
从“消息队列”到“服务总线”和“流处理平台”

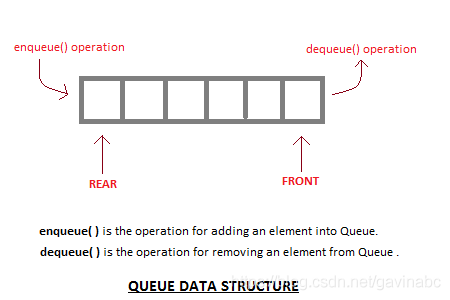
- 什么是队列? -
- 什么是消息队列? -
- 消息队列的优势 -
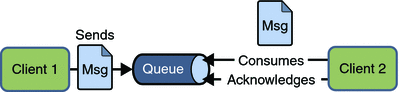
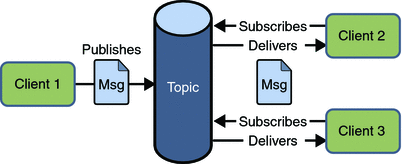
- 消息模板:如何发布和获取消息 -
- 何时使用消息队列 -

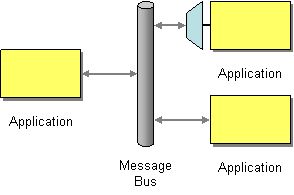
- 服务总线 -
- 流处理平台——Kafka -
可以让你发布和订阅流式的记录。这一方面与消息队列或者消息总线类似。 可以储存流式的记录,并且有较好的容错性。 可以在流式记录产生时就进行处理。
作者:陈喆gavin
来源:
https://blog.csdn.net/gavinchen1985/article/details/113957742

评论