
从单体架构到分布式架构之四:数据持久化,ORM 框架之 Mybatis
关注 ▲会点代码的大叔▲,我们一起成长
这是会点代码的大叔的第 56 期分享
作者 l 会点代码的大叔
分类 l 从单独服务到分布式架构
你好,我是会点代码的大叔,这是我的系列文章【从单独服务到分布式架构】的第四篇:
《数据持久化,ORM 框架之 MyBatis》
01. 万丈高楼平地起:环境准备
02. 请求增多,单点变集群(1):负载均衡
03. 请求增多,单点变集群(2):Nginx
04. 数据持久化(1):ORM 框架之 Mybatis
05. 数据持久化(2):ORM 更高级的封装之 Spring Data JPA
06. 当数据量涨到上百万:数据库优化
07. 尽可能减少数据库压力(1):实现本地缓存
08. 尽可能减少数据库压力(2):本地缓存框架
09. 尽可能减少数据库压力(3):Redis
10. 缓存不是万能的:使用缓存时要注意的问题
11. 当数据量涨到上亿:基于 Sharding-Sphere 的分库分表
12. 领导想看汇总数据:数据的分分合合
13. 请求太多压垮应用?那就排队处理:消息队列
14. 接口可不能随便被调用:Token 认证
15. 如何让批处理任务跑的更快:分布式批处理任务
16. 分布式系统如何寻找服务地址:注册中心
17. 分布式系统如何横向扩展:客户端负载均衡
18. 一次请求跨多个请求如何监控:链路追踪
19. 分布式系统抗压三板斧:限流、降级、熔断
20. 内部服务千万,对外保持统一:API 网关
01
前置概念
01 持久化
持久化就是把数据保存到可以永久保存的存储设备中,比如磁盘。
02 JDBC
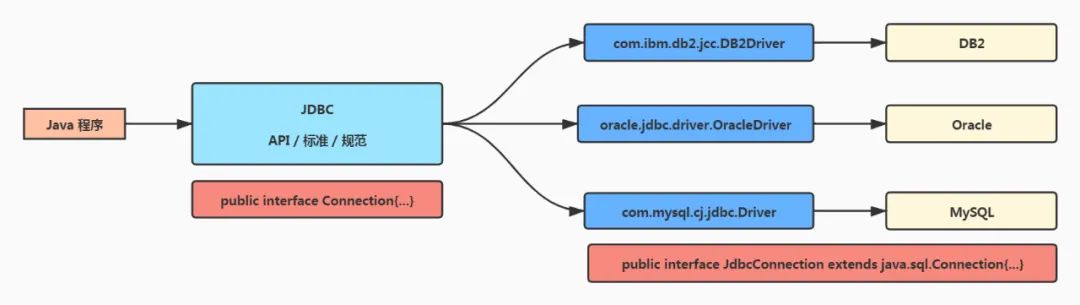
大多数程序员在学习 Java 的过程中,当学习到 Java 访问数据库的时候,一定会先学习 JDBC,它是一种用于执行 SQL 语句的 Java API,为数据库提供统一访问,并把数据“持久化”到数据库中。
我再通俗地解释一下(对 JDBC 有一定了解的同学可以直接跳过):
Sun 公司在 97 年发布 JDK1.1 ,JDBC 就是这个版本中一个重要的技术点,要用 Java 语言连接数据库,正常的思维都是 Sun 公司自己来实现如何连接数据库、如果执行 SQL 语句,但是市场上的数据库太多了,数据库之间的差异也很大,而且 Sun 公司也不可能了解每个数据库的内部细节呐...
于是为了让 Java 代码能更好地与数据库连接,Sun 公司于是制定了一系列的接口,说是接口,其实也就是一套【标准】、一套【规范】,具体代码如何实现由各个数据库厂商来敲代码;所以我们常说的“驱动类”,就是各个厂商的实现类。
所以我们在用 JDBC 连接数据库的时候,第一步需要注册驱动,就是要告诉 JVM 使用的是操作哪个数据库的实现类。
03 ORM
在没有 ORM 框架之前,我们操作数据库需要这样:

我们可以看到使用 JDBC 操作数据库,代码比较繁琐,参数拼写在 SQL 中容易出错,而且可读性比较差,增加了代码维护的难度。
有了 ORM 框架之后,我们操作数据库是这样的:
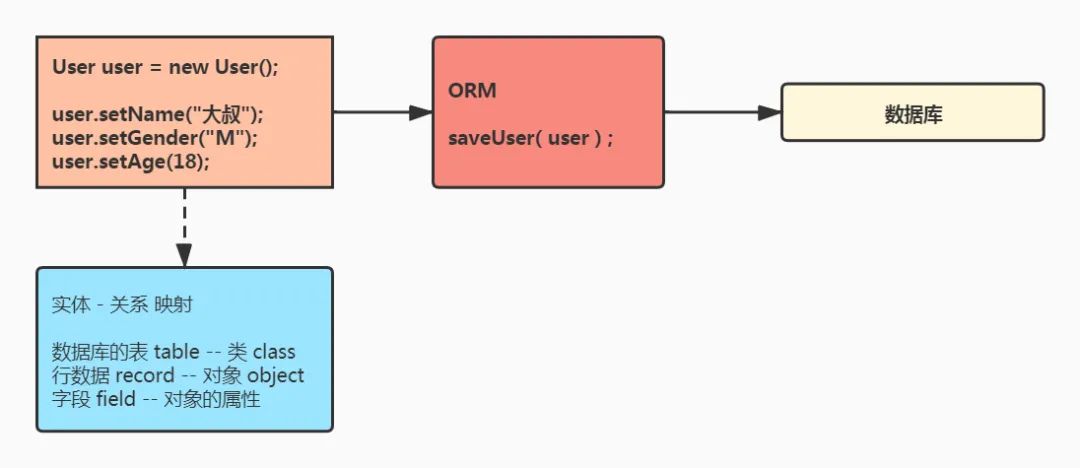
ORM 框架在 Java 对象和数据库表之间做了一个映射,封装了数据库的访问细节,我们再需要操作数据库语句的时候,直接操作 Java 对象就可以了。
02
Java 常用的 ORM 框架有 Hibernate、MyBatis、JPA 等等,我在后文中在比较这集中框架的优缺点,本章节主要介绍 Spring Boot 项目集成 MyBatis 访问数据库。
Step 1. 添加依赖
<dependency><groupId>mysqlgroupId><artifactId>mysql-connector-javaartifactId>dependency><dependency><groupId>org.mybatis.spring.bootgroupId><artifactId>mybatis-spring-boot-starterartifactId><version>2.0.1version>dependency>
Step 2. 配置数据库链接
在 application.yml 文件中配置数据库相关信息。
#数据源配置spring:datasource:#数据库驱动: com.mysql.cj.jdbc.Driver#数据库 urlurl: jdbc:mysql://127.0.0.1:3306/arch?characterEncoding=UTF-8&serverTimezone=UTC#用户名username: root#密码password: root
Step 3. 配置数据库链接
在我们本机的数据库上,创建一个用户表,并插入一条数据:
CREATE TABLE IF NOT EXISTS `user`(`id` INT UNSIGNED AUTO_INCREMENT,`userid` VARCHAR(100) NOT NULL,`username` VARCHAR(100) NOT NULL,`gender` CHAR(1) NOT NULL,`age` INT NOT NULL,PRIMARY KEY ( `id` ))ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user(userid ,username, gender, age) values('dashu','大叔','M',18);
Step 4. 创建 Model 层
通常用于接收数据库中数据的对象,我会单独创建一个 model package,类中的属性我习惯和字段保持相同。
package com.archevolution.chapter4.model;public class User {private int id;//主键ID,自增长private String userId;//用户ID,或看做登录名private String userName;//用户姓名private String gender;//性别private int age;//年龄//省略 get、set、toString 方法}
Step 5. 创建 Dao 层
通常直接和数据库打交道的代码,我们把它们放在 DAO 层(Data Access Object),数据访问逻辑全都在这里;
我们新建一个 dao package,并在下面新建一个**接口**,注意是接口:
public interface UserDao {public User queryUserById( int id);}
这里我多说几句!
从技术角度来说,model 中的属性可以和表中的字段不一样,比如我们在数据库中增加一个手机号的字段叫做 [mobilephone] :
--增加手机号字段ALTER TABLE user ADD mobilephone varchar(15) ;--更新 userid = 1 数据的手机号update user set mobilephone = '13800000000' where userid = '1';
我们在 User.java 中添加一个字段,叫做 [telephone]:
我们自己知道 [telephone] 是和数据库中的 [mobilephone] 对应,但是如何让 Mybatis 知道这两个字段要对应上呢?有几个办法:
01. 在 SQL 语句中控制,对名字不相同的字段起别名:
@Select("SELECT id, userId, userName, gender, age, mobilephone as telephone FROM USER WHERE id = #{id}")public User queryUserTelById(@Param("id") int id);
02. 使用 @Results 标签,将属性和字段不相同的设置映射(名称相同的可以不写):
@Select("SELECT id, userId, userName, gender, age, mobilephone FROM USER WHERE id = #{id}")@Results({@Result(property = "telephone" , column = "mobilephone")})public User queryUserTelById2(@Param("id") int id);
不过我还是建议大家在写 model 类的时候,属性和表中的字段保持一模一样,这样不仅可以减少代码的复杂程度,还能很大程度地增加代码的可读性,减少出错的可能;
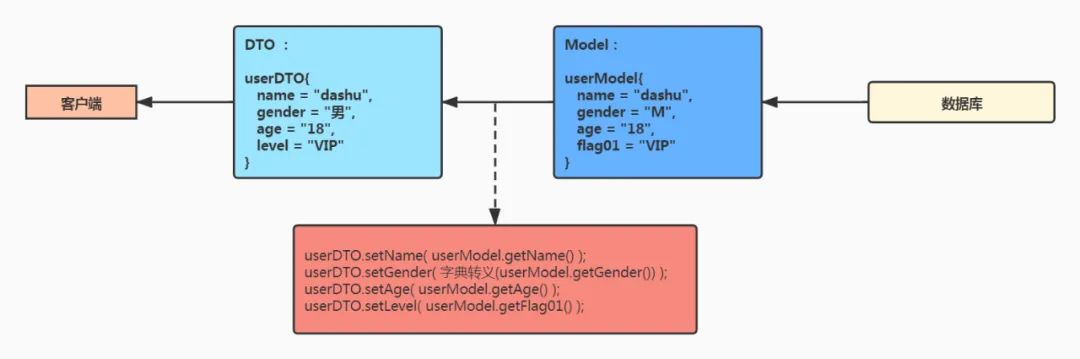
有些同学可能会有疑问,很多项目的数据结构设计的不是那么规范,比如字段名称可能是一个很奇怪的名字,比如 flag01、flag02,如果这样的字段从数据库中查询出来,通过接口返回,那么会不会造成接口的可读性太差?
通常我们不会把 model 中的内容直接包装返回,model 很多的是数据库和 Java 对象的映射,而传输数据的话,通常需要 DTO;我们从数据库中查询出来数据放到 model 中,在接口中返回数据之前,把 model 转换成 DTO,而 DTO 中的属性需要保证其规范性和见名知意。
Step 6. 创建 Service 层
我们的项目现在已经有了 Dao 层,用于访问数据,有 Controller 层,用户提供接口访问,那么 Controller 是否能直接调用 Dao 中的方法呢?最好不要直接调用!
通常我们会创建一个 Service 层,用于存放业务逻辑,这时候完整的调用流程是:
Controller - Service - Dao
创建 Service package 之后,在里面创建一个 UserService :
public class UserService {UserDao userDao;public User queryUserById(int id) {return userDao.queryUserById(id);}}
Step 7. 在 Controller 层增加接口
增加一个接口,通过 userId 查询客户信息,并返回客户信息:
public String queryUserById( int id){User user = userService.queryUserById(id);return user == null ? "User is not find" : user.toString() ;}
Step 8. 测试验证
在浏览器或客户端中访问接口进行调试测试,可以查询到客户信息:
http://127.0.0.1:8088/queryUser/1User [id=1, userId=dashu, userName=大叔, gender=M, age=18, telephone=null]
03
只给出关键代码,完整代码请参考本章节的项目代码。
01. 新增
@Insert("INSERT INTO USER(userId, userName, gender, age) values"+ " (#{userId}, #{userName}, #{gender}, #{age})")public void insertUser(User user);
02. 修改
@Update("UPDATE USER SET mobilephone = #{telephone} WHERE id = #{id}")public void updateUserTel(User user);
03. 删除
@Delete("DELETE FROM USER WHERE id = #{id}")public void deleteUserById(@Param("id") int id);
04
上面我们就完成了 Spring Boot 和 MyBatis 最简单的集成,可以正常地读取数据库做 CRUD 了,但是因为是最简单的集成,所以有一些细节需要完善一下,比如:
参数都在显示在了 url 中;
直接返回 Object.toString(), 不是很友好;
查询不到数据或发生异常,没有做特殊处理;
下面让我们逐步完善
01. 使用 Json 作为参数发送 Post 请求
如果严格地遵守 Restful 风格,那么需要遵守:
查询:GET /url/xxx
新增:POST /url
修改:PUT /url/xxx
删除:DELETE /url/xxx
在这里我们就单纯地认为把参数写在 url 中,容易一眼就看到我们的参数内容,并且如果参数比较多的时候会造成 url 过长,所以通常我们比较习惯使用 Json 作为参数发送 Post 请求。比如新增 User 的接口可以写成这样:
新增 DTO package 并新建 UserDTO:
//使用了 Josn 作为参数,需要设置 headers = {"content-type=application/json"}//@RequestBody UserDto userDto 可以让 JSON 串自动和 UserDto 绑定和转换(value = "/insertUser2",headers = {"content-type=application/json"})public String insertUser2( UserDto userDto){//DTO 转成 ModelUser user = new User();user.setUserId(userDto.getUserId());user.setUserName(userDto.getUserName());user.setGender(userDto.getGender());user.setAge(userDto.getAge());userService.insertUser(user);return "Success" ;}
新增 User 的接口:
//使用了 Josn 作为参数,需要设置 headers = {"content-type=application/json"}//@RequestBody UserDto userDto 可以让 JSON 串自动和 UserDto 绑定和转换(value = "/insertUser2",headers = {"content-type=application/json"})public String insertUser2( UserDto userDto){//DTO 转成 ModelUser user = new User();user.setUserId(userDto.getUserId());user.setUserName(userDto.getUserName());user.setGender(userDto.getGender());user.setAge(userDto.getAge());userService.insertUser(user);return "Success" ;}
让我们调用接口测试一下:
{"userId": "lisi","userName": "李四","gender": "F","age": "40","telephone": "18600000000"}
02. 规范回参
直接返回 Object.toString(), 不是很友好;
让我们设计一个简单的回参对象,包括 code-状态码,message-异常信息描述,data-数据:
public class JsonResponse {private String code;private String message;private Object data;//省略 set、get 方法}
其中 code 我们就参考 Http 状态码,使用常用的几个:
public class ResponseCode {public static final String SUCCESS = "200";//查询成功public static final String SUCCESS_NULL = "204";//查询成功,但是没有数据public static final String PARAMETERERROR = "400";//参数错误public static final String FAIL = "500";//服务器异常}
这时我们再来重写一下查询接口:
public JsonResponse queryUser2ById( UserDto userDto){JsonResponse res = new JsonResponse();//省略参数校验User user = userService.queryUserById(userDto.getUserId());if(user != null){//能查询到结果,封装到回参中res.setCode(ResponseCode.SUCCESS);res.setData(user);;}else{//如果查询不到结果,则返回 '204'res.setCode(ResponseCode.SUCCESS_NULL);res.setMessage("查询不到数据");}return res;}
调用结果可以看到封装后的回参,看起来是不是规范了很多:
{"code": "200","message": null,"data": {"id": 3,"userId": "lisi","userName": "李四","gender": "F","age": 40,"telephone": null}}
03. 异常处理
如果代码在运行过程中发生异常,那么改如何处理呢?直接把异常信息返回给前端么?这样做对调用方不是很友好,通常我们把错误日志打印到本地,给调用方返回一个异常状态码即可。
Service、Dao 层的集成都往上抛:
public User queryUserById(int userId) throws Exception{return userDao.queryUserById(userId);}
在 Controller 层抓住异常,并封装回参:
User user = new User();try {user = userService.queryUserById(userDto.getId());} catch (Exception e) {res.setCode(ResponseCode.FAIL);res.setMessage("服务异常");}
04
01. 为什么 MyBatis 被称为半自动 ORM 框架?
有半自动就会有全自动;
Hibernate 就属于全自动 ORM 框架,使用 Hibernate 可以完全根据对象关系模型进行操作,也就是指操作 Java 对象不需要写 SQL,因此是全自动的;而 MyBatis 在关联对象的时候,需要手动编写 SQL 语句,因此被称作“半自动”。
02. 使用注解还是 XML?
相信大部分项目使用 MyBatis 的时候,都是使用 XML 配置 SQL 语句,而我们课程中的例子,都是使用注解的方式,那么这两者有什么区别呢?我们在实际开发中,要如何选择呢?
首先官方是比较推荐使用 XML 的,因为使用注解的方式,拼接动态 SQL 比较费劲儿,如果你们的 SQL 比较复杂,需要多表关联,还是使用 XML 比较好;而且现在也有很多插件,可以自动生成 MyBatis XML。
但是事物总是有两方面的,复杂的 SQL 并不是值得骄傲的事情,如果你们的项目能做到没有复杂 SQL 的话,使用注解会是更好的选择(我们现在的项目 95% 以上的 SQL 都是单表查询)。
03. #{} 和 ${} 的区别是什么?
${} 是字符串替换,#{} 是预编译处理;使用 #{} 可以防止 SQL 注入,提高系统安全性。
04. 如何做批量插入?
注解的方式同样可以使用动态 SQL :
@Insert({""})public void insertUserList(@Param(value="userList") List<User> userList);
Spring Boot 集成 MyBatis 做数据库增删查改的操作,是比较基础的知识,希望对初学 Java 的人有所帮助。

从单独服务到分布式架构,希望您能和我一起,坚持到最后。
[ 用大白话讲解复杂的技术 ]