
从零理解分布式之Raft协议也可以很简单
分布式之Raft协议
仔细思索分布式的CAP理论,就能发现P数据分区是分布式的特性,是必须满足的特点。如果一个系统没有数据分区的存在,那这样的系统就是单体,而不是分布式。CAP三个特性无法同时满足,那么所有的分布式系统实现都是在A(可用性)和C(一致性)之间权衡选择。
Raft是一个分布式的一致性协议,放弃了CAP的可用性,保证严格的一致性。
Raft是什么
Raft是一个分布式的一致性协议,通过选主机制和日志状态机算法来保证分布式系统的一致。Raft的应用非常广泛,etcd、consul等都使用了Raft协议。
Raft的选主机制
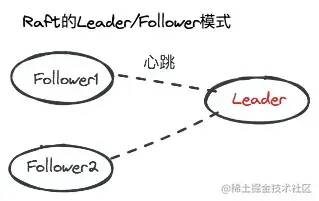
在Raft协议里,系统中的所有节点中必须选出一个Leader。
因为分布式的数据分区特性,所以没有leader来协调,就很难是一致的了。
Paxos算法也是一个分布式一致性协议,使用P2P算法来保证,但是实际理解和实现都过于复杂。就像我上面理解的那样,如果有一个leader会让决策变得简单快速。
Raft系统采用RPC来通信,主要有两种类型的RPC:
RequestVote:用于candidate的拉票选举
AppendEntries:用于Leader向其他Follower
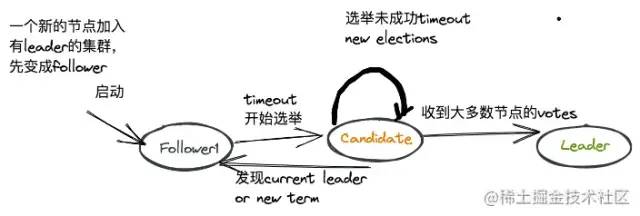
节点状态变迁如下:
Raft普通节点和Leader之间都有心跳,一有异常就等着重新选举。
term:任期
一个新的节点加入有leader的集群,先变成follower
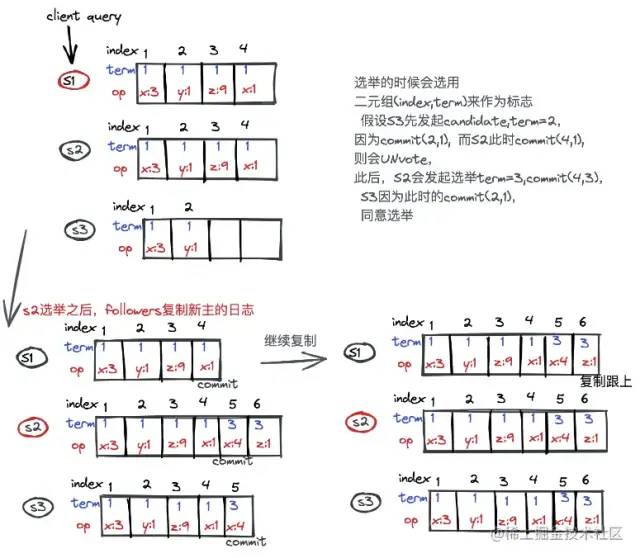
每次选主都有一个新的term,下图显示了选主的过程:
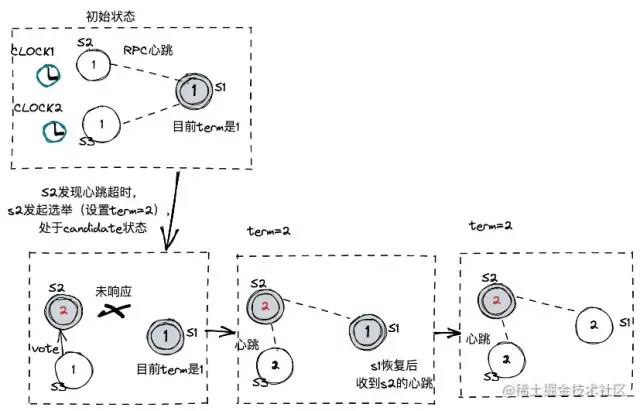
S2的时钟先发现心跳超时,发起选举,作为candidate投自己一票,S3也投S2一票,则S2当选为新的Leader。当S1和S2重新有心跳时,发现任期大于自己原来的任期,则也成为S2的follower。
日志状态机
分布式往往意味着多副本存储,且各副本节点的数据一致。
Raft维持多副本数据一致的方式是使用一种状态机,也叫做日志状态机来完成的。
比如上图对应的初始状态,这个时候如果有客户端发起操作数据的请求,这个数据会通过leader并且复制日志到各个follower
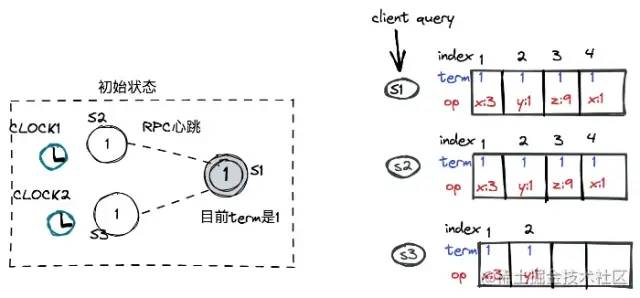 从图上可以看出,此时的S2复制了全部的S1的全部日志,S3还有所落后。leader收到超过半数以上的follower的ack信号,则commit该index的操作日志。
从图上可以看出,此时的S2复制了全部的S1的全部日志,S3还有所落后。leader收到超过半数以上的follower的ack信号,则commit该index的操作日志。
选举的时候会选用
二元组(index,term)来作为标志
假设S3先发起candidate,term=2,
因为commit(2,1), 而S2此时commit(4,1),
则会UNvote,
此后,S2会发起选举term=3,commit(4,3),
S3因为此时的commit(2,1),
同意选举
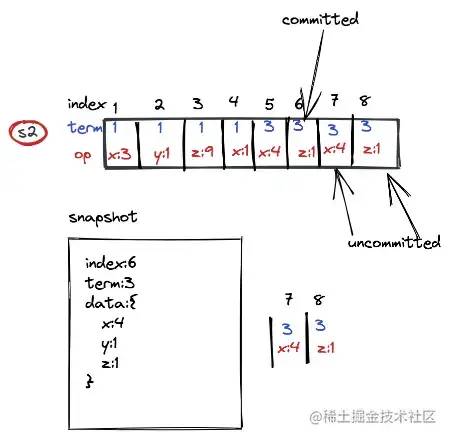
leader知道大部分节点都成功之后,将这个index的日志状态设置为committed,follower是通过心跳包得知log已经被成功复制,然后所有节点会将该条目设置为committed.
假设S2被选为主之前,还有一条数据(4,1)未提交,未提交的数据是不能复制给其他follower的(之前已经返回错误给客户端了吧),可以覆盖或者删除(最好删除)
反正不允许commit了,因为后面已经不属于当前的term了。(直接覆盖比较妥当,何必留脏数据呢)
试试问到底
和MySQL的复制有什么区别?
MySQL的binlog其实也可以认为是日志,被复制到其他的备机
raft可以在有异常的时候,自动的随时切换主备
MySQL没有通过这些复制的日志来选主,一般都是手动切换的。实际应用的时候,MySQL更看重可用性。
MySQL不支持这么复杂的分布式情况,侧重点在可用性和关系复杂性。
新加入的日志是怎样应用压缩日志的?
当日志被leader做了快照并删除了的时候,leader需要把快照发送给follower,或者集群有新的节点加入,leader也可以直接发送快照,大量节点日志传输和回放时间。
快照只包括已提交的数据。将已提交的数据和未提交的数据一起给follower就可以,大大节省了日志传输和回放时间。
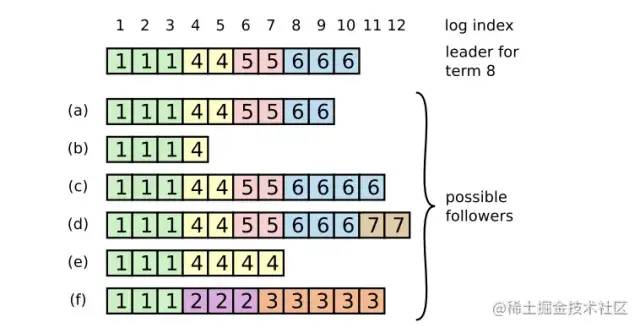
这个图的产生过程,你真的理解了吗
d宕机,当前节点当选。(10,6)比(11,3)的term长,所以f统一,b,e当然同意,a同意,可是c不能同意,d也不同意,不过已经有4票了,当前节点当选
当前节点要把数据同步给其他节点
a节点接收一个(10,6)
b节点还有很多数据要同步,从(5,4)开始
c节点多了一个,删除(11,6)
d节点多了两个(12,7),(11,7),这两个是因为d获取到term 7的leader之后宕机
e节点要同步的数据也比较多,(7,5)和(7,4)不一样,(6,5)和(6,4)也不一样,这两个日志e删掉,然后重新从leader同步数据过来
f节点也是,需要删除的日志很多。产生f节点的原因是因为它当选了term 2和 term 3的leader,但是数据都不曾同步给其他节点。
什么是脑裂现象
在一个分布式系统系统,如果出现多个leader,则是脑裂。
怎么解决?必须大于半数的节点同意才是主。
使用奇数个节点,必须大于半数的节点同意才是主,这样开销比较小
如果是偶数个节点,必须大于半数的节点同意才是主,那么选主的开销是很大的,但是也不会导致脑裂。
Raft为何一定要设计term这个概念?
首先很形象,就像总统选举一样,每次都有一个任期号
每个leader都有自己的Term,而且这个term会带到log的每个entry中去,来代表这个entry是哪个leader term时期写入的。
另外Term相当于一个lease。如果在规定的时间内leader没有发送心跳(心跳也是AppendEntries这个RPC call),Follower就会认为leader已经挂掉,会把自己收到过的最高的Term加上1做为新的term去发起一轮选举。
如果参选人的term还没自己的高的话,follower会投反对票,保证选出来的新leader的term是最高的。如果在time out周期内没人获得足够的选票(这是有可能的),则follower会在term上再加上1去做新的投票请求,直到选出leader为止。最初的raft是用c语言实现的,这个timeout时间可以设置的非常短,通常在几十ms,因此在raft协议中,leader挂掉之后基本在几十ms就能够被检测发现,故障恢复时间可以做到非常短。
超过半数同意,但是没有半数以上commit的日志在选主之后何去何从?
也就是说uncommitted状态,等待半数同意之后可以commit吗?
上面的例子如果换成一个有这样假设的,会怎样?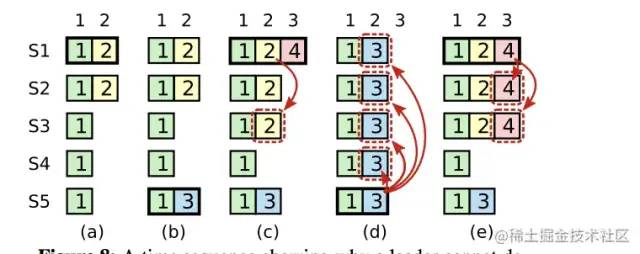
参考文献
ramcloud.atlassian.net/wiki/downlo…
「欢迎在评论区讨论,掘金官方将在掘力星计划活动结束后,在评论区抽送100份掘金周边,抽奖详情见活动文章」。
作者:小圆规
链接:https://juejin.cn/post/7023542859257085965
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。