
分享一个CI/CD的自动部署想法
这里是Z哥的个人公众号
每周五11:45 按时送达
当然了,也会时不时加个餐~
我的第「221」篇原创敬上
最近工作中正好在设计一个方案,以支持 CD 环节的第一个部署节点可以完全自动部署,并且整个环节中尽量减少人为干预的节点。
之前也没有这块的实战经验,摸着石头过河,想了一个方案,在这里分享给大家,欢迎你一起讨论,相互学习。
我目前所在的公司 CI/CD 流程是这样的。
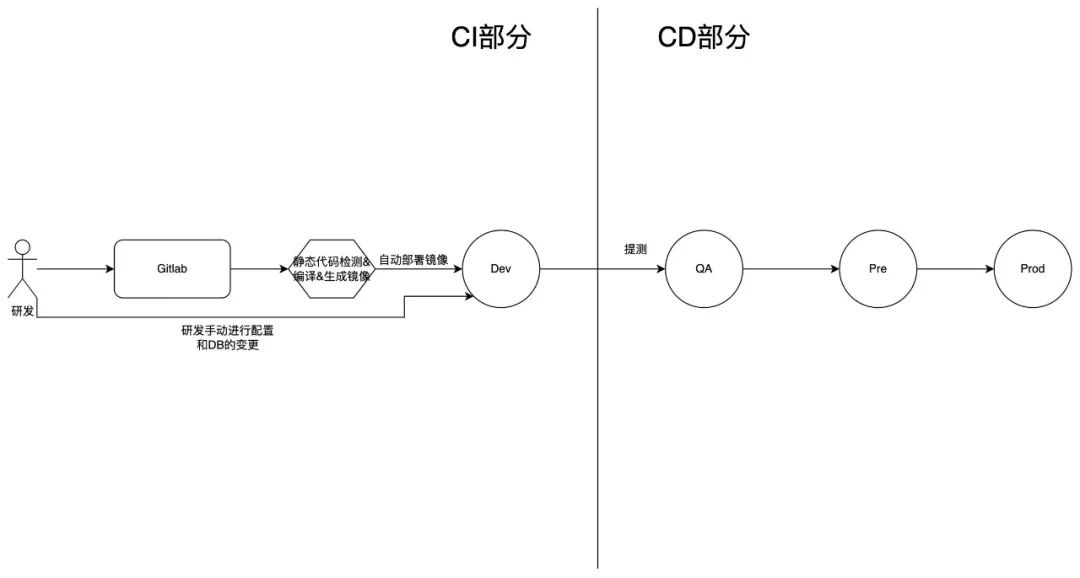
相信大多数公司的 CI/CD 流程和上图差别不大,基本上都是一个逐渐推进的直线节点。
在这个节点不断推进的过程中,数据库和配置的变更如何自动化,往往是面临的最大问题。
我这次要做的事就是在图中的 QA 环境之前增加一个 Alpha 环境,并且该环境的部署需要完全自动化进行。
那么自动部署过程中,我们有哪些原则可以被提炼出来,可以指导我们将这件事做成,并且往正确的方向持续进行呢?
我的理解是以下两点:
在自动部署之前,尽可能提前检测出部署后会导致该程序的上下游甚至整个系统不可用的风险。比如,通过静态代码检测。
部署之后,尽可能广地识别上下游以及整个系统的异常,及时回滚。比如,通过冒烟测试。
基于此原则,我构思的方案是这个样子:
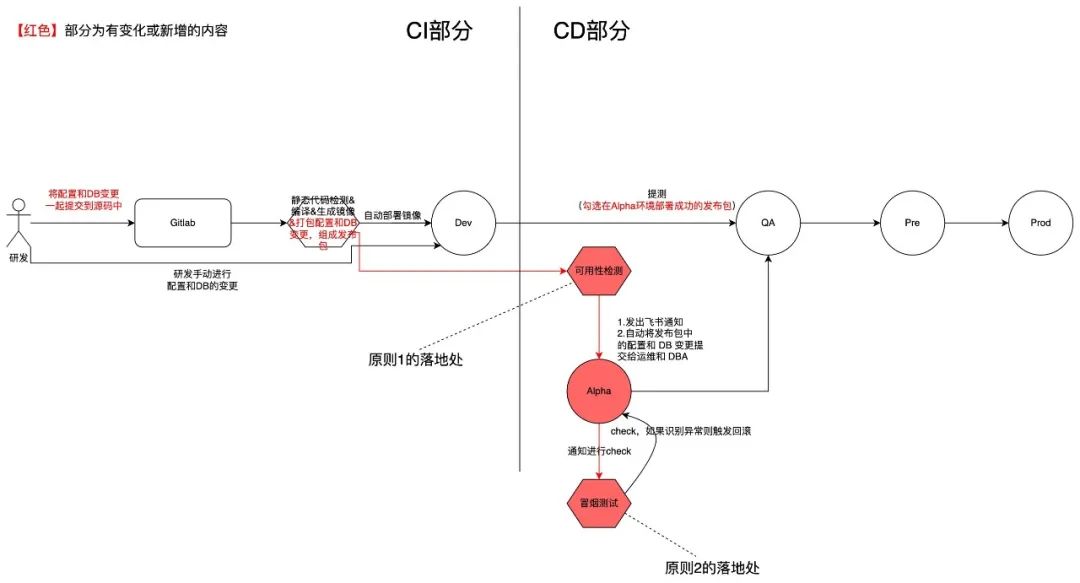
在具体实施层面,觉得需要做以下几件事,优先级从高到低排列:
配置和数据库变更文件的标准制定
能够识别配置和数据库变更文件的新增
能够将构建的镜像、变更文件打包到一起通知到运维与 DBA(条件允许的话,直接在系统层面打通)
在部署 Alpha 环境前的可用性检测。
每个程序提供健康检查接口,用于检测部署结果。
自动化的冒烟测试。用于检测 Alpha 环境的可用性,并触发回滚。
要做的细节工作还不有不少,但是核心工作就这么多。我们再来展开一下其中的每一件事。
/01 配置和数据库变更文件的标准制定/
首先,自动化的前提是先标准化,为了实现自动化,我们需要先将标准确定好。针对变更文件的标准,我大致想了下是这个样子。
01 文件存放目录定义
方案1:分别在 gitlab 仓库里定义 infra_changes_conf 、 infra_changes_db 、deploy_dependencies 文件夹。
【建议】方案2:在 gitlab 仓库里定义infra_changes文件夹,其中统一存放配置和 DB 变更、依赖描述文件,用不同的前缀区分。
02 文件名的定义
文件名格式为:[conf/db/depend]_JiraID_自增序号。Jira ID 是Jira上的故事、任务、Bug 的 ID。示例:
conf_XXXProject-2564_1.yaml
conf_XXXProject-2564_2.yaml
db_XXXProject-2564_1.yaml
db_XXXProject-2564_2.yaml
depend_XXXProject-2564_1.yaml
depend_XXXProject-2564_2.yaml
文件名最后的自增序号一般用于两种场景:
前一次构建并发布 Alpha 环境成功,但因功能需求,需要额外增加配置并发新版。
配置或者 db 变更需要区分程序运行前还是运行后。
03 文件内容的格式
conf_ 文件内容格式为 YAML 格式,结构如下:
runtime: before|after #程序运行前 or 运行后store_type: config_map|apollo|nacos|... #配置的存储类型service_name: xxxxxx #服务名remove_keys:key1key2.a.b #多级key 以 Properties 格式定义add_keys:-key1: value1: value2update_keys:-key1: value1: value2
同样的,db_ 文件内容格式为 YAML 格式,它支持两种模式,结构分别如下:
runtime: before|after #程序运行前or运行后db_type: mysql|mongodb|dynamodb|... #数据库的类型ddls:- sql1- sql2dmls:- sql1- sql2
depend_ 文件内容格式同样为 YAML 格式,结构如下
jira_ids:- XXXProject-2564- XXXProject-2564
相信你从文件格式中也能明白每一个属性的意义吧?
/02 识别配置和 DB 变更文件的新增/
聪明的你可能已经根据前面的《文件名的定义》部分内容猜到了,就是通过 Jira ID 来识别。具体操作方式是:
研发将配置、DB变更文件与代码一起提交到Gitlab 仓库。
如果检测到 Gitlab 的 commit 信息中带 Jira ID,那么会触发构建,并且将该镜像与 commit 中的 Jira ID 关联。
然后根据 Jira ID 去找 infra_changes 目录中与该 Jira ID 相关的变更文件,将它们与镜像放到一起。
/03 将构建的镜像、变更文件打包到一起通知到运维与 DBA /
如果运维和DBA已经有相关的自动化操作系统的话,可以直接在系统层面进行打通。否则的话,直接发出一个飞书或者钉钉消息就好了。
/04 部署 Alpha 环境前的可用性检测/
这个目前能想到的好像只有静态代码扫描了。
/05 每个程序提供健康检查接口,用于检测部署结果/
健康检查的作用在于,在部署完之后,通过调用每个系统的健康检查接口来快速得到某个程序的自检结果。毕竟只靠冒烟测试的话,整个效率会比较低。
具体的检查项:
比如数据库连接是否正常,所依赖的外部系统是否已经就绪等等。
/06 自动化的冒烟测试/
这个大家应该都知道,就不展开了。
大体上就这么多。等后面实际运用起来之后应该还会有一些迭代变化,到时候如果我觉得值得分享的话,再来和大家分享。
好了,总结一下。
这篇呢,Z 哥和你分享了我在目前团队中正在做的一个与 CI/CD 相关的事情。
为了确保整个自动化过程的尽可能稳定,我们需要基于两个原则不断思考和打磨整个过程。他们分别是:
在自动部署之前,尽可能提前检测出部署后会导致该程序的上下游甚至整个系统不可用的风险。比如,通过静态代码检测。
部署之后,尽可能广的识别上下游以及整个系统的异常,及时回滚。比如,通过冒烟测试。
在具体的实践过程中,主要有以下六个步骤:
配置和数据库变更文件的标准制定
能够识别配置和数据库变更文件的新增
能够将构建的镜像、变更文件打包到一起通知到运维与 DBA(条件允许的话,直接在系统层面打通)
在部署 Alpha 环境前的可用性检测。
每个程序提供健康检查接口,用于检测部署结果。
自动化的冒烟测试。用于检测 Alpha 环境的可用性,并触发回滚。
希望对你有所启发。
如果你有什么关于CI/CD的好想法,欢迎和我交流哈~
推荐阅读:
原创不易,如果你觉得这篇文章还不错,就「点赞」或者「在看」一下吧,鼓励我的创作 :)
也可以分享我的公众号名片给有需要的朋友们。
如果你有关于软件架构、分布式系统、产品、运营的困惑
可以试试点击「阅读原文」