
深度学习,打通工业高性能部署最后一公里
在深度学习产业落地过程中,我们经常能听到一种说法——模型部署是打通AI应用的最后一公里!想要走通这一公里,看似简单,但是真正实践起来却困难重重:显卡利用率低、内存溢出、多线程调度奔溃、TensorRT加速算子不支持等等问题一直是深度学习模型最后部署的老大难问题。
在工业制造环境中,Windows系统有着广泛的应用。为了更好的帮助工业用户解决落地最后的一公里问题,飞桨联合产业用户,基于Windows系统,提供了工业级的部署Demo,支持图像分类、目标检测、实例分割和语义分割模型的部署,并提供了一键的TensorRT加速方式,极大的提升了部署的效率,同时支持多线程推理的方式,满足了用户多视频输入预测的需求!
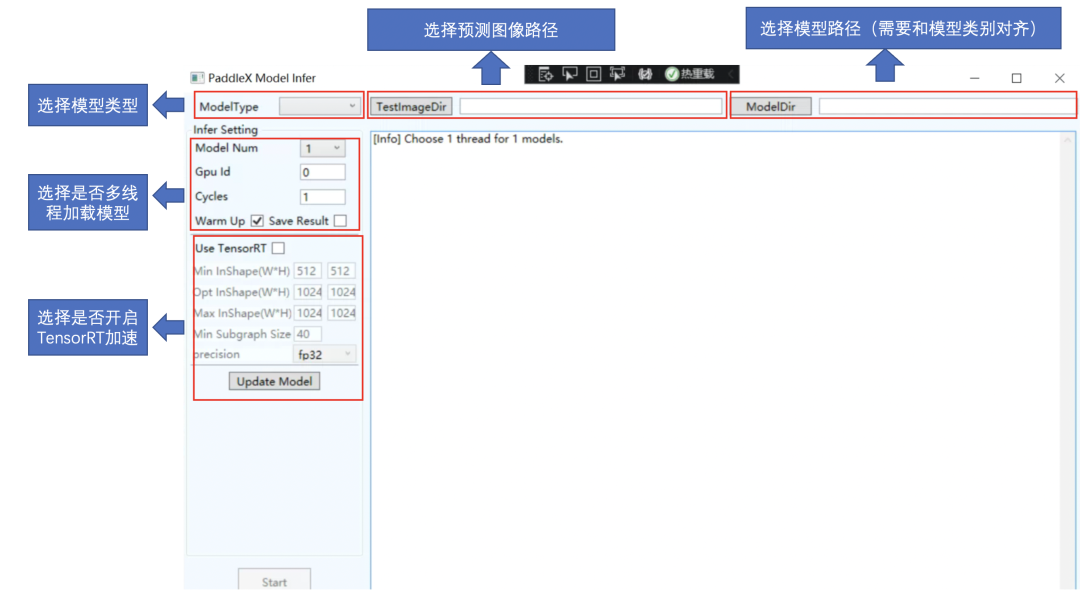
图1 部署开发示例说明
部署Demo地址,欢迎大家star收藏。
https://github.com/PaddlePaddle/PaddleX/tree/develop/deploy/cpp/docs/csharp_deploy

支持多种类别模型部署
满足多种场景需求
为了更好的满足用户多种视觉任务场景,部署Demo基于PaddleX的Deployment模块进行二次开发,不仅仅支持对PaddleX自身训练的模型进行推理,同时支持PaddleClas、PaddleDetection、PaddleSeg视觉开发套件的模型,满足多种场景需求。
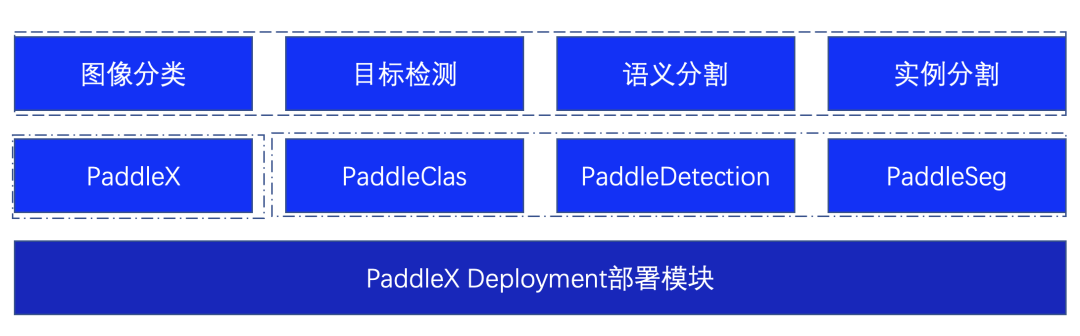
图2 部署Demo支持模型说明
一键TensorRT加速
部署效率显著提升
NVIDIA TensorRT 是一个高性能的深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量。在部署Demo中集成了TensorRT预测库,用户只需一键启动,即可进行高性能的部署。

图3 部署Demo性能对比说明
为了更好的帮助用户了解在工业制造场景部署的问题,飞桨邀请产业用户现场coding,一步步带着大家现场演示如何搭建部署开发示例,如何更高性能的应用在自己的产业落地中。
扫码报名直播课,加入技术交流群
更多精彩抢先看