=4) 和 product(A, A, A, A) 的返回结果是一样的。
列表的extend方法是将可迭代对象的每个元素都添加到列表中,而append方法只能添加单个元素。
当然,我们还可以将整个for循环改写成列表生成式:
result = [(k, v) for k, vs in mydict.items() for v in vs]
pd.DataFrame(result)
也可以简化代码量。
变形法解题
df = pd.DataFrame(mydict.items(), columns=["a", "b"])
df
实现思路,上面的界面是下面最左边:
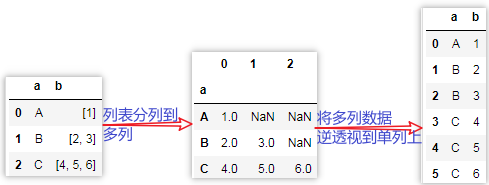
列表分列的2种方法
列表分列的思路:Pandas的Series对象调用apply方法单个元素返回的结果是Series时,这个Series的每个数据会作为Datafrem的每一列,索引会作为列名。
对Series进行列表分列
例如:
df["b"].apply(pd.Series)
结果:
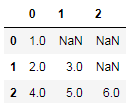
不过这样会丢失原本的"a"列,我们可以先将"a"列设置为索引,再进行Series分列操作:
df.set_index("a")["b"].apply(pd.Series)
或者把结果设置成原本的"a"列为索引:
df["b"].apply(pd.Series).set_index(df["a"])
结果均为上述实现思路的第二步。
直接对Datafream进行列表分列
如果我们希望直接使用Datafream实现分列可以借助agg方法,因为agg方法是对每一列的Series对象操作:
df.agg({"a": lambda x: x, "b": pd.Series})
结果:
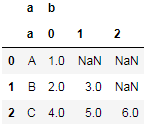
但这操作导致列多了一个级别,需要删除:
df.agg({"a": lambda x: x, "b": pd.Series}).droplevel(0, axis=1)
结果:
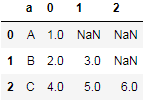
只要再执行set_index("a"):
df.agg({"a": lambda x: x, "b": pd.Series}).droplevel(0, axis=1).set_index("a")
结果就会与实现思路的第二步结果一致。
将字典的键作为索引的2种读取方法
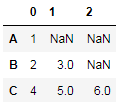
当然上面我只是为了给大家讲述分列的一些方法。对于这个例子,其实我们可以直接通过pd.DataFrame.from_dict方法orient参数传入’index’,直接获得第二步的结果(只是索引没有名称):
df = pd.DataFrame.from_dict(mydict, 'index')
或者分别传入data和索引index:
df = pd.DataFrame(data=mydict.values(), index=mydict.keys())
都能得到以下结果:
melt实现逆透视
说起逆透视我个人首先想到了melt方法,然后才想到melt方法实现的本质用到了stack方法。
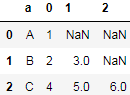
为了避免索引丢失,我们首先还原索引为普通的列:
df = df.rename_axis(index="a").reset_index()
df
结果:
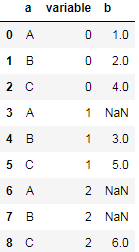
然后使用melt方法进行逆透视:
df.melt(id_vars='a', value_name='b')
结果:
然后删除第二列,再删除空值行,再将数值列转换为整数类型就搞定。
最终代码:
df = pd.DataFrame.from_dict(mydict, 'index')
df = df.melt(id_vars='a', value_name='b').drop(columns="variable").dropna()
df.b = df.b.astype("int")
df
成功得到结果:

stack实现逆透视
df = pd.DataFrame.from_dict(mydict, 'index')
df.stack()
结果:
A 0 1.0
B 0 2.0
1 3.0
C 0 4.0
1 5.0
2 6.0
dtype: float64
结果返回了一个多级索引的Series,我们首先需要删除索引中多余的部分:
df.stack().droplevel(1)
结果:
A 1.0
B 2.0
B 3.0
C 4.0
C 5.0
C 6.0
dtype: float64
此时我们再还原索引到普通列:
df.stack().droplevel(1).reset_index()
再重新设置一下列名:
df.stack().droplevel(1).reset_index().set_axis(["a", "b"], axis=1)
最后重设一下B列的类型:
df.b = df.b.astype("int")
最终代码:
df = pd.DataFrame.from_dict(mydict, 'index')
df = df.stack().droplevel(1).reset_index().set_axis(["a", "b"], axis=1)
df.b = df.b.astype("int")
df
结果:

欢迎你在下方评论区留言,发表你的看法,给大家分享和互动!
如果大家喜欢我的文章,请动动你的小手,点个赞吧~
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典