
认识人和鱼的AI,能识别美人鱼吗?阿里CVPR论文试用因果推理方法解答
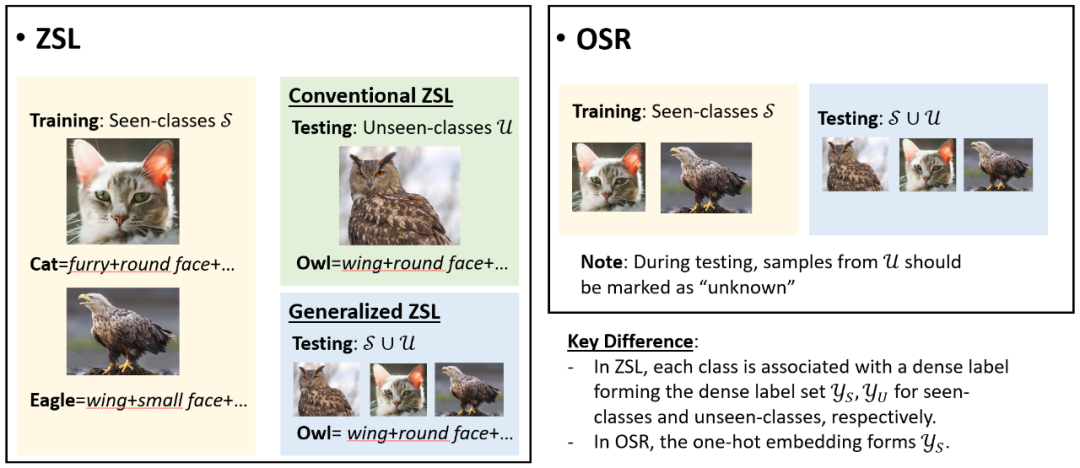
学过人类照片和鱼类照片的 AI,第一次见到美人鱼的照片会作何反应?人脸和鱼身它都很熟悉,但它无法想象一个从没见过的事物。近期,阿里巴巴达摩院将因果推理方法引入计算机视觉领域,尝试克服机器学习方法的缺陷,让 AI 想象从未见过的事物,相关论文已被计算机视觉顶会 CVPR 2021 收录。

论文链接:https://arxiv.org/pdf/2103.00887.pdf
代码链接:https://github.com/yue-zhongqi/gcm-cf
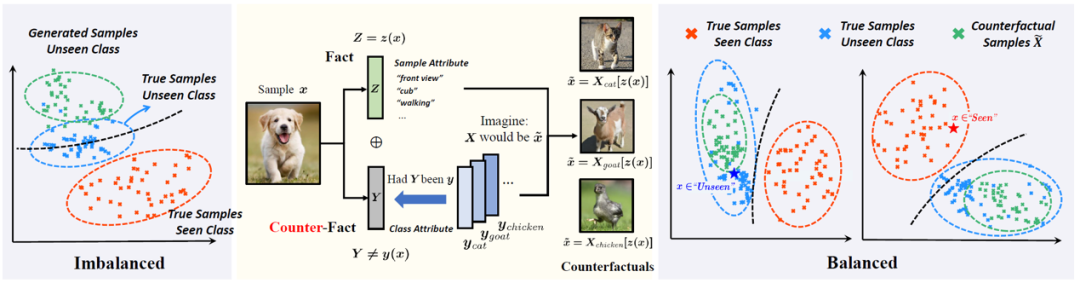
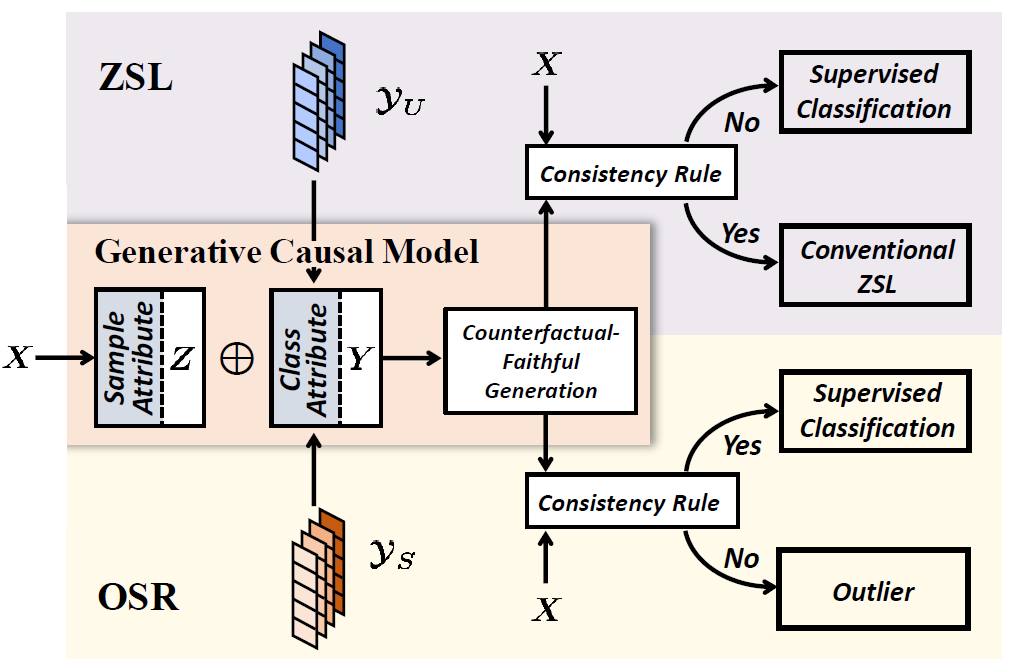
我们提出的 GCM-CF 是一个见过 / 未见过类别的二元分类器,二元分类后可以适用任何监督学习(在见过类别上)和零次学习算法(在未见过类别上);
我们提出的反事实生成框架适用于各种生成模型,例如基于 VAE、GAN 或是 Flow 的;
我们提供了一种易于实现的两组概念间解耦的算法
接下来我会具体介绍我们针对的任务、提出的框架和对应的算法。


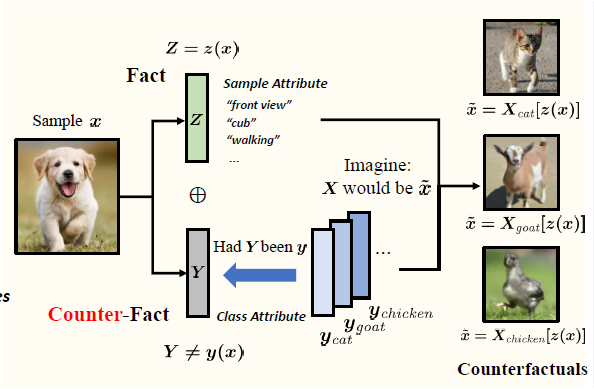

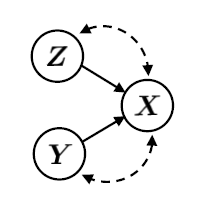
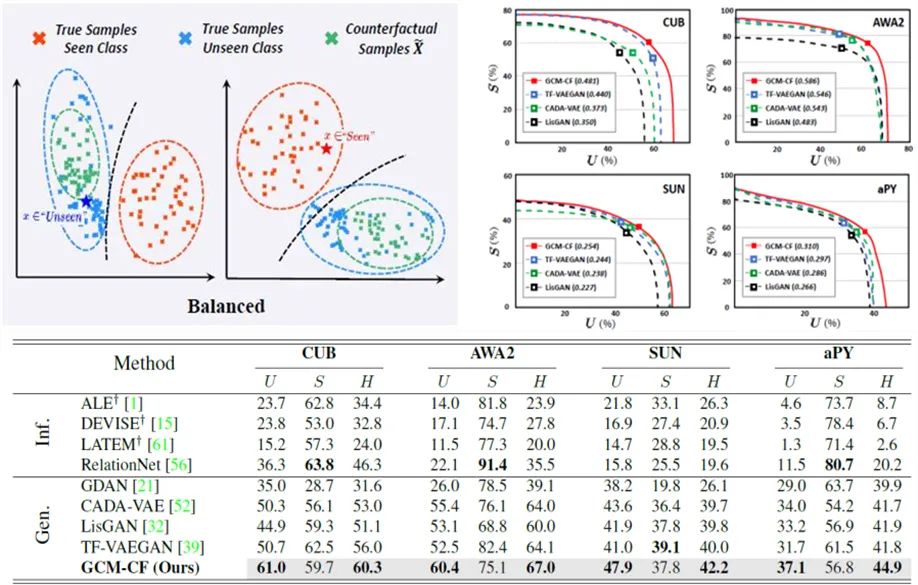
β-VAE loss:这个 loss 要求 encode 得到的 Z=z(x),和样本自己的 Y=y,可以重构样本 X=x,并且 encode 出来的 Z 要非常符合 isotropic Gaussian 分布。这样通过使 Z 的分布和 Y 无关实现解耦;
Contrastive loss:反事实生成的样本中,x 只和自己类别特征生成的样本像,和其他类别特征生成的样本都远。这个避免了生成模型只用 Z 里面的信息进行生成而忽略了 Y,从而进一步把 Y 的信息从 Z 里解耦;
GAN loss:这个 loss 直接要求反事实生成的样本被 discriminator 认为是真实的,通过充要条件,用保真来进一步解耦。
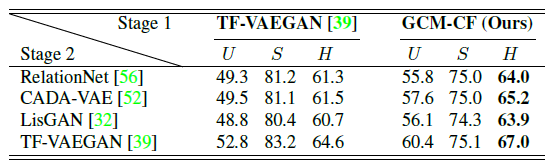
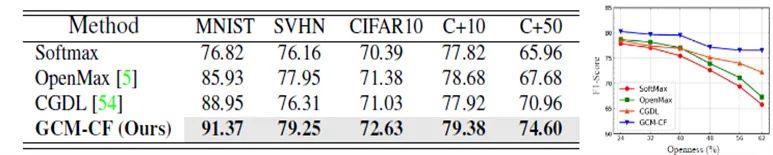
@inproceedings{yue2021counterfactual,title={Counterfactual Zero-Shot and Open-Set Visual Recognition},author={Yue, Zhongqi and Wang, Tan and Zhang, Hanwang and Sun, Qianru and Hua, Xian-Sheng},booktitle= {CVPR},year={2021}}
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论