
送书 | 火遍日本 IT 界的「鱼书」终出续作!!!!

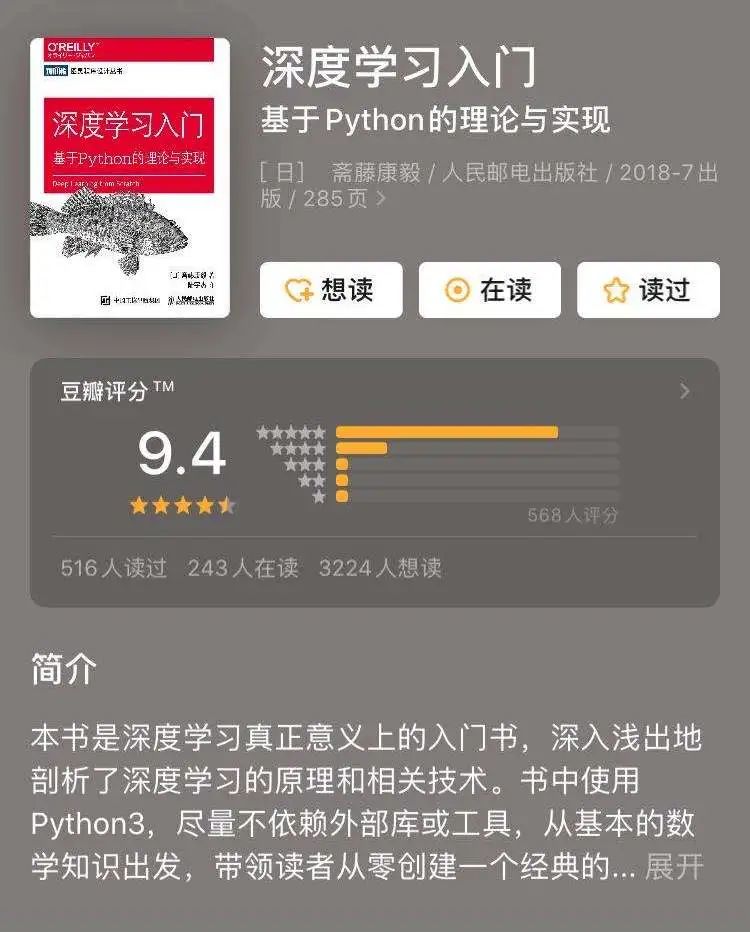

豆瓣评分9.4的畅销书《深度学习入门:基于Python的理论与实现》续作,带你快速直达自然语言处理领域!
1.简明易懂
本书内容精炼,聚焦深度学习视角下的自然语言处理,延续前作的行文风格,采用通俗的语言和大量直观的示意图详细讲解,帮助读者加深对深度学习技术的理解,轻松入门自然语言处理。
2.侧重原理
不依赖外部库,使用Python 3从零开始创建深度学习程序,通过亲自创建程序并运行,读者可透彻掌握word2vec、RNN、LSTM、GRU、seq2seq和Attention等技术背后的运行原理。
3.学习曲线平缓
按照“文字介绍→代码实现→分析结果→发现问题→进行改善”的流程,逐步深入,读者只需具备基础的神经网络和Python知识,即可轻松读懂。
4.提供源代码
内容简介
《深度学习进阶:自然语言处理》是《深度学习入门:基于Python 的理论与实现》的续作,围绕自然语言处理和时序数据处理,介绍深度学习中的重要技术,包括word2vec、RNN、LSTM、GRU、seq2seq 和Attention 等。本书语言平实,结合大量示意图和Python代码,按照“提出问题”“思考解决问题的新方法”“加以改善”的流程,基于深度学习解决自然语言处理相关的各种问题,使读者在此过程中更深入地理解深度学习中的重要技术。
作者简介
斋藤康毅(作者) 1984年生于日本长崎县,东京工业大学毕业,并完成东京大学研究生院课程。目前在某企业从事人工智能相关的研究和开发工作。著有《深度学习入门:基于Python的理论与实现》,同时也是Introducing Python、Python in Practice、The Elements of Computing Systems、Building Machine Learning Systems with Python的日文版译者。陆宇杰(译者) 长期从事自然语言处理、知识图谱、深度学习相关的研究和开发工作。译有《深度学习入门:基于Python的理论与实现》。
目 录
译者序 xi
前言 xiii
第1章 神经网络的复习 1
1.1 数学和Python的复习 1
1.1.1 向量和矩阵 1
1.1.2 矩阵的对应元素的运算 4
1.1.3 广播 4
1.1.4 向量内积和矩阵乘积 6
1.1.5 矩阵的形状检查 7
1.2 神经网络的推理 8
1.2.1 神经网络的推理的全貌图 8
1.2.2 层的类化及正向传播的实现 14
1.3 神经网络的学习 18
1.3.1 损失函数 18
1.3.2 导数和梯度 21
1.3.3 链式法则 23
1.3.4 计算图 24
1.3.5 梯度的推导和反向传播的实现 35
1.3.6 权重的更新 39
1.4 使用神经网络解决问题 41
1.4.1 螺旋状数据集 41
1.4.2 神经网络的实现 43
1.4.3 学习用的代码 45
1.4.4 Trainer 类 49
1.5 计算的高速化 50
1.5.1 位精度 51
1.5.2 GPU(CuPy) 52
1.6 小结 54
第2章 自然语言和单词的分布式表示 57
2.1 什么是自然语言处理 57
2.2 同义词词典 59
2.2.1 WordNet 61
2.2.2 同义词词典的问题 61
2.3 基于计数的方法 63
2.3.1 基于Python的语料库的预处理 63
2.3.2 单词的分布式表示 66
2.3.3 分布式假设 67
2.3.4 共现矩阵 68
2.3.5 向量间的相似度 72
2.3.6 相似单词的排序 74
2.4 基于计数的方法的改进 77
2.4.1 点互信息 77
2.4.2 降维 81
2.4.3 基于SVD的降维 84
2.4.4 PTB数据集 86
2.4.5 基于PTB数据集的评价 88
2.5 小结 91
第3章 word2vec 93
3.1 基于推理的方法和神经网络 93
3.1.1 基于计数的方法的问题 94
3.1.2 基于推理的方法的概要 95
3.1.3 神经网络中单词的处理方法 96
3.2 简单的word2vec 101
3.2.1 CBOW模型的推理 101
3.2.2 CBOW模型的学习 106
3.2.3 word2vec的权重和分布式表示 108
3.3 学习数据的准备 110
3.2.1 上下文和目标词 110
3.3.2 转化为one-hot 表示 113
3.4 CBOW模型的实现 114
3.5 word2vec的补充说明 120
3.5.1 CBOW模型和概率 121
3.5.2 skip-gram 模型 122
3.5.3 基于计数与基于推理 125
3.6 小结 127
第4章 word2vec的高速化 129
4.1 word2vec的改进① 129
4.1.1 Embedding层 132
4.1.2 Embedding层的实现 133
4.2 word2vec的改进② 137
4.2.1 中间层之后的计算问题 138
4.2.2 从多分类到二分类 139
4.2.3 Sigmoid 函数和交叉熵误差 141
4.2.4 多分类到二分类的实现 144
4.2.5 负采样 148
4.2.6 负采样的采样方法 151
4.2.7 负采样的实现 154
4.3 改进版word2vec的学习 156
4.3.1 CBOW模型的实现 156
4.3.2 CBOW模型的学习代码 159
4.3.3 CBOW模型的评价 161
4.4 wor2vec相关的其他话题 165
4.4.1 word2vec的应用例 166
4.4.2 单词向量的评价方法 168
4.5 小结 170
第5章 RNN 173
5.1 概率和语言模型 173
5.1.1 概率视角下的word2vec 174
5.1.2 语言模型 176
5.1.3 将CBOW模型用作语言模型? 178
5.2 RNN 181
5.2.1 循环的神经网络 181
5.2.2 展开循环 183
5.2.3 Backpropagation Through Time 185
5.2.4 Truncated BPTT 186
5.2.5 Truncated BPTT的mini-batch 学习 190
5.3 RNN的实现 192
5.3.1 RNN层的实现 193
5.3.2 Time RNN层的实现 197
5.4 处理时序数据的层的实现 202
5.4.1 RNNLM的全貌图 202
5.4.2 Time层的实现 205
5.5 RNNLM的学习和评价 207
5.5.1 RNNLM的实现 207
5.5.2 语言模型的评价 211
5.5.3 RNNLM的学习代码 213
5.5.4 RNNLM的Trainer类 216
5.6 小结 217
第6章 Gated RNN 219
6.1 RNN的问题 220
6.1.1 RNN的复习 220
6.1.2 梯度消失和梯度爆炸 221
6.1.3 梯度消失和梯度爆炸的原因 223
6.1.4 梯度爆炸的对策 228
6.2 梯度消失和LSTM 229
6.2.1 LSTM的接口 230
6.2.2 LSTM层的结构 231
6.2.3 输出门 234
6.2.4 遗忘门 236
6.2.5 新的记忆单元 237
6.2.6 输入门 238
6.2.7 LSTM的梯度的流动 239
6.3 LSTM的实现 240
6.4 使用LSTM的语言模型 248
6.5 进一步改进RNNLM 255
6.5.1 LSTM层的多层化 256
6.5.2 基于Dropout抑制过拟合 257
6.5.3 权重共享 262
6.5.4 更好的RNNLM的实现 263
6.5.5 前沿研究 269
6.6 小结 270
第7章 基于RNN生成文本 273
7.1 使用语言模型生成文本 274
7.1.1 使用RNN生成文本的步骤 274
7.1.2 文本生成的实现 278
7.1.3 更好的文本生成 281
7.2 seq2seq 模型 283
7.2.1 seq2seq 的原理 283
7.2.2 时序数据转换的简单尝试 287
7.2.3 可变长度的时序数据 288
7.2.4 加法数据集 290
7.3 seq2seq 的实现 291
7.3.1 Encoder类 291
7.3.2 Decoder类 295
7.3.3 Seq2seq 类 300
7.3.4 seq2seq 的评价 301
7.4 seq2seq 的改进 305
7.4.1 反转输入数据(Reverse) 305
7.4.2 偷窥(Peeky) 308
7.5 seq2seq 的应用 313
7.5.1 聊天机器人 314
7.5.2 算法学习 315
7.5.3 自动图像描述 316
7.6 小结 318
第8章 Attention 321
8.1 Attention 的结构 321
8.1.1 seq2seq 存在的问题 322
8.1.2 编码器的改进 323
8.1.3 解码器的改进① 325
8.1.4 解码器的改进② 333
8.1.5 解码器的改进③ 339
8.2 带Attention 的seq2seq 的实现 344
8.2.1 编码器的实现 344
8.2.2 解码器的实现 345
8.2.3 seq2seq 的实现 347
8.3 Attention 的评价 347
8.3.1 日期格式转换问题 348
8.3.2 带Attention 的seq2seq 的学习 349
8.3.3 Attention 的可视化 353
8.4 关于Attention 的其他话题 356
8.4.1 双向RNN 356
8.4.2 Attention 层的使用方法 358
8.4.3 seq2seq 的深层化和skip connection 360
8.5 Attention 的应用 363
8.5.1 Google Neural Machine Translation(GNMT) 363
8.5.2 Transformer 365
8.5.3 Neural Turing Machine(NTM) 369
8.6 小结 373
附录A sigmoid 函数和tanh 函数的导数 375
A.1 sigmoid 函数 375
A.2 tanh 函数 378
A.3 小结 380
附录B 运行WordNet 381
B.1 NLTK的安装 381
B.2 使用WordNet获得同义词 382
B.3 WordNet和单词网络 384
B.4 基于WordNet的语义相似度 385
附录C GRU 387
C.1 GRU的接口 387
C.2 GRU的计算图 388
后记 391
参考文献 395

本次送书3本
或者扫一扫下方的二维码回复:送书 即可!