
Proxima 概览 | 淘宝推荐、视频搜索背后的检索技术竟是它!深度揭秘达摩院向量检索引擎 Proxima

阿里妹导读:淘宝搜索推荐、视频搜索的背后使用了什么样的检索技术?非结构化数据检索,向量检索,以及多模态检索,它们到底解决了什么问题?今天由阿里巴巴达摩院的科学家从业务问题出发,抽丝剥茧,深度揭秘达摩院内部技术——向量检索引擎 Proxima,以及相关领域的现状、挑战和未来。
本文作者
大沙,阿里巴巴达摩院机器智能实验室 资深技术专家
鹤冲,阿里巴巴达摩院机器智能实验室 资深技术专家
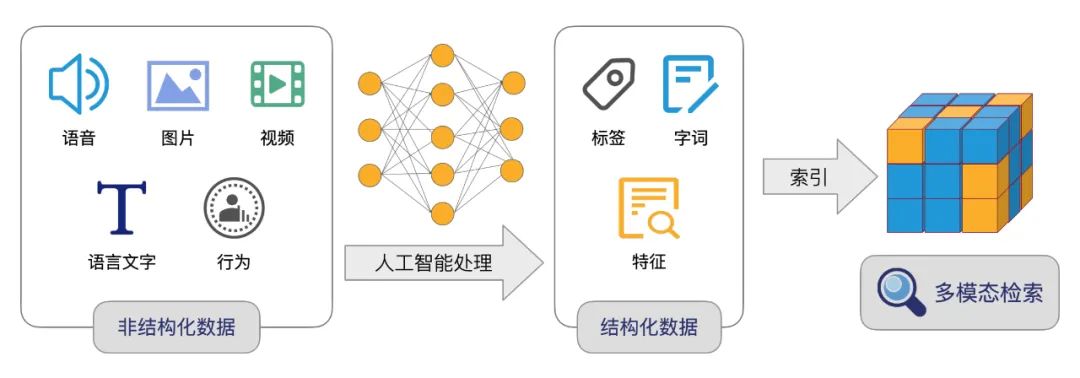

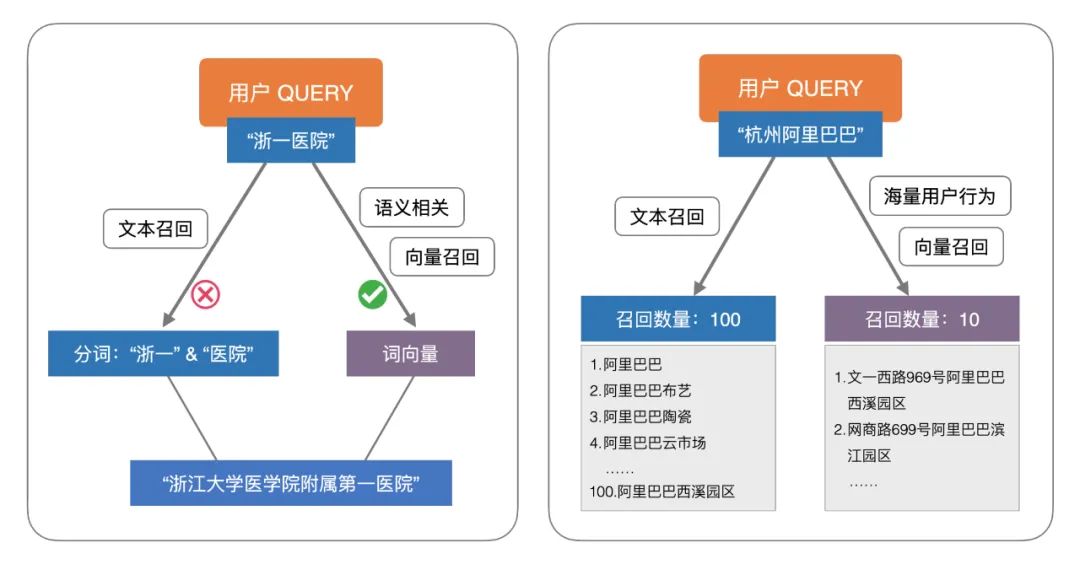
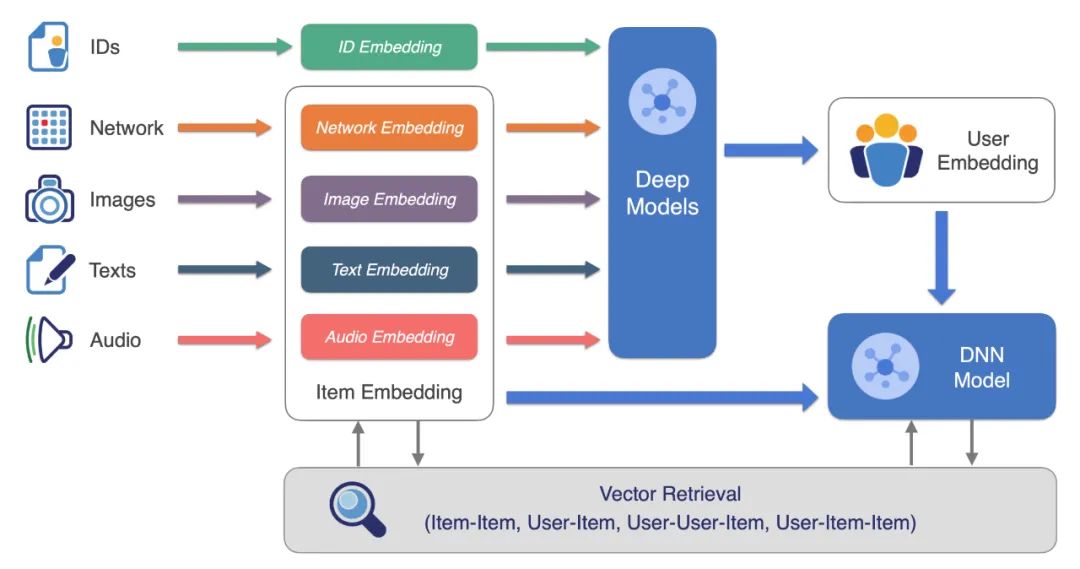

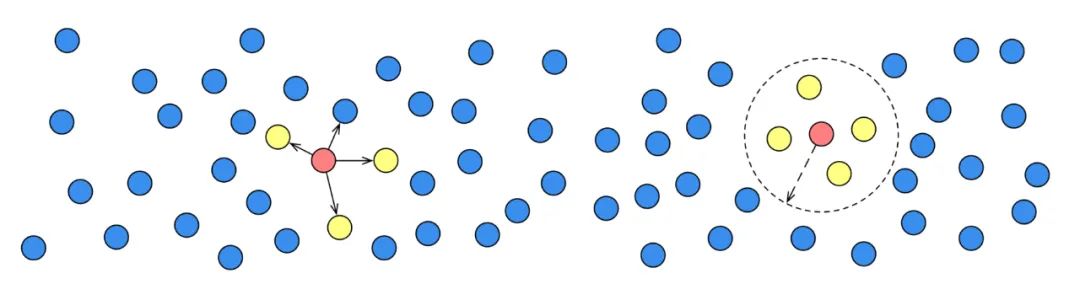



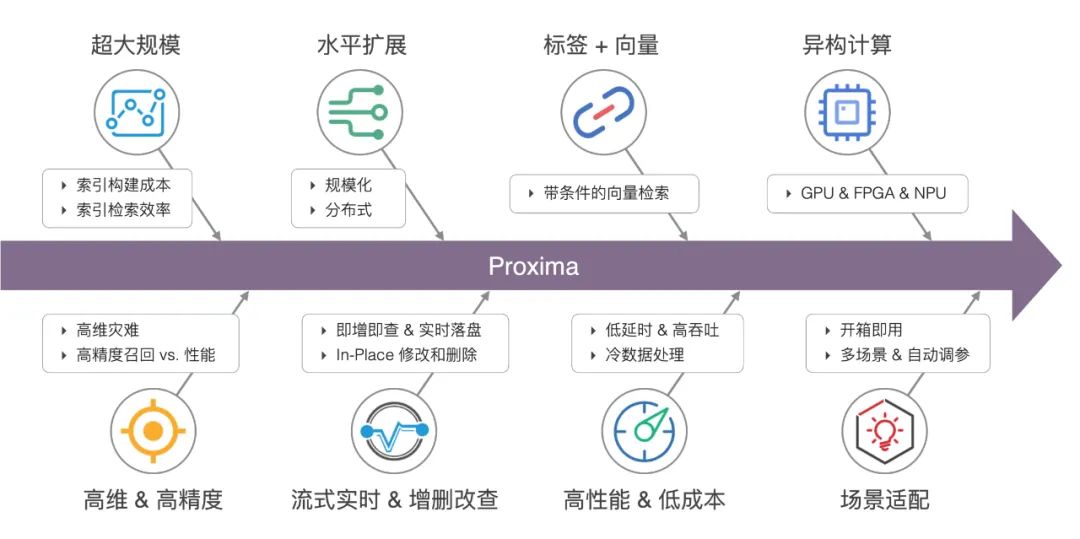
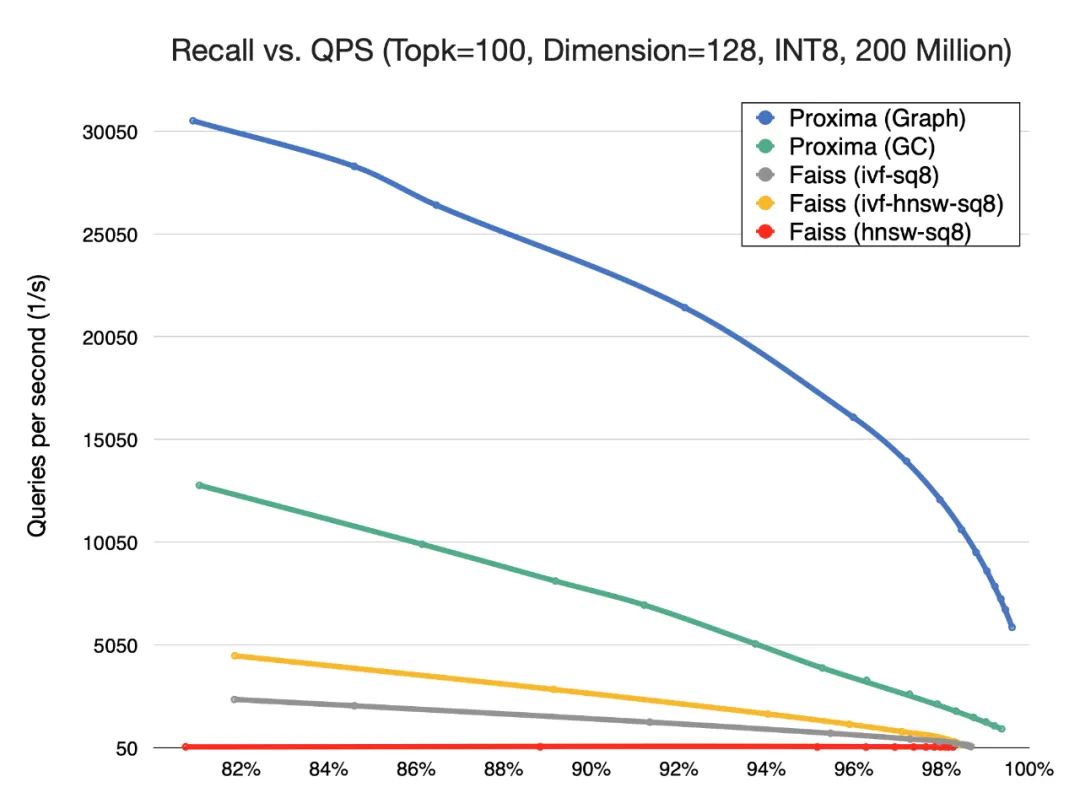
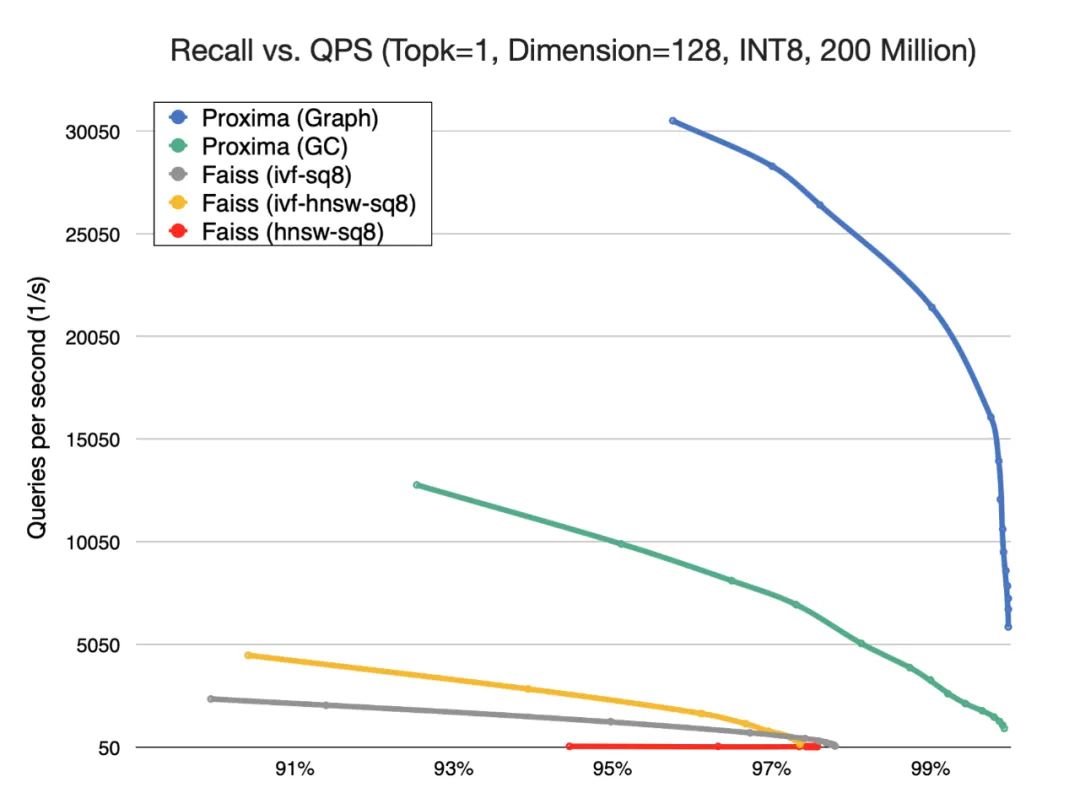
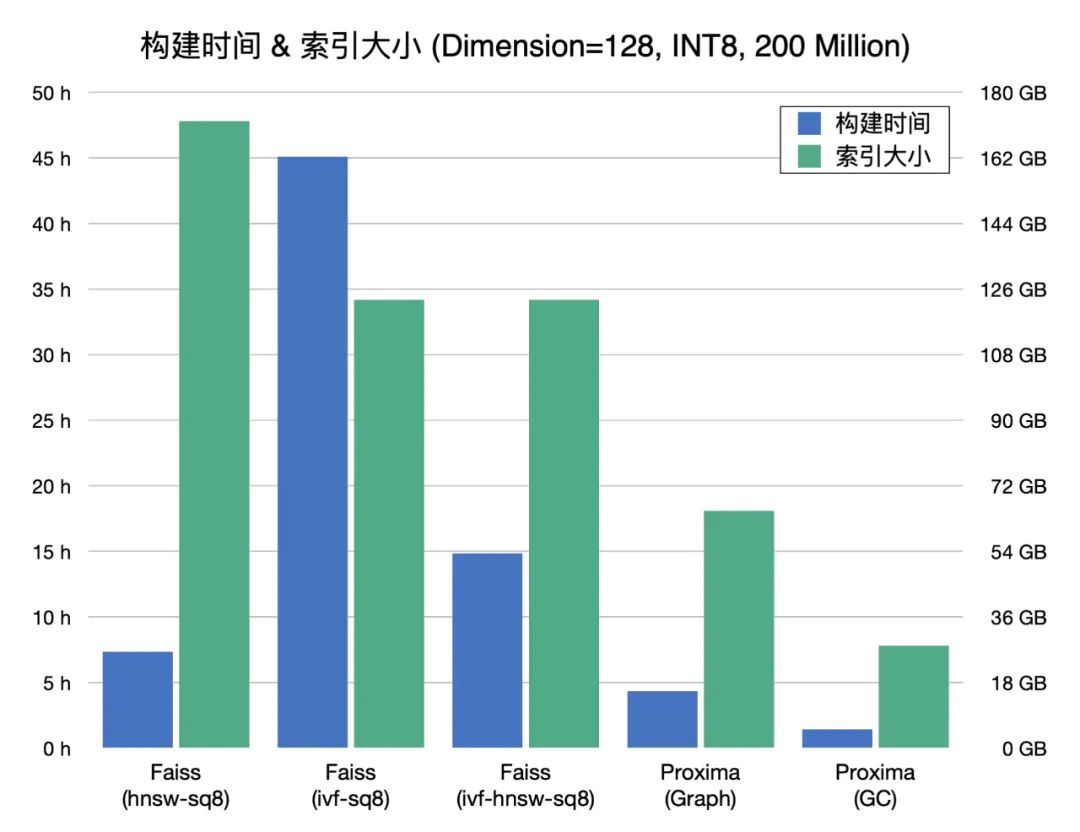
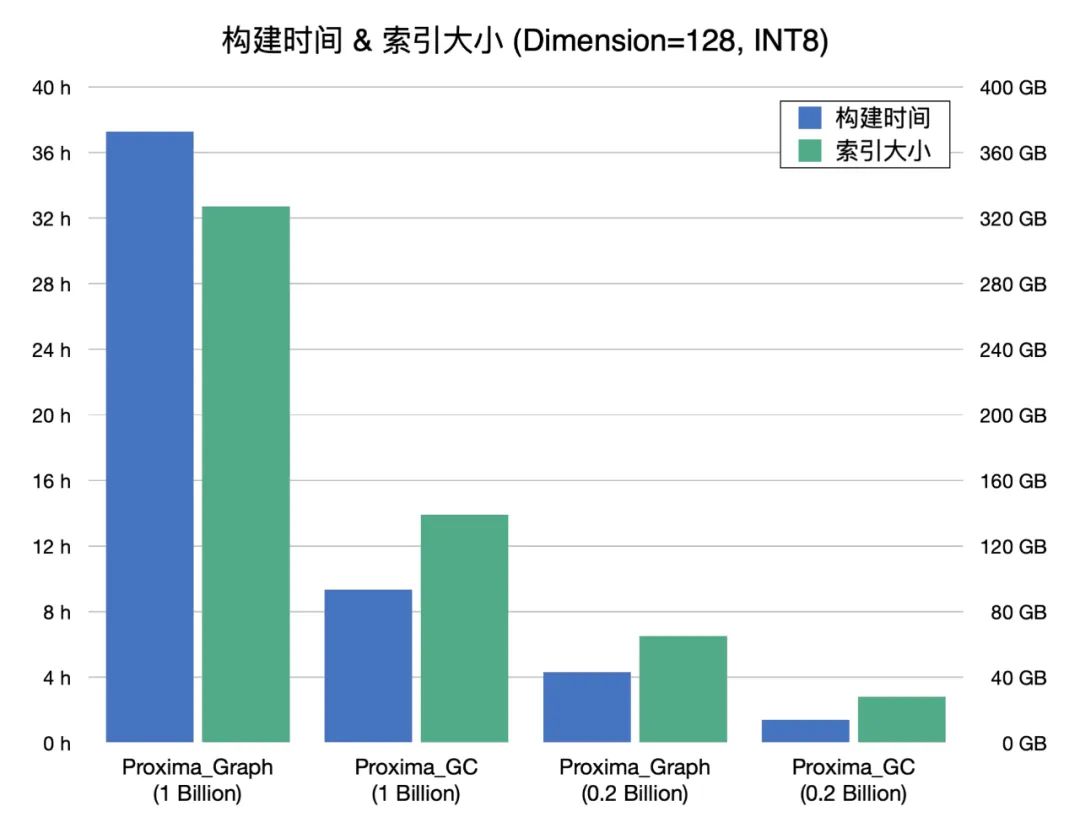
超大规模索引构建和检索:Proxima 精于工程实现和算法底层优化,引入了复合性的检索算法,基于有限的构建成本实现了高效率的检索方法,单片索引可达几十亿的规模。
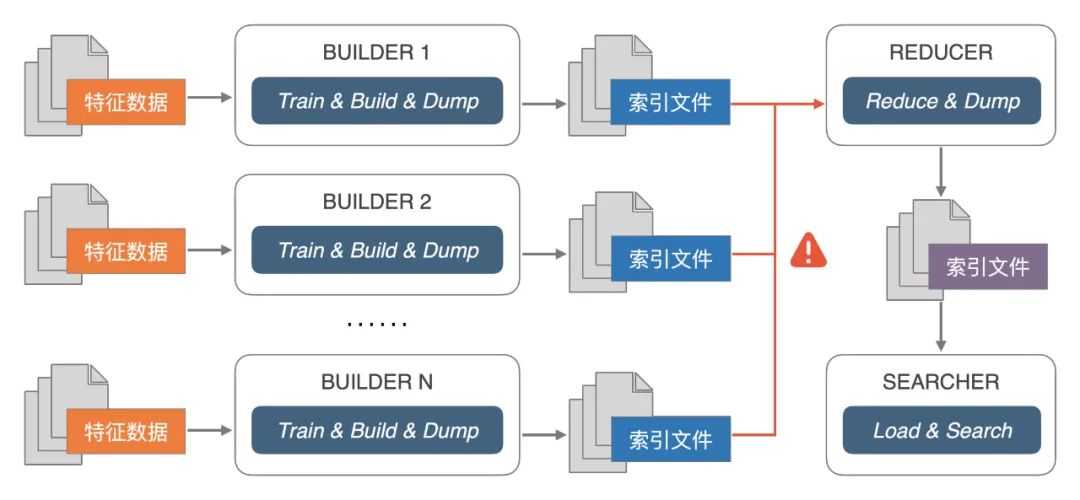
索引水平扩展:Proxima 采用非对等分片的方法实现分布式检索。对于邻居图索引,解决了有限精度下图索引快速合并的难题,与 Map-Reduce 计算模型可有效进行结合。
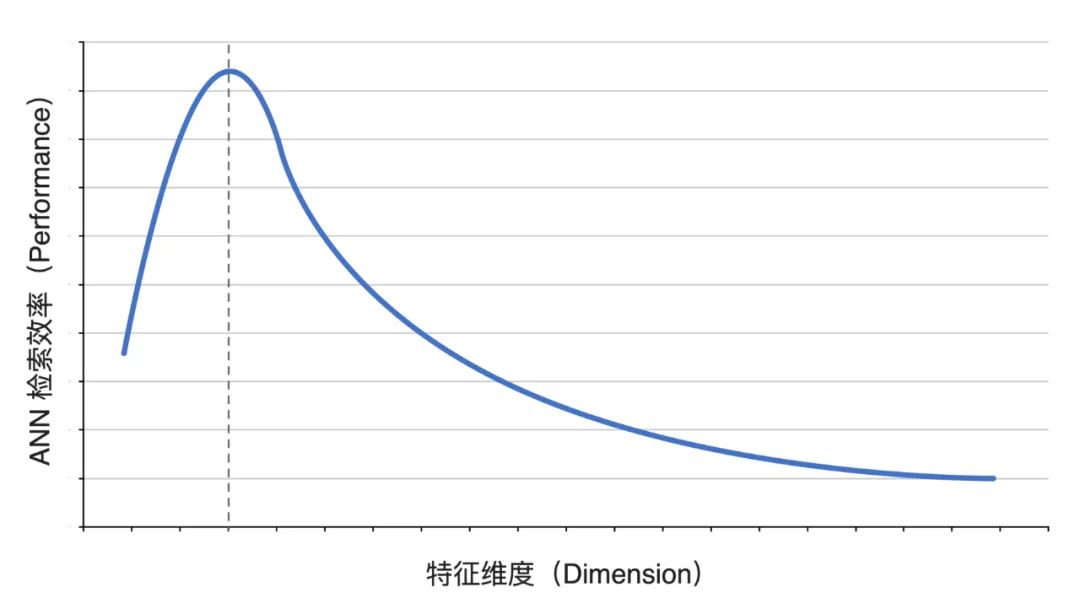
高维 & 高精度:Proxima 支持多种检索算法,并对算法做了更深层的抽象,形成算法框架,依据不同数据维度和分布选择不同算法或算法组合,根据具体场景需求实现精度和性能之间的平衡。
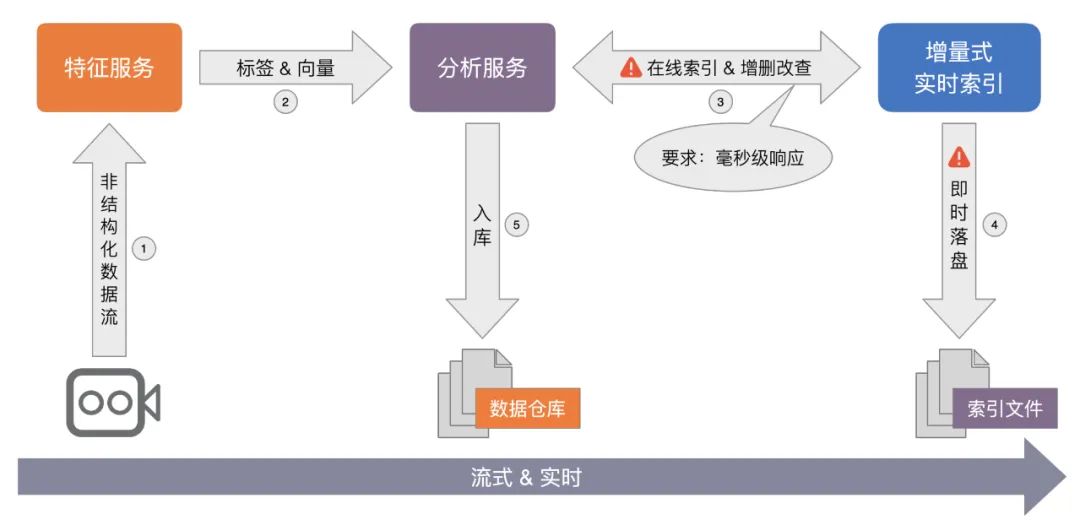
流式实时 & 在线更新:Proxima 采用扁平化的索引结构,支持在线大规模向量索引的从 0 到 1 的流式构建,并利用邻居图的便利性和数据特点,实现了索引即增即查、即时落盘,以及实时动态更新。
标签+向量检索:Proxima 在索引算法层实现了“带条件的向量检索”方法,解决了传统多路归并召回结果不理想的情况,更大程度的满足了组合检索的要求。
异构计算:Proxima 支持大批量高吞吐的离线检索加速,同时解决了 GPU 构建邻居图索引的难题,另一方面也成功解决了小批量+低延时+高吞吐的资源利用问题,并将其全面应用在淘宝的搜索推荐系统中。
高性能和低成本:有限成本下实现最大化性能并满足业务的需求是向量检索需要解决的主要问题。Proxima 实现了对多种平台和硬件的优化,支持云服务器和部分嵌入式设备,通过与分布式调度引擎的结合实现离线数据检索和训练,通过扁平化索引和磁盘检索的方案实现了对冷数据的快速检索。
场景适配:结合超参调优和复合索引等方法,通过对数据采样和预实验,Proxima 可以解决一些数据场景智能适配的问题,从而提高系统的自动化能力,以及增强用户的易用性。


电子书免费下载
《2021前端热门技术解读》
阿里巴巴前端委员会重磅推荐!阿里巴巴前端技术专家为你解读前端技术新趋势以及2021你需要关注的技术热点,覆盖前端安全生产、跨端技术、Node.js(Serverless)以及多样化的前端技术四大方向,是2021不容错过的前端学习手册。
点击“阅读原文”,立即下载吧~