
2021年了,对话系统凉透了吗?
共 5797字,需浏览 12分钟
·
2022-02-09 17:28
最近,经常被问到“拿到了做对话的offer,还值得去吗”,作为一名工作近两年,涉身工业届对话产品的初级社畜,来聊聊作为业内人的看法。
写下这篇文章,也算是对自己在头部大厂2年算法岗炼丹经历的一个经验浓缩和总结。时间倒退到2018年,从我找算法岗实习开始,先问两个问题暖个身:
Q1: 2018年工业界最火的算法岗是什么?
答:CV、NLP、推荐。
Q2: 2018年工业界招人最多的NLP方向是什么?
答:对话系统、机器翻译。
虽然当时还在读研的我沉溺于做着文本表示、模型鲁棒性相关的工作,但是,一方面目睹了小度、天猫精灵、小爱同学为代表的C端对话产品正面厮杀,另一方面领略了10086和各大银行APP里宛如智障般的智能客服和“正在接入人工客服,您前面还有999+人”。当时的我觉得,对话系统要给这个世界带来一波重要的变革了,它将是最能让大众体验人工智能技术的产品了。


抱着这个坚(天)定(真)的信念,先是轻松屠了当年某知名的智能客服天池竞赛的榜单,然后义无反顾的将简历投到了那个将AI、对话作为公司核心战略的大厂。很开心,顺利拿到了实习和秋招提前批special offer。没成想,最想去的团队,一下子就去了,以至于事后都有些遗憾没体验过其他小伙伴口中惊心动魄的秋招。
至此,我与对话系统的故事正式开始了。


# 谈谈对话这个“顶流”行业
先简单介绍下全球视角下的工业界对话产品发展史吧,行内的小伙伴可以快速跳过。
2011年,世界闻名的人机大战主角——IBM的Wastson,在智力竞猜节目中战胜人类,向全世界宣告了计算机拥有了自然语言理解能力和人机对话能力。同年,乔布斯收购Siri,Siri担起了苹果向AI领域进军的大旗,作为智能数字助理搭载在iPhone上。2014年,微软在中国区发布会上发布了第一款个人智能助理Cortana(中文名小娜);同年,亚马逊推出自己的智能语音助理Alexa和智能音箱Echo,凭借新颖性和稳定性迅速占据了全球市场。2016年谷歌也完成了它的对话产品-谷歌assistant。
到了2017年,中国本土的对话产品开始觉醒、登场。17年下半年,阿里的天猫精灵、小米的小爱同学正式推出,2018年,百度的小度智能音箱,以及华为AI音箱相继跟上,这些头部大厂率先抢占了市场和人心,而后第二梯队的思必驰、出门问问等产品又进一步参与了对话市场的瓜分。
# 初露锋芒
看起来一片欣欣向荣啊,怎么会跟“凉”扯上关系呢?
首先,C端对话产品成本巨大但盈利空间不明朗,加上激烈的市场竞争,一边是用户打开了新世界的大门,直呼nb!另一边,企业在头疼变现手段,在线广告?电商推荐?会员付费?硬件输出?似乎传统的商业模式在这个场景下都能搞搞,仔细一看又发现似乎都不太能大搞。
长期高额的技术投入却得不到真金白银的反馈,怎么办呢?于是企业将目光投向了B端市场。电信运营商、银行、政务司法、能源电力等各大传统行业都需要部署大量的人工客服,客服就是一个天然的对话场景,如果用对话技术替代掉人工坐席,不仅降低人力成本而且提升服务效率,况且传统企业面临技术更新转型,纷纷想踏上AI这趟快车,所以智能客服的前景一片春天呐。


# 谈谈需求和技术
当我真正开始战斗在企业对话产品的一线,却发现事情没有那么简单。下面我们讲讲技术话题~
工业界对话系统的核心目的是通过人机对话接口让机器为用户提供服务。这里的服务可以是解答用户一个疑问,帮用户办理一件事,或者是单纯的聊天(情感服务),这三个核心需求对应的技术模块分别是:
- 问答(基于FAQ、文档、表格、KG等)
- 任务式对话
- 闲聊
请记下这三个需求和三套对应的技术模块,接下来这三点将分别简称为一类需求、二类需求和三类需求,并贯穿本文重点内容。
三类需求:闲聊
显然,前两个需求都是在满足用户的刚需,而最后一个需求,抖音不香么?吃鸡不好玩吗?陌陌用过吗?淘宝两块钱的陪聊不满足吗?
一句话讲,工业界对话系统最能满足用户刚需,创造商业价值的更多还是在于问答和任务式对话,微软小冰的结局正是对第三条需求的证伪。
有人说,闲聊的商业化之所以失败,是因为闲聊技术不够成熟!只要我预训练模型足够大,等我打败了Google的Meena[1],Facebook的Blender[2],微软的DialoGPT[3],百度的PLATO[4],我就能像人一样逼真幽默,会聊天了!想象一下,哪怕你做到了像人一样会聊天,又能怎样呢?满足情感和娱乐化需求,创造大规模商业价值,那你的对手将会是整个文娱产业。游戏、短视频、网剧、音乐,甚至陌生人社交APP,一个终于做到像人的产品能干掉哪个呢?
当然了,你如果说要再给这个闲聊系统装一个肉体,那当我没说。。。可能确实有更大的商业化想象空间,就要看下法律、伦理答不答应。。。证伪了第三类需求,再来说说第一类需求——问答。
一类需求:问答
没错,“解答用户一个疑问”看起来是很刚需的功能。但仔细一想,百度做了20年,知乎做了10年,不就是这个需求吗?
问答是什么?就是精准满足用户query,那就可以理解成百度搜索的TOP1搜索结果,或者知乎上的回答最高赞。换句话讲,就是做一个缩小版、精准版、垂直版的搜索引擎。这下你是不是可以理解为什么出道最晚的小度,反而会比天猫精灵和小爱音箱“更聪明”了?
既然都说了可以用搜索引擎的方式去满足对话的第一个需求,那去做不就是啦?有啥好凉的呢?
首先来说说理想层面。问答,或者说搜索TOP1,中文做的最好的显然就是某度了。大家可能平时搜索时都有遇到这种前端样式。

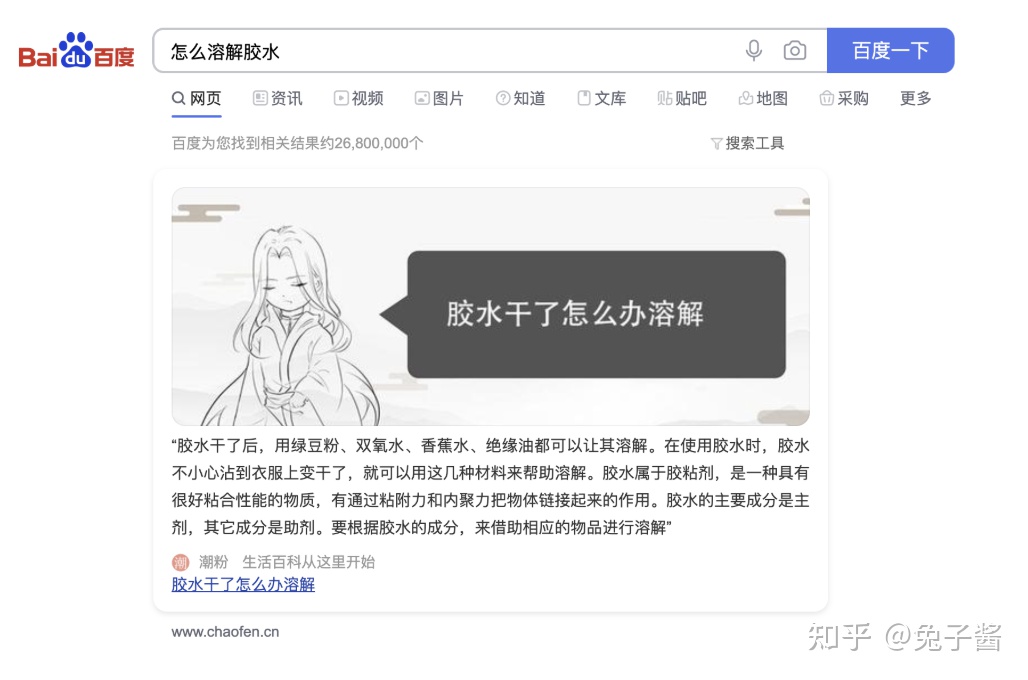
这就是搜索TOP1问答的典型场景。如果每次用户在对话产品中的提问都像在通用搜索引擎中这样这么理想、生活化就好了。但是不知道大家有没有试过在百度里面搜索一些稍微冷门的问题?比如:

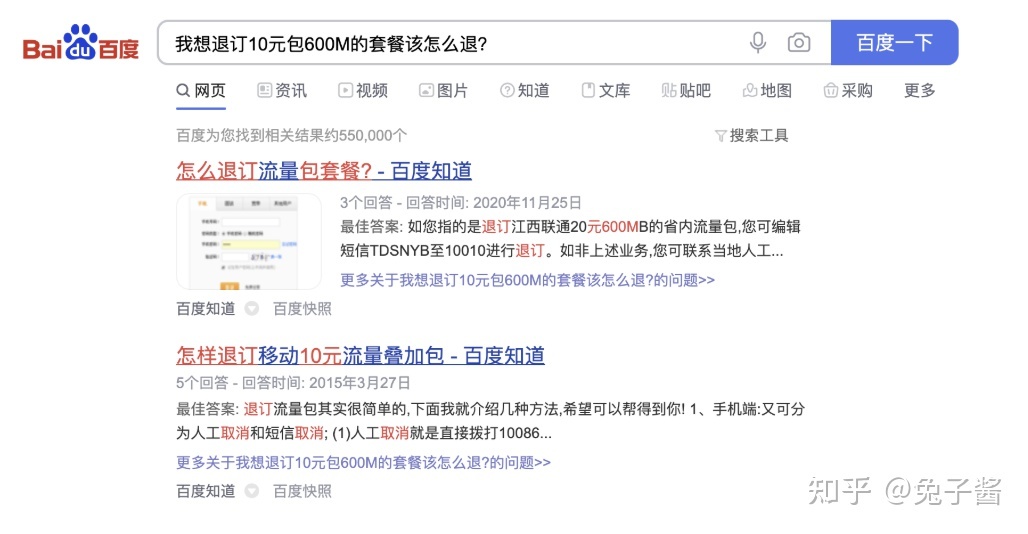
你会发现根本没有搜索TOP1问答卡片的影子了。然而,这种垂直行业、细节化的用户query恰恰是对话产品第一类需求中的高频问题!在通用搜索中,由于TOP1的准确率要求非常高,因此面对这种冷门、细节化的query,模型回答不了可以直接展现搜索的相关结果,让用户自己去底下找答案。但是,在对话产品中,几乎注定了是一问一答,如果你没有高精准的找到那个TOP1的回答,那你几乎只能跟用户说“对不起,我好像不明白”。然后用户就“玛德智障!给我转人工!”


尽管学术界对问答对匹配问题研究的挺彻底了,但是SOTA模型放在业务数据中翻车的情况太常见了,所以脱离了业务的模型不算好模型。问答对的质量决定了模型效果的上限,更何况随着数据的增加,问题之间的边界模糊和交叉现象会进一步增加匹配的难度。
当然,我们做问答引擎的过程中,在搜索范式之外,可以增加针对问答场景设计的辅助模块,来缓解无法精准回答的尴尬局面,比如在召回、精排和后处理阶段增加复杂的处理逻辑。可是,若要同时做到垂直而精准,同时还试图通用化,用一套模型/系统实现跨场景跨行业的大规模落地变现,在现有技术范式下几乎是一件不可能的事情。
再者,学术界的问答系统的研究重点普遍聚焦在开放域问答和阅读理解问题上,所谓迁移学习、domain adaption、预训练、小样本学习等技术,还不足以经受的住现实的考验,撑不起一个通用和垂直兼备的问答引擎,依然免不了要一个行业一个行业的做,一份数据一份数据的标。用一个模型去精准的覆盖多个场景和行业是非常不现实的。
总结一下,对话中的第一类需求表面上是一个垂直领域的搜索TOP1匹配问题,而实际操作中的难点诸多。如果技术上无法实现通用、垂直且精准的问答满足,要么技术平台方一个订单一个订单的啃,导致平台方大规模变现艰难;要么就降低标准,导致业务方的用户用脚投票,不停的对机器人喊“我要转人工”,导致业务方重金砸来的智能客服系统也没有真正节约多少运营成本。
这个问题,是我认为对话系统第一类需求的技术硬伤,是打开百亿规模市场的最大障碍。更不必说,第一类需求中还存在query描述冗长/超短、FAQ库不完备、甚至ASR解析噪声等问题。当然,相比上面的最大问题,这些优先级都可以后排。不过话说回来,毕竟算上实习,我做对话也就2年时间,目光有限,或许将来会出现更好的解法呢?
好了,第三类需求和第一类需求都聊完了。最后聊聊第二类需求,也就是任务式对话。
二类需求:任务式对话
前面讲的问答需求(一类需求)本质上是一个文本相关性问题,因此技术抽象上更多的是一个搜索、问答问题;而任务完成式需求(二类需求)由于要帮助用户完成任务目标,比如订票、订餐、查天气等,就免不了要跟系统功能性的API打交道,就注定了要做query结构化解析,即意图识别、实体槽位填充,将文本转成系统查询API。
然而,像智能音箱这种C端对话产品因为是面向所有用户的,我们无法预先知道用户所有的意图(永远不要低估一个用户的脑洞),即意图是开放域的。对于一些高频意图,如询问天气、播放周杰伦的歌等,我们可以富集、标注大量数据,甚至写个规则就搞定了。然而,对大量的长尾意图就处理困难了,不仅难以采集到充分的数据进行标注,甚至难以穷举并定义这些意图是什么。更加糟糕的是,意图的权重还是不一样的,比如“投诉”的意图识别错了,代价要比“订票”高的多。此外还有一个在论文中不会提及的真实问题,那就是如何在开放域下识别一句话“没有意图”(比如一只猫爬过用户键盘并按下了ENTER)。
再来谈实体识别,这也是学术界已经研究烂的技术了,为什么工业界还是做不好呢?
主要的原因是,实际业务中的实体不只是机构名/人名/地名这么简单和理想,而是些和业务紧密联系的专有名词,往往是某一家公司所独有的词汇。比如运营商场景中的套餐实体,“30元每月30G”,这个时候既没有足够的标注数据,套餐每隔一段时间还会变化,所以学术界的那一套NER的方法太fragile了。所以工业界采用的方法目前还是以规则为主,模型为辅。
此外,任务式对话还会面临多轮问题,这就涉及到了对话管理的概念。
工业界的对话管理的第一要义是绝对可控性,所以技术选型上都是pipeline系统,而非端到端系统(尽管学术界从2015年就有了端到端任务式对话相关的研究工作[5])。
对话管理模块是多轮对话的控制中枢,决定了对话如何进行下去以及对话的质量,作用是维护和更新对话状态以及判断系统的下一步动作。目前工业界的普遍做法是基于有限状态机,这种方法需要事前显式定义对话系统的所有可能状态,优点是可控,缺点是状态转移过程是人为定义的,一旦出现定义范围之外的情况,无法处理就变成人工智障了;此外,对于用户回答偏离业务设计的情况,怎么拉回到对话的主流程上?再比如用户前一个意图还没结束,可能就开启了下一个意图,这个时候如何处理?即使对话流程配置的很精细,也无法应对可能的突发和未知状况,这些都是实际应用中经常面临的问题。
因此,虽然学术界普遍认为任务式对话的各个子模块似乎都做的差不多了,甚至端到端也看似不少paper了,但来到真实场景,才会发现学术界的问题定义和测试集太过理想了。
联想到,很多产品都在吹“我们的产品用了XX学习,XX技术,能做到XX效果”,可是,它真的给产品的用户体验带来提升了吗?提升了多少呢?对话的痛点问题又解决了多少呢。
路在何方
在当今深度学习大风口与预训练小风口的带动下,不可否认的是NLP领域迎来一波质的飞跃,但是在对话问题上,却远远没有乐观到能一下子解决实际问题的程度。对话领域要迎来颠覆,必须有超脱于单纯的炼丹技术和预训练范式之外的突破。
这个突破是什么?我也不知道,但至少是个机器学习命题。我也一直在思考,该怎么跳出这个不断挖字典+写规则和不断标数据finetune的桎梏。我也希望真正热爱对话的学术界研究者们能将更多的精力放在对话框架层面的痛点问题上,而不单单是DSTC又屠了榜、训了个更大的闲聊模型能聊的更像人了、意图识别准确率又提升了1%。这些都不是影响对话大规模落地的痛点问题。
回到标题上来,对话系统凉透了吗?相信认真看完本文的小伙伴心里已经有了答案。对话确实很难,过去的一年里,某AI Lab解散,多个C端产品面临调整和拆分,B端业务订单难啃,难以大规模变现,学术界对话研究热点又似乎跟工业界痛点不合节拍,外界一片看衰。但,对话依然是个很有意思&有意义的研究课题,它的社会价值和人类憧憬一直没有改变。
文章是结合自己的工作经验对领域的一个思考和总结,可能会有不妥之处,留下联系方式,欢迎一起交流哇~(weixin: elec_Wang9018)
参考文献
1、Adiwardana, Daniel, et al. "Towards a human-like open-domain chatbot." arXiv preprint arXiv:2001.09977 (2020).
2、Roller, Stephen, et al. "Recipes for building an open-domain chatbot." arXiv preprint arXiv:2004.13637 (2020).
3、Zhang, Yizhe, et al. "Dialogpt: Large-scale generative pre-training for conversational response generation." arXiv preprint arXiv:1911.00536 (2019).
4、Bao, Siqi, et al. "Plato-2: Towards building an open-domain chatbot via curriculum learning." arXiv preprint arXiv:2006.16779 (2020).
5、Wen, Tsung-Hsien, David Vandyke, Nikola Mrksic, Milica Gasic, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. "A network-based end-to-end trainable task-oriented dialogue system." arXiv preprint arXiv:1604.04562(2016).