MySQL的死锁系列- 锁的类型以及加锁原理
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
疫情期间在家工作时,同事使用了 insert into on duplicate key update 语句进行插入去重,但是在测试过程中发生了死锁现象:
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
由于开发任务紧急,只是暂时规避了一下,但是对触发死锁的原因和相关原理不甚了解,于是这几天一直在查阅相关资料,总结出一个系列文章供大家参考,本篇是上篇,主要介绍 MySQL 加锁原理和锁的不同模式或类型的基本知识。后续会讲解常见语句的加锁情况和通过 MySQL 死锁日志分析死锁原因。
由于本篇文章涉及很多 MySQL 的基础知识,大家可以自行阅读我之前的 MySQL系列文章 《MySQL探秘》(公众号菜单处可进入系列文章)中的对应章节。
表锁和行锁
我们首先来了解一下表锁和行锁:表锁是指对一整张表加锁,一般是 DDL 处理时使用;而行锁则是锁定某一行或者某几行,或者行与行之间的间隙。
表锁由 MySQL Server 实现,行锁则是存储引擎实现,不同的引擎实现的不同。在 MySQL 的常用引擎中 InnoDB 支持行锁,而 MyISAM 则只能使用 MySQL Server 提供的表锁。
表锁
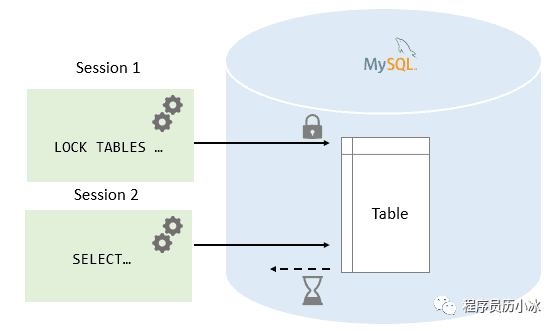
表锁由 MySQL Server 实现,一般在执行 DDL 语句时会对整个表进行加锁,比如说 ALTER TABLE 等操作。在执行 SQL 语句时,也可以明确指定对某个表进行加锁。
mysql> lock table user read(write); # 分为读锁和写锁
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 100; # 成功
mysql> select * from role where id = 100; # 失败,未提前获取该 role的读表锁
mysql> update user set name = 'Tom' where id = 100; # 失败,未提前获得user的写表锁
mysql> unlock tables; # 显示释放表锁
Query OK, 0 rows affected (0.00 sec)
表锁使用的是一次性锁技术,也就是说,在会话开始的地方使用 lock 命令将后续需要用到的表都加上锁,在表释放前,只能访问这些加锁的表,不能访问其他表,直到最后通过 unlock tables 释放所有表锁。
除了使用 unlock tables 显示释放锁之外,会话持有其他表锁时执行lock table 语句会释放会话之前持有的锁;会话持有其他表锁时执行 start transaction 或者 begin 开启事务时,也会释放之前持有的锁。
行锁
不同存储引擎的行锁实现不同,后续没有特别说明,则行锁特指 InnoDB 实现的行锁。
在了解 InnoDB 的加锁原理前,需要对其存储结构有一定的了解。InnoDB 是聚簇索引,也就是 B+树的叶节点既存储了主键索引也存储了数据行。而 InnoDB 的二级索引的叶节点存储的则是主键值,所以通过二级索引查询数据时,还需要拿对应的主键去聚簇索引中再次进行查询。关于 InnoDB 和 MyISAM 的索引的详细知识可以阅读《Mysql探索(一):B+Tree索引》一文。
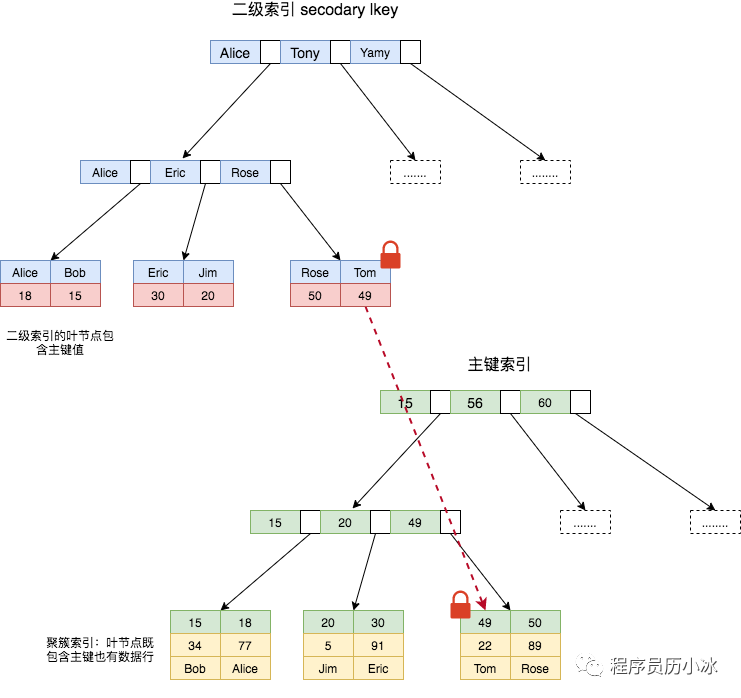
下面以两条 SQL 的执行为例,讲解一下 InnoDB 对于单行数据的加锁原理。
update user set age = 10 where id = 49;
update user set age = 10 where name = 'Tom';
第一条 SQL 使用主键索引来查询,则只需要在 id = 49 这个主键索引上加上写锁;第二条 SQL 则使用二级索引来查询,则首先在 name = Tom 这个索引上加写锁,然后由于使用 InnoDB 二级索引还需再次根据主键索引查询,所以还需要在 id = 49 这个主键索引上加写锁,如上图所示。
也就是说使用主键索引需要加一把锁,使用二级索引需要在二级索引和主键索引上各加一把锁。
根据索引对单行数据进行更新的加锁原理了解了,那如果更新操作涉及多个行呢,比如下面 SQL 的执行场景。
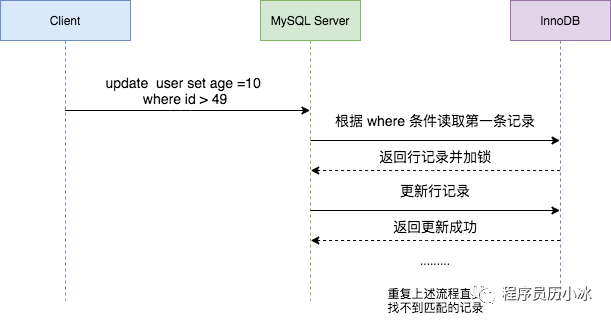
update user set age = 10 where id > 49;
上述 SQL 的执行过程如下图所示。MySQL Server 会根据 WHERE 条件读取第一条满足条件的记录,然后 InnoDB 引擎会将第一条记录返回并加锁,接着 MySQL Server 发起更新改行记录的 UPDATE 请求,更新这条记录。一条记录操作完成,再读取下一条记录,直至没有匹配的记录为止。
这种场景下的锁的释放较为复杂,有多种的优化方式,我对这块暂时还没有了解,还请知道的小伙伴在下方留言解释。
下面主要依次介绍 InnoDB 中锁的模式和类型,锁的类型是指锁的粒度或者锁具体加在什么地方;而锁模式描述的是锁的兼容性,也就是加的是什么锁,比如写锁或者读锁。
内容基本来自于 MySQL 的技术文档 innodb-lock 一章,感兴趣的同学可以直接去阅读原文,原文地址为见文章末尾。
行锁的模式
锁的模式有:读意向锁,写意向锁,读锁,写锁和自增锁(auto_inc),下面我们依次来看。
读写锁
读锁,又称共享锁(Share locks,简称 S 锁),加了读锁的记录,所有的事务都可以读取,但是不能修改,并且可同时有多个事务对记录加读锁。
写锁,又称排他锁(Exclusive locks,简称 X 锁),或独占锁,对记录加了排他锁之后,只有拥有该锁的事务可以读取和修改,其他事务都不可以读取和修改,并且同一时间只能有一个事务加写锁。
读写意向锁
由于表锁和行锁虽然锁定范围不同,但是会相互冲突。所以当你要加表锁时,势必要先遍历该表的所有记录,判断是否加有排他锁。这种遍历检查的方式显然是一种低效的方式,MySQL 引入了意向锁,来检测表锁和行锁的冲突。
意向锁也是表级锁,也可分为读意向锁(IS 锁)和写意向锁(IX 锁)。当事务要在记录上加上读锁或写锁时,要首先在表上加上意向锁。这样判断表中是否有记录加锁就很简单了,只要看下表上是否有意向锁就行了。
意向锁之间是不会产生冲突的,也不和 AUTO_INC 表锁冲突,它只会阻塞表级读锁或表级写锁,另外,意向锁也不会和行锁冲突,行锁只会和行锁冲突。
自增锁
AUTOINC 锁又叫自增锁(一般简写成 AI 锁),是一种表锁,当表中有自增列(AUTOINCREMENT)时出现。当插入表中有自增列时,数据库需要自动生成自增值,它会先为该表加 AUTOINC 表锁,阻塞其他事务的插入操作,这样保证生成的自增值肯定是唯一的。AUTOINC 锁具有如下特点:
AUTO_INC 锁互不兼容,也就是说同一张表同时只允许有一个自增锁;
自增值一旦分配了就会 +1,如果事务回滚,自增值也不会减回去,所以自增值可能会出现中断的情况。
显然,AUTOINC 表锁会导致并发插入的效率降低,为了提高插入的并发性,MySQL 从 5.1.22 版本开始,引入了一种可选的轻量级锁(mutex)机制来代替 AUTOINC 锁,可以通过参数 innodbautoinclockmode 来灵活控制分配自增值时的并发策略。具体可以参考 MySQL 的 AUTOINCREMENT Handling in InnoDB 一文,链接在文末。
不同模式锁的兼容矩阵
下面是各个表锁之间的兼容矩阵。
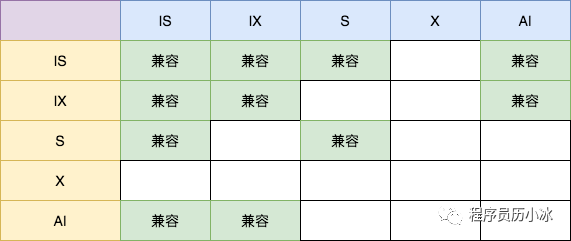
总结起来有下面几点:
意向锁之间互不冲突;
S 锁只和 S/IS 锁兼容,和其他锁都冲突;
X 锁和其他所有锁都冲突;
AI 锁只和意向锁兼容;
行锁的类型
根据锁的粒度可以把锁细分为表锁和行锁,行锁根据场景的不同又可以进一步细分,依次为 Next-Key Lock,Gap Lock 间隙锁,Record Lock 记录锁和插入意向 GAP 锁。
不同的锁锁定的位置是不同的,比如说记录锁只锁住对应的记录,而间隙锁锁住记录和记录之间的间隔,Next-Key Lock 则所属记录和记录之前的间隙。不同类型锁的锁定范围大致如下图所示。
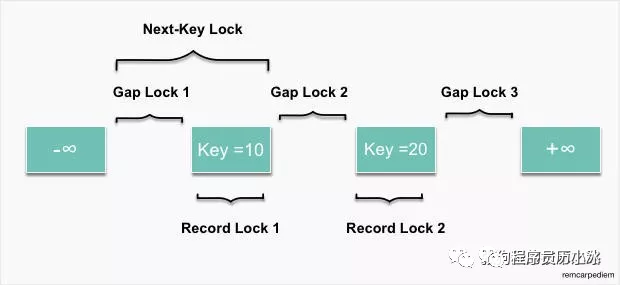
下面我们来依次了解一下不同的类型的锁。
记录锁
记录锁是最简单的行锁,并没有什么好说的。上边描述 InnoDB 加锁原理中的锁就是记录锁,只锁住 id = 49 或者 name = 'Tom' 这一条记录。
当 SQL 语句无法使用索引时,会进行全表扫描,这个时候 MySQL 会给整张表的所有数据行加记录锁,再由 MySQL Server 层进行过滤。但是,在 MySQL Server 层进行过滤的时候,如果发现不满足 WHERE 条件,会释放对应记录的锁。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。
所以更新操作必须要根据索引进行操作,没有索引时,不仅会消耗大量的锁资源,增加数据库的开销,还会极大的降低了数据库的并发性能。
间隙锁
还是最开始更新用户年龄的例子,如果 id = 49 这条记录不存在,这个 SQL 语句还会加锁吗?答案是可能有,这取决于数据库的隔离级别。这种情况下,在 RC 隔离级别不会加任何锁,在 RR 隔离级别会在 id = 49 前后两个索引之间加上间隙锁。
间隙锁是一种加在两个索引之间的锁,或者加在第一个索引之前,或最后一个索引之后的间隙。这个间隙可以跨一个索引记录,多个索引记录,甚至是空的。使用间隙锁可以防止其他事务在这个范围内插入或修改记录,保证两次读取这个范围内的记录不会变,从而不会出现幻读现象。
值得注意的是,间隙锁和间隙锁之间是互不冲突的,间隙锁唯一的作用就是为了防止其他事务的插入,所以加间隙 S 锁和加间隙 X 锁没有任何区别。
Next-Key 锁
Next-key锁是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁。假设一个索引包含
15、18、20 ,30,49,50 这几个值,可能的 Next-key 锁如下:
(-∞, 15],(15, 18],(18, 20],(20, 30],(30, 49],(49, 50],(50, +∞)
通常我们都用这种左开右闭区间来表示 Next-key 锁,其中,圆括号表示不包含该记录,方括号表示包含该记录。前面四个都是 Next-key 锁,最后一个为间隙锁。和间隙锁一样,在 RC 隔离级别下没有 Next-key 锁,只有 RR 隔离级别才有。还是之前的例子,如果 id 不是主键,而是二级索引,且不是唯一索引,那么这个 SQL 在 RR 隔离级别下就会加如下的 Next-key 锁 (30, 49](49, 50)
此时如果插入一条 id = 31 的记录将会阻塞住。之所以要把 id = 49 前后的间隙都锁住,仍然是为了解决幻读问题,因为 id 是非唯一索引,所以 id = 49 可能会有多条记录,为了防止再插入一条 id = 49 的记录。
插入意向锁
插入意向锁是一种特殊的间隙锁(简写成 II GAP)表示插入的意向,只有在 INSERT 的时候才会有这个锁。注意,这个锁虽然也叫意向锁,但是和上面介绍的表级意向锁是两个完全不同的概念,不要搞混了。
插入意向锁和插入意向锁之间互不冲突,所以可以在同一个间隙中有多个事务同时插入不同索引的记录。譬如在上面的例子中,id = 30 和 id = 49 之间如果有两个事务要同时分别插入 id = 32 和 id = 33 是没问题的,虽然两个事务都会在 id = 30 和 id = 50 之间加上插入意向锁,但是不会冲突。
插入意向锁只会和间隙锁或 Next-key 锁冲突,正如上面所说,间隙锁唯一的作用就是防止其他事务插入记录造成幻读,正是由于在执行 INSERT 语句时需要加插入意向锁,而插入意向锁和间隙锁冲突,从而阻止了插入操作的执行。
不同类型锁的兼容矩阵
不同类型锁的兼容下如下图所示。
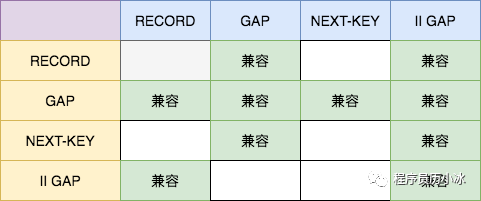
其中,第一行表示已有的锁,第一列表示要加的锁。插入意向锁较为特殊,所以我们先对插入意向锁做个总结,如下:
插入意向锁不影响其他事务加其他任何锁。也就是说,一个事务已经获取了插入意向锁,对其他事务是没有任何影响的;
插入意向锁与间隙锁和 Next-key 锁冲突。也就是说,一个事务想要获取插入意向锁,如果有其他事务已经加了间隙锁或 Next-key 锁,则会阻塞。
其他类型的锁的规则较为简单:
间隙锁不和其他锁(不包括插入意向锁)冲突;
记录锁和记录锁冲突,Next-key 锁和 Next-key 锁冲突,记录锁和 Next-key 锁冲突;
后记
下一篇文章我们来看一下具体 SQL 的加锁分析和死锁日志分析,请小伙伴多多留意和关注,有问题的可以文章下方留言。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈