
SpringBoot + Apache tika 轻松实现各种文档内容解析
点击关注公众号,Java干货 及时送达
本文演示在spring boot 中引入tika的方式解析文档。如下:
引入依赖
在spring boot 项目中引入如下依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-bom</artifactId>
<version>2.8.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
</dependency>
创建配置
将tika-config.xml文件放在resources目录下。tika-config.xml文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<encodingDetectors>
<encodingDetector class="org.apache.tika.parser.html.HtmlEncodingDetector">
<params>
<param name="markLimit" type="int">64000</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.UniversalEncodingDetector">
<params>
<param name="markLimit" type="int">64001</param>
</params>
</encodingDetector>
<encodingDetector class="org.apache.tika.parser.txt.Icu4jEncodingDetector">
<params>
<param name="markLimit" type="int">64002</param>
</params>
</encodingDetector>
</encodingDetectors>
</properties>
创建配置类MyTikaConfig
import java.io.IOException;
import java.io.InputStream;
import org.apache.tika.Tika;
import org.apache.tika.config.TikaConfig;
import org.apache.tika.detect.Detector;
import org.apache.tika.exception.TikaException;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.Parser;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import org.xml.sax.SAXException;
/**
* tika配置类
*/
@Configuration
public class MyTikaConfig {
@Autowired
private ResourceLoader resourceLoader;
@Bean
public Tika tika() throws TikaException, IOException, SAXException {
Resource resource = resourceLoader.getResource("classpath:tika-config.xml");
InputStream inputStream = resource.getInputStream();
TikaConfig config = new TikaConfig(inputStream);
Detector detector = config.getDetector();
Parser autoDetectParser = new AutoDetectParser(config);
return new Tika(detector, autoDetectParser);
}
}
Tika类中提供了文芳detect、translate和parse功能, 在项目中通过注入TIka, 就可以使用了
在项目使用
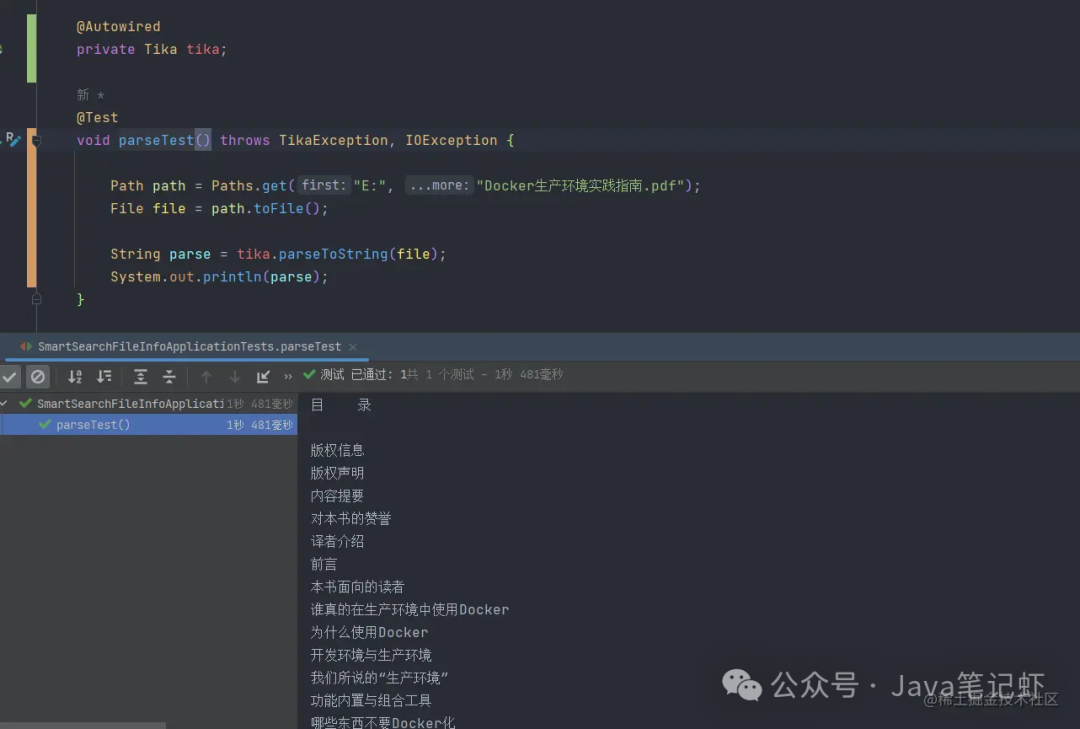
配置完成后在项目中可以通过注入TIka即可完成文档的解析。如下图所示:

往 期 推 荐
4、为什么国外JetBrains做 IDE 就可以养活自己,国内不行?区别在哪?
5、中国程序员独立开发9年、最受欢迎的开源Redis客户端 被Redis公司收购(文末送书)
点 分 享
点 收 藏
点 点 赞
点在看
评论