
4 秒处理 10 亿行数据! Go 语言的 9 大代码方案,一个比一个快
阅读本文大概需要 6 分钟。
编译 | 核子可乐、凌敏 来自 | InfoQ2024 年开年,Java “十亿行挑战”(1BRC)火爆外网。该挑战赛要求开发者编写一个 Java 程序,从一个包含十亿行信息的文本文件中检索温度测量值,并计算每个气象站的最小、平均值和最高温度。“十亿行挑战”的目标是为这项任务创建最快的实现,同时探索现代 Java 的优势。
这项挑战听起来很简单。但十亿行代码实际是一项庞大的工程,如果以每个数字 3 秒的速度数到 10 亿,大约需要 95.1 年!因此该挑战最大的难度在于,处理文件以在尽可能短的时间内打印输出:
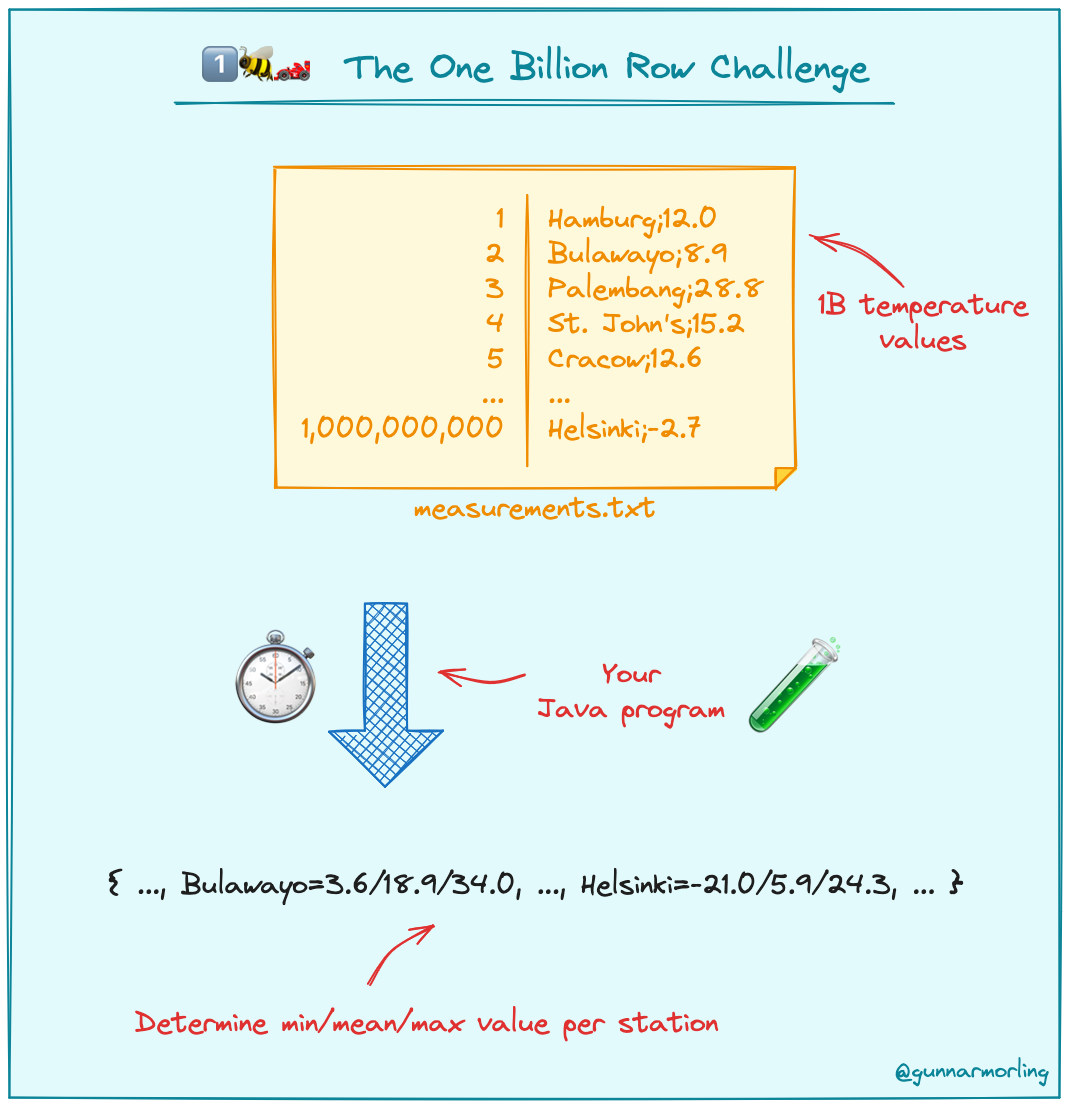
该挑战很快在 Hacker News、lobste.rs、Reddit 等社区掀起热烈讨论,不少开发者采用 Rust、Go、C++ 等其他编程语言甚至是数据库参与挑战。
日前,从业 20 年的软件工程师 Ben Hoyt 用 Go 语言参与该挑战,他一共想出了 9 种解决方案,完成 10 亿行数据处理的时间最快只需 4 秒,最慢需要 1 分 45 秒。Ben Hoyt 还给自己提了点限制条件:每种方法都仅使用 Go 标准库以保证可移植性,不涉及程序集、不涉及 unsafe、不涉及内存映射文件。跟其他作者的发现相比,Ben Hoyt 的解决方案不是最慢的、但也没能占据榜首。不过最重要的是,他的解跟其他参赛者的思路都不一样,这种独立性可能更具价值。
以下是 Ben Hoyt 用 Go 语言编写的九种解决方案,每个方案都比前一个速度更快,概要如下:
-
方案一:简单且常见
-
方案二:带指针值的 map
-
方案三:手动解析温度
-
方案四:定点整数
-
方案五:去掉 bytes.Cut
-
方案六:去掉 bufio.Scanner
-
方案七:自定义哈希表
-
方案八:并行化方案一
-
方案九:并行化方案七
基线性能
首先通过几条基线建立对这个任务的初步认识,看看使用 cat 读取 13 GB 的数据需要多长时间:
$ time cat measurements.txt >/dev/null
0m1.052s
这里 Ben Hoyt 一共测试了五次,所以实际上文件是被缓存过的。看起来 Linux 是允许把完整的 13 GB 数据都保留在磁盘缓存中,因为第一次操作花了接近 6 秒时间,之后速度开始直线上升。
相比之下,对文件实际执行某些操作则要慢得多,wc 几乎需要整整一分钟:
time wc measurements.txt
1000000000 1179173106 13795293380 measurements.txt
0m55.710s
要快速为这个问题找个简单的方案,Ben Hoyt 可能会先从 AWK 开始。这种方法使用 Gawk,因为其中的 asorti 函数可以轻松对输出进行排序。Ben Hoyt 还加上了 -b 选项来使用“将字符当作字节”模式,这样能让速度更快一些:
time gawk -b -f 1brc.awk measurements.txt >measurements.out
7m35.567s
事实证明哪怕是最简单粗暴的 Go 方法,也能在 7 分钟左右搞定问题。下面就以此为基础摸索答案序列。
Ben Hoyt 首先优化出按序单核版本(方案 1 到 7),之后再对其做并行化调整(方案 8 和 9)。得到的所有结果都是在配备高速 SSD 驱动器和 32 GB 内存的 linux/amd64 笔记本电脑上,配合 Go 1.21.5 版本得到的。
Ben Hoyt 的许多方案和其他参与者给出的大部分最快方案,都会假设有效输入。例如温度数值只保留一位小数。如果输入无效,那么这几种方案可能会引发运行时故障或产生错误输出。
方案一:简单且常见的 Go 代码作为第一种方案,Ben Hoyt 的要求就是简单且直接,只使用 Go 标准库中的工具:bufio.Scanner 负责读取数据行,strings.Cut 通过“;”进行分隔,strconv.ParseFloat 用于解析温度,再加上普通的 Go map 来累积结果。
在方案一中,Ben Hoyt 完整列出首种方案的所有代码,对于之后的方案就只给出比较有趣的部分:
func r1(inputPath string, output io.Writer) error {
type stats struct {
min, max, sum float64
count int64
}
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Close()
stationStats := make(map[string]stats)
scanner := bufio.NewScanner(f)
for scanner.Scan() {
line := scanner.Text()
station, tempStr, hasSemi := strings.Cut(line, ";")
if !hasSemi {
continue
}
temp, err := strconv.ParseFloat(tempStr, 64)
if err != nil {
return err
}
s, ok := stationStats[station]
if !ok {
s.min = temp
s.max = temp
s.sum = temp
s.count = 1
} else {
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += temp
s.count++
}
stationStats[station] = s
}
stations := make([]string, 0, len(stationStats))
for station := range stationStats {
stations = append(stations, station)
}
sort.Strings(stations)
fmt.Fprint(output, "{")
for i, station := range stations {
if i > 0 {
fmt.Fprint(output, ", ")
}
s := stationStats[station]
mean := s.sum / float64(s.count)
fmt.Fprintf(output, "%s=%.1f/%.1f/%.1f", station, s.min, mean, s.max)
}
fmt.Fprint(output, "}\n")
return nil
}
这种最基本的方案能够在 1 分 45 秒内完成 10 亿行数据的处理。相较于 AWK 方案的 7 分钟,这明显是有了质的飞跃。
方案二:带指针值的 mapBen Hoyt 之前开发过一款单词计数程序,当时就发现实际执行的哈希处理比理论需要的数量要多得多。对于每一行,我们都会对字符串执行两次哈希处理:第一次用于从 map 中获取值,第二次则是更新该 map。
为了避免这种情况,我们可以使用 map[string]*stats(指针值)并更新指向的 struct,而不再使用 map[string]stats 并更新哈希表本体。
这里,Ben Hoyt 首先想到用 Go 分析器来做确认。只需几行代码,即可将 CPU 分析添加到 Go 程序当中。
$ ./go-1brc -cpuprofile=cpu.prof -revision=1 measurements-10000000.txt >measurements-10000000.out
Processed 131.6MB in 965.888929ms
$ go tool pprof -http=: cpu.prof
...
通过在精简后的 1000 万行输入文件上运行,这些命令为方案一生成了以下概览:
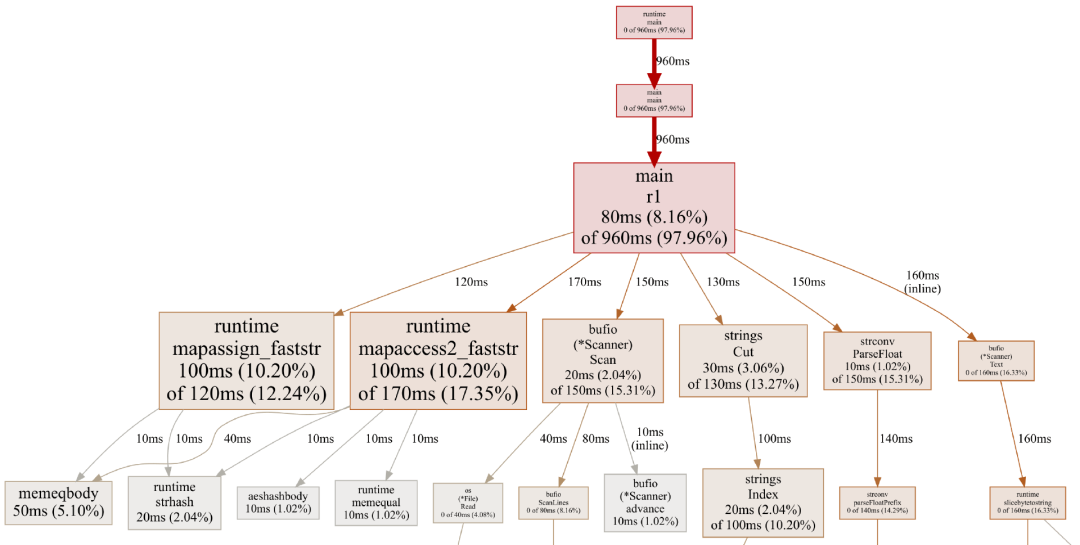
Map 操作占用了整整 30% 的时间:其中 12.24% 用于分配,17.35% 用于查找。所以只要使用指针值,我们应该就能消除大部分 map 分配时间。
顺带一提,这张概览图还显示出其余时间的具体用途:
-
通过 Scanner.Scan 扫描各行
-
通过 strings.Cut 找到“;”
-
通过 strconv.ParseFloat 解析温度
-
调用 Scanner.Text 为该行分配一个字符串
总的来说,方案二其实就是对 map 操作做一点小小调整:
stationStats := make(map[string]*stats)
scanner := bufio.NewScanner(f)
for scanner.Scan() {
// ...
s := stationStats[station]
if s == nil {
stationStats[station] = &stats{
min: temp,
max: temp,
sum: temp,
count: 1,
}
} else {
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += temp
s.count++
}
}
在 map 中存在气象站的常见情况下,我们现在只须执行一次 map 操作 s := stationStats[station],也就是说对气象站名称进行哈希处理并访问哈希表的过程只需执行一次。即在气象站已存在于 map 内的情况(在 10 亿行数据中占多数比例),我们会更新现有指向 struct。
虽然这对性能的提升不是太大,但也有一定效果:在 map 中使用指针值,可以将整个处理时间由 1 分 45 秒缩短至 1 分 31 秒。
方案三:去掉 strconv.ParseFloat第三种方案相对比较硬核:用自定义代码来取代 strconv.ParseFloat 进行温度解析。标准库函数会处理大量我们并不需要支持的极端温度输入情况,毕竟实际数据格式就是 1.2 或 34.5 这类 2 到 3 位数字(有些前面再多个负号)。
另外,strconv.ParseFloat 会接受一条字符串参数。现在我们不需要调用该参数,因此可以直接从 Scanner.Bytes 使用字节切片,而非借助 Scanner.Text 进行字符串的分配和复制。
方法如下:
negative := false
index := 0
if tempBytes[index] == '-' {
index++
negative = true
}
temp := float64(tempBytes[index] - '0') // parse first digit
index++
if tempBytes[index] != '.' {
temp = temp*10 + float64(tempBytes[index]-'0') // parse optional second digit
index++
}
index++ // skip '.'
temp += float64(tempBytes[index]-'0') / 10 // parse decimal digit
if negative {
temp = -temp
}
不太直观,但也不至于特别难理解。方案三的处理时长从 1 分 31 秒成功缩短到了 1 分钟以内:55.8 秒。
方案四:定点整数曾几何时,浮点指令的执行速度要比整数指令慢得多。现如今速度差距仍然存在,只是没那么夸张。但如果可以,把浮点转换成整数还是会提高性能。
对于这个问题,每项温度都有一个小数位,因此可以轻松用定点整数进行表示。例如,我们可以将 34.5 表示为整数 345,然后在最终输出结果之前再将其转换回浮点数。
所以方案四跟方案三基本相同,只是将 stats struct 字段调整如下:
type stats struct {
min, max, count int32
sum int64
}
之后在输出结果时,再将数字除以 10:
mean := float64(s.sum) / float64(s.count) / 10
fmt.Fprintf(output, "%s=%.1f/%.1f/%.1f",
station, float64(s.min)/10, mean, float64(s.max)/10)
这里 Ben Hoyt 用 32 位整数表示最低和最高温度,因为最高温度很可能达到约 500(即 50 摄氏度)。也可以使用 int16,但从过往的开发经验来看,现代 64 位 CPU 在处理 16 位整数时速度要比 32 位整数更慢。在具体测试中,二者似乎没有什么可感知的差异,但 Ben Hoyt 还是优先选择了 32 位。
使用整数之后,运行时间从 55.8 秒缩短到了 51.0 秒,效果也算显著。
方案五:去掉 bytes.Cut为了推衍出方案五,Ben Hoyt 先为方案四生成了一份概览图:
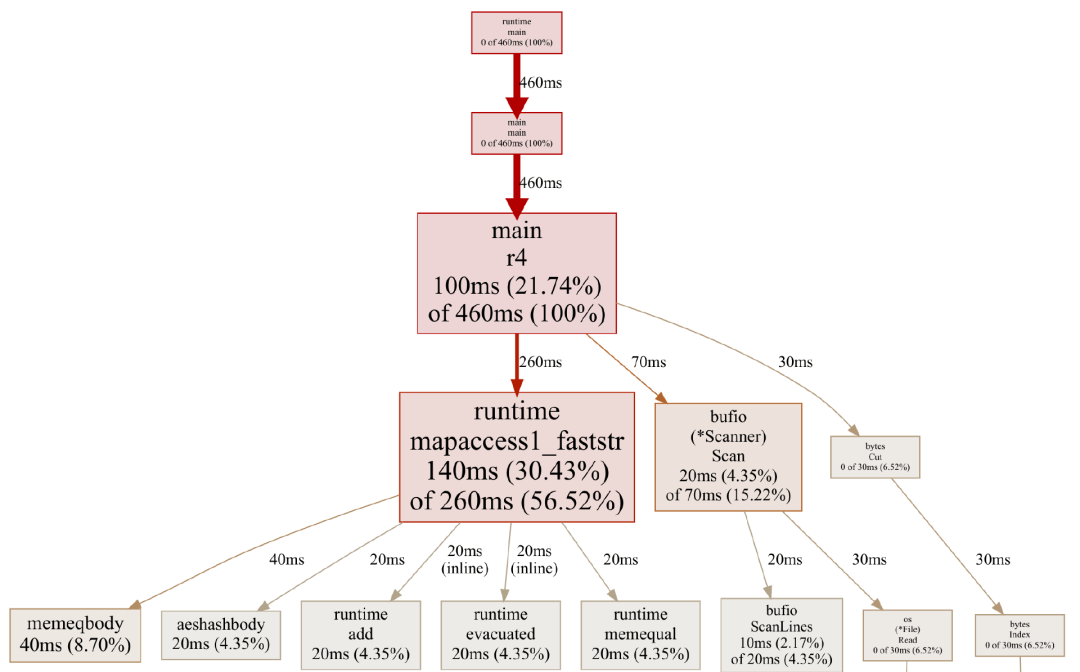
看来继续优化是越来越困难了。很明显,map 操作在其中占主导地位,转为自定义哈希表和去掉 bufio.Scanner 也非易事。所以这里我们先试着去掉 bytes.Cut。
Ben Hoyt 想到一个简单的办法来节约时间。以原始文件中的一行数据为例:
New Orleans;11.7
直接从后往前查找“;”来解析温度,其速度会比直接扫描完整气象站名称来查找“;”更快。下面这段不怎么优雅的代码就是干这个的:
end := len(line)
tenths := int32(line[end-1] - '0')
ones := int32(line[end-3] - '0') // line[end-2] is '.'
var temp int32
var semicolon int
if line[end-4] == ';' { // positive N.N temperature
temp = ones*10 + tenths
semicolon = end - 4
} else if line[end-4] == '-' { // negative -N.N temperature
temp = -(ones*10 + tenths)
semicolon = end - 5
} else {
tens := int32(line[end-4] - '0')
if line[end-5] == ';' { // positive NN.N temperature
temp = tens*100 + ones*10 + tenths
semicolon = end - 5
} else { // negative -NN.N temperature
temp = -(tens*100 + ones*10 + tenths)
semicolon = end - 6
}
}
station := line[:semicolon]
回避掉 bytes.Cut 之后,运行时间从 51.0 秒缩短到了 46.0 秒,又是一场小小的胜利。
方案六:去掉 bufio.Scanner现在要尝试去掉 bufio.Scanner 了。可以想到,要想查找每行的末尾,扫描器必须查看所有字节并寻找换行符。接下来,就是处理大量字节来解析温度并找到“;”。因此,我们可以尝试把这些步骤整合起来,避免使用 bufio.Scanner。
在方案六中,我们分配了一个 1 MB 的缓冲区来读取大块文件,查找块中的最后一个换行符来确保不会把单行截断,之后再处理这些单个块。具体代码如下:
buf := make([]byte, 1024*1024)
readStart := 0
for {
n, err := f.Read(buf[readStart:])
if err != nil && err != io.EOF {
return err
}
if readStart+n == 0 {
break
}
chunk := buf[:readStart+n]
newline := bytes.LastIndexByte(chunk, '\n')
if newline < 0 {
break
}
remaining := chunk[newline+1:]
chunk = chunk[:newline+1]
for {
station, after, hasSemi := bytes.Cut(chunk, []byte(";"))
// ... from here, same temperature processing as r4 ...
去掉 bufio.Scanner 并进行自主扫描之后,处理时间从 46.0 秒缩短到了 41.3 秒。效果不算太好,但至少感知得到。
方案七:自定义哈希表方案七是这次探索中的真正核心。我们会自行建立一个自定义哈希表,而不再使用 Go map。这样做有两大优点:
-
我们可以在查找“;”时对气象站名称进行哈希处理,从而避免对字节的二次处理。
-
我们可以将哈希表中的每个键存储为字节切片,从而避免将各个键转换为 string(将在每一行上分配和复制)。
在 Go 中自定义哈希表并不复杂,只需使用带有线性探测的 FNV-1a 哈希算法即可。如果发生冲突,则使用下一空槽。
为了简单起见,Ben Hoyt 预先分配了大量哈希桶(这里共用到 10 万个)以避免编写逻辑来调整表的大小。但如果表的占用比例超过了一半,代码还是会出问题。通过测试,Ben Hoyt 发现引发哈希冲突的几率大概是 2%。
为了解决这次的问题,Ben Hoyt 还添加了一堆新代码,包括哈希表设置、哈希本体以及表探测与插入:
// The hash table structure:
type item struct {
key []byte
stat *stats
}
items := make([]item, 100000) // hash buckets, linearly probed
size := 0 // number of active items in items slice
buf := make([]byte, 1024*1024)
readStart := 0
for {
// ... same chunking as r6 ...
for {
const (
// FNV-1 64-bit constants from hash/fnv.
offset64 = 14695981039346656037
prime64 = 1099511628211
)
// Hash the station name and look for ';'.
var station, after []byte
hash := uint64(offset64)
i := 0
for ; i < len(chunk); i++ {
c := chunk[i]
if c == ';' {
station = chunk[:i]
after = chunk[i+1:]
break
}
hash ^= uint64(c) // FNV-1a is XOR then *
hash *= prime64
}
if i == len(chunk) {
break
}
// ... same temperature parsing as r6 ...
// Go to correct bucket in hash table.
hashIndex := int(hash & uint64(len(items)-1))
for {
if items[hashIndex].key == nil {
// Found empty slot, add new item (copying key).
key := make([]byte, len(station))
copy(key, station)
items[hashIndex] = item{
key: key,
stat: &stats{
min: temp,
max: temp,
sum: int64(temp),
count: 1,
},
}
size++
if size > len(items)/2 {
panic("too many items in hash table")
}
break
}
if bytes.Equal(items[hashIndex].key, station) {
// Found matching slot, add to existing stats.
s := items[hashIndex].stat
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += int64(temp)
s.count++
break
}
// Slot already holds another key, try next slot (linear probe).
hashIndex++
if hashIndex >= len(items) {
hashIndex = 0
}
}
}
readStart = copy(buf, remaining)
}
这部分代码带来了巨大回报:自定义哈希表将处理时长从 41.3 秒缩短到了 25.8 秒。
方案八:并行处理各块在方案八中,Ben Hoyt 想引入一些并行性。但为了控制变量,他打算继续沿用方案 1 的代码,毕竟更简单且常见。方案一中保留了 bufio.Scanner 和 strconv.ParseFloat,这里姑且直接将其并行化。在并行化成功之后,Ben Hoyt 再尝试引入之后几种方案的优化手段,双管齐下的结果就是最终的方案九。
对这类 Map-Reduce 问题进行并行化并不困难:把文件拆分成大小相似的多个块(每个 CPU 核心对应一个块)、启动一个线程(在 Go 中叫作 goroutine)来处理各个块,最后把结果合并起来即可。
所以总体来看,代码表示如下所示:
// Determine non-overlapping parts for file split (each part has offset and size).
parts, err := splitFile(inputPath, maxGoroutines)
if err != nil {
return err
}
// Start a goroutine to process each part, returning results on a channel.
resultsCh := make(chan map[string]r8Stats)
for _, part := range parts {
go r8ProcessPart(inputPath, part.offset, part.size, resultsCh)
}
// Wait for the results to come back in and aggregate them.
totals := make(map[string]r8Stats)
for i := 0; i < len(parts); i++ {
result := <-resultsCh
for station, s := range result {
ts, ok := totals[station]
if !ok {
totals[station] = r8Stats{
min: s.min,
max: s.max,
sum: s.sum,
count: s.count,
}
continue
}
ts.min = min(ts.min, s.min)
ts.max = max(ts.max, s.max)
ts.sum += s.sum
ts.count += s.count
totals[station] = ts
}
}
由于 splitFile 函数有点繁琐,所以这里没有使用。它负责查看文件的大小,除以我们指定的拆分块数,然后查找每一块,在末尾读取 100 个字节并查找最后一个换行符,借此确保每个块在结尾都保留了整行(未将原始数据行截断)。
r8ProcessPart 函数与方案 1 基本相同,但它会首先查找各个块的偏移并将长度限制为块大小之内(使用 io.LimitedReader)。完成后,它会发回自己的 stats map:
func r8ProcessPart(inputPath string, fileOffset, fileSize int64,
resultsCh chan map[string]r8Stats) {
file, err := os.Open(inputPath)
if err != nil {
panic(err)
}
defer file.Close()
_, err = file.Seek(fileOffset, io.SeekStart)
if err != nil {
panic(err)
}
f := io.LimitedReader{R: file, N: fileSize}
stationStats := make(map[string]r8Stats)
scanner := bufio.NewScanner(&f)
for scanner.Scan() {
// ... same processing as r1 ...
}
resultsCh <- stationStats
}
相较于方案一,并行处理的性能表现出巨大优势,成功将时间从 1 分 45 秒缩短到了 24.3 秒。相比之下,之前的“优化但非并行”版本(即方案七)需要耗费 25.8 秒。也就是说并行化比优化的性能增强效果更好,而且也简单得多。
方案九:优化加并行在方案九,也就是最终答案中,我们简单将之前从方案一到七的所有优化方法,跟方案八中的并行化结合起来。
这里 Ben Hoyt 使用了方案八中的 splitFile 函数,其余代码则直接从方案七处复制而来,所以这里就不再赘述了。从结果来看,最终方案将处理时长从 24.3 秒进一步缩短到 3.99 秒。
有趣的是,由于所有实际处理现在都在单一大函数 r9ProcessPart 中进行,因此概览图就没什么用了。整个过程如下所示:
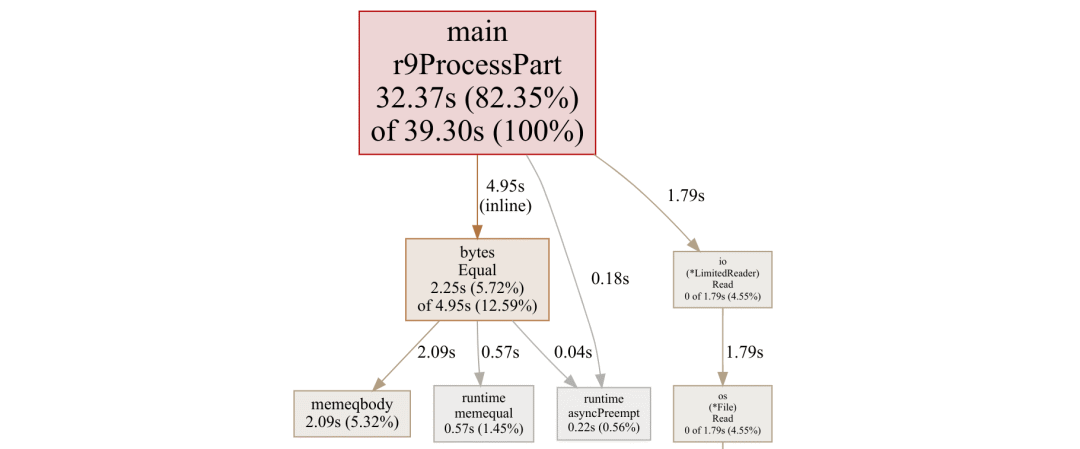
如大家所见,有 82% 的时间都花在了 r9ProcessPart 上,其中 bytes.Equal 占用了 13%,文件读取则占用了余下的 5%。
如果想要进一步分析,我们就得进一步下探到源视图的层次。下面来看内部循环:

但这份报告还是有让人迷惑的地方。为什么 if items[hashIndex].key == nil 显示消费了 5.01 秒,但调用 bytes.Equal 则只用了 390 毫秒?难道说切片查找就是要比函数调用快得多?Ben Hoyt 自己也不太理解,欢迎各位 Go 性能大神在评论区中答疑解惑。
总而言之,这里肯定还有更大的性能优化空间,但 4 秒之内处理 10 亿行数据,也就是每秒 2.5 亿行,这对不少开发者来说已经相当够用了。
写在最后也许有人会问,折腾这些有意义吗?
对于大多数日常编程任务,使用最简单、最常见的代码往往才是王道。哪怕是面对超过 10 亿行的温度统计数据,如果只需要获得一次答案,那么 1 分 45 秒也绝非不可接受。
但如果我们正在构建数据处理管线,并且用以上种种方法把代码执行速度提高了 4 倍、甚至是 26 倍,那么不仅用户体验会更好,也能节约下大量计算成本。换言之,系统负载水平更低,且计算成本很可能只是原先的 1/4 甚至 1/26!
或者,如果大家正在构建像 GraalVM 这样的运行时,或者像 Ben Hoyt 的 GoAWK 这种解释器,那这样的性能差异将极为重要:解释器的速度越快,一切用户程序的运行速度都将同步提升。
哪怕退一万步,单纯尝试让代码充分发挥机器性能本身也是种既有益、也有趣的尝试,不是吗?
参考链接:
https://benhoyt.com/writings/go-1brc/
https://www.morling.dev/blog/one-billion-row-challenge/
往期推荐
我是 polarisxu,北大硕士毕业,曾在 360 等知名互联网公司工作,10多年技术研发与架构经验!2012 年接触 Go 语言并创建了 Go 语言中文网!著有《 Go语言编程之旅 》、开源图书《 Go语言标准库 》等。
坚持输出技术(包括 Go、Rust 等技术)、职场心得和创业感悟!欢迎关注「polarisxu」一起成长!也欢迎加我微信好友交流: gopherstudio