干货 | 实时数据聚合怎么破
作者简介
数据猩猩,携程数据分析总监,关注分布式数据存储和实时数据分析。
通过何种机制观察到变化的数据
通过何种方式能最有效的处理变化数据,将结果并入到原先的聚合分析结果中
分析后的数据如何让使用方及时感知并获取
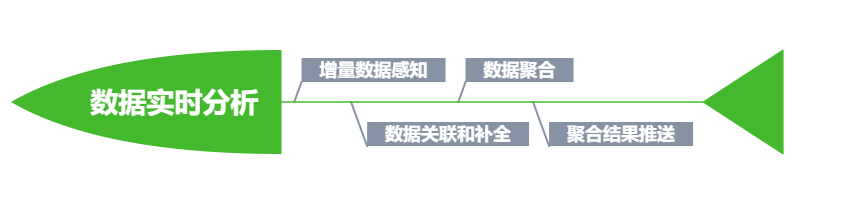
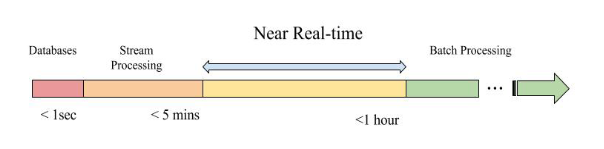
一、数据新鲜性
二、数据关联
三、计算及时性
3.1 全量计算(1m<时延<5m)
3.2 增量计算
四、计算触发机制
定时触发
trigger for every new element

五、聚合结果实时可见
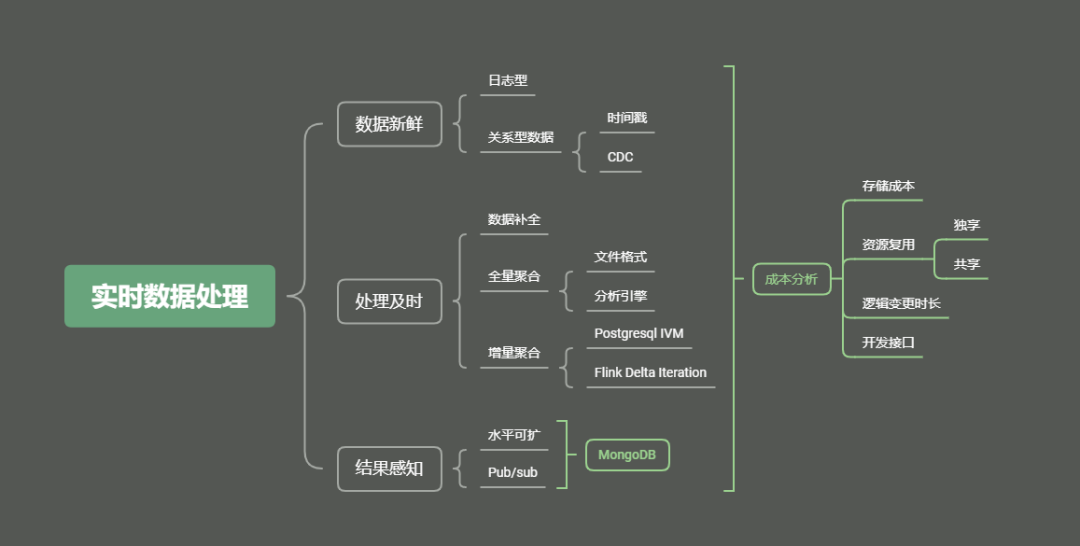
六、小结
评论
 下载APP
下载APP作者简介
数据猩猩,携程数据分析总监,关注分布式数据存储和实时数据分析。
通过何种机制观察到变化的数据
通过何种方式能最有效的处理变化数据,将结果并入到原先的聚合分析结果中
分析后的数据如何让使用方及时感知并获取
一、数据新鲜性
二、数据关联
三、计算及时性
3.1 全量计算(1m<时延<5m)
3.2 增量计算
四、计算触发机制
定时触发
trigger for every new element
五、聚合结果实时可见
六、小结