
阿里云二面:zookeeper一致性算法
上次跟学弟学妹们聊完了Spring相关的一些知识点,学弟学妹们还是挺开心的,但是上次有学弟在跟我留言,在出去面试的时候被面试官问了个一脸蒙逼急的问题:
zookeeper你用过吗?作为注册中心它是怎么如何保证CP的呢?
为了对的起学弟学妹们的信赖这次跟大家具体聊聊zookeeper中的一致性选举算法Paxos算法
什么是CAP?
CAP理论指的是在一个分布式系统中,不可能同时满足Consistency(一致性)、Availablity(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能满足其中的两项。
一致性(Consistency):数据在不同的副本之间数据是保持一致的,并且当执行数据更新之后,各个副本之间能然是处于一致的状态。
可用性(Availablity):系统提供的服务必须是处于一直可用的状态,针对每一次对系统的请求操作在设定的时间内,都能得到正常的result返回。
分区容错性(Partition tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非整个网络环境全部瘫痪了。
什么是三二原则?
对于分布式系统,在CAP原则中,P是一定要保证的,如果没有分区容错性那这个系统就太脆落了,但是并不能同时保证一致性或者可用性,在现在我们的分布式系统中,满足一致性,则必然会失去可用性,满足可用性,则必然失去一执性。所以CAP原则对一个分布式系统来说要么满足AP,要么满足CP,这就是三二原则。
Zookeeper与Eureka的区别?
Zookeeper遵循是的CP原则,即保证了一致性,失去了可用性,体现在当Leader宕机后,zk 集群会马上进行新的 Leader 的选举,但是选举的这个过程是处于瘫痪状态的。所以其不满足可用性。
Eureka遵循的是AP原则,即保证了高可用,失去了一执行。每台服务器之间都有心跳检测机制,而且每台服务器都能进行读写,通过心跳机制完成数据共享同步,所以当一台机器宕机之后,其他的机器可以正常工作,但是可能此时宕机的机器还没有进行数据共享同步,所以其不满足一致性。
言归正转,基础就跟大家聊到这里了,开始直接开始正文吧!!!
Paxos算法
Paxos 算法是莱斯利·兰伯特(Leslie Lamport)1990 年提出的一种基于消息传递的、具有高容错性的一致性算法。Google Chubby 的作者 Mike Burrows 说过,世上只有一种一致性算法, 那就是 Paxos,所有其他一致性算法都是 Paxos 算法的不完整版。
Paxos 算法是一种公认的晦涩难懂的算法,并且工程实现上也具有很大难度。
所以 Paxos算法主要用来解决我们的分布式系统中如何根据表决达成一致。
算法前置理解
首先需要理解的是算法中的三种角色
Proposer(提议者) Acceptor(决策者) Learners(群众)
一个提案的决策者(Acceptor)会存在多个,但在一个集群中提议者(Proposer)也是可能存在多个的,不同的提议者(Proposer)会提出不同的提案。
paxos算法特点:
没有提案被提出则不会有提案被选定。 每个提议者在提出提案时都会首先获取到一个具有全局唯一性的、递增的提案编号 N, 即在整个集群中是唯一的编号N,然后将该编号赋予其要提出的提案。(在zookeeper中就是zxid,由epoch 和xid组成) 每个表决者在 accept 某提案后,会将该提案的编号N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个编号最大的提案,其编号假设为 maxN。每个表决者仅会 accept 编号大于自己本地maxN 的提案。 在众多提案中最终只能有一个提案被选定。 一旦一个提案被选定,则其它服务器会主动同步(Learn)该提案到本地。
Paxos算法整个选举的过程可以分为两个阶段来理解。
阶段一
这个阶段主要是准备阶段发送提议
提议者(Proposer)准备提交一个编号为 N 的提议,于是其首先向所有表决者(Acceptor)发送 prepare(N)请求,用于试探集群是否支持该编号的提议。
每个决策者(Acceptor)中都保存着自己曾经 accept 过的提议中的最大编号 maxN。当一个表决者接收到其它主机发送来的 prepare(N)请求时,其会比较 N 与 maxN 的值。
若 N 小于 maxN,则说明该提议已过时,当前表决者采取不回应来拒绝该 prepare 请求
若N 大于maxN,则说明该提议是可以接受的,当前表决者会首先将该 N 记录下来, 并将其曾经已经 accept 的编号最大的提案 Proposal(myid,maxN,value)反馈给提议者, 以向提议者展示自己支持的提案意愿。其中第一个参数 myid 表示表决者 Acceptor 的标识 id,第二个参数表示其曾接受的提案的最大编号 maxN,第三个参数表示该提案的真正内容 value。
若当前表决者还未曾 accept 过任何提议(第一次初始化的时候),则会将Proposal(myid,null,null)反馈给提议者。
在当前阶段 N 不可能等于maxN。这是由 N 的生成机制决定的。要获得 N 的值, 其必定会在原来数值的基础上采用同步锁方式增一
阶段二
当前阶段要是真正的发送接收阶段又被称为Accept阶段
当提议者(Proposer)发出 prepare(N)后,若收到了超过半数的决策者(Accepter)的反馈, 那么该提议者就会将其真正的提案 Proposal(N,value)发送给所有的表决者。 当决策者(Acceptor)接收到提议者发送的 Proposal(N,value)提案后,会再次拿出自己曾经accept 过的提议中的最大编号 maxN,及曾经记录下的 prepare 的最大编号,让 N 与它们进行比较,若N 大等于于这两个编号,则当前表决者 accept 该提案,并反馈给提议者。若 N 小于这两个编号,则决策者采取不回应来拒绝该提议。 若提议者没有接收到超过半数的表决者的 accept 反馈,则重新进入 prepare 阶段,递增提案号,重新提出 prepare 请求。若提议者接收到的反馈数量超过了半数,则其会向外广播两类信息:
向曾 accept 其提案的表决者发送“可执行数据同步信号”,即让它们执行其曾接收到的提案 向未曾向其发送 accept 反馈的表决者发送“提案 + 可执行数据同步信号”,即让它们接受到该提案后马上执行。
看到这里可能很多学弟都是一脸懵逼,什么鬼?为了加深理解,让整个过程更加的透明,还是举例说明一下吧!!!
假设现在我们有三台主机服务器从中选取leader(也可以选择其他的更多的服务器,为了比较方便容易理解这里选少一点)。所以这三台主机它们就分别充当着提议者(Proposer)、决策者(Acceptor)、Learners(群众)三种角色。
所以假设现在开始模拟选举,三台服务分别开始获取N(具有全局唯一性的、递增的提案编号 N)的值,此时 serverOne(主机1) 就对应这个 ProposerOne(提议者1)、serverTwo(主机2)对应ProposerTwo(提议者2)、serverThree(主机3)对应ProposerThree(提议者3)。
为了整个流程比较简单清晰,过程中更好理解。他们的初始N值就特定的设置为 ServerOne(2)、ServerTwo(1)、ServerThree(3),所以他们都要发送给提议(Proposal)给决策者(Acceptor),让它们进行表决确定
名词解析
提议(Proposal):提议者向决策者发送的中间数据的包装简称提议。
同时每个 提议者(Proposer)向其中的两个决策者(Acceptor)发送提案消息。所以假设:
ProposerOne(提议者1)向 AcceptorOne(决策者1)和AcceptorTwo(决策者2)、
ProposerTwo(提议者2)向AcceptorTwo(决策者2)和AcceptorThree(决策者3)、
ProposerThree(提议者3)向AcceptorTwo(决策者2)和AcceptorThree(决策者3)、
发送提案消息。为了流程结构简单就向其中的2台发送提案,但是也是已经超过半票了,当然也可以多选几个主机,多发送提案,只是流程就复杂了一点不好理解了。注意点就是一定要超过半票。
那么整个图可以如下所示:
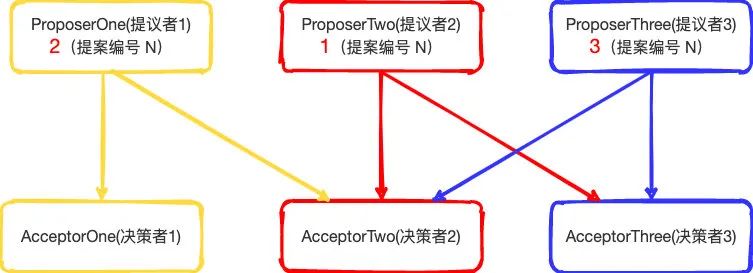
所以根据上面的图开始走第一阶段
按照上面我们假设的流程开始执行流程
ProposerOne(提议者1)向 AcceptorOne(决策者1)和AcceptorTwo(决策者2)
AcceptorOne(决策者1)和AcceptorTwo(决策者2)第一次收到ProposerOne(提议者1)的提议(Proposal),由于是第一次收到提议(Proposal),本地没有存储最大的N值,所以都会接受ProposerOne(提议者1)的提议。
所以AcceptorOne(决策者1)和AcceptorTwo(决策者2)都会提议返回给ProposerOne(提议者1)告知我赞同你的提议。
同时AcceptorOne(决策者1)和AcceptorTwo(决策者2)因为收到的当前的最大提议编号N为2,并且保存在本地,所以想接受到其他的N值小于2时则不会回复提议。
而ProposerOne(提议者1)已经收到超过半数返回,所以提议通过
此时 :
AcceptorOne(决策者1)本地 N值为2
AcceptorTwo(决策者2) 本地 N值为2
AcceptorThree(决策者3)本地 N值为null
ProposerTwo(提议者2)向AcceptorTwo(决策者2)和AcceptorThree(决策者3)
AcceptorTwo(决策者2)和AcceptorThree(决策者3)收到ProposerTwo(提议者2)的提议(Proposal)时。因为AcceptorTwo(决策者2)之前已经接受过ProposerOne(提议者1)的提议,所以本地的N值已经存储了2
当ProposerTwo(提议者2)的N值为1的时候,小于本地存的最大N值,所以不给予通过,也就不回复ProposerTwo(提议者2)
而AcceptorThree(决策者3)因为这是第一次收到提议,没有最大N值,所以同意提议(Proposal),返回当前提,更新本地N值。
最后ProposerTwo(提议者2)只收到AcceptorThree(决策者3)的同意反馈,没有超过半数选择,所以不给通过。
此时 :
AcceptorOne(决策者1)本地 N值为2
AcceptorTwo(决策者2) 本地 N值为2
AcceptorThree(决策者3)本地 N值为1
ProposerThree(提议者3)向AcceptorTwo(决策者2)和AcceptorThree(决策者3)
AcceptorTwo(决策者2)和AcceptorThree(决策者3)收到ProposerThree(提议者3)的提议(Proposal)时。因为
AcceptorTwo(决策者2)和AcceptorThree(决策者3)都已经都到过提议(Proposal),所以AcceptorTwo(决策者2)收到ProposerThree(提议者3)的提议时,本地N值2小于ProposerThree(提议者3)的N值3,所以通过提议
AcceptorThree(决策者3)因为本地之前收到最大的值为1,所以本次通过也通过提议,更新本次的N值为3
最后ProposerThree(提议者3)收到超过半数的同意反馈,所以通过。
此时 :
AcceptorOne(决策者1)本地 N值为2
AcceptorTwo(决策者2) 本地 N值为3
AcceptorThree(决策者3)本地 N值为3
由于之前ProposerTwo(提议者2)向AcceptorTwo(决策者2)和AcceptorThree(决策者3)发出提议时,没有超过半数投票。所以会从新获取最大N值(具有全局唯一性的、递增的提案编号 N),这个时候ProposerTwo(提议者2)本地获取的N值为4所以会再次发起一轮投票
AcceptorTwo(决策者2)和AcceptorThree(决策者3)再次收到ProposerTwo(提议者2)的提议(Proposal)时。AcceptorTwo(决策者2)和AcceptorThree(决策者3)本地存储的最大N值都小于现在最新的ProposerTwo(提议者2)的N值4,所以全部通过返回提议,更新本地N值
当ProposerTwo(提议者2)的N值为1的时候,小于本地存的最大N值,所以不给予通过,也就不回复ProposerTwo(提议者2)
最后ProposerTwo(提议者2)收到超过半数的同意反馈,所以通过。
此时 :
AcceptorOne(决策者1)本地 N值为2
AcceptorTwo(决策者2) 本地 N值为4
AcceptorThree(决策者3)本地 N值为4
到此第一阶段的工作就已经完成了,整个流程都是文字较多,看起需要多看几遍。同时我也给大家画了一个流程图如下:
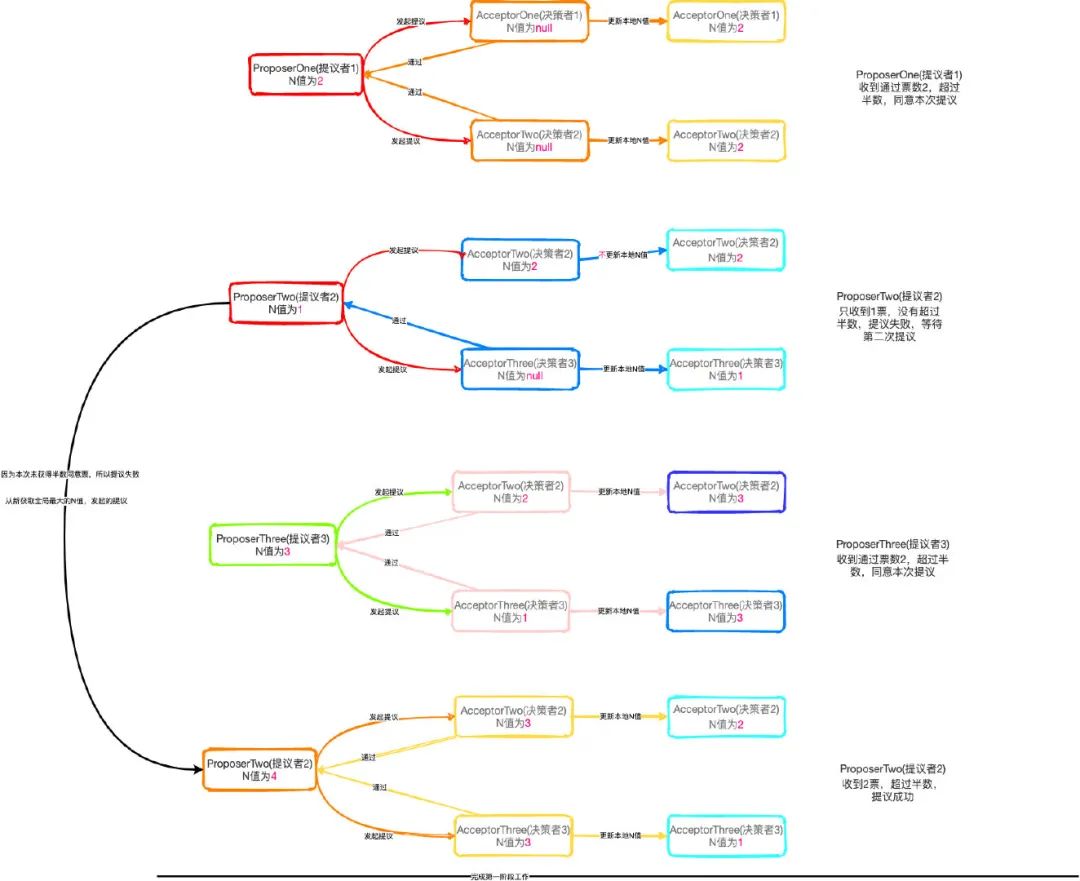
由于上面已经走完第一阶段,那么接下来肯定就是第二阶段的流程了
同时整体第二阶段可以分为两块来理解,第一块是正式提交提议,第二块是表决确定阶段
第一阶段执行完得到的结果:
Proposer
ProposerOne(提议者1) 本地N值为2 ProposerTwo(提议者2) 本地N值为4 ProposerThree(提议者3) 本地N值为3 Acceptor
AcceptorOne(决策者1) 本地N值为2 AcceptorTwo(决策者2) 本地N值为4 AcceptorThree(决策者3) 本地N值为4
第一块:
ProposerOne(提议者1)正式发出提议到AcceptorOne(决策者1)和AcceptorTwo(决策者2),通过第一阶段的结果可以知道只有AcceptorOne(决策者1)表决通过,AcceptorTwo(决策者2)不通过因为小于本地N值
ProposerTwo(提议者2)正式发出提议到AcceptorTwo(决策者2)和AcceptorThree(决策者3),同样的通过第一阶段的结果,可以知道两个决策者都通过,所以超过半数投票
ProposerThree(提议者3)正式发出提议到AcceptorTwo(决策者2)和AcceptorThree(决策者3),同样的通过第一阶段的结果,可以知道两个决策者都没有通过
第二块:
从上面的第一块结果来看,只有**ProposerTwo(提议者2)**得到半数同意,所以ProposerTwo(提议者2)立马就能成为leader。至此选举状态就结束,即ProposerTwo(提议者2)会发布广播给所有的learner,通知它们过来同步数据。当数据完成同步时,那个整个服务器的集群就能正常工作了。
总结
整个Paxos算法过程还是比较难理解,为了讲明白这里面的流程都是按最简单的例子来的。这里面也可以有更多的机器发起更多的提议。但是整个流程那就更难理解了。
理解Paxos算法需要按上面的两个阶段来理解。第一阶段是做什么,得到了什么结果,第二阶段又是基于第一阶段的结果执行怎样的一个选举流程,这个是大家需要思考的重点。
这里主要是跟大家分享的是Paxos算法这个选举过程,也有很多其他的优化版本比如 Fast Paxos、EPaxos等等。
Zookeeper
在zookeeper中的选举算法就是用的 Fast Paxos算法,为什么用Fast paxos?
Fast Paxos算法是Paxos的优化版本,解决了Paxos算法的活锁问题保证每次线程过来获取到唯一的N值。
ZAB(Zookeeper Atomic BroadCast)原子广播协议
ZAB其实就是上面算法的一种实现,所以Zookeeper也就是依赖ZAB来实现分布式数据的一致性的。
所以在zookeeper中,只有一台服务器机器作为leader机器,所以当客户端链接到机器的某一个节点时
当这个客户端提交的是读取数据请求,那么当前连接的机器节点,就会把自己保存的数据返回出去。
当这个客户端提交的是写数据请求时,首先会看当前连接的节点是不是leader节点,如果不是leader节点则会转发出去到leader机器的节点上,由leader机器写入,然后广播出去通知其他的节点过来同步数据
在ZAB中的三类角色
Leader:ZK集群的老大,唯一的一个可以进行写数据的机器。 Follower:ZK集群的具有一定职位的干活人。只能进行数据的读取,当老大(leader)机器挂了之后可以参与选举投票的机器。 Observe:最小的干活小弟,只能进行数据读取,就算老大(leader)机器挂了,跟他一毛关系没有,不能参与选举投票的机器。
在ZAB中的三个重点数据
Zxid:是zookeeper中的事务ID,总长度为64位的长度的Long类型数据。其中有两部分构成前32位是 epoch后32位是xidEpoch:每一个leader都会有一个这个值,表示当前leader获取到的最大N值,可以理解为“年代” Xid:事务ID,表示当前zookeeper集群当前提交的事物ID是多少(watch机制),方便选举的过程后不会出现事务重复执行或者遗漏等一些特殊情况。
zookeeper中的一些知识点就分享到这里了,因为这里面还有很多很多东西,比如Session 、Znode、Watcher机制 、ACL、三种状态模式 还zookeeper怎么实现分布式事务锁等等。没有办法一次性跟大家聊完。
这次主要还是想让学弟学妹了解清楚Zookeeper中的一致性的算法是怎么保证。
结尾
针对面试来说能完全的跟面试官讲明白这个一致性算法,那你就已经走在前面了。整个过程还是比较复杂的,需要自己不断的多看多画图理解。
在这个互联内卷的时代,只有懂得比别人多才能走的比别人远。
最后希望我的学弟学妹们都能有一个好的校招结果!!!