
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
最近CV界最大的新闻就是transformer的应用,这其中最火的就是Facebook提出的基于transformer的目标检测模型DETR(https://arxiv.org/abs/2005.12872)。目前,港中文维护的MMDetection库发布了最新的V2.7版本,在新版本中支持DETR模型:
其实transformer提出已久,但是主要在NLP领域,而且基于transformer的模型如BERT也彻底革新了NLP领域。所以,我们也期待transformer能够同样给CV领域带来惊喜,毕竟CNN统治CV领域太长时间了,是时候需要加点新鲜料(虽然是NLP用过的料)。transformer的论文名是
Attention Is All You Need,其实从名字中就知道了transformer的核心组件是attention,关于transformer的解读文章太大了,这里不做详细介绍,这里简单说一下transformer为啥可以应用在CV上。其实transformer主要适合处理的数据输入是a set of objects,就是一坨东西然后attention。对于文本的句子来说,其实是一个word序列,而对于图像来说,其实就是一堆像素点,其实这都在
a set of objects的范围内,另外transformer采用位置嵌入(positional encoding)来解决objects间的位置关系,所以无论是句子的word顺序还是像素点的空间位置都可以解决。具体到目标检测问题上,因为detection的输出更是
a set of objects,这简直不能和transformer更契合了:
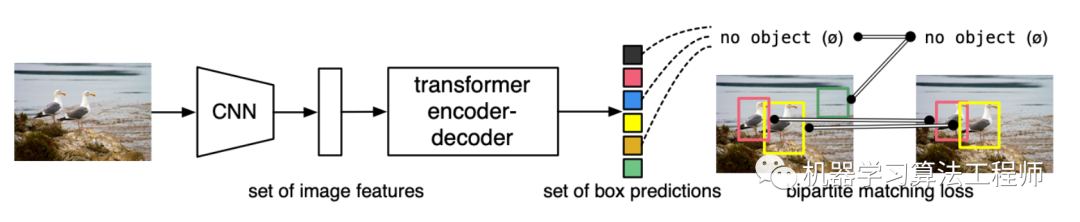
不过令大家失望的是,transformer带给CV虽然是新的视角,但是性能上谈不上超越。对于DETR来说,也存在一些问题,不如收敛慢训练时间长,而且对小目标检测不太好,不过也有一些新的工作开始做了改进:
Deformable DETR: Deformable Transformers for End-to-End Object Detection (https://arxiv.org/abs/2010.04159)
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals (https://arxiv.org/abs/2011.12450)
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers (https://arxiv.org/abs/2011.09094)
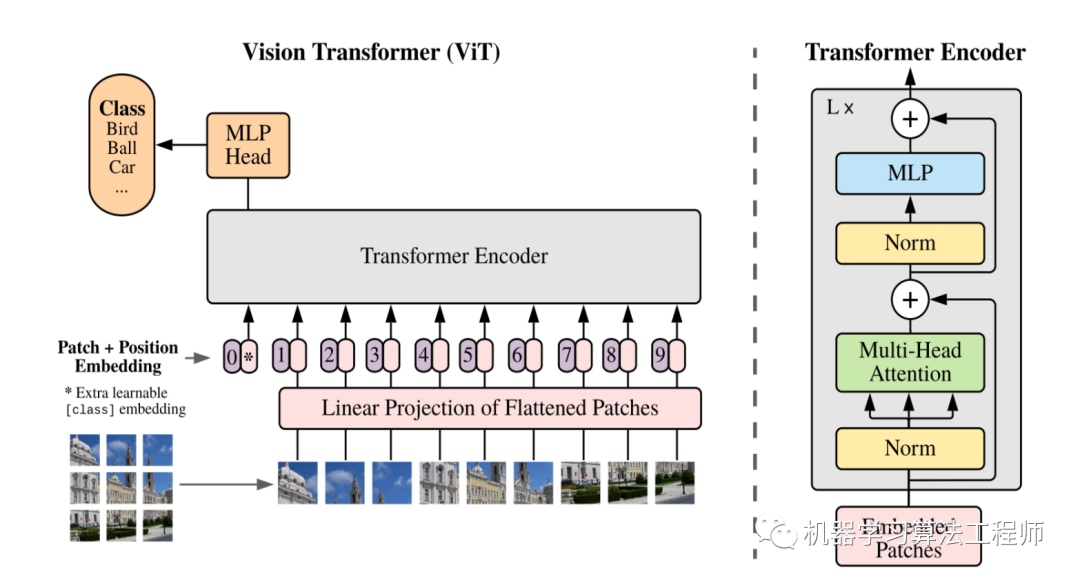
我们也期待transformer能给检测问题带来更多惊喜,另外transformer也已经成功应用在图像分类问题上,如ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale:
检测和分类都有了,基于transformer的分割还远么 ,期待ing...
,期待ing...
另外值得期待的一件事是,MMDetection库已经有了YOLOv4的分支(https://github.com/open-mmlab/mmdetection/tree/yolov4),这意味不远的明天你可以用上mmdet版本的YOLOv4模型:
@DETECTORS.register_module()class YOLOV4(SingleStageDetector):def __init__(self,backbone,neck,bbox_head,train_cfg=None,test_cfg=None,pretrained=None):super(YOLOV4, self).__init__(backbone, neck, bbox_head, train_cfg,test_cfg, pretrained)
推荐阅读
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
