
快手大数据平台服务化实践
点击“开发者技术前线”,选择“星标🔝”
在看|星标|留言, 真爱

作者简介:倪顺,本硕毕业于北京大学,曾就职于Hulu
背景
快手是一家数据驱动的公司,数据扮演了非常重要的角色,而数据的生产加工主要依靠数据开发工程师,其工作内容会涉及多个方面:数据开发工程师则首先根据业务需求开发好高质量的数据,通常是结构化数据(数据表);其次,开发稳定可靠的数据服务,并通过API方式交付给业务方使用。数据开发工程师有两个痛点:1)开发数据服务门槛高;2)重复开发数据服务。
痛点一:开发数据服务门槛高
数据开发工程师除了开发完数据表外,通常还需要思考如下问题:
数据如何交付:业务通常期望使用数据接口方式来使用数据,而非数据表,这会更加灵活、解耦、高效。数据开发工程师因此需要建立对应的数据服务。
服务如何开发:数据服务有多种形式,通常要求开发工程师有微服务知识、服务发现注册、高并发等。
权限、可用性问题:开发完数据服务后,需要考虑权限问题,确保数据资源能被安全的访问;此外还需要考虑可用性问题,要以多种手段保障数据访问的稳定性。
运维问题:数据服务本身涉及多种运维问题,如扩容、迁移、下线、接口变更、服务报警等。
以上问题都需要数据开发工程师去解决。这要求数据开发不仅仅是开发出数据表,还需要将数据表包装成一个独立的、灵活的、高可用的、安全的数据服务。这对于数据开发工程师要求很高:除了具备基本的业务需求捕获、数据建模、SQL开发等能力外,还要具备开发高可用、高性能的数据服务能力(包括java开发、微服务等)。
痛点二:重复开发数据服务
快手很多业务线(如支付业务、直播业务、账户业务等),都存在数据需求,各业务线都做着:1)数据同步到线上数据库和缓存;2)建设微服务等开发,其中不同业务线下,数据同步和微服务通常有很多共同之处,重复烟囱式的开发意味要重复开发数据服务,造成了人力资源浪费,而且开发效率低,从数据开发到最终交付数据服务,需要经历较长的周期。
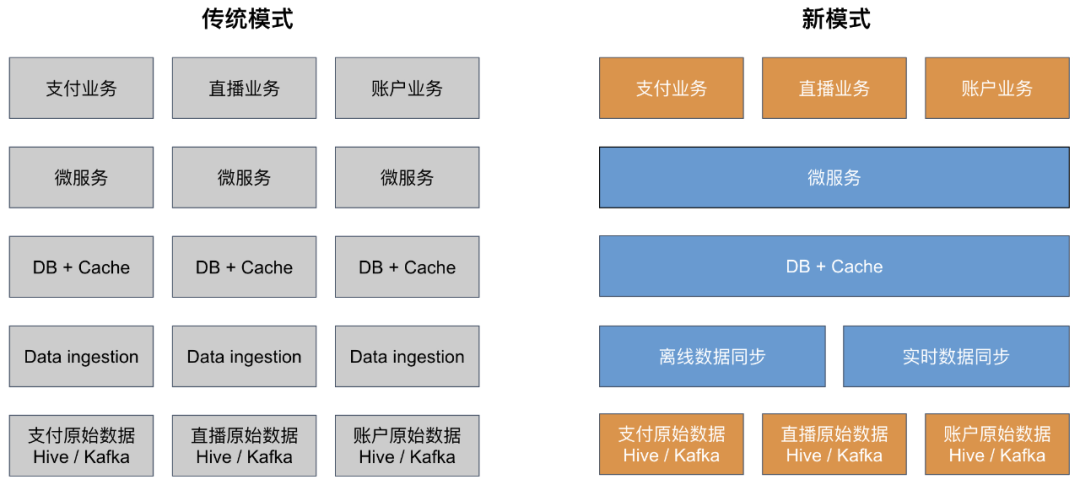
基于上述痛点,我们开始建设统一的数据服务化平台。由此开启一个新模式去解决问题。
大数据服务化平台
数据平台本身的定位是一站式自助数据服务平台。用户通过平台来创建数据服务接口、运维服务、调用服务。平台秉承“配置即服务”的理念:数据开发工程师不再需要手写数据服务,只需要在平台上进行简单配置,平台便可自动生产和部署数据服务,从而提升效率。
系统架构
大数据服务化业务架构如下所示,Data Lake 数据湖中存储原始数据,经过数据开发之后,形成按主题域组织的数据资产。此时数据资产通常是在数据仓库,访问速度较慢,因此需要通过数据加速到更高速的存储介质,最后经过多场景服务接口,服务于业务。
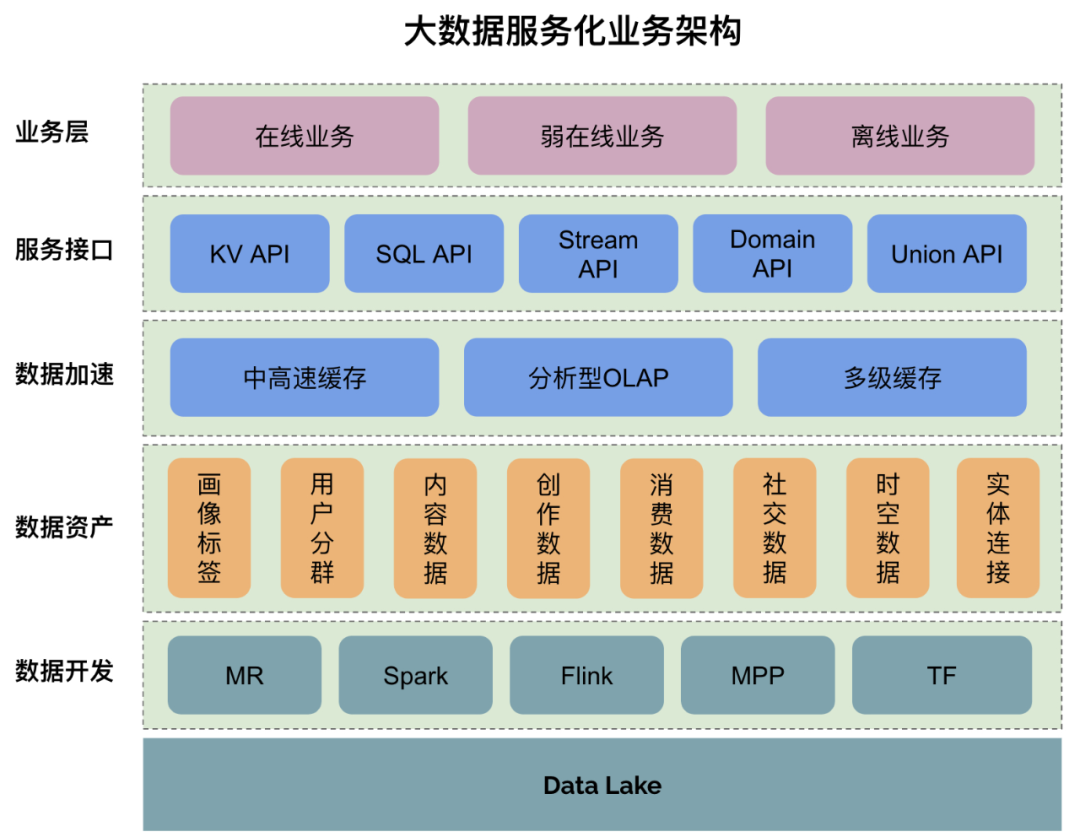
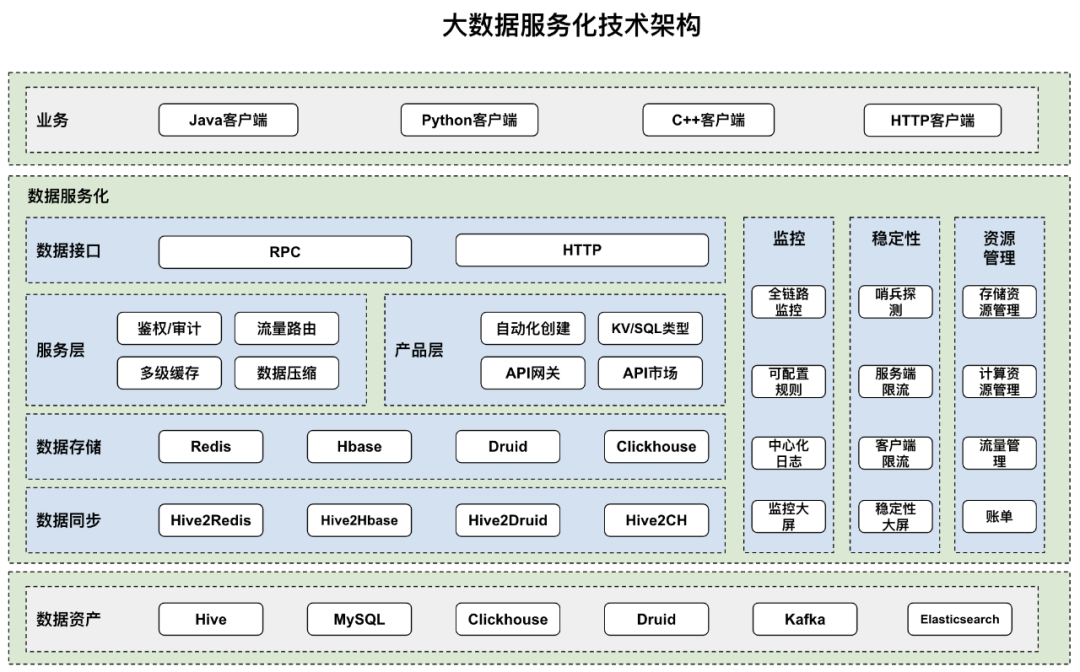
在技术架构方面,数据接口形式有 RPC 和 HTTP 两类接口。RPC 接口不需要重复建立链接,且传输数据时会被高效序列化,适用于高吞吐场景下的微服务,实现负载均衡、流控、降级、调用链追踪等功能。相对而言,HTTP 接口传输效率低一些,但使用非常简单。
关键技术一:配置即开发
平台用户分为两类角色:其一是数据服务生产方,其二是数据服务调用方。数据服务生产方只需要配置,做到“配置即开发”,配置包括:1)数据源;2)数据加速到何处;3)接口形态,访问方式;4)配置独立的测试环境,访问隔离的测试数据。当配置完毕后,数据服务平台便会根据配置清单,完成接口的自动化生产和部署。生产和部署完毕后,调用方在平台申请服务权限调用。通过自动化生产,达到配置即开发的目的,从而极大的提升效率。
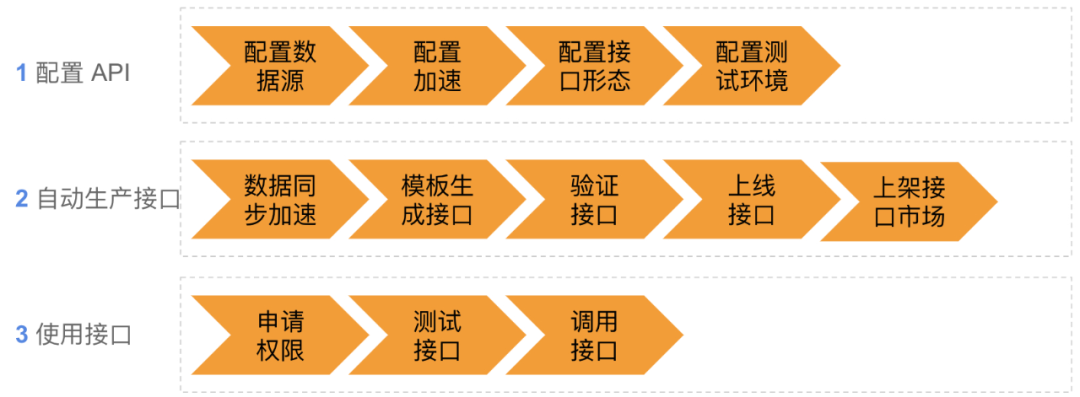
关键技术二:多模式服务形态
数据服务有多种服务形态,包括:
KV API:简单点查,可以支撑百万QPS、毫秒延迟。这类API是通过模板自动化创建出来,支持单查、批量查询等接口,返回的结果是 Protobuf (PB) 结构体,从而将结果自动做了 ORM,对于主调方更加友好。典型场景包括:根据IP查询geo位置信息、根据用户Id查询用户标签画像信息等。
SQL API:复杂灵活查询,底层基于 OLAP/OLTP 存储引擎。通过 Fluent API 接口,用户可自由组合搭配一种或若干种嵌套查询条件,可查询若干简单字段或者聚合字段,可分页或者全量取回数据。典型场景包括:用户圈选(组合若干用户标签筛选出一批用户)。
Union API:融合API,可自由组合多个原子API,组合方式包括串行和并行方式。调用方不再需要调用多个原子API,而是调用融合API,通过服务端代理访问多个子查询,可以极大降低访问延迟。

关键技术三:高效数据加速
前面提及的数据资产,通常是存在于低速的存储引擎中,无法支撑线上业务高访问流量。因此需要以系统化的方式进行数据加速。目前有两种加速方式:1)全量数据加速;2)多级缓存(部分数据加速)。
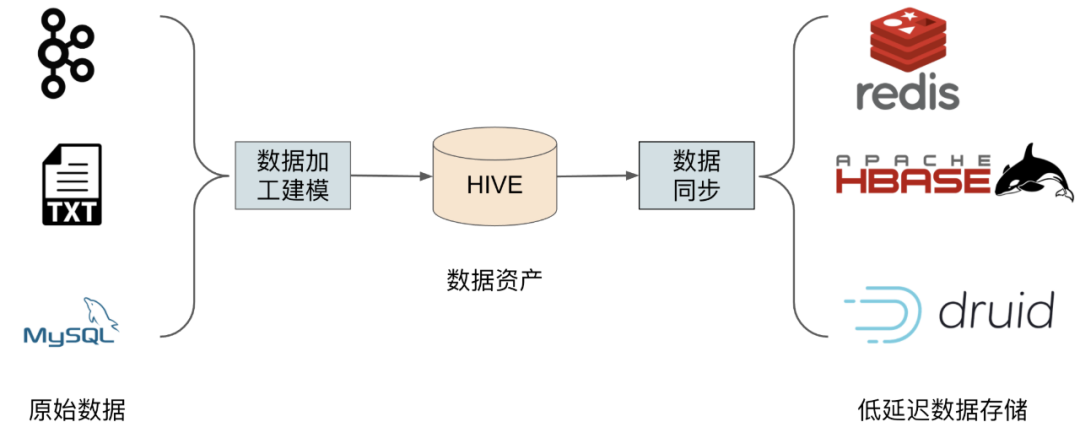
全量数据加速
从多个数据源摄入原始数据(如Kafka,MySQL、线上访问日志等),进行加工建模后,得到数据资产。数据资产经由独立的数据同步服务,同步至其他更高速的存储引擎,如 redis、hbase、druid等。数据同步支持一次性或者周期性(小时、天、周等)将数据从Hive同步至其他存储中,数据同步本身是基于分布式的调度系统,内核是基于 datax 进行数据同步。大数据服务化平台单日同步的数据量达到1200亿条,数据size达到20TB。
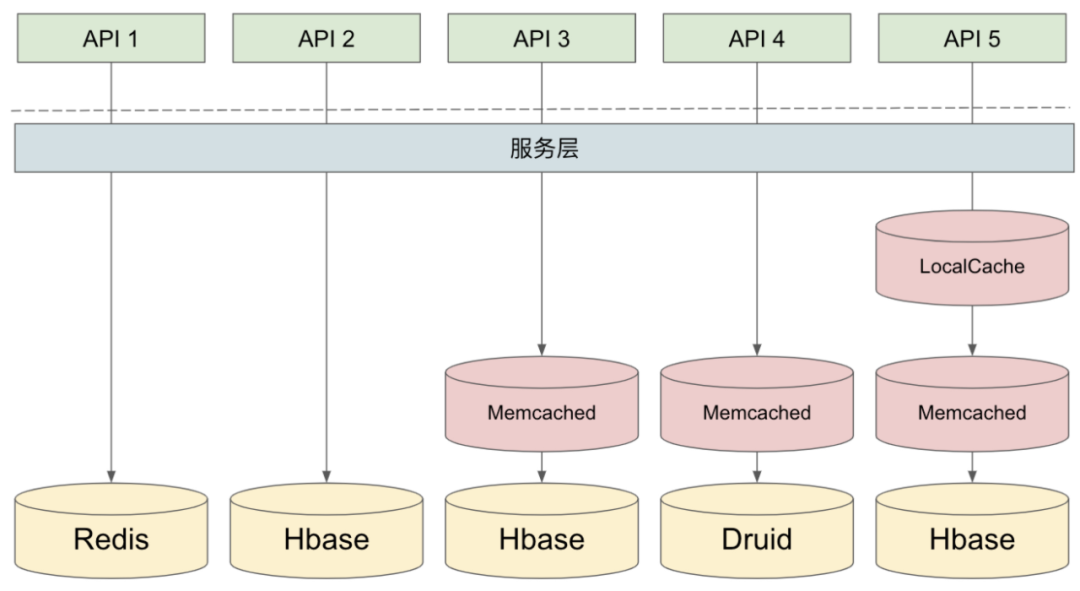
多级缓存
大数据服务化平台会使用 Redis、Hbase、Druid、Clickhouse 等方式存储所有数据,但是部分存储如Hbase速度可能较慢,针对热点数据需要使用额外的热点缓存来Cache数据。热点缓存是多级缓存,针对每个API接口,用户可自由搭配组合多级缓存、灵活设置缓存策略。此外,针对数据较大的API,还可配置数据压缩,通过多种压缩方式(如 ZSTD, SNAPPY, GZIP 等),可将数据量显著减少(部分API 甚至能减少90%的数据存储量)
关键技术四:高可用保障
服务可用性是微服务领域内的一大核心,服务的高可用通常需要组合多种手段来保障。快手数据服务化平台通过多种方式来达到高可用的目的,主要包括:
弹性服务框架
资源隔离
全链路监控
弹性服务框架
数据服务是部署在容器云环境,容器云是快手自研的弹性可伸缩的容器服务,部署在其中的RPC服务会注册到 KESS (快手自研服务注册与发现中心),供主调方去调用,如有离群坏点,会自动摘除。服务调用是基于 RPC,全链路都有监控,包括服务可用性、延迟、QPS、容器CPU、容器内存等情况。
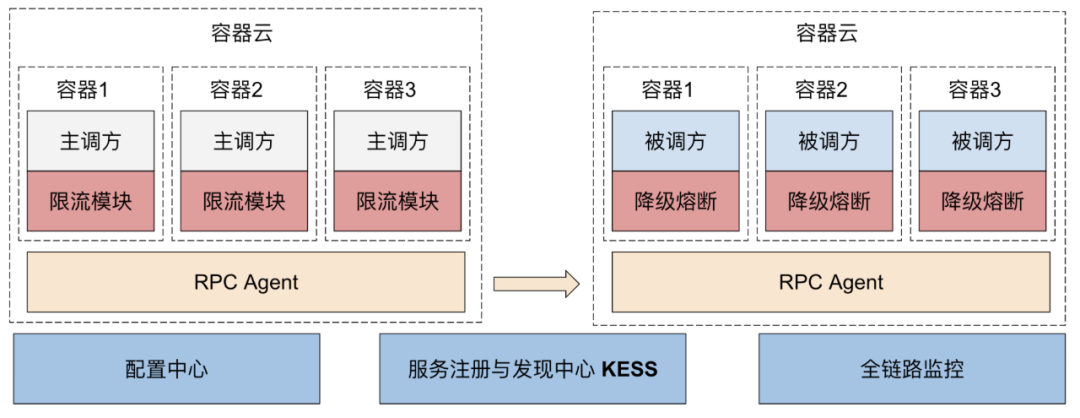
资源隔离
资源隔离是可用性保障的常见手段之一,通过隔离将意外故障等情况的影响面降低。不管是微服务,还是存储,我们都按照业务 + 优先级(高、中、低)粒度隔离部署,独立保障,业务之间互不影响、业务内不同级别也互不影响。同一业务线内可能有多个不同数据服务,通过混合部署,提高资源使用率。
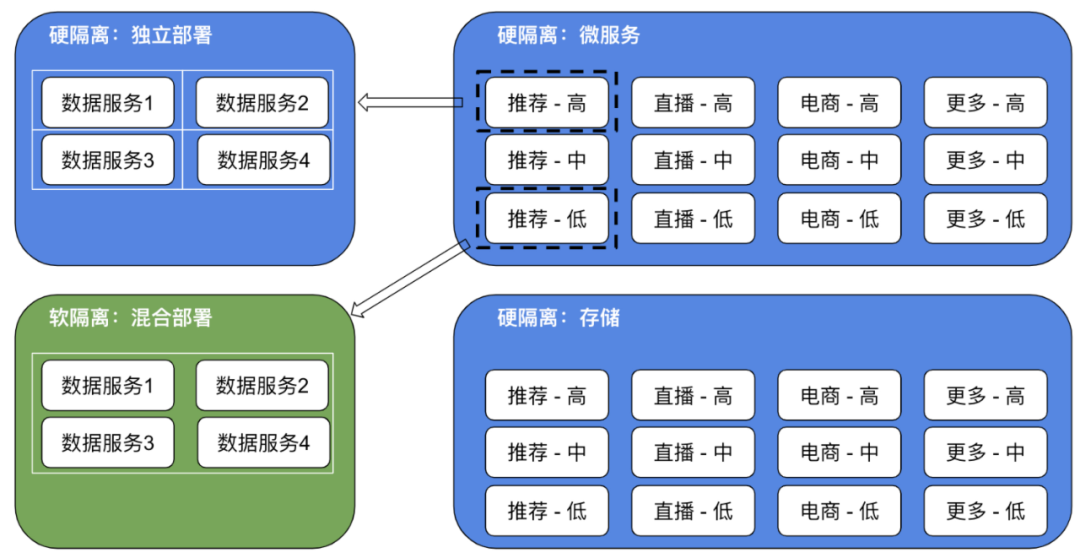
全链路监控
服务很难避免出现问题或者故障,一旦出现问题,及早发现及早介入是非常重要的。服务平台构建了全链路监控,包括:
数据同步:对数据资产同步至高速存储的过程进行监控,包括数据质量检测(过滤脏数据)、同步超时或者失败检测等
服务稳定性:构建一个独立的哨兵服务,来监测每个API的运行指标(如延迟、可用性等),客观的评估健康度
业务正确性:数据服务需要确保用户访问的数据内容和数据资产表内容是一致的,因此哨兵服务会从数据一致性层面去探查,确保每个API的数据一致性

总结和展望
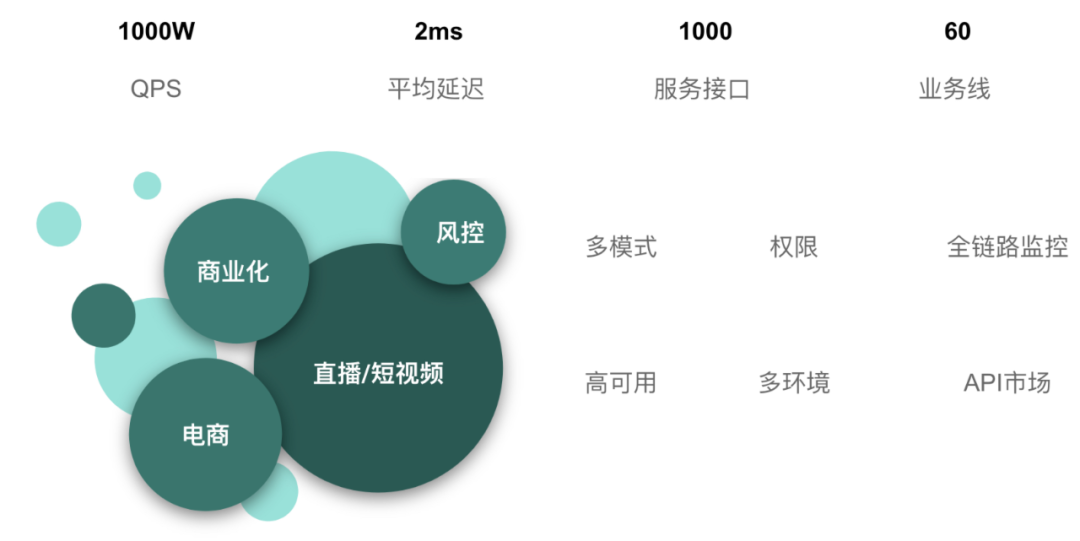
大数据服务化平台从2017年演化至今,已经支持多类应用场景,涵盖直播、短视频、电商、商业化等在线业务,生产者中台等准在线业务,运营系统等偏内部数据系统等,目前平台在线业务总 QPS 达到 1000W,平均延迟在毫秒级;对于准在线业务和内部数据系统,基于CH、Druid等多种数据引擎,支持多种灵活查询。数据服务平台支持了多种模式API,很好满足了多元化需求。此外数据服务平台也支持服务权限、API市场等丰富功能,进一步赋能业务。
大数据服务化平台未来进一步发展方向主要包括:
贴近业务需求:数据服务平台本身是为业务服务,通过赋能业务而对企业带来价值,业务本身在不断发展,未来也会有更多的需求出现,因此数据服务平台本身会不断抽象和沉淀出公共数据服务能力。
深耕数据资产:数据资产是数据服务之根本,如果没有完善的数据资产建设,上面就很难构建出结构化的统一的数据服务,针对数据资产有较多内容,包括资产注册和审核、资产地图、资产标签、资产管理、资产开放和服务。
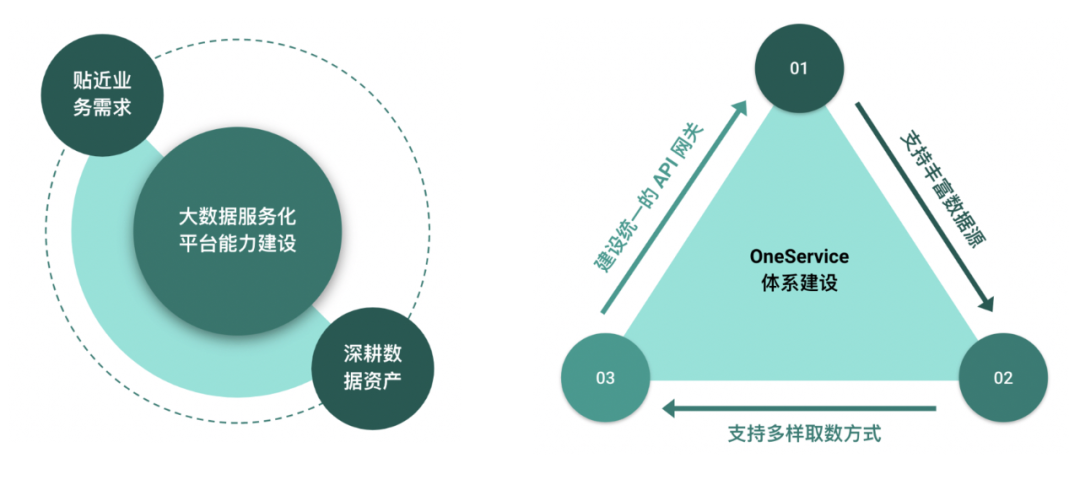
大数据服务平台的能力建设会朝着统一的 OneService 体系前进。主要包括三个方面:
支持丰富的数据源:包括大宽表、文本文件、机器学习模型(模型也是一种数据资产),来构建完善的数据服务。
支持多样取数方式:除了支持同步快速取数之外,还支持异步查询取数、推送结果、定时任务等多样化方式,以满足业务多种场景需求。
建设统一的API网关:集成权限管控、限流降级、流量管理等于一体,不仅平台创建的服务可以注册进API网关,用户自己开发的API也可注册进API网关,从而享受已有的基础网关能力,为业务提供数据服务能力。
文末再跟大家推荐个 Linux 命令行教程:《The Linux Command Line》,中文译名:《Linux 命令行大全》。

“图形用户界面让简单的任务更容易完成, 而命令行界面使完成复杂的任务成为可能”,这句话到今天,仍然很正确。
第一部分:命令行发展历史
第二部分:命令行的基本语言 Shell
第三部分:熟悉 Linux 的环境配置与文件处理
第四部分:命令行处理真实场景的任务
第五部分:学习 Shell 编程
如何获取?
1. 识别并关注公众号「下面的二维码」;
2. 在下面公众号后台回复关键字「命令行」。
👆长按上方二维码 2 秒 回复「命令行」即可获取资料