
Timm助力ResNet焕发“第二春”,无蒸馏且无额外数据,性能高达80.4%
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

arXiv:https://arxiv.org/abs/2110.00476
code: https://github.com/rwightman/pytorch-image-models
Abstract
自从恺明大神提出ResNet以来,ResNet就成为了各个领域的默认/基线架构。与此同时,更好的优化器、数据增广方法也得到研究并用于提升训练效率。
本文对ResNet50与这些新技术组合时的性能进行了重评估,并将相应的训练配置以及预训练模型进行了开源,希望能够为未来的研究提供更好的基线。比如,基于所提训练配置,ResNet50达到了80.4%的top-1精度 (无需任何额外数据或蒸馏)。
Background
一般来讲,模型的精度与网络架构、训练配置以及度量噪声,可以描述为:
其中,分别代表网络架构、训练配置以及度量噪声。
在现有文献中,ResNet50的性能从75.2%-79.5%不等。尚不明确是否已进行了充分研究进一步推进基线模型的性能。本文则旨在填充该差距:以原生ResNet为基线,通过优化训练配置最大的提升提性能 。本文贡献包含以下几点:
本文为ResNet50提出三种可作为强基线的训练方案;
所提训练方案包含近期的一些进展以及新的建议,比如移除CE损失改用BCE损失;
度量了模型精度关于不同种子的稳定性,通过比较ImageNet-val与ImageNetV2上的验证性能对过拟合问题进行了讨论;
对主流架构进行了训练并重评估其性能。
Training Procedures
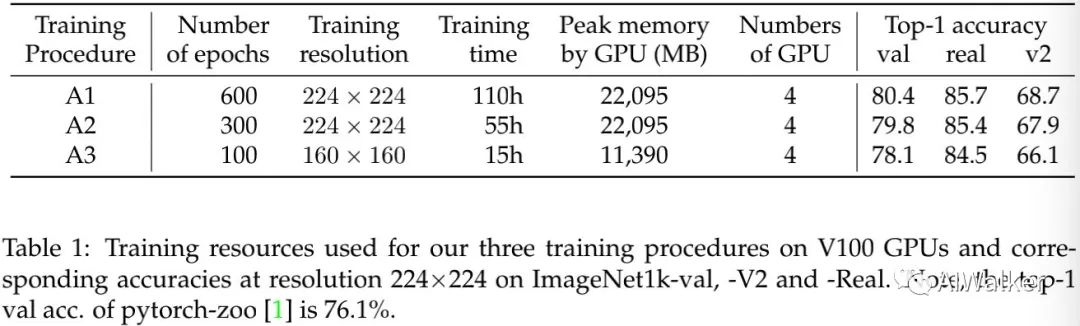
上表给出了本文所提出的三种训练配置,均旨在最大化输入分辨率时的ResNet50的性能。
Procedure A1:旨在提供具有最佳精度的ResNet50,它采用了更长的训练周期,高达600epoch;
Procedure A2:旨在与DeiT等训练机制对标,但采用了更大的batch;
Procedure A3:旨在以更少的训练周期超越原生ResNet50训练机制;
接下来,我们对上述三种训练机制中用到的一些技术进行介绍:
Loss: multi-label classification objective 损失函数方面考虑了Mixup与Cutmix增广的内在机制,弃用CE损失而改用BCE损失。
Data-augmentation 在数据增广方面,类似DeiT采用了Random Resized Crop、Horizontal Flip、RandAugment、Mixup、Cutmix等组合(见timm库)。
Regularization 在正则技术方面,本文采用Repeated-Augmentation、Stochasti-Depth、Label Smoothing等等,不同长度的训练周期采用不同的正则技术。
Optimization 优化器方面弃用SGD而选用了LAMB。
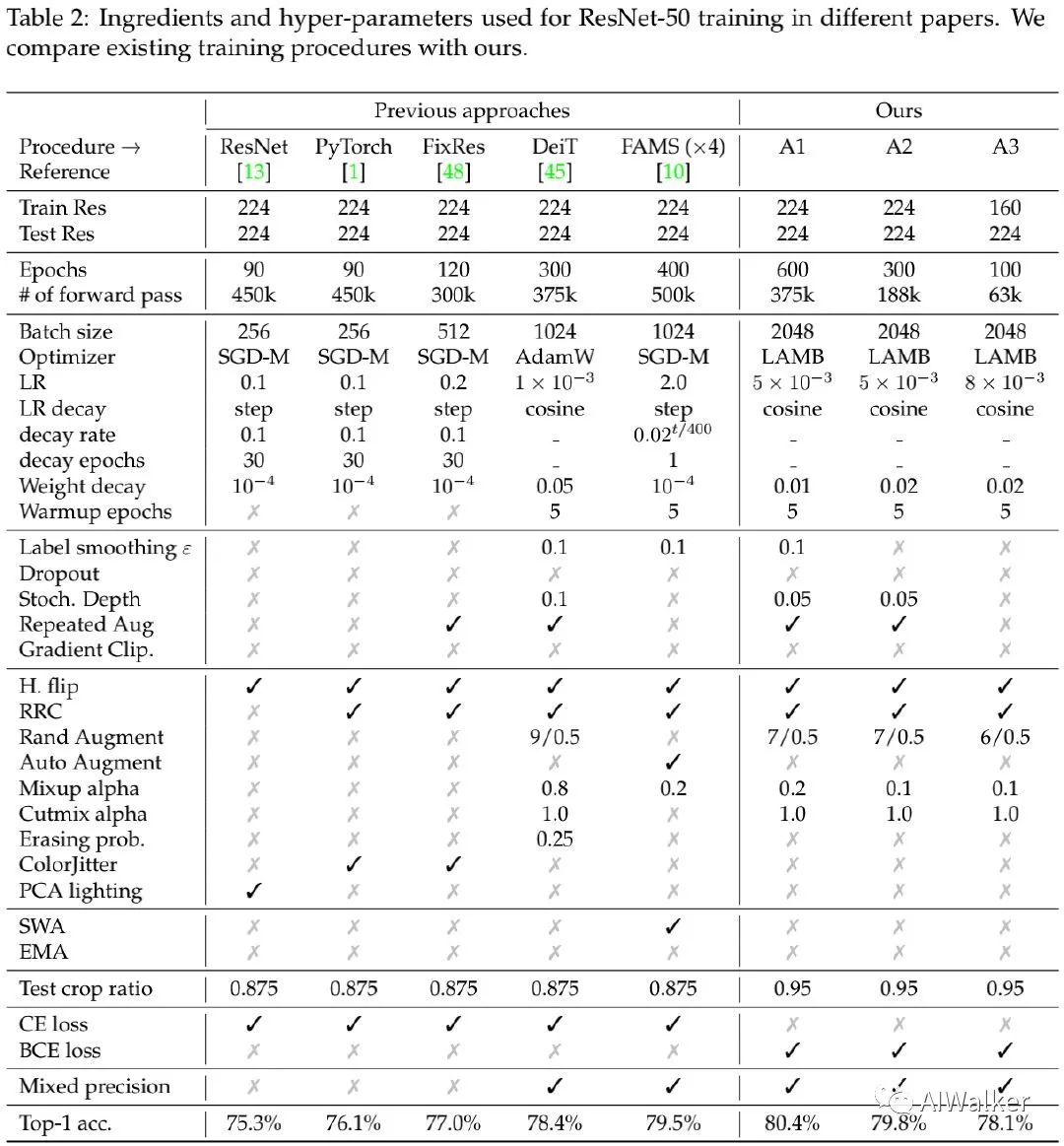
上表给出了不同训练机制的相关超参信息对比,注:上表仅以原生ResNet50作为基线进行对比。此外,本文并未考虑其他更先进的训练机制,比如知识蒸馏、自监督预训练以及伪标签。
Experiments
在实验过程中,我们首先在不同架构上对比了所提训练机制与现有训练机制。通过以下两点因素讨论了所提方案的重要性:
对性能对随机因素的敏感性进行了量化;
通过不同测试集上上的度量过拟合问题进行了评估。
Comparison of training procedures for ResNet50
从上面的Table1可以看到:所提A1训练机制取得了原始ResNet50有史以来的最佳性能80.4%( ) ;所提A2与A3训练机制以更少的资源取得了低于A1方案性能但仍旧非常高的性能79.8%与78.1%。
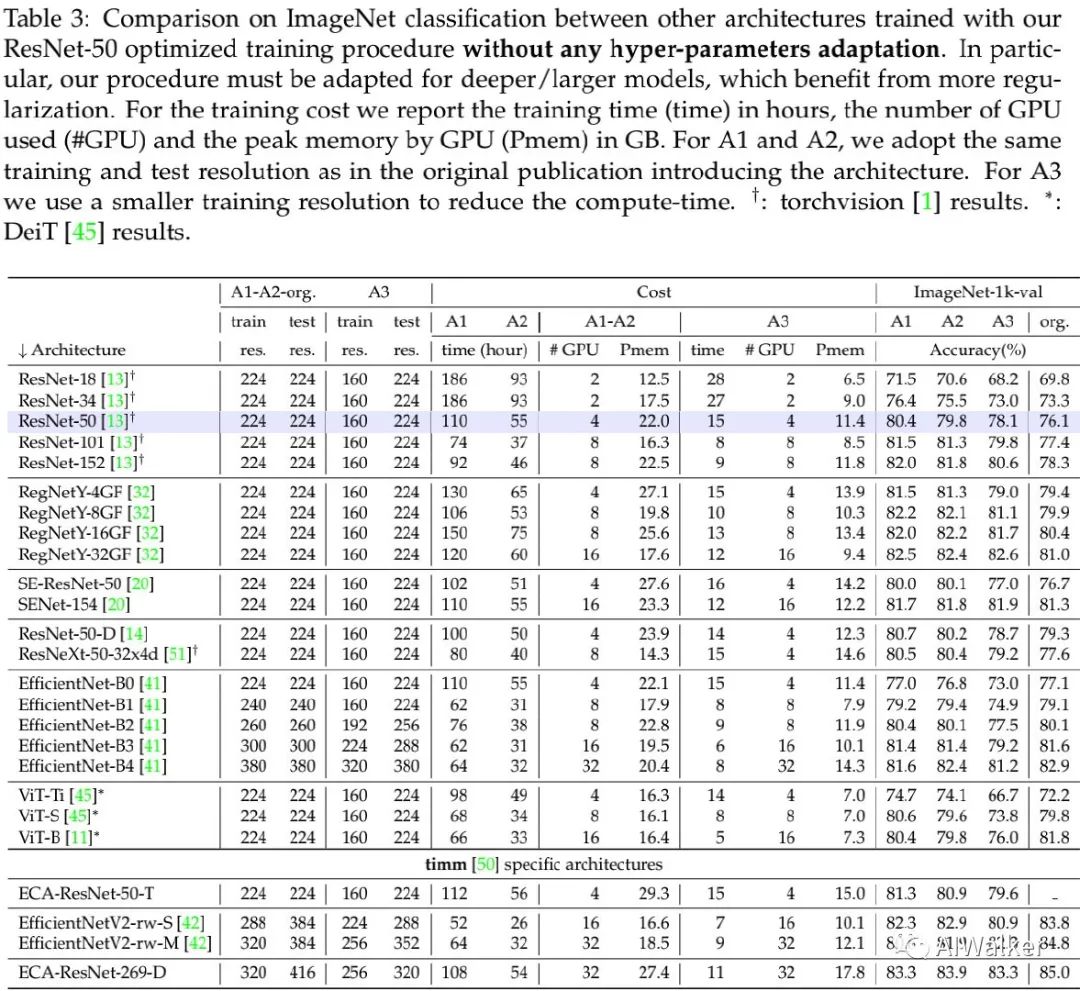
上表给出了所提训练机制+不同架构的性能,从中可以看到:在某些情形下,A2训练机制取得了比A1更高的精度,这说明:超参数不会针对更长训练周期进行自适应调整。与此同时,上表给出了A1训练机制与不同方案组合时的性能。

Significance of measurements: seed experiments
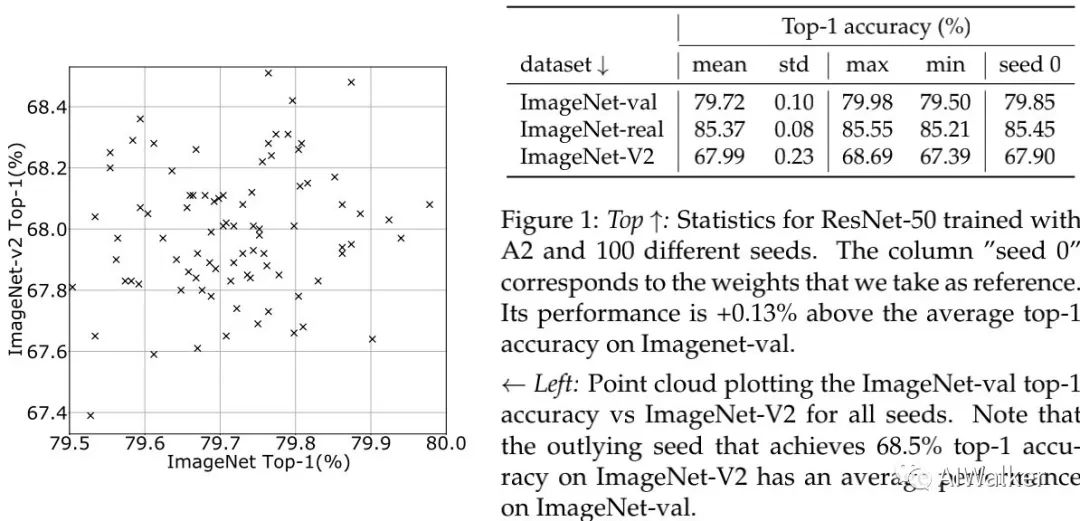
上图给出了A2训练机制+ResNet50在100次训练下的性能点图,从中可以看到:
ImageNet-val上的精度标准差约为0.1,见上图;
ImageNetV2上的精度标准差约为0.23,标准差更高;
平均精度79.72%要比种子0时的精度高0.13%。

为防止验证集上过多高估模型性能,我们仅仅选择最后的checkpoint进行性能评估。上图给出了精度的直方图分布,最高精度接近80.0%。关于性能与epoch之间的关系曲线可详见下图。

Transfer Learning
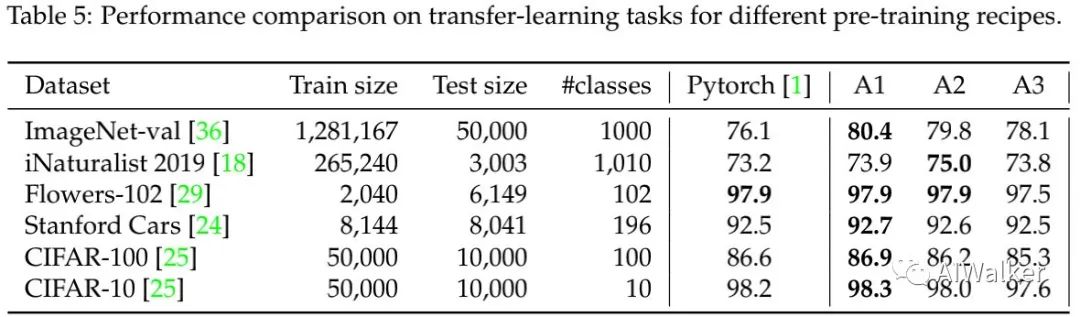
上表给出了不同数据集上的模型迁移学习能力,可以看到:
在特定数据集(如CIFAR、Standford Cars)上,微调会平滑性能差异;
总体来说,A1训练机制会在下游任务上导致最佳性能;而A3则弱于基线性能(可能与训练时图像分辨率()小有关)。
Comparing architectures and training procedures: a show-case of contradictory conclusions

不同架构、不同训练机制组合的性能对比,从中可以看到:
ResNet50的最佳训练机制为A2,而DeiT-S的最佳训练机制则是T2;
相比原生训练机制,新提出T2训练机制可以提升DeiT-S性能0.6%;
网络架构与训练机制的相互影响导致很难在一个公平的情况下对模型性能进行对比。
Ablations

上表对损失函数、学习率-性能之间的影响进行了消融对比,从中可以看到:
学习率对于性能有非常重要的影响,更高的学习率()具有更高的性能(仅限表中对比哦);
权值衰减因子有些敏感,且会与正则技术相互影响;
BCE损失取得了比CE损失更高的性能;
Repeated Augmentation可以取得更好的性能提升,同时与其他超参存在复杂的相关性。

上表随机深度、标签平滑在不同训练机制中的影响,从中可以看到:
对于A3来说,不用随机深度性能更佳,而对于A1与A2使用0.05的随机深度具有更高的性能;
对于低于300epoch的训练机制,标签平滑反而失效;对于更长周期的训练,标签平滑可以取得正面性能提升。

上表对比了不同增广的作用,可以看到:不同的改动均会对性能产生影响,均低于平均精度79.72%。
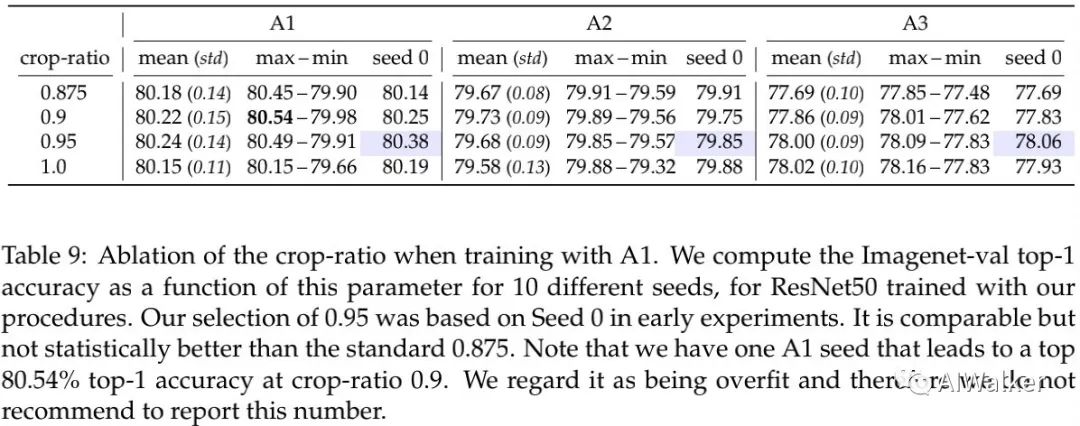
上表给出了推理阶段不同crop-ratio的影响,0.95对于A1具有更高的平均精度。
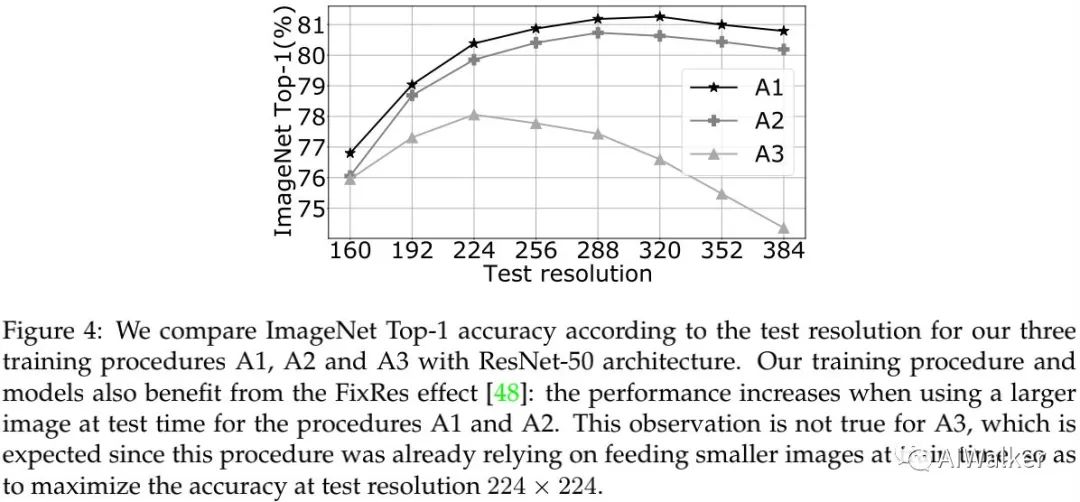
上表比较了推理阶段分辨率对性能的影响,可以看到:在更高分辨率测试时,A1与A2训练的模型具有更高的性能。
个人反思
现在每天arxiv上都能看到大量的paper发出来,质量层次不齐,就连基线模型的精度都差别甚大,以ResNet这个深度学习领域最知名的网络来说,不同paper引用时的精度甚至差别高达近4个点,不得不说,这为灌水提供了天然的土壤。
知名timm库的作者Ross从训练配置角度出发,对ResNet的性能进行了深入的探索,使其焕发“第二春”,使其性能达到80.4%。为未来网络结构的改进提供了一个非常有价值的基线,也为后续“水文”设置了一个较强的门槛,赞!
ResNet的训练配置从早期到现在网络的训练配置发生了多次的迭代,优化器、损失函数、数据增广、正则技术等等涨点技术均发生了“天翻地覆”的变化,如果在这个年代还与原生ResNet性能对比,着实很难让人怀疑:改进带来的性能提升到底是训练配置导致的还是改进带来的,改进又真正带来了多大的提升。
笔者在平时的一些训练学习中也有类似的体会,也在想:既然已经有了那么多优秀的涨点技巧,我们为什么不通过这些技术把基线往上提升一下呢?一直跟原生的性能对比真的公平吗?基线模型的性能不应该是“与时俱进”吗?否则学术界的大佬们研究那么多新技术其价值几何?个人赞成:基线模型的性能也应该“与时俱进”,及时吸收最新的技术,为真正有价值的研究提供一个强有力的基线。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
