百度商业大规模高性能全息日志检索技术揭秘
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
一、背景介绍
百度商业产品是服务于百度广告主用来投放广告而打造的产品生态。包含搜索推广、信息流推广、品牌等推广渠道以及观星盘、基木鱼等营销工具。
这一系列商业产品底层多为复杂的 Java 业务系统。复杂性主要体现在底层微服务子系统多、应用间调用关系复杂、基础组件依赖多。复杂性高就就意味着容易出问题,并且出了问题定位困难。但是这些产品出问题会直接导致广告主是否成功投放广告或者修改出价、创意等操作失败。
「如果有过在广告业务系统一线工作经历的同学,应该深知排查线上问题的枯燥和耗时」
如何在出问题第一时间定位问题,从而快速止损和修复问题,是商业产品系统中一个关键的技术痛点。为了解决这个痛点,百度商业平台部打造了大规模分布式微服务监控系统。公众号前文「百度商业大规模微服务业务监控系统-凤睛」已经讲述了凤睛如何通过自研无侵入探针以及高性能调用链存储系统为百度各业务线提供微服务系统性能指标、业务黄金指标、健康状况、监控告警等。
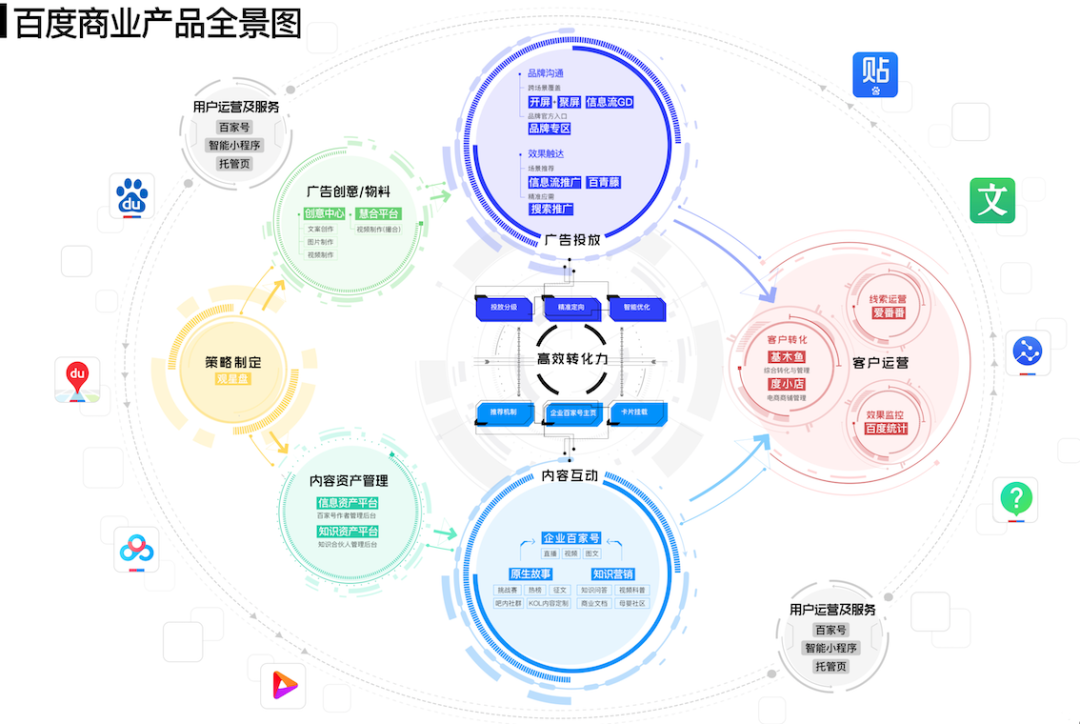
当收到线上报警时,值班同学需要首先找到出问题的根因模块,然后找出该模块出错的服务接口,最后定位到问题代码行栈。凤睛提供了调用链数据能够查看各个调用环节的状态码、耗时等,同时也收录了业务系统打印的错误堆栈。
大部分情况下,通过调用链以及系统打印的错误堆栈可以确定问题。但是,部分情况下问题与用户请求返回、业务访问缓存的情况等等比较特殊的场景有关。这需要通过系统打印的业务日志辅助定位。
凤睛并没有采集和存储业务日志,这与数据量有关,它部署在数千个微服务子系统上,运行在数万个容器中。每天采集的调用链数据条数达千亿,日存储数据在TB级别。而更加庞大、抽象程度最低的业务日志,预估单日总量接近PB级别,存储开销实在太大。
二、技术原理
传统做法:为了检索到单个请求相关的所有业务日志,日志会被采集走存储在 ES 里面提供检索功能。
诚然,Kibana+ES会提供更丰富灵活的检索功能,但是对于凤睛这种平台级别监控系统,基本不可行。ES的资源成本过于昂贵,整个平台单日日志数据接近 PB。如果全部存储在 ES 中,那么集群资源消耗以及维护成本都是很高的。并且,单纯定位线上问题,并不需要特别复杂的日志检索功能。
那么能否在少量资源消耗下,满足用户可以看到单个请求相关的完整调用链以及业务日志呢?
凤睛整个迭代过程就是不断利用有限资源来创造性解决实际问题的过程。而真正好的系统架构亦然如此,要「因地制宜」。在阿里巴巴钟华同学的《企业IT架构转型之道:阿里巴巴中台战略思想与架构实战》一书中,开篇就提到过「好的创新一定是基于企业现状因地制宜」。
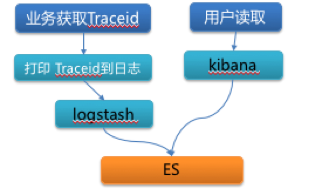
目前商业平台 Java 系统统一部署在企业级微服务托管平台 Jarvis上,同时凤睛探针能够无侵入式跟踪和采集系统的动作,这是我们的技术优势。能否利用这个优势,来规避掉存储资源有限的短板。探针既然能够记录系统在每个请求发生过程中的所有的动作;那么同样可以记录系统打印日志的动作。
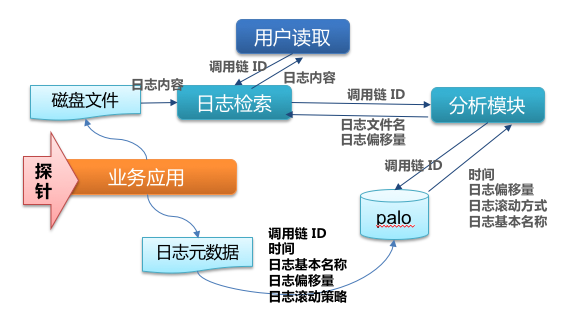
我们通过探针记录下请求相关的业务日志文件名、日志偏移量,并且存储数据库中。当用户在Jarvis管理端检索调用链相关的业务日志时,系统会先通过调用链 ID 去获取相关的虚拟容器地址、日志文件名、日志偏移量等元数据信息,然后通过这些元数据去具体的容器中取到完整的日志内容,最后展现给用户。
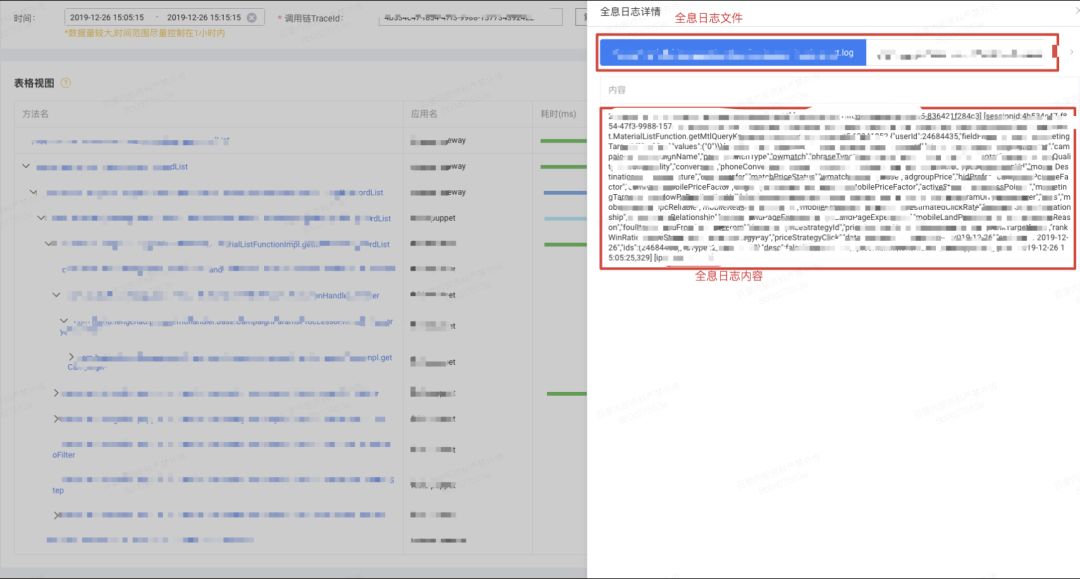
这样虽然我们只消耗少量的存储和计算资源,也可以轻松检索到海量调用链相关的业务日志。这个受限于日志在容器中的实际存储时间,但是线上问题很少需要借助远久历史日志来分析定位。绝大多数情况下借助当前日志就可以满足需求了。
「全息日志技术是凤睛自研技术,也申请了相关专利」
三、算法实现
全息日志技术设计中分为两个主要的部分:
日志元数据采集:拦截打印日志的前后操作,进行元数据采集。 元数据解析:解析元数据定位出日志文件当前位置以及日志所在文件的位置。
在通常情况下,一份日志消息可能打印到多个日志文件中,日志文件可能根据配置的滚动策略进行基于时间或者大小的滚动,不同的时间进行日志检索需要能够自动区分出日志当前所在的实际位置,用户不需要感知底层日志文件位置变化。
在设计和实现中关键问题的解决:
元数据采集的性能和准确性问题
为了保证元数据能够被准确的采集,需要基于凤睛探针拦截打印日志的方法。
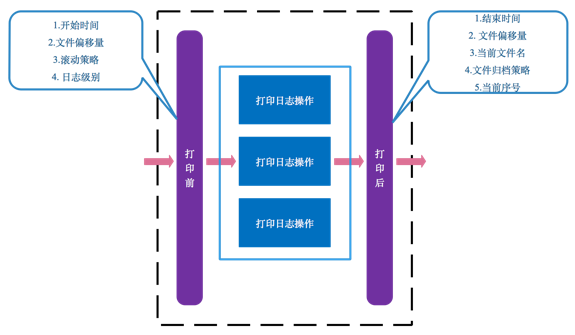
在原始打印日志操作之前插入字节码,记录开始时间、读文件标识符获取打印前文件偏移量、文件的滚动策略(包括文件最大大小、文件滚动时间等)、日志级别; 在原始打印日志操作之后插入字节码,记录结束时间、读文件标识符获取打印后文件偏移量、日志内容当前写入的文件、文件按滚动策略归档后策略、同名归档时归档序号等. 在采集文件偏移量时通过直接读取文件描述符而不是直接读文件内容来提高性能。同时,在日志打印内容里注入每次调用唯一的traceId做更精准的标注,其他数据的采集用来日志检索时解析使用。
元数据解析
用户发起日志检索时,使用算法解析出此时此刻日志内容所在位置。
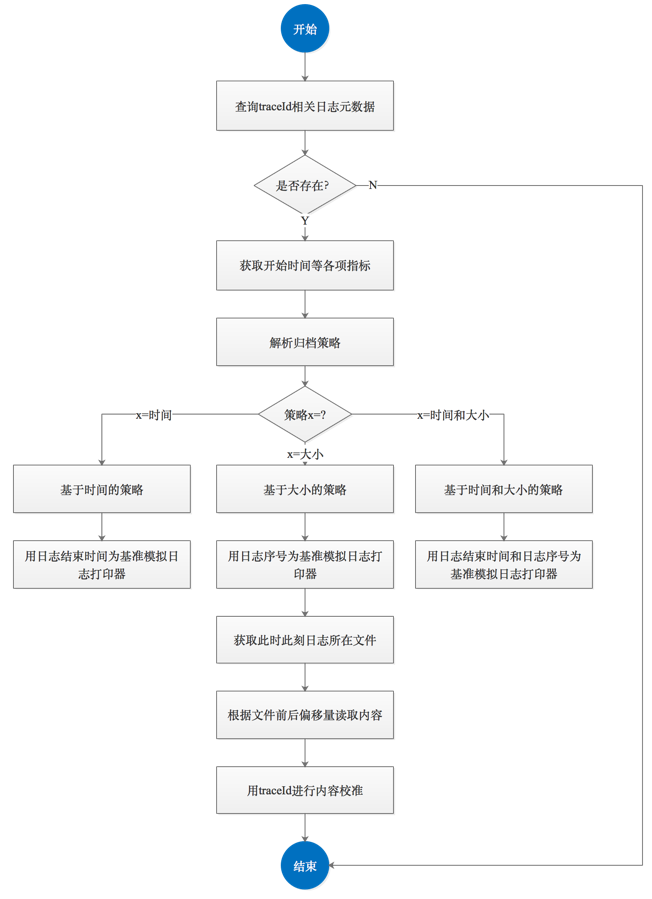
根据调用链traceId查询出与该traceId相同的所以日志元数据记录; 分别获取日志打印结束时间、日志打印时当前文件名、文件归档策略; 解析归档策略; 根据归档策略注入不同基准参数,模拟出一个日志打印器,以此获取到此时此刻文件位置; 根据文件位置,以及文件前后偏移量,读取出两个偏移量之前的日志内容; 用traceId进行内容校准.
四、结语
凤睛通过自研的全息日志技术能够帮助业务方快速检索到业务请求相关的完整调用链以及完整的业务日志。作为分布式追踪系统,我们也补齐了追踪领域最后一块短板。但是业务系统的复杂性,也决定了凤睛作为一个平台化的业务监控产品所面临的诸多挑战。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈