
一个关于hashCode的追问!
起因是群里的一位童鞋突然问了这么问题:
如果重写 equals 不重写 hashcode 会有什么影响?
这个问题从上午10:45 开始陆续讨论,到下午15:39 接近尾声 (忽略这形同虚设的马赛克)
这是一个好问题,更是一个高频基础面试题,我还曾经专门写过一篇文章 Java equals 和 hashCode 的这几个问题可以说明白吗, 主要说明了以下内容

随着讨论的进行,问题慢慢集中在内存溢出和内存泄漏的问题上
内存溢出 VS 内存泄漏
这两个词在中文解释上有些相似,至少给我的第一感觉,他们的差别是这样的(有人和我一样吗?)

内存溢出:Out of Memory (OOM) ,这个大家都很熟悉了,理解起来也很简单,就是内存不够用了(啤酒【对象】太多,杯子【内存】装不下了)
那啥是内存泄漏呢?
内存泄漏:Memory Leak
特意查了一下 Leak 的字典含义,解释1的直白翻译是【通常是由于错误或失误,从一个开口 进入或逃脱】
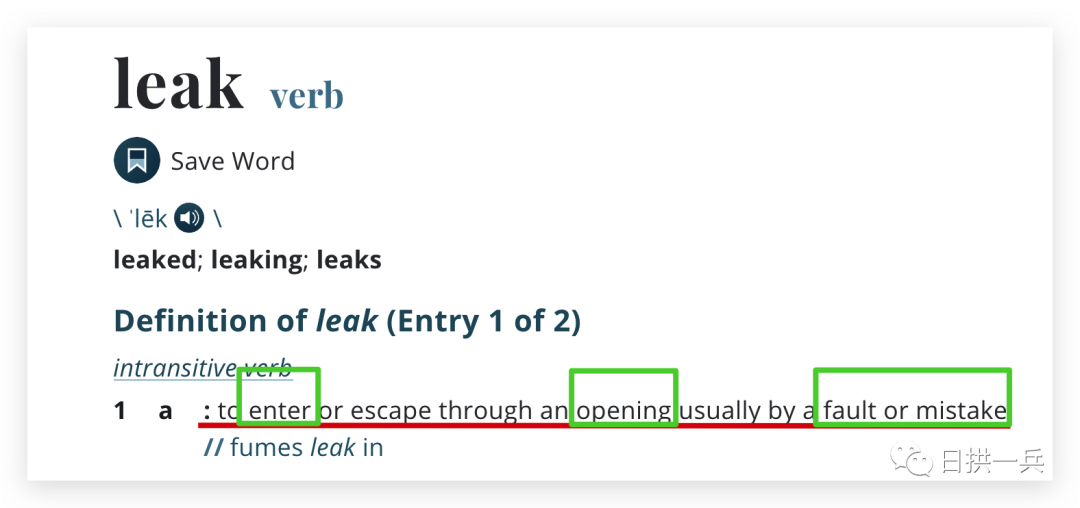
所以程序中的内存泄漏我的理解更多是:由于程序的编写错误暴漏出一些 开口,导致一些对象进入这写开口,最终导致相关问题,进一步说白了,程序有漏洞,不当的调用就会出问题
所以接下来我们主要来看看 Java 内存泄漏,以及问题的起因 hashCode 和内存泄漏到底有哪些关系
内存泄漏
咱也是一个有身份证的人,不能总讲大白话,相对官方的内存泄漏解释是这样滴:
内存泄漏说明的是这样一种情况:堆中存在一些不再使用的对象,但垃圾收集器无法将它们从内存中删除(垃圾收集器定期删除未引用的对象,但从不收集仍在引用的对象),因此对它们进行了不必要的维护
这句话略显抽象,一张图你就能明白

如果有用的、但垃圾收集器又不能删除的对象增多,就像下图这样,那么就会逐渐导致内存溢出(OOM)了

所以也可以总结为,OOM 的原因之一可能是内存泄漏导致的
内存泄漏会带来哪些问题
内存泄漏,会导致真正可用内存变少,在没达到 OOM 的这个过程中,就会出现奇奇怪怪的问题
当应用程序长时间连续运行时,性能会严重下降,毕竟可用内存变小 自发的和奇怪的应用程序崩溃 应用程序偶尔会耗尽连接对象(这个经常听说吧) 最终的结果是 OOM
所以也可以反过来推理,如果发生上述问题,有可能程序的某些地方发生了内存泄漏
那常见的哪些情形可能会引起内存泄漏呢?又有哪些解决办法呢?
会引起内存泄漏的常见情形与相应解决办法
静态成员变量的乱用
直接来看一个例子
@Slf4j
public class StaticTest {
public static List<Double> list = new ArrayList<>();
public void populateList() {
for (int i = 0; i < 10000000; i++) {
list.add(Math.random());
}
}
public static void main(String[] args) {
new StaticTest().populateList();
}
}
populateList() 是一个 public 方法,可能被各种调用,导致 list 无限增大
解决办法
解决办法很简单,针对这种情形(也就是通常所说的长周期对象引用短周期对象),就是将 list 放到方法内部,方法栈帧执行完自动就会被回收了
public void populateList() {
List<Double> list = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
list.add(Math.random());
}
}
有童鞋可能有疑问:
看 Spring 源码时有好多是 static 修饰的成员变量,难道它们也会导致内存泄漏?
不是的,如果你仔细看逻辑,它们都是是在容器初始化的过程中一次性加载的,所以不会像 populateList 随着调用次数的增加,无限撑大 List
未关闭的流
在学习流的时候老师就在耳边反复说:
一定要关闭流... 闭流... 流... 㐬... 儿...
因为每当我们建立一个新的连接或打开一个流时(比如数据库连接、输入流和会话对象),JVM都会为这些资源分配内存,如果不关闭,这就是占用空间"有用"的对象, GC 就不会回收他们,当请求很大,来个请求就新建一个流,最终都还没关闭,结果可想而知
解决办法
流的解决办法很简单,其实主要遵循相应范式就可以避免此类问题
通过 try/catch/finally范式在 finally 关掉流 如果你用的 Java 7+ 的版本,也可以用 try-with-resources, 这样代码在编译后会自动帮你关闭流也可以使用 Lombok 的 @Cleanup 注解, 就像下面这样
@Cleanup InputStream jobJarInputStream = new URL(jobJarUrl).openStream();
@Cleanup OutputStream jobJarOutputStream = new FileOutputStream(jobJarFile);
IOUtils.copy(jobJarInputStream, jobJarOutputStream);
不正确的 equals 和 hashCode 实现
又回到了这两个函数上,有很大一部分程序员不会主动重写 equals 和 hashCode,尤其是用 Lombok @Data 注解(该注解默认会帮助重写这两个函数)后,更会忽视这两个方法实现,一不小心的使就可能引起内存泄漏
来看个非常简单的例子:
public class MemLeakTest {
public static void main(String[] args) throws InterruptedException {
Map<Person, String> map = new HashMap<>();
Person p1 = new Person("zhangsan", 1);
Person p2 = new Person("zhangsan", 1);
Person p3 = new Person("zhangsan", 1);
map.put(p1, "zhangsan");
map.put(p2, "zhangsan");
map.put(p3, "zhangsan");
System.out.println(map.entrySet().size()); // 运行结果:3
}
}
@Getter
@Setter
class Person {
private String name;
private Integer id;
public Person(String name, Integer id){
this.name = name;
this.id = id;
}
}
Person 类没有重写 hashCode 方法,那 Map 的 put 方法就会调用 Object 默认的 hashCode 方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
p1, p2, p3 在【业务】属性上是完全相同的三个对象,由于「对象地址」的不同导致生成的 hashCode 不一样,最终都被放到 Map 中,这就会导致业务重复对象占用空间,所以这也是内存泄漏的一种
解决办法
解决办法很简单,在 Person 上加一个 Lombok 的 @Data 注解自动帮你重写 hashCode 方法,或手动在 IDE 中 generate,再次运行,结果就为 1了,符合业务需求
那重写了 hashCode 确实可以避免重复对象的加入,那这就完事大吉了吗, 再来看个例子
public static void main(String[] args) throws InterruptedException {
// 注意: HashSet 的底层也是 Map 结构
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("zhangsan", 1);
Person p2 = new Person("lisi", 2);
Person p3 = new Person("wanger", 3);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println(set.size()); // 运行结果:3
p3.setName("wangermao");
set.remove(p3);
System.out.println(set.size()); // 运行结果:3
set.add(p3);
System.out.println(set.size()); // 运行结果:4
}
从运行结果中来看,很显然 set.remove(p3) 没有删除成功,因为 p3.setName("wangermao") 后,重新计算 p3 的 hashCode 会发生变化,所以 remove 的时候会找不到相应的 Node,这就又给了增加相同对象的“机会”,导致业务中无用的对象被引用着,所以可以说这也是内存泄漏的一种。运行结果来看:
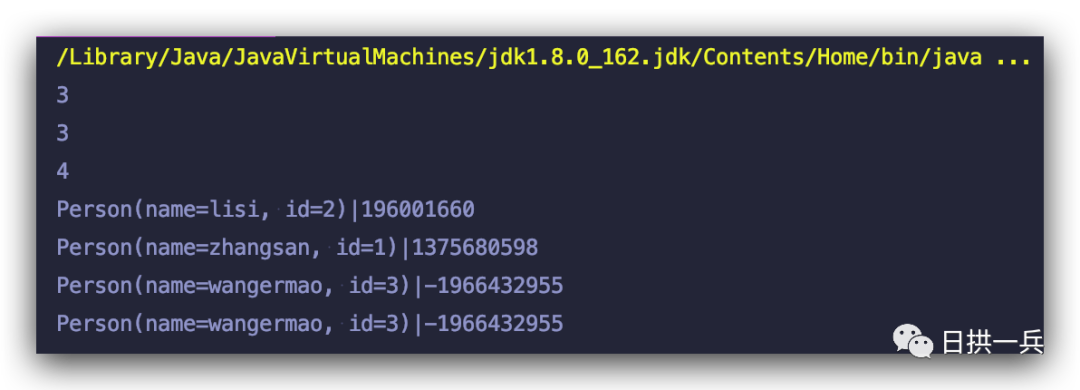
所以诸如此类操作,最好是先 remove,然后更改属性,最后再重新 add 进去
看到这,你应该发现了,要解决 hashCode 相关的问题,你要充分了解集合的特性,更要留意类是否重写了该方法以及它们的实现方式,避免出现内存泄漏情况
ThreadLocal
群消息中的最后,小姐姐 留下【ThreadLocal】几个字,深藏功与名的离开了,一看就是高手
ThreadLocal 是面试多线程的高频考点,它的好处是可以快速方便的做到线程隔离,但大家也都知道他是一把双刃剑,因为使用不好就有可能导致内存泄漏了
实际工作中我们都是使用线程池来管理线程 「具体请参考 我会手动创建线程,为什么要使用线程池」,这种方式可以让线程得到反复利用(故意不让 GC 回收),
现在,如果任何类创建了一个ThreadLocal变量,但没有显式地删除它,那么即使在web应用程序停止之后,该对象的副本仍将保留在工作线程中,从而阻止了该对象被垃圾收集,所以乱用也会导致内存泄漏
解决办法
解决办法依旧很简单,依旧是遵循标准
调用 ThreadLocal 的 remove()方法,移除当前线程变量值也可以将它看作一种 resource,使用 try/finally 范式,万一在运行过程中出现异常,还可以在 finally 中 remove 掉
try {
threadLocal.set(System.nanoTime());
// business code
}
finally {
threadLocal.remove();
}
我觉得小姐姐一定是高手
总的来说,引起内存泄漏的原因非常多,比如还有引用外部类的内部类等问题,这里不再展开说明,只是说明了几种非常常见的可能引发内存泄漏问题的几种场景
内存泄漏问题不易察觉,所以有时需要借助工具来帮忙
JVisualVM
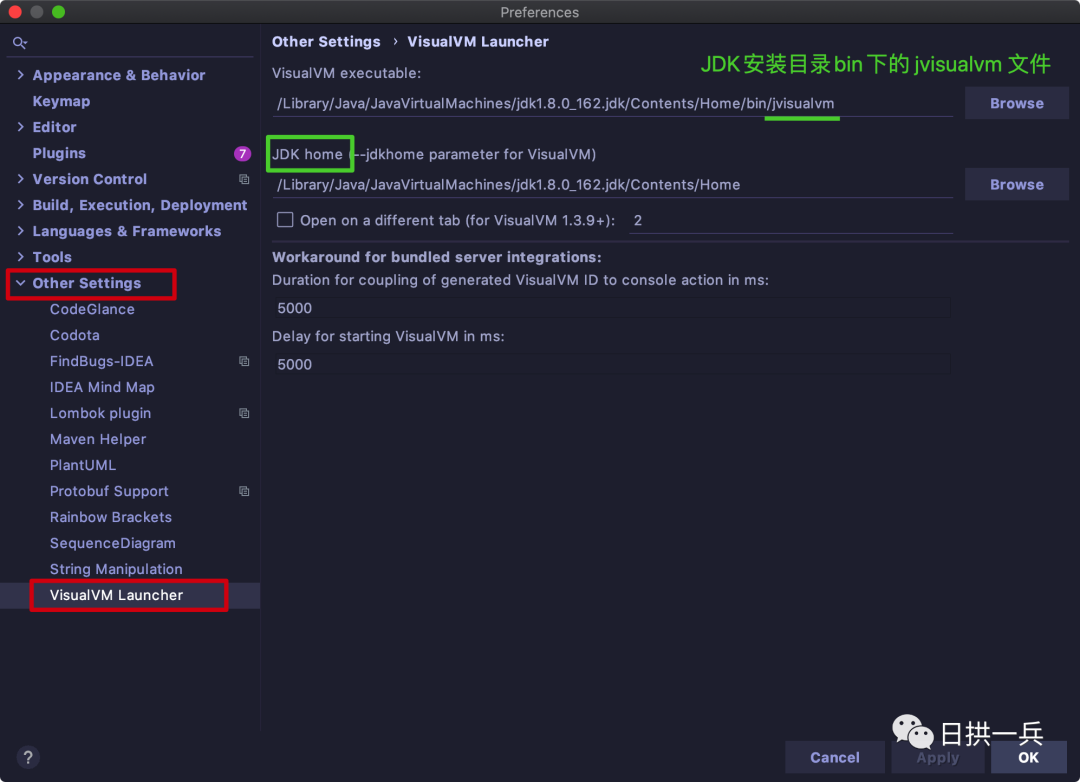
JVisualvm 【可视化JVM】,可分析JDK1.6及其以上版本的JVM运行时的JVM参数、系统参数、堆栈、CPU使用等信息。可分析本地应用及远程应用,在JDK1.6以上版本中自带,工具的使用暂不展开说明, 想快速使用此工具,只需要在 IDE 中安装个 VisualVM Launcher 插件
然后在进行基本的配置
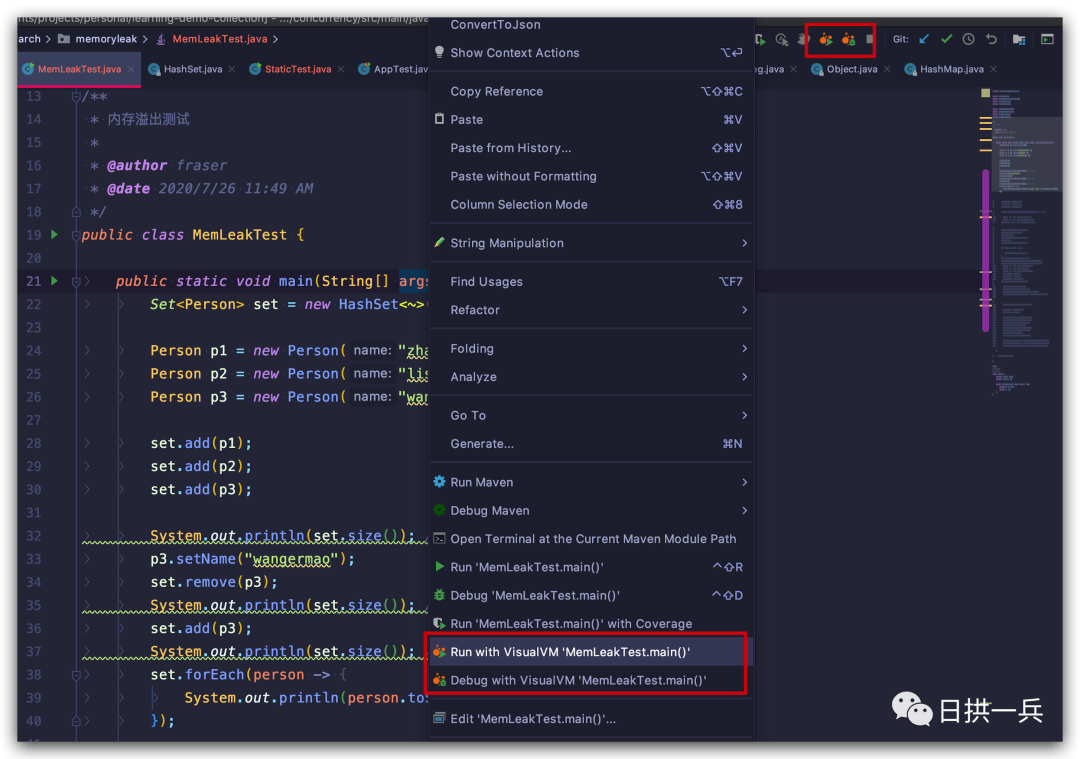
然后在IDE的右上角或当前类鼠标右键就可以点击运行查看了
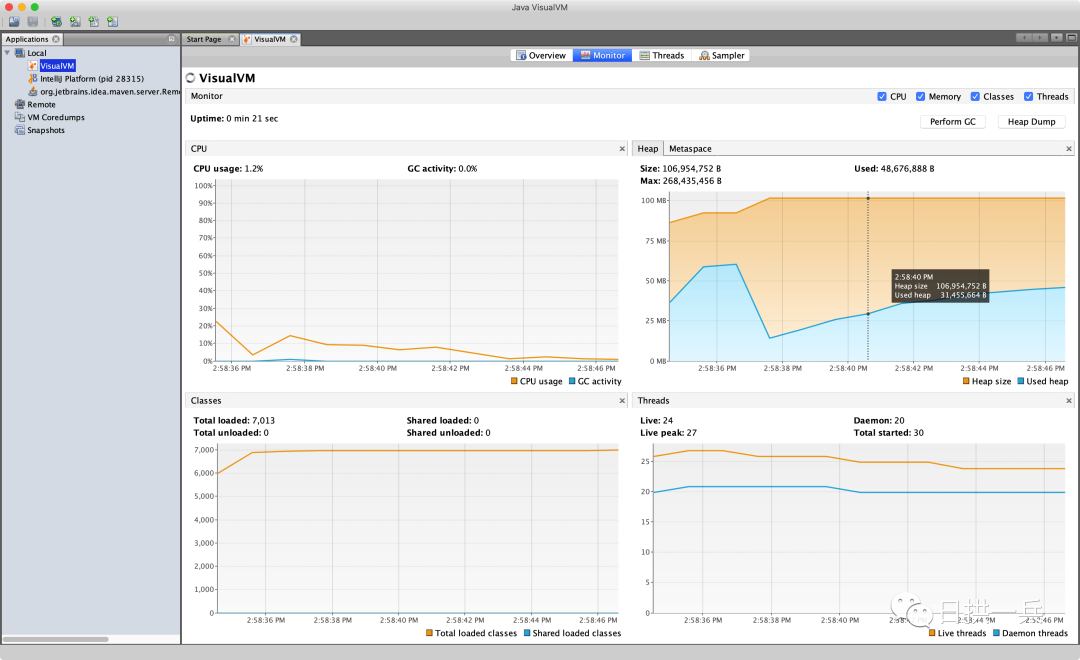
运行起 VisualVM 就是这样子了
不要走,还没结束,在总结这篇文章的时候,我还发现了「新大陆」
HashCode 真是根据对象内存地址生成的?
脑海中的印象不知道为何,很根深蒂固的接受了Object hashCode 是根据对象内存地址生成的,这次刚好想探求一下 hashCode 的本质,还着实打破了我的固有印象 (以 JDK1.8 为例)
OpenJDK 定义 hashCode 的方法在下面两个文件中
src/share/vm/prims/jvm.hsrc/share/vm/prims/jvm.cpp
逐步看下去,最终会来到 get_next_hash 这个方法中,方便大家查看我先把方法截图至此:
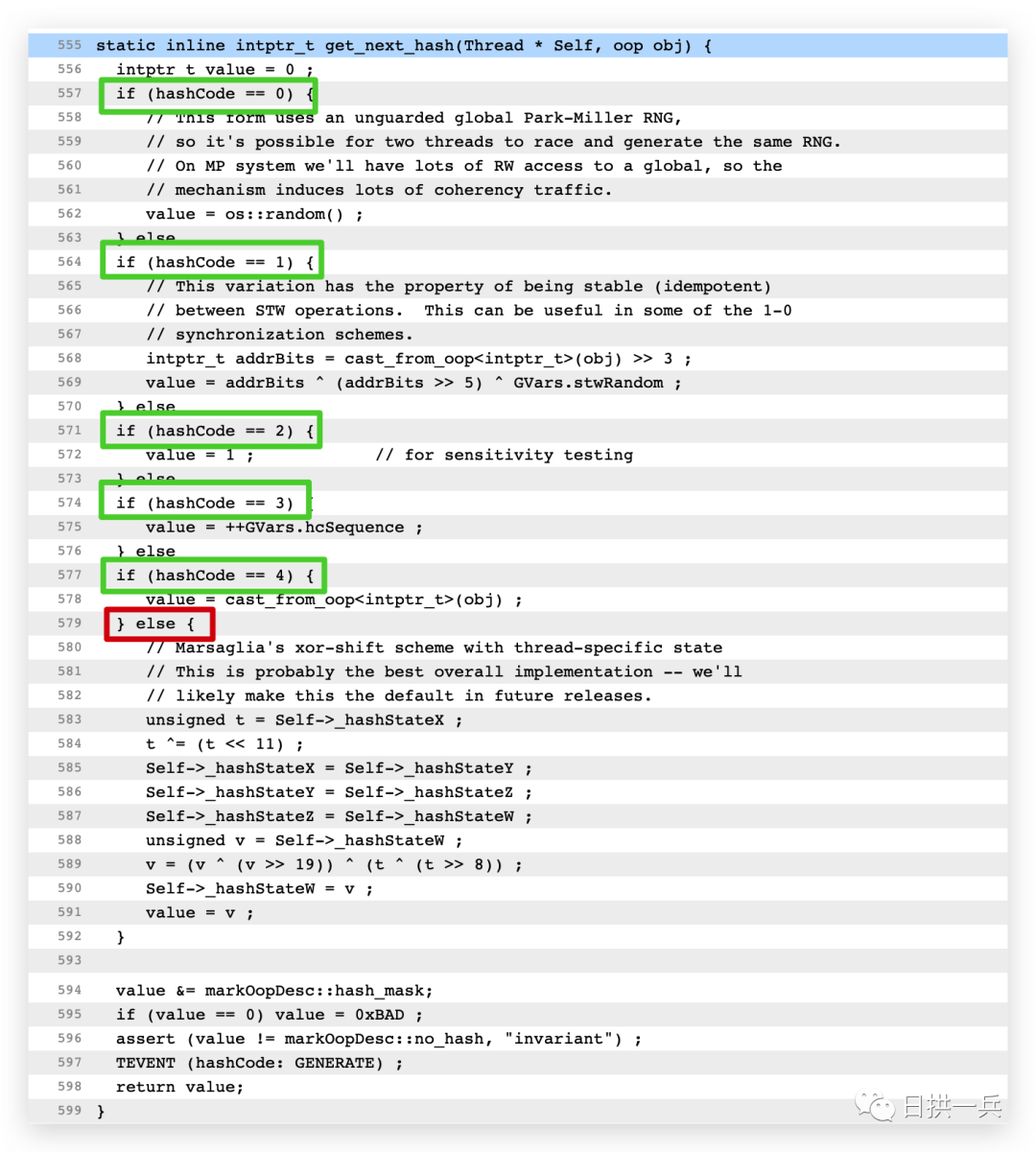
总的来说有 6 种生成 hashCode 的方式:
0: A randomly generated number 1: A function of memory address of the object 2: A hardcoded 1 (used for sensitivity testing.) 3: A sequence. 4: The memory address of the object, cast to int 5(else): Thread state combined with xor-shift[1]
那在 JDK1.8 种用的哪一种呢?

可以看到在 JDK1.8 中生成 hashCode 的方式是 5, 也就是走程序的 else 路径,即使用 Xorshift,并不是之前认为的对象内存地址「1」,以为老版本是采用对象内存地址的方式,所以继续查看其他版本
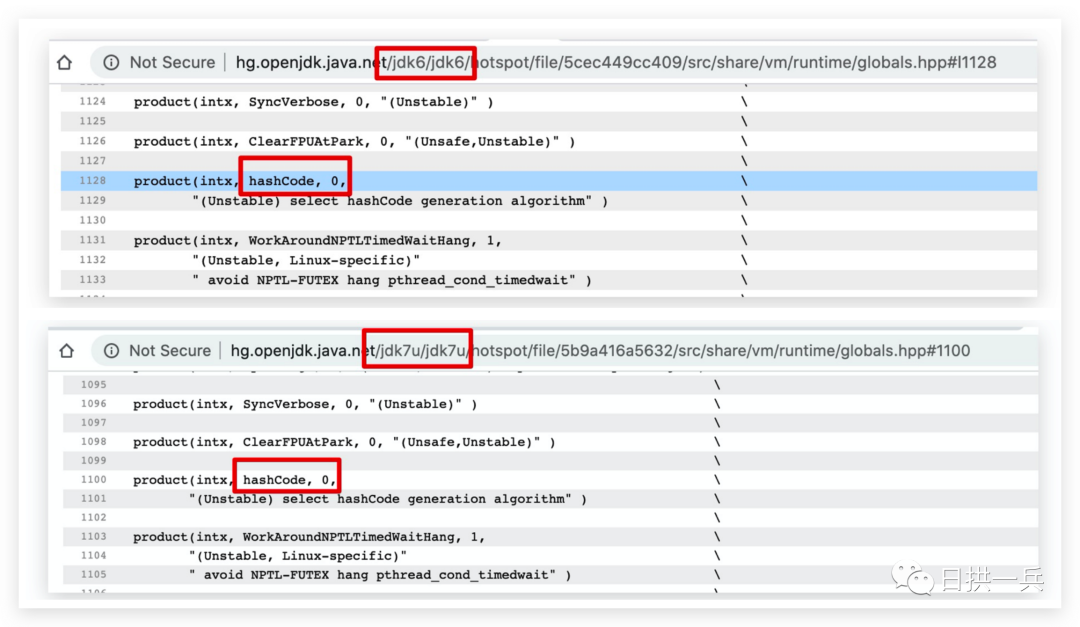
从图中可以看出,JDK1.6[2] 和 JDK1.7[3] 版本生成 hashCode 的方式「1」随机数的形式,和我们原本认为的并不一样,别的版本没有继续查询,至于「流传下来」说是对象内存地址生成的 hashCode 我也木有再深入研究,有了解的同学还请留言赐教
那么问题来了:
假设用的 JDK1.6或 JDK1.7,它们生成 hashCode 的方式是随机生成的,那一个对象多次调用hashCode是会有不同的hashCode 呢?(排除服务重启的情况)
显然应该不会的,因为如果每次都变化, 存储到集合中的对象那就很容易丢失了,那问题又来了:
它们存在哪了?
hash 值是存在对象头中的,我们还知道对象头中还可能存储线程ID,所以他们在某些情形中还会存在冲突
对象头中 hashCode 和 偏向锁的冲突
jvm 启动时,可以使用 -XX:+UseBiasedLocking=true 开启偏向锁,(关于偏向锁,轻量级锁,重量级锁大家查阅 synchronized 相关文档就可以),这里引 OpenJDK Wiki[4] 里面的图片加以文字说明整个冲突过程
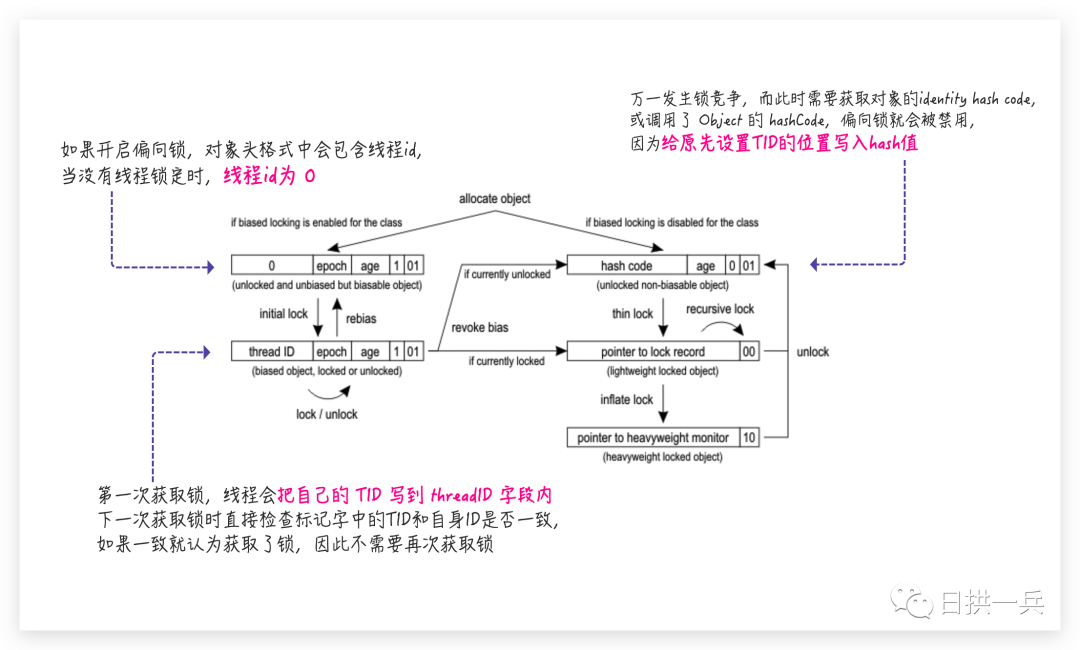
所以,调用 Object 的 hashCode() 方法或者 System.identityHashCode() 方法会让对象不能使用偏向锁。到这里你也就应该知道了,如果你还想使用偏向锁,那最好重写 hashCode() 方法,避免使偏向锁失效
总结
为了解决群的这个问题,发现新大陆的同时也差点让我掉入【追问无底洞】,不过通过本文你应该了解内存溢出和内存泄漏的差别,以及他们的解决方案,另外 hashCode[5] 生成方式还着实让人有些惊讶,如果你知道「hashCode的生成是根据对象内存地址生成的来源,还请留言赐教」。除此之外,小小的 hashCode 还有可能让偏向锁失效,所有的这些细节问题都有可能是导致程序崩溃的坑,所以勿以「恶」小而为之,毋以「善」小而不为,良好的编程习惯能避免很多问题
当然想要更好的理解内存泄漏,当然是要更好的理解 GC 机制,而想要更好的理解 GC,当然是更好的理解 JVM,咱们后续慢慢分析吧
灵魂追问
为了清除 ThreadLocal 线程变量值,不用 ThreadLocal.remove()方法,而是用ThreadLocal.set(null)会达到同样的效果吗?你曾经遇到哪些不易察觉的内存泄漏问题呢?
参考
xor-shift算法: https://en.wikipedia.org/wiki/Xorshift
[2]JDK1.6代码: http://hg.openjdk.java.net/jdk6/jdk6/hotspot/file/5cec449cc409/src/share/vm/runtime/globals.hpp#l1128
[3]JDK1.7代码: http://hg.openjdk.java.net/jdk7u/jdk7u/hotspot/file/5b9a416a5632/src/share/vm/runtime/globals.hpp#l1100
[4]OpenJDK Wiki: https://wiki.openjdk.java.net/display/HotSpot/Synchronization
[5]默认hashCode生成方式: https://srvaroa.github.io/jvm/java/openjdk/biased-locking/2017/01/30/hashCode.html
往期推荐
关注我回复「加群」,加入Spring技术交流群