
MySQL 老有贼慢 SQL ,怎么优化?

阅读本文大概需要 8 分钟。
来自:my.oschina.net/liughDevelop/blog/1788148
一、导致SQL执行慢的原因
二、分析原因时,一定要找切入点
三、什么是索引?
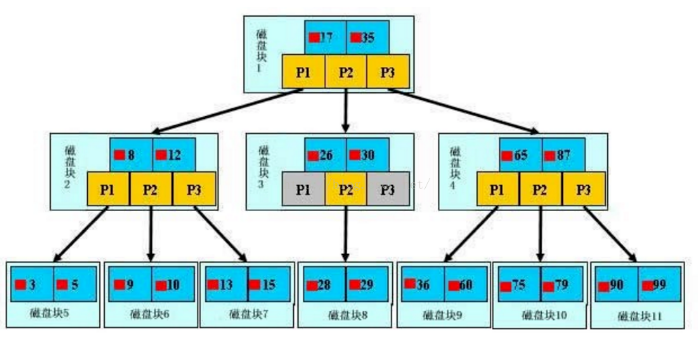
四、Explain分析
CREATE TABLE `user_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL DEFAULT '',
`age` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_index` (`name`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO user_info (name, age) VALUES ('xys', 20);
INSERT INTO user_info (name, age) VALUES ('a', 21);
INSERT INTO user_info (name, age) VALUES ('b', 23);
INSERT INTO user_info (name, age) VALUES ('c', 50);
INSERT INTO user_info (name, age) VALUES ('d', 15);
INSERT INTO user_info (name, age) VALUES ('e', 20);
INSERT INTO user_info (name, age) VALUES ('f', 21);
INSERT INTO user_info (name, age) VALUES ('g', 23);
INSERT INTO user_info (name, age) VALUES ('h', 50);
INSERT INTO user_info (name, age) VALUES ('i', 15);
CREATE TABLE `order_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`user_id` BIGINT(20) DEFAULT NULL,
`product_name` VARCHAR(50) NOT NULL DEFAULT '',
`productor` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p2', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'DX');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p5', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (3, 'p3', 'MA');
INSERT INTO order_info (user_id, product_name, productor) VALUES (4, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (6, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (9, 'p8', 'TE');

1.id
--id相同,执行顺序由上而下
explain select u.*,o.* from user_info u,order_info o where u.id=o.user_id;

--id不同,值越大越先被执行
explain select * from user_info where id=(select user_id from order_info where product_name ='p8');

2.select_type
SIMPLE: 表示此查询不包含 UNION 查询或子查询
PRIMARY: 表示此查询是最外层的查询
SUBQUERY: 子查询中的第一个 SELECT
UNION: 表示此查询是 UNION 的第二或随后的查询
DEPENDENT UNION:UNION 中的第二个或后面的查询语句, 取决于外面的查询
UNION RESULT, UNION 的结果
DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
DERIVED:衍生,表示导出表的SELECT(FROM子句的子查询)
3.table
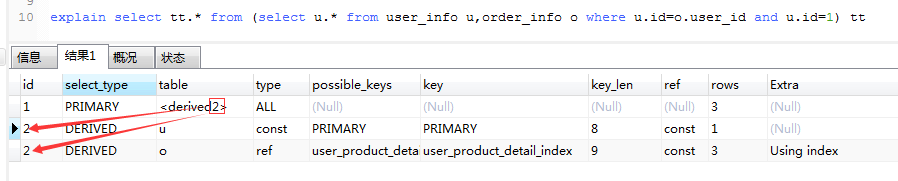
explain select tt.* from (select u.* from user_info u,order_info o where u.id=o.user_id and u.id=1) tt
4.type

type 常用的取值有:
system: 表中只有一条数据, 这个类型是特殊的 const 类型。
const: 针对主键或唯一索引的等值查询扫描,最多只返回一行数据。const 查询速度非常快, 因为它仅仅读取一次即可。例如下面的这个查询,它使用了主键索引,因此 type 就是 const 类型的:explain select * from user_info where id = 2;
eq_ref: 此类型通常出现在多表的 join 查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果。并且查询的比较操作通常是 =,查询效率较高。例如:explain select * from user_info, order_info where user_info.id = order_info.user_id;
ref: 此类型通常出现在多表的 join 查询,针对于非唯一或非主键索引,或者是使用了 最左前缀 规则索引的查询。例如下面这个例子中, 就使用到了 ref 类型的查询:explain select * from user_info, order_info where user_info.id = order_info.user_id AND order_info.user_id = 5
range: 表示使用索引范围查询,通过索引字段范围获取表中部分数据记录。这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中。例如下面的例子就是一个范围查询:explain select * from user_info where id between 2 and 8;
index: 表示全索引扫描(full index scan),和 ALL 类型类似,只不过 ALL 类型是全表扫描,而 index 类型则仅仅扫描所有的索引, 而不扫描数据。index 类型通常出现在:所要查询的数据直接在索引树中就可以获取到, 而不需要扫描数据。当是这种情况时,Extra 字段 会显示 Using index。
ALL: 表示全表扫描,这个类型的查询是性能最差的查询之一。通常来说, 我们的查询不应该出现 ALL 类型的查询,因为这样的查询在数据量大的情况下,对数据库的性能是巨大的灾难。如一个查询是 ALL 类型查询, 那么一般来说可以对相应的字段添加索引来避免。
ALL < index < range ~ index_merge < ref < eq_ref < const < system
5.possible_keys
6.key
explain select o.* from order_info o where o.product_name= 'p1' and o.productor='whh';
create index idx_name_productor on order_info(productor);
drop index idx_name_productor on order_info;


7.key_len
8.ref

9.rows
10.extra

using filesort :表示 mysql 需额外的排序操作,不能通过索引顺序达到排序效果。一般有 using filesort都建议优化去掉,因为这样的查询 cpu 资源消耗大。
using index:覆盖索引扫描,表示查询在索引树中就可查找所需数据,不用扫描表数据文件,往往说明性能不错。
using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高,建议优化。
using where :表名使用了where过滤。
五、优化案例
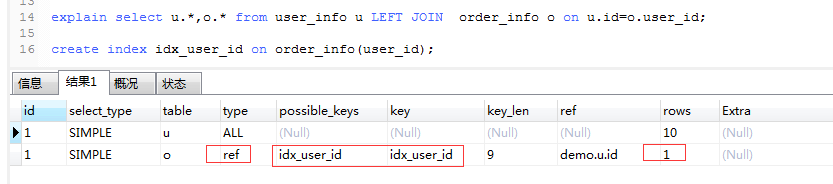
explain select u.*,o.* from user_info u LEFT JOIN order_info o on u.id=o.user_id;

六、是否需要创建索引?

别忘记点个在看,咱们下篇见!
慢一点才能更快
推荐阅读:
微信扫描二维码,关注我的公众号
朕已阅 