
中国奥运会成绩,知道多少?13张图告诉你
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Peter~
最近奥运会也是非常热门的事件,但是针对本次奥运会有很多值得吐槽的地方,小岛国的骚气操作不想写
于是Peter从网上收集的我国从1984年第一次参加夏季奥运会到2016年的历届奥运会获奖情况,了解下历届的奥运会成绩。
数据整理成宽表和长表两种形式,进行简单的数据处理和不同方式的可视化图形展示,方便大家了解我国的奥运会成绩。
文中全程使用的绘图工具是高级可视化库:plotly
往期精选
本文使用的数据很简单,但是涉及到了很多之前关于Plotly绘图和Python的文章,推荐阅读:
图形预览
看看部分图形效果展示:
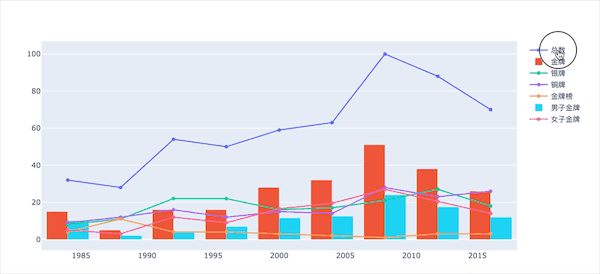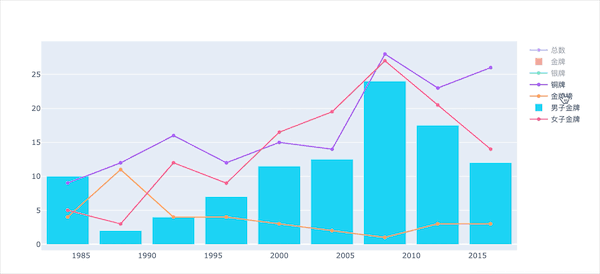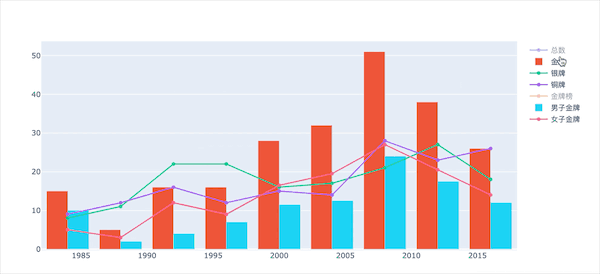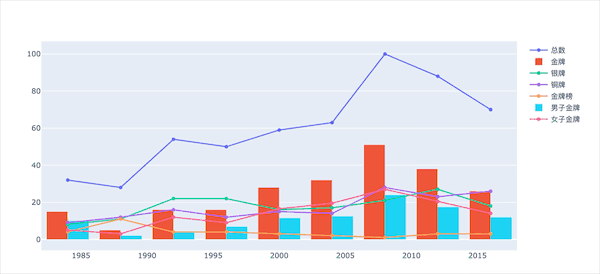
导入库
导入的库主要是两种:数据处理和绘图相关
# 数据处理相关
import pandas as pd
import numpy as np
# 绘图相关
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots # 制作多子图
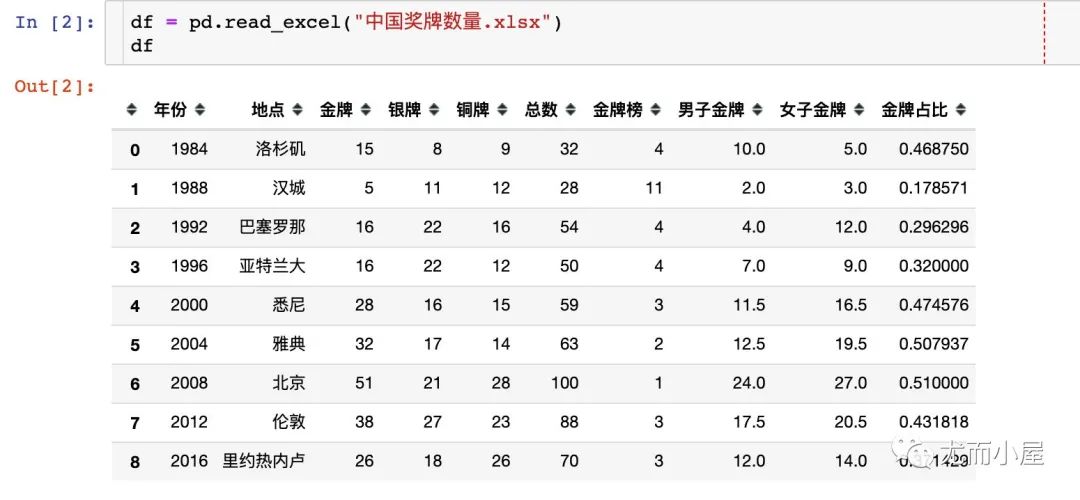
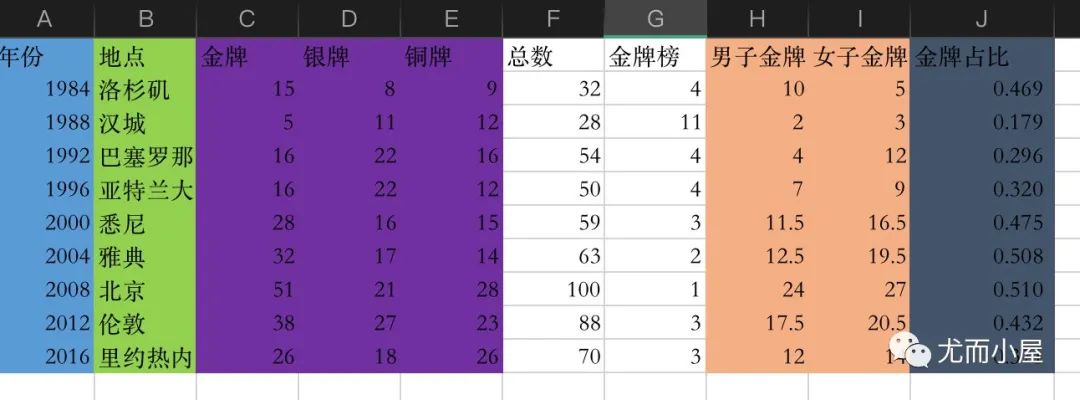
两种形式数据
从网上收集的中国队历届夏季奥运会获奖情况,整理成两种形式:宽表和长表
1、宽表
宽表形式是将字段尽可能多罗列出来
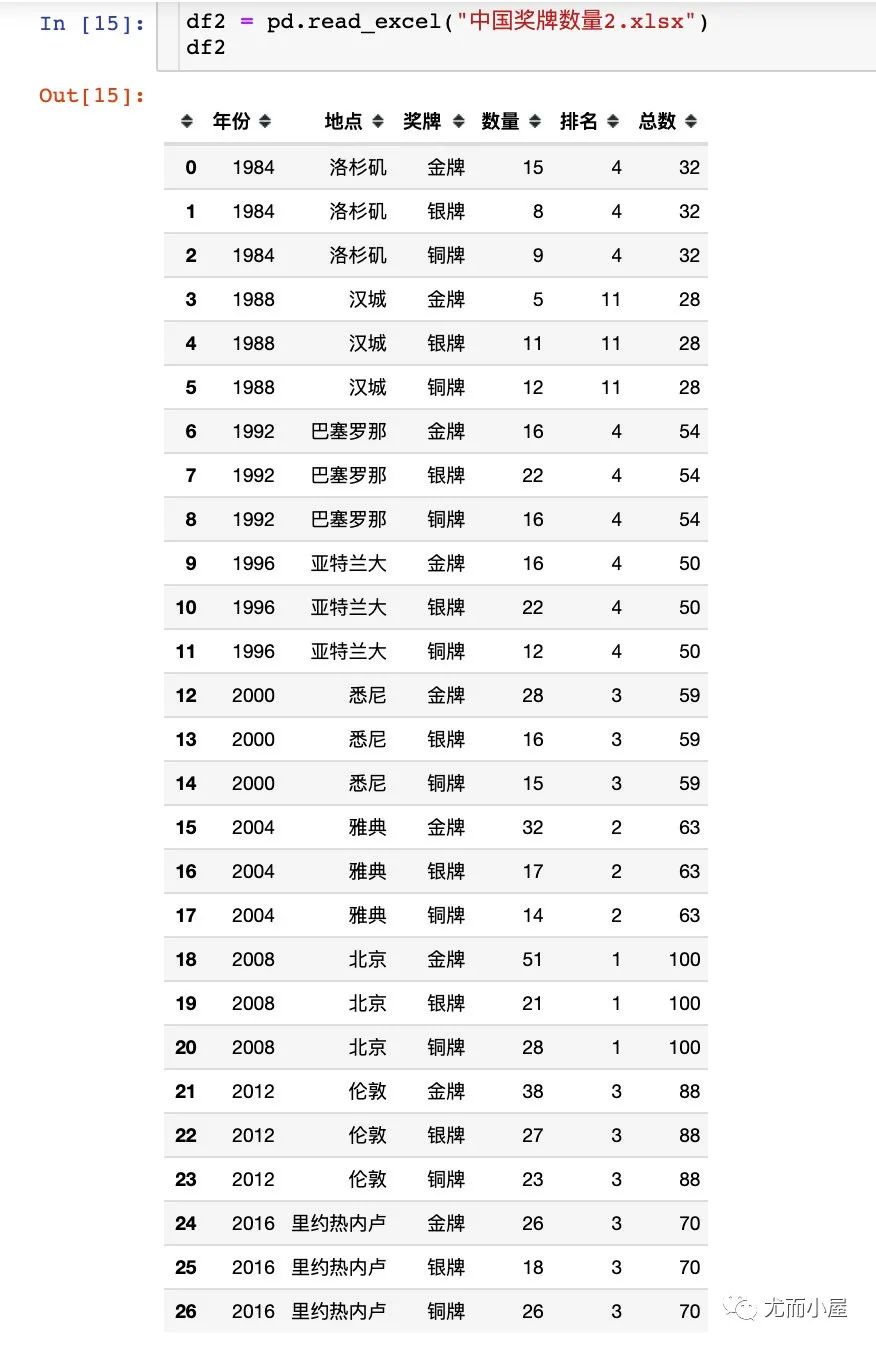
2、长表
长表形式是将字段尽可能减少,同一个字段的数据信息可能出现重复
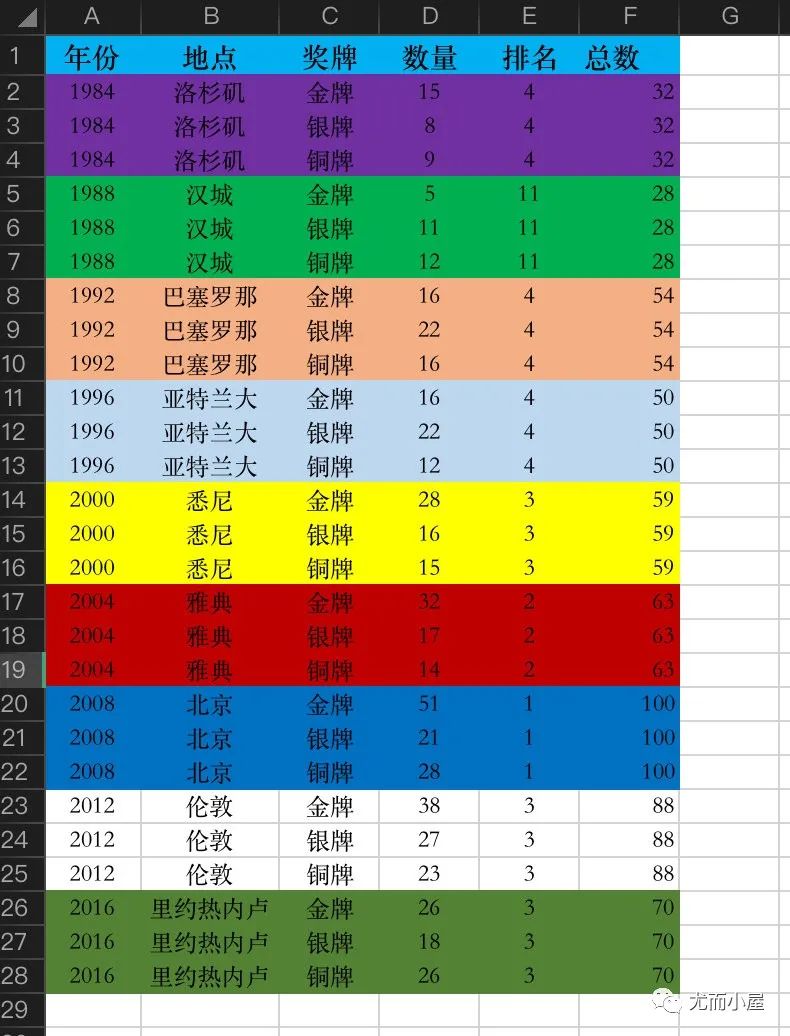
中国参加了多少届夏季奥运会
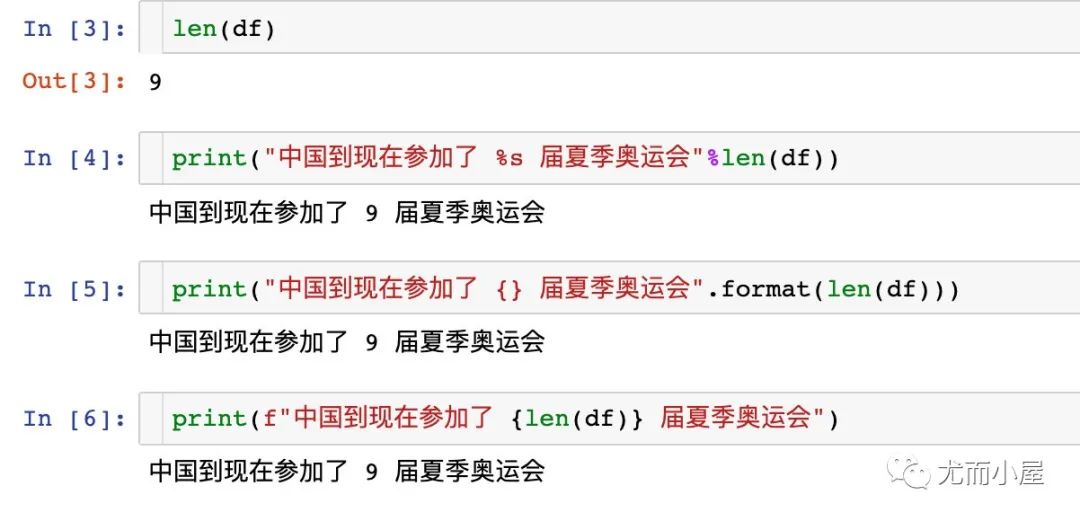
主要讲解的是Python中字符串格式化的知识点,3种不同的格式化展示方式:
占位符%s format() f-string
总奖牌数
展示的是中国历届奥运会的总奖牌数变化趋势:
fig = px.line(df,x="地点",y="总数",text="总数")
fig.update_layout(title="中国获得总奖牌数")
fig.show()
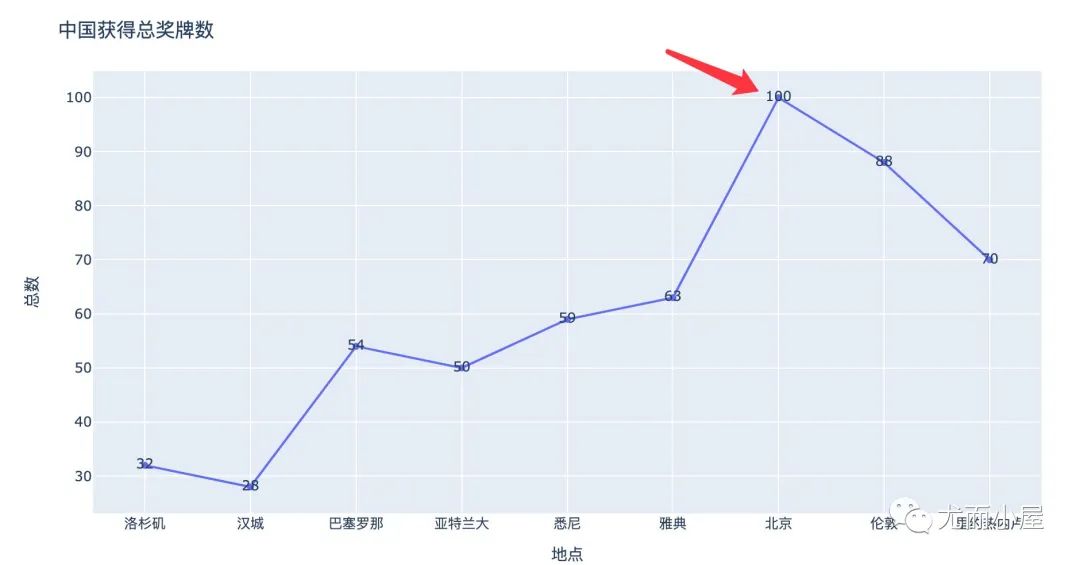
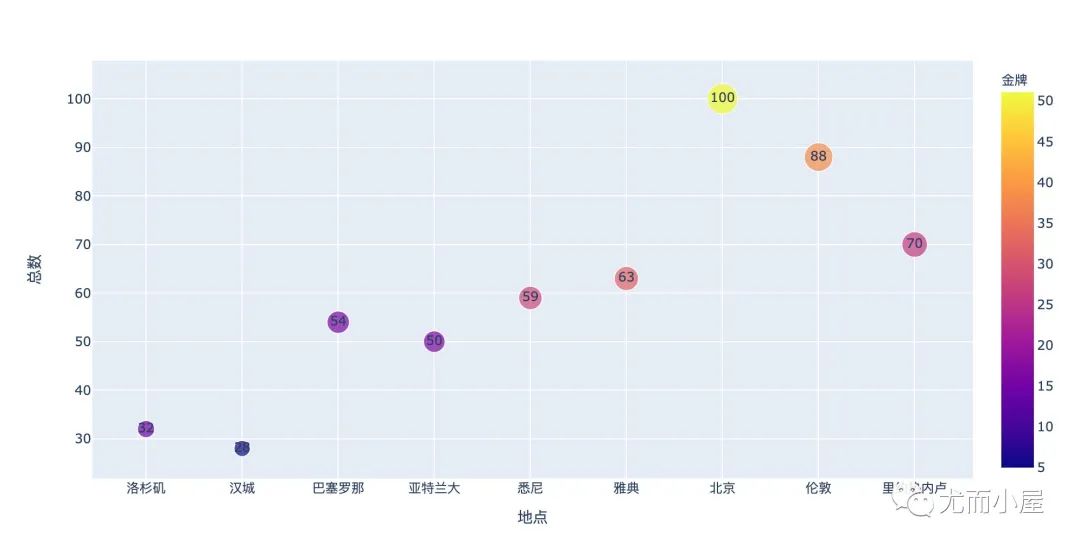
从结果的图形中,我们看到2008年是最多的,刚好是100枚毕竟是家门口的比赛
fig = px.scatter(
df,
x="地点",
y="总数",
color="金牌",
size="总数",
text="总数"
)
fig.show()
男子和女子金牌对比
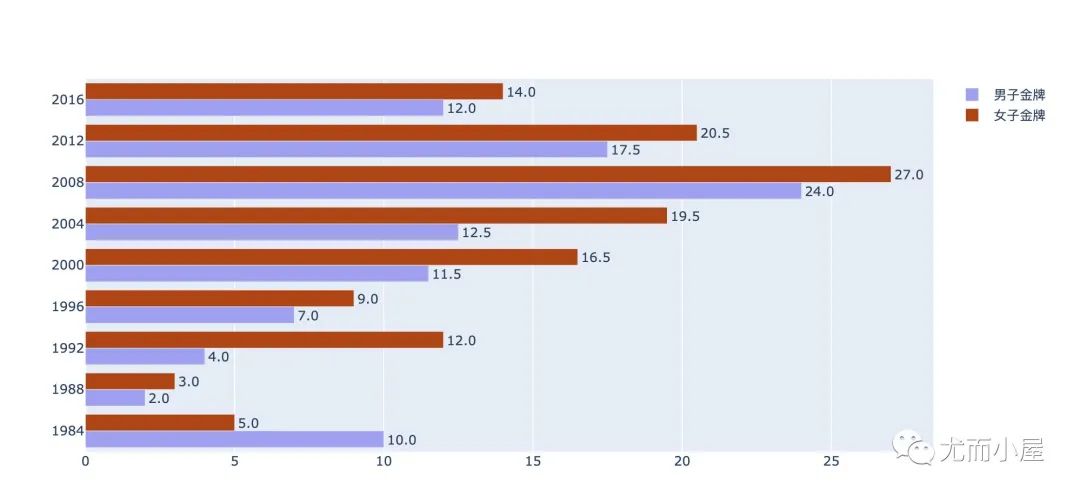
从结果中我们可以看出来:
1984年第一次参加奥运会,男子金牌数量是高于女子的 此后,每届都是女子高于男子:巾帼不让须眉
多指标变化
fig = go.Figure()
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["总数"].tolist(),
name="总数"
))
fig.add_trace(go.Bar(
x=df["年份"].tolist(),
y=df["金牌"].tolist(),
name="金牌"
))
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["银牌"].tolist(),
name="银牌"
))
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["铜牌"].tolist(),
name="铜牌"
))
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["金牌榜"].tolist(),
name="金牌榜"
))
fig.add_trace(go.Bar(
x=df["年份"].tolist(),
y=df["男子金牌"].tolist(),
name="男子金牌"
))
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["女子金牌"].tolist(),
name="女子金牌"
))
fig.show()
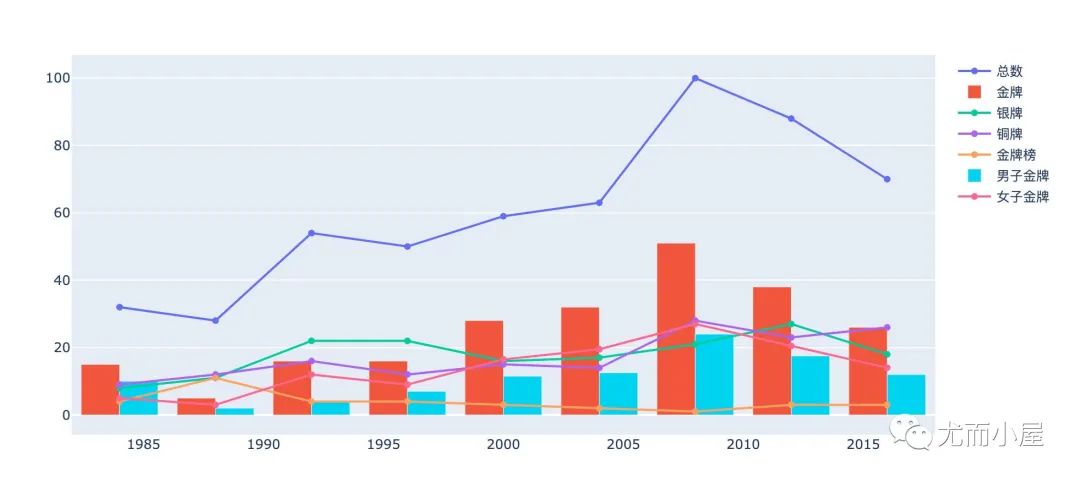
多指标变化
通过子图的形式展示不同指标的变化趋势:
# 两个基本参数:设置行、列
fig = make_subplots(rows=4, cols=2,
subplot_titles=["奖牌总数","金牌","银牌","铜牌","金牌榜","男子金牌","女子金牌","金牌占比"])
# 添加数据轨迹
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["总数"].tolist(),
name="总数"
),1,1)
fig.add_trace(go.Bar(
x=df["年份"].tolist(),
y=df["金牌"].tolist(),
name="金牌"
),1,2)
fig.add_trace(go.Bar(
x=df["年份"].tolist(),
y=df["银牌"].tolist(),
text=df["银牌"].tolist(),
textposition="outside",
name="银牌"
),2,1)
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["铜牌"].tolist(),
name="铜牌"
),2,2)
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["金牌榜"].tolist(),
mode="markers+text",
text=df["金牌榜"].tolist(),
textposition="bottom center", # 位置
name="金牌榜"
),3,1)
fig.add_trace(go.Bar(
x=df["年份"].tolist(),
y=df["男子金牌"].tolist(),
name="男子金牌"
),3,2)
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["女子金牌"].tolist(),
name="女子金牌"
),4,1)
fig.add_trace(go.Scatter(
x=df["年份"].tolist(),
y=df["金牌占比"].tolist(),
mode="lines+markers",
text=df["金牌占比"].tolist(),
textposition="top center",
name="金牌占比"
),4,2)
# 设置图形的宽高和标题
fig.update_layout(height=600,
width=800,
title_text="奥运会奖牌可视化")
fig.show()
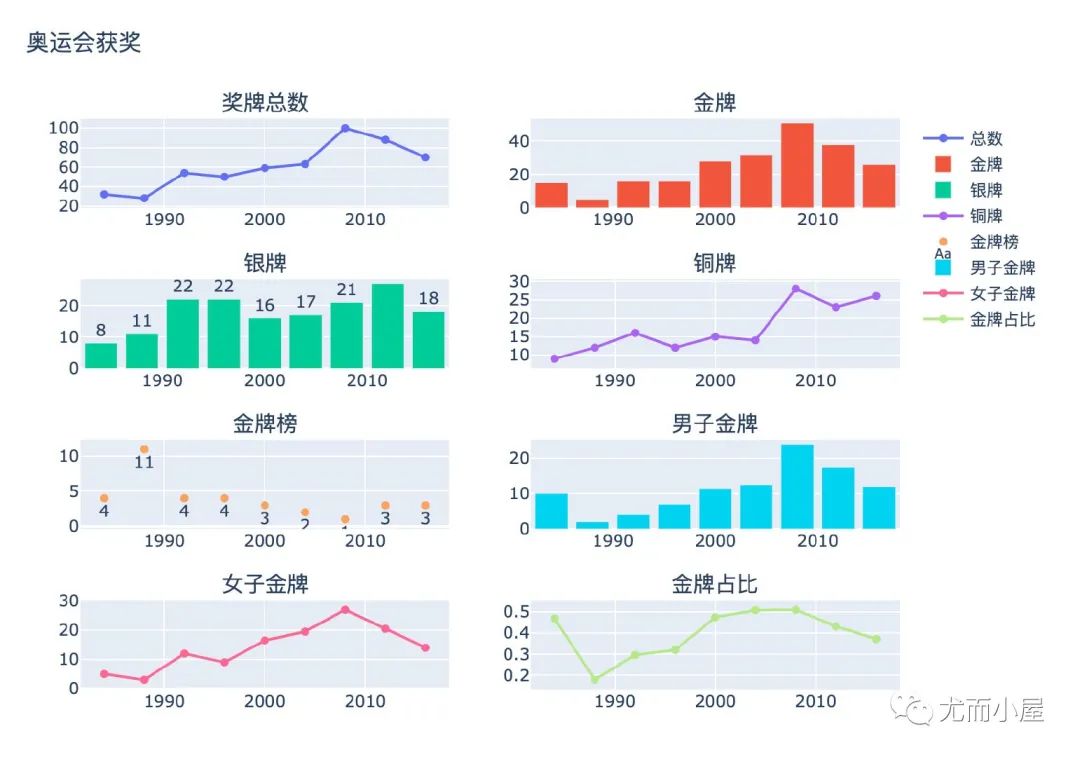
雷达图
雷达图展示的是不同年份的获奖情况
import plotly.graph_objects as go
categories = ['金牌','银牌','铜牌']
fig = go.Figure()
fig.add_trace(go.Scatterpolar(
r=df.iloc[0,2:5].tolist(),
theta=categories,
fill='tonext',
name='洛杉矶-1984'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[1,2:5].tolist(),
theta=categories,
fill='tonext',
name='汉城-1988'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[2,2:5].tolist(),
theta=categories,
fill='tonext',
name='巴塞罗那-1992'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[3,2:5].tolist(),
theta=categories,
fill='tonext',
name='亚特兰大-1996'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[4,2:5].tolist(),
theta=categories,
fill='tonext',
name='悉尼-2000'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[5,2:5].tolist(),
theta=categories,
fill='tonext',
name='雅典-2004'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[6,2:5].tolist(),
theta=categories,
fill='tonext', # ['none', 'toself', 'tonext']
name='北京-2008'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[7,2:5].tolist(),
theta=categories,
fill='tonext',
name='伦敦-2012'
))
fig.add_trace(go.Scatterpolar(
r=df.iloc[8,2:5].tolist(),
theta=categories,
fill='tonext',
name='里约热内卢-2016'
))
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 54]
)),
showlegend=True
)
fig.show()
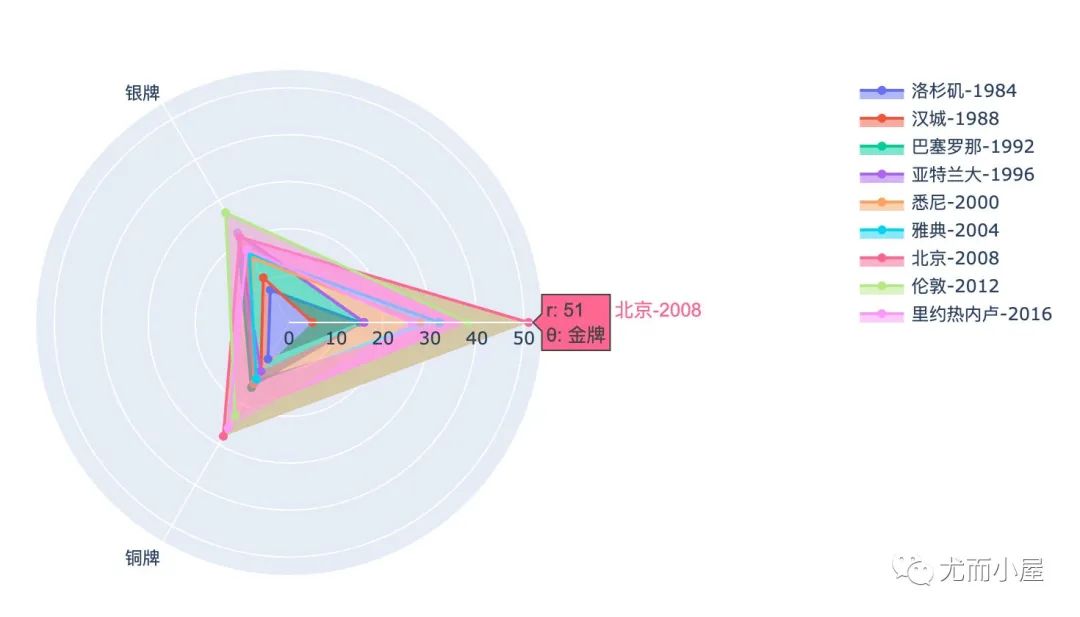
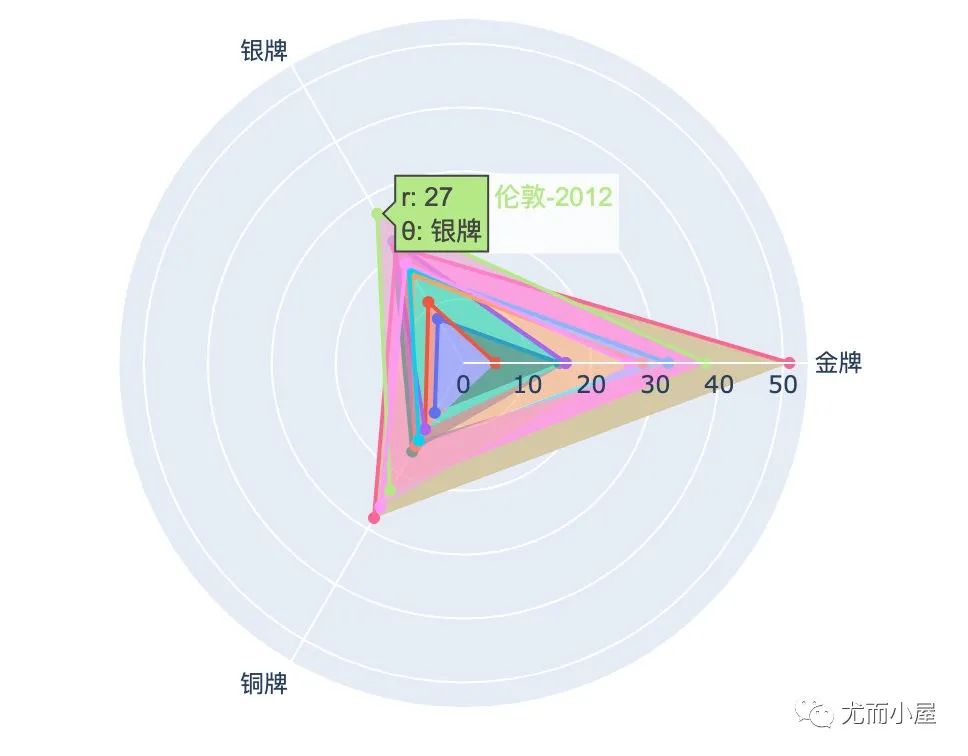
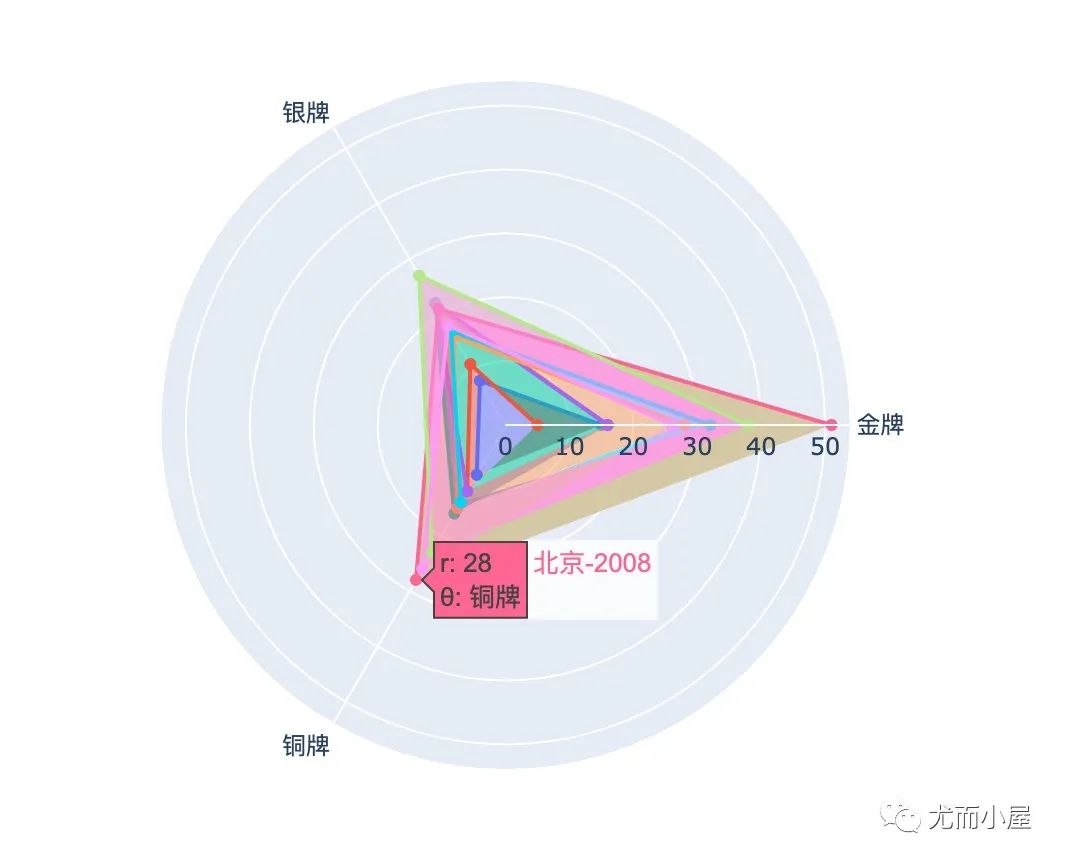
小结:从雷达图的不同维度顶端触角,就可以观察到各自的最大值,比如金牌和铜牌最多的就是北京奥运会,银牌最多的是伦敦奥运会
⚠️:上面的图形都是基于宽表形式的数据,下面是基于长表形式
金银铜牌对比
3种不同奖牌的地点(年份)对比情况:
px.bar(df2,
x="地点",
y="数量",
color="奖牌",
text="数量",
barmode="group"
)
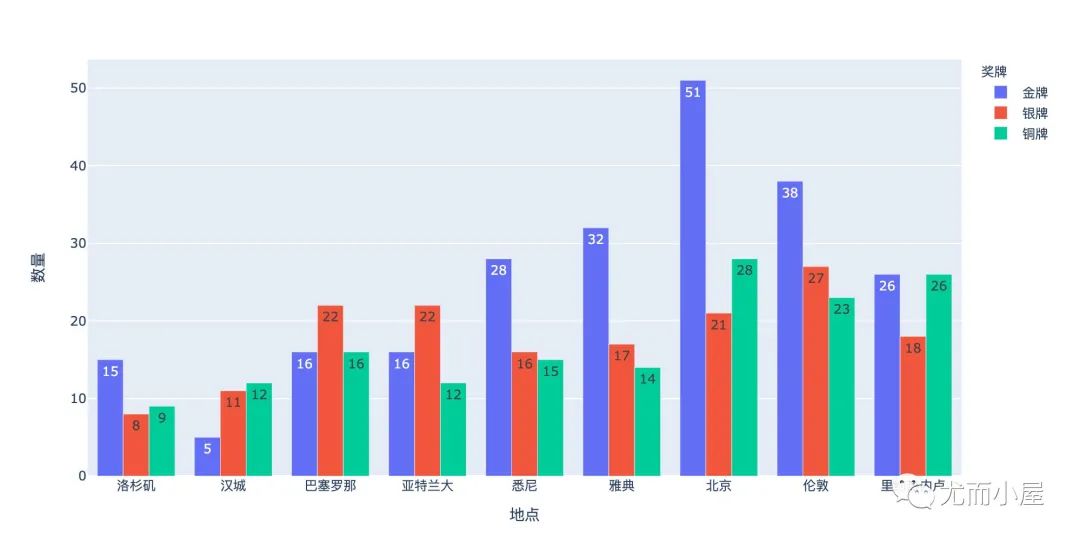
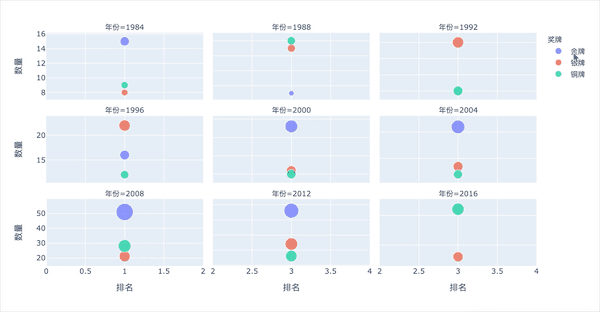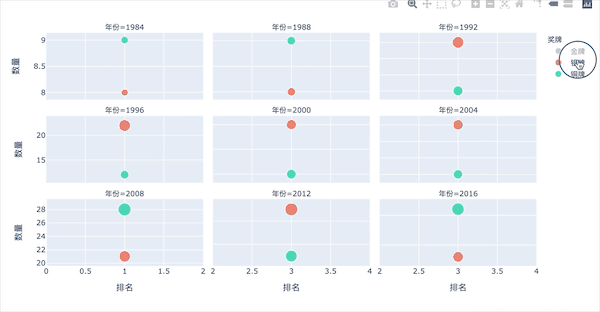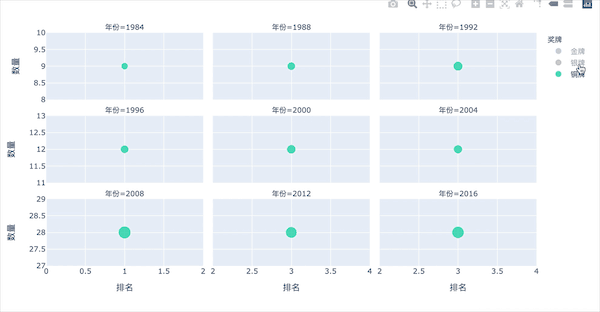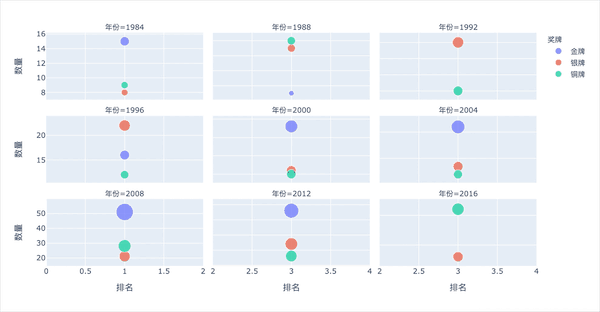
多子图-不同年份的3种奖牌数
# 不共享y轴
fig = px.scatter(
df2,
x="排名",
y="数量",
color="奖牌",
size="数量",
facet_col="年份",
facet_col_wrap=3
)
#fig.update_yaxes(matches=None) # 不共享y轴
fig.show()
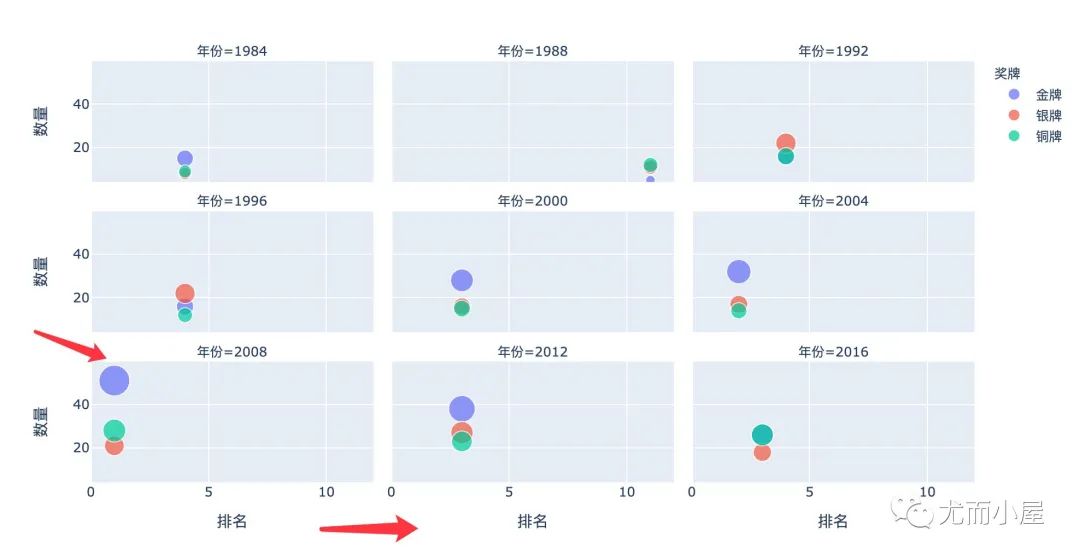
图形解释:
横坐标:整体的排名。越靠左,数值越小,排名靠前。可以看到北京奥运会是最棒的:整体排名靠左 纵坐标:每个奖牌的数量,气泡越大,数量越多。银牌是2012年伦敦,铜牌是2008年北京(看点的高度)
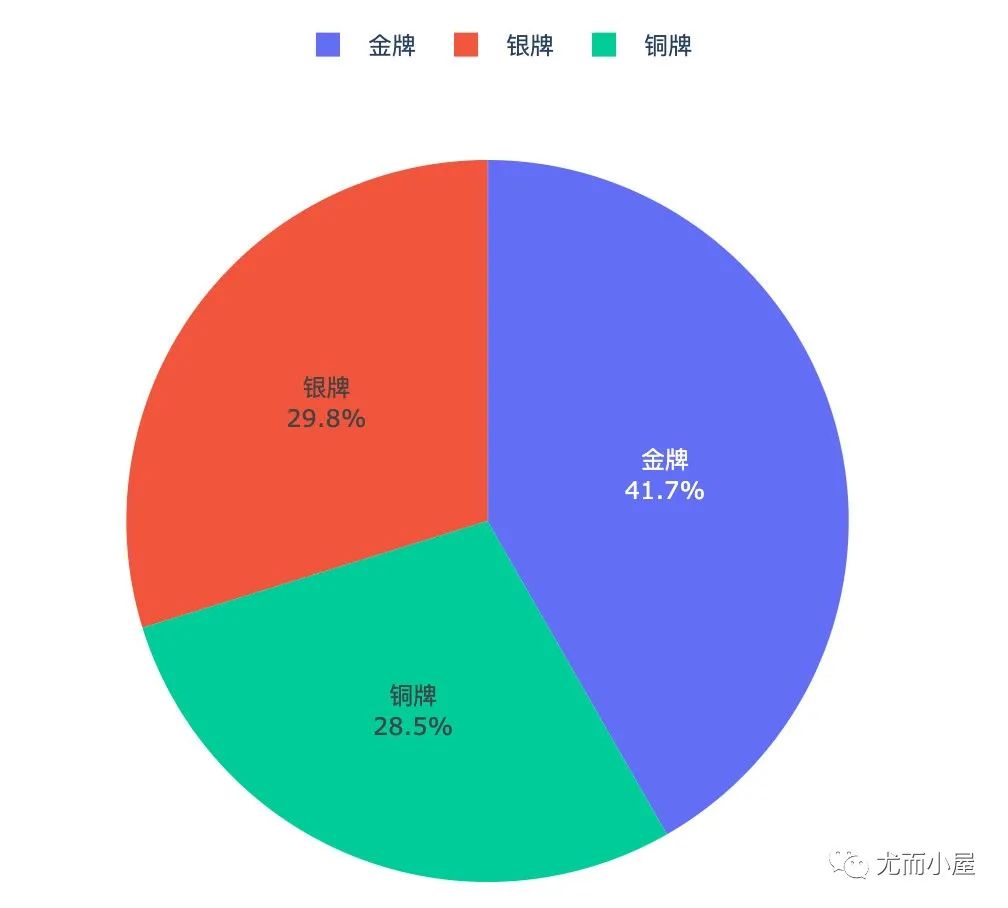
3种奖牌整体占比
3种奖牌不同年份占比
3种奖牌在不同届奥运会的占比情况:
# 两个基本参数:设置行、列
fig = make_subplots(rows=3, cols=3,
horizontal_spacing=0.08,
vertical_spacing=0.1,
column_widths=[0.4,0.4,0.4],
specs=[[{"type":"domain"},{"type":"domain"},{"type":"domain"}],
[{"type":"domain"},{"type":"domain"},{"type":"domain"}],
[{"type":"domain"},{"type":"domain"},{"type":"domain"}]
],
subplot_titles=["1984-洛杉矶","1988-汉城","1992-巴塞罗那","1996-亚特兰大",
"2000-悉尼","2004-雅典","2008-北京","2012-伦敦","2016-里约热内卢"])
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][:3].tolist(),
name="1984-洛杉矶"
),1,1)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][3:6].tolist(),
name="1988-汉城"
),1,2)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][6:9].tolist(),
name="1992-巴塞罗那"
),1,3)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][9:12].tolist(),
name="1996-亚特兰大"
),2,1)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][12:15].tolist(),
name="2000-悉尼"
),2,2)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][15:18].tolist(),
name="2004-雅典"
),2,3)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][18:21].tolist(),
name="2008-北京"
),3,1)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][21:24].tolist(),
name="2012-伦敦"
),3,2)
fig.add_trace(go.Pie(
labels=df2["奖牌"][:3].tolist(),
values=df2["数量"][24:27].tolist(),
name="2016-里约热内卢"
),3,3)
fig.update_traces(hole=0.2)
fig.show()
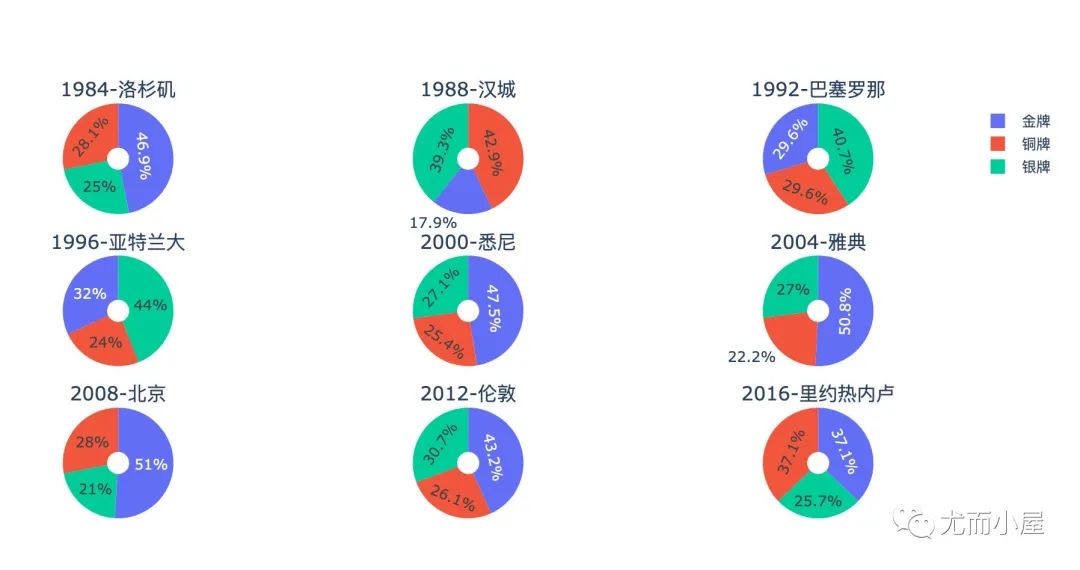
从图形可以看出来:
北京奥运会占比最高:51%;其次是雅典奥运会 1988年的汉城奥运会最低,才17.9%
3种奖牌旭日图
px.sunburst(df2,path=["奖牌","地点"],
values="数量",
color="年份",
color_continuous_scale="RdBu"
)
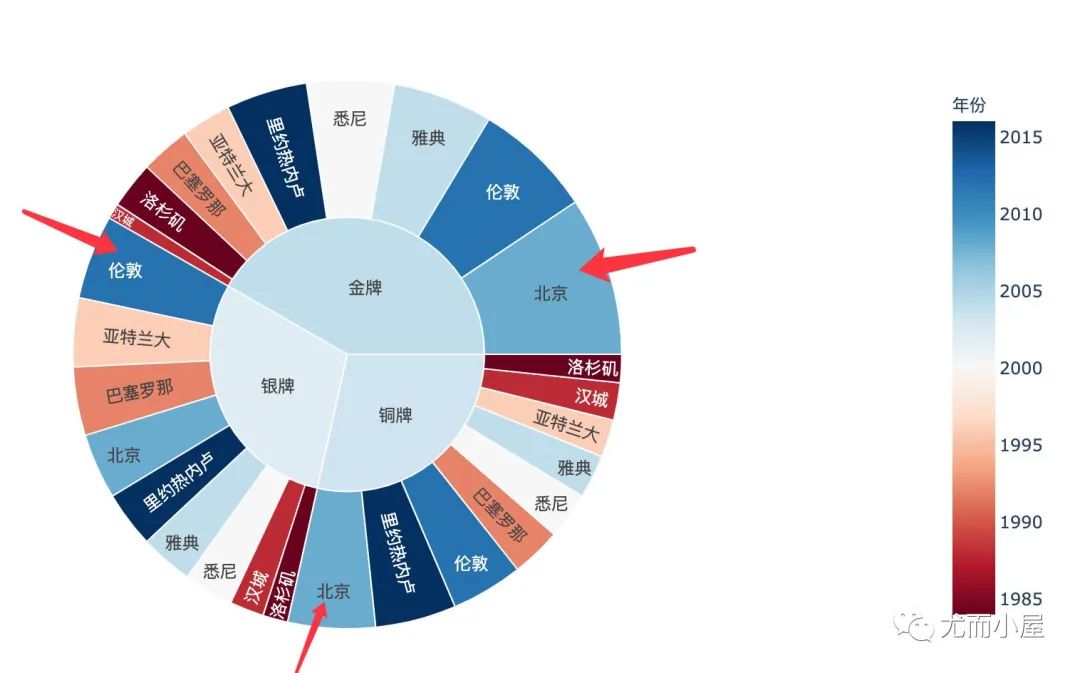
根据3种奖牌的旭日图,能够看到3种奖牌各自的排序:
金牌:北京、伦敦、雅典 银牌:伦敦、亚特兰大、巴塞罗那 铜牌:北京、里约热内卢、伦敦
总结
本文通过不同的可视化图形展示了我国的获奖情况,数据显示在北京奥运会中取得成绩是最亮眼的;其次,女子的金牌一直都是高于男子,女队员真的是巾帼不让须眉。希望在这次奥运会中国队再创辉煌!中国队,yyds!
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~