
AI 大模型最新突破:帮科学家读论文,小菜一碟

大数据文摘转载自AI科技评论
作者:施方圆
编辑:陈彩娴
自人类迈入信息时代开始,信息资源总量越来越多,信息过载的现象非常严重。
英国学者带姆·乔丹曾说:“拥有太多信息使信息的利用变得不可能。” 美国工程师 Vannever Bush 也观察到信息过载的情况,在上个世纪就提出通过计算机来解决日益庞大的信息量问题。
Meta AI 新近推出的语言大模型 Galactica,正是在这样的背景下诞生。
由于语言模型可以潜在地储存、组织和推理科学知识,所以语言模型可以作为一种工具帮人类处理大量的信息。例如,语言模型可以在一个文献训练中发现不同研究中潜在的联系,并让这些见解浮出水面。Galactica 通过自动生成二次内容来整合知识,将论文与代码连接起来,为科学研究提供动力。
目前,Meta AI 已开放了 Galactica 所有模型的源代码。

精心设计的语料库
近年来,大型语言模型在 NLP 任务上取得了突破性的进展。这些模型在大型通用语料库上进行自我监督训练,并在数百个任务中表现良好。
但自监督的一个缺点是倾向使用未经整理的数据,模型可能反映语料库中的错误信息、刻板印象和偏见等。对于重视真理的科学任务来说,这是不可取的,未经整理的数据也意味着会浪费更多算力预算。
Galactica 用一个大型科学语料库训练一个单一的神经网络,以学习不同的科学语言。Galactica 的语料库包括了论文、参考资料、百科全书和其他学科资源的 1060 亿个 token 组成,集合了自然语言来源,如论文、教科书和自然序列,如蛋白质序列和化学公式,能够捕捉到 LATEX 并对其进行处理,同时还用学术代码捕捉计算科学。
与其他规模更大、未经策划的大型语言模型项目相比,Galactica 使用的数据集规模更小,而且是经过精心策划的,这很关键,即我们能否在一个经过策划和规范的语料库上制造一个好的大型语言模型。如果可以,我们就能通过设置语料库的内容,更有目的性地设计出大型语言模型。
研发者们主要通过专业化标记来设计数据集,这会形成不同的模态,例如:蛋白质序列是根据氨基酸残基来写的。研发团队还对不同模态进行了专门的标签化。在处理好了数据集后,研发者们在 Galactic 的解码器设置中使用了 Transformer 架构,并进行了以下修改:
GeLU 激活——对所有模型的尺寸都使用了 GeLU 激活;
上下文窗口——对所有的模型尺寸都使用了 2048 长度的上下文窗口;
无偏差——遵循 PaLM ,不在任何密集核或层规范中使用偏差;
学习的位置嵌入——对模型使用学习的位置嵌入,在较小的尺度上试验了 ALi Bi ,但没有观察到大的收益,所以研发者们没有使用它;
词语——使用 BPE 构建了一个包含 50k 个标记组成的词汇表,词汇量是由随机选择的 2% 的训练数据子集中产生的。
实验效果
研发者们还对大型语言模型作为科学模式和自然语言之间的桥梁的潜力进行了初步调查,展示了 Galactica 可以通过自监督来学习 IUPAC 命名等任务。他们发现,增加连接自然语言和自然序列的数据及数量和大小可能进一步提高模型的性能。
研发者们认为语言模型有更多潜力承担目前人类所擅长的事情。
而且为了考察 Galactica 吸收知识的情况,研发者们还建立了几个知识探针的基准,并用于确定语料库内的知识差距,并告知如何确定语料库内的知识差距和迭代语料库。
另外,Galactica 在推理方面表现十分出色,在数学 MMLU 上的表现优于 Chinchilla 41.3% 至 35.7%,在 MATH 上的 PaLM 540B 得分分别为 20.4% 和 8.8%。
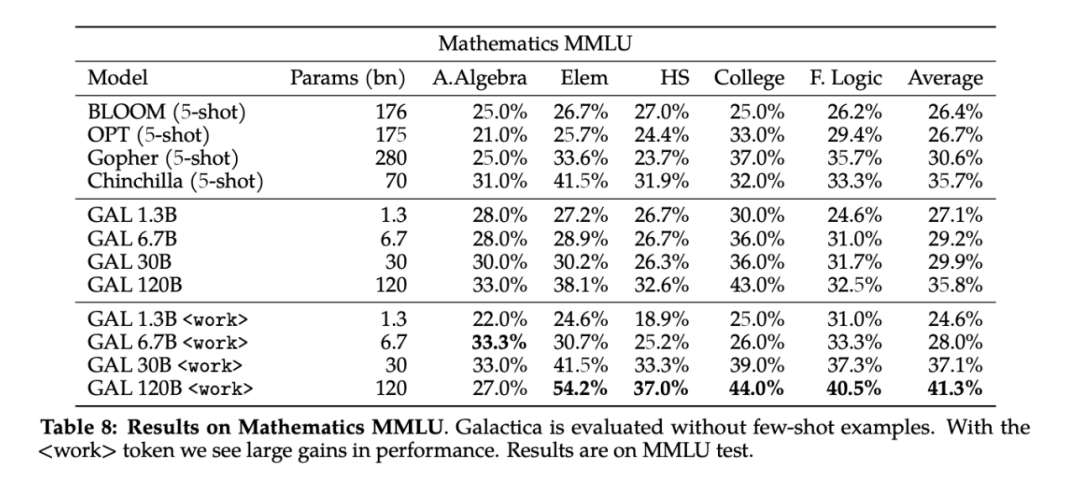

在经过四个 epoch 的训练之后,最大的 120B 参数模型从第五个 epoch 才开始过度拟合。

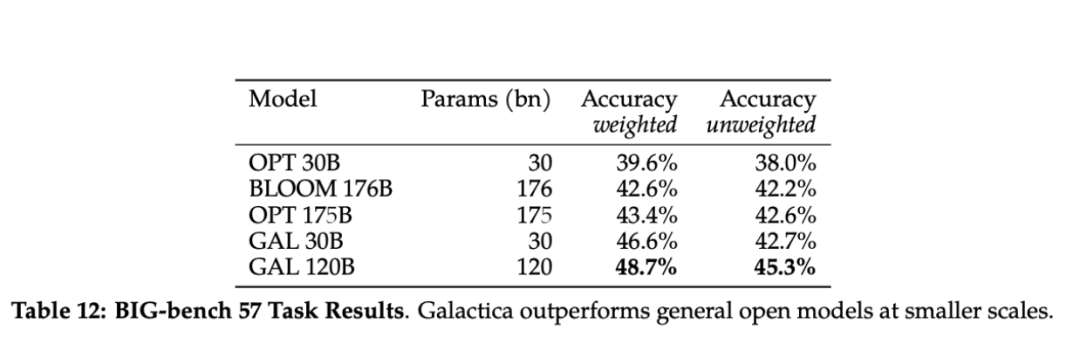
尽管没有接受过一般语料库的训练,但 Galactica 在 BIG-bench 上的表现优于 BLOOM 和 OPT-175B。根据评估,Galactica 的毒性也明显低于其他语言模型。

Galactica 犹如自动驾驶
Meta AI 发布 Galactica 后,在 AI 领域引起广泛注意,并收获了一众好评。
Yann LeCun 评论:这个工具( Galactica )于论文写作而言,就像辅助驾驶之于驾驶一样,它不会帮你自动写论文,但它会在你写论文的时候大大减轻你的认知负担。

其他研究者则评论:
太神奇了!Galactica 甚至可以针对某个领域写评论,推导 SVM ,告诉我什么是线性回归算法!只是生产内容的长度好像有限制?

真是太神奇了!我只是用这个来帮我写“选择性注意研究”评论——它看起来很不错,也许下一步它就可以产生真正的想法!

50 多年来,人类获取科学知识的主要方式一直是通过存储和检索,信息的推理、组合、组织无法依靠机器,只能通过人的努力完成,这导致知识吞吐量存在瓶颈。在 Galactica 的实践中,研发者们探讨了语言模型可能如何破坏这种旧的形式,带来人与知识的新接口。
从长远来看,语言模型的上下文关联能力可能会给搜索引擎带来显著优势。在 Galactica 的实践中,研发者们还证明语言模型可以是一个精心策划的知识库,执行知识密集型的问答任务。
