
推荐一款小众且好用的 Python 爬虫库
👆本文转载自公众号【AirPython】,详情可以点击上方卡片,关注该公众号,获取更多好文推荐。

1. 前言
今天给大家推荐一款小众轻量级的爬虫库:MechanicalSoup
MechanicalSoup,也是一款爬虫神器!它使用纯 Python 开发,底层基于 Beautiful Soup 和 Requests,实现网页自动化及数据爬取
项目地址:
https://github.com/MechanicalSoup/MechanicalSoup
2. 安装及常见用法
首先安装依赖库
# 安装依赖库
pip3 install MechanicalSoup
常见操作如下:
2-1 实例化浏览器对象
使用 mechanicalsoup 内置的 StatefulBrowser() 方法可以实例化一个浏览器对象
import mechanicalsoup
# 实例化浏览器对象
browser = mechanicalsoup.StatefulBrowser(user_agent='MechanicalSoup')
PS:实例化的同时,参数可以执行 User Agent 及数据解析器,默认解析器为 lxml
2-2 打开网站及返回值
使用浏览器实例对象的 open(url) 即可以打开一个网页,返回值类型为:requests.models.Response
# 打开一个网站
result = browser.open("http://httpbin.org/")
print(result)
# 返回值类型:requests.models.Response
print(type(result))
通过返回值可以发现,使用浏览器对象打开网站相当于使用 requests 库对网站进行了一次请求
2-3 网页元素及当前 URL
使用浏览器对象的「url」属性可以获取当前页面的 URL 地址;浏览器的「 page 」属性用于获取页面的所有网页元素内容
由于 MechanicalSoup 底层基于 BS4,因此 BS4 的语法都适用于 MechanicalSoup
# 当前网页URL地址
url = browser.url
print(url)
# 查看网页的内容
page_content = browser.page
print(page_content)
2-4 表单操作
浏览器对象内置的 select_form(selector) 方法用于获取当前页面的 Form 表单元素
如果当前网页只有一个 Form 表单,则参数可以省略
# 获取当前网页中某个表单元素
# 利用action来过滤
browser.select_form('form[action="/post"]')
# 如果网页只有一个Form表单,参数可以省略
browser.select_form()
form.print_summary() 用于将表单内全部元素打印出来
form = browser.select_form()
# 打印当前选定表单内部全部元素
form.print_summary()
至于表单内的 input 普通输入框、单选框 radio、复选框 checkbox
# 1、普通输入框
# 通过input的name属性直接设置值,模拟输入
browser["norm_input"] = "普通输入框的值"
# 2、单元框radio
# 通过name属性值,选择某一个value值
# <input name="size" type="radio" value="small"/>
# <input name="size" type="radio" value="medium"/>
# <input name="size" type="radio" value="large"/>
browser["size"] = "medium"
# 3、复选框checkbox
# 通过name属性值,选择某几个值
# <input name="topping" type="checkbox" value="bacon"/>
# <input name="topping" type="checkbox" value="cheese"/>
# <input name="topping" type="checkbox" value="onion"/>
# <input name="topping" type="checkbox" value="mushroom"/>
browser["topping"] = ("bacon", "cheese")
浏览器对象的 submit_selected(btnName) 方法用于提交表单
需要注意的是,提交表单后的返回值类型为:requests.models.Response
# 提交表单(模拟单击“提交”按钮)
response = browser.submit_selected()
print("结果为:",response.text)
# 结果类型:requests.models.Response
print(type(response))
2-5 调试利器
浏览器对象 browser 提供了一个方法:launch_browser()
用于启动一个真实的 Web 浏览器,可视化展示当前网页的状态,在自动化操作过程中非常直观有用
PS:它不会真实打开网页,而是创建一个包含页面内容的临时页面,并将浏览器指向这个文件
更多功能可以参考:
https://mechanicalsoup.readthedocs.io/en/stable/tutorial.html
3. 实战一下
我们以「 微信文章搜索,爬取文章标题及链接地址 」为例
3-1 打开目标网站,并指定随机 UA
由于很多网站对 User Agent 做了反爬,因此这里随机生成了一个 UA,并设置进去
PS:从 MechanicalSoup 源码会发现,UA 相当于设置到 Requests 的请求头中
import mechanicalsoup
from faker import Factory
home_url = 'https://weixin.sogou.com/'
# 实例化一个浏览器对象
# user_agent:指定UA
f = Factory.create()
ua = f.user_agent()
browser = mechanicalsoup.StatefulBrowser(user_agent=ua)
# 打开目标网站
result = browser.open(home_url)3-2 表单提交,搜索一次
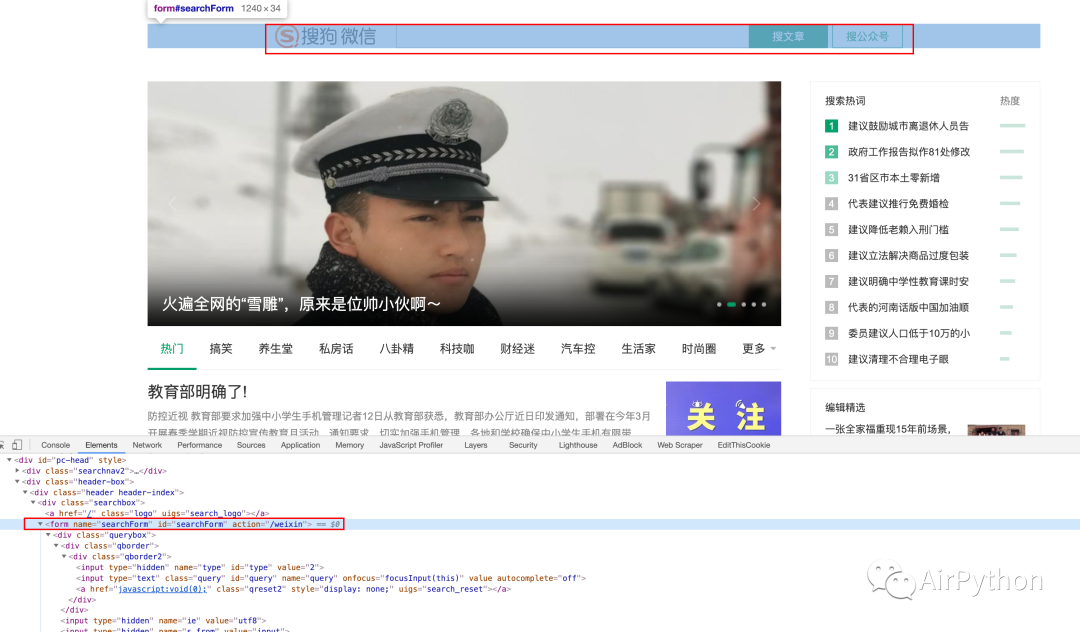
使用浏览器对象获取网页中的表单元素,然后给表单中的 input 输入框设置值,最后模拟表单提交
# 获取表单元素
browser.select_form()
# 打印表单内所有元素信息
# browser.form.print_summary()
# 根据name属性,填充内容
browser["query"] = "Python"
# 提交
response = browser.submit_selected()3-3 数据爬取
数据爬取的部分很简单,语法与 BS4 类似,这里就不展示说明了
search_results = browser.get_current_page().select('.news-list li .txt-box')
print('搜索结果为:', len(search_results))
# 网页数据爬取
for result in search_results:
# a标签
element_a = result.select('a')[0]
# 获取href值
# 注意:这里的地址经过调转才是真实的文章地址
href = "https://mp.weixin.qq.com" + element_a.attrs['href']
text = element_a.text
print("标题:", text)
print("地址:", href)
# 关闭浏览器对象
browser.close()
3-4 反反爬
MechanicalSoup 除了设置 UA,还可以通过浏览器对象的「 session.proxies 」设置代理 IP
# 代理ip
proxies = {
'https': 'https_ip',
'http': 'http_ip'
}
# 设置代理ip
browser.session.proxies = proxies4. 最后
文中结合微信文章搜索实例,使用 MechanicalSoup 完成了一次自动化及爬虫操作
相比 Selenium,最大的区别是 Selenium 可以和 JS 进行交互;而 MechanicalSoup 不行
但是对于一些简单的自动化场景,MechanicalSoup 是一种简单、轻量级的解决方案
· 推荐阅读 ·