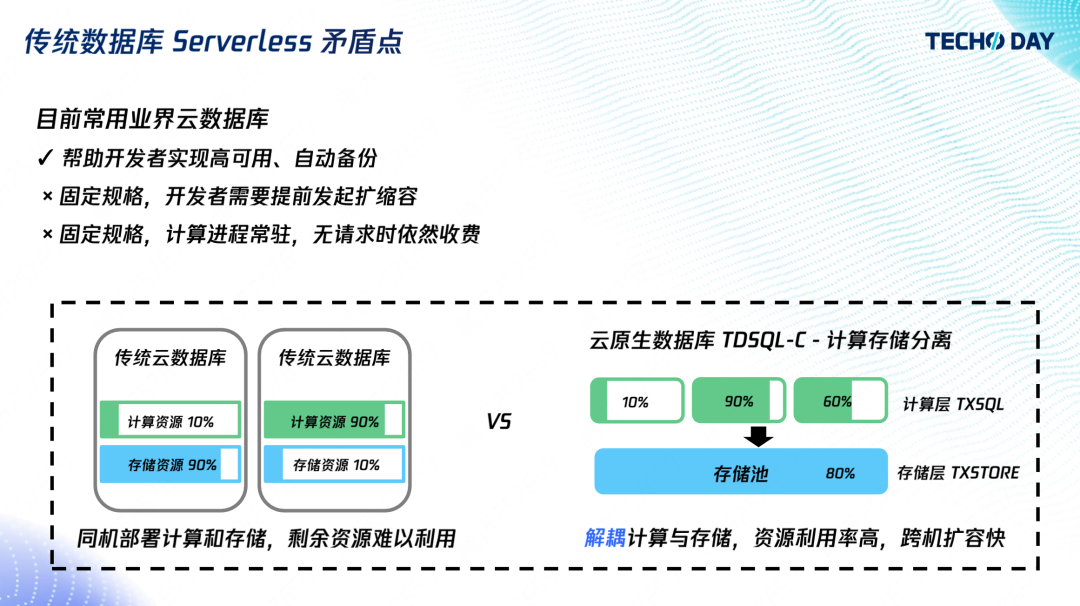
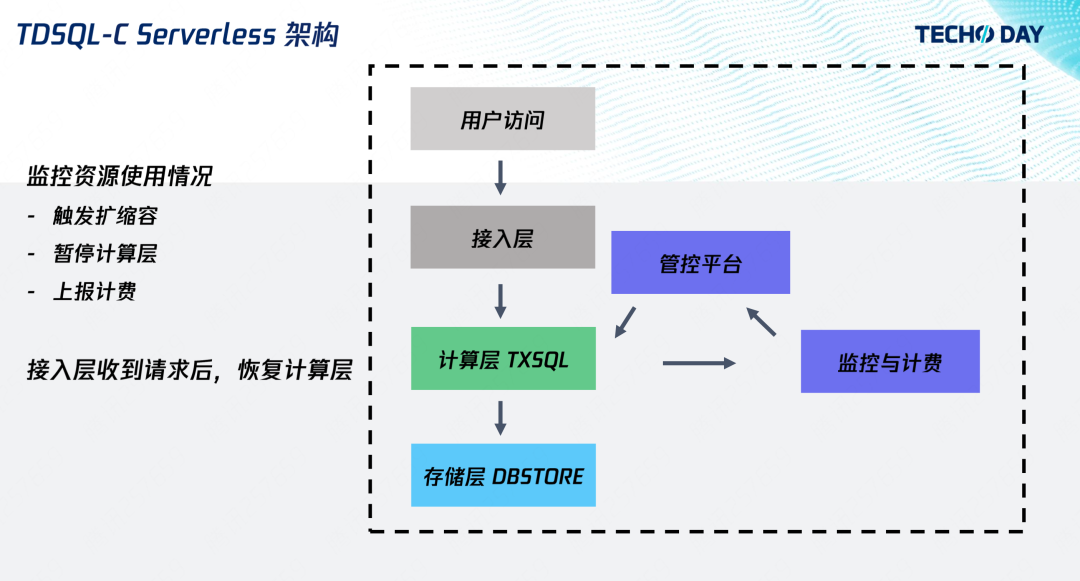
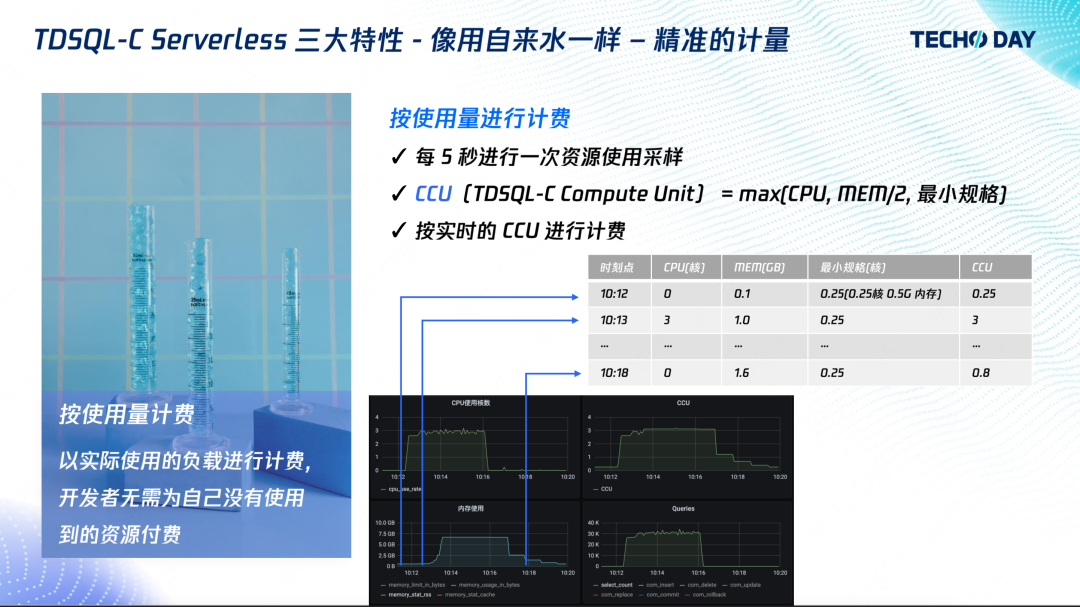
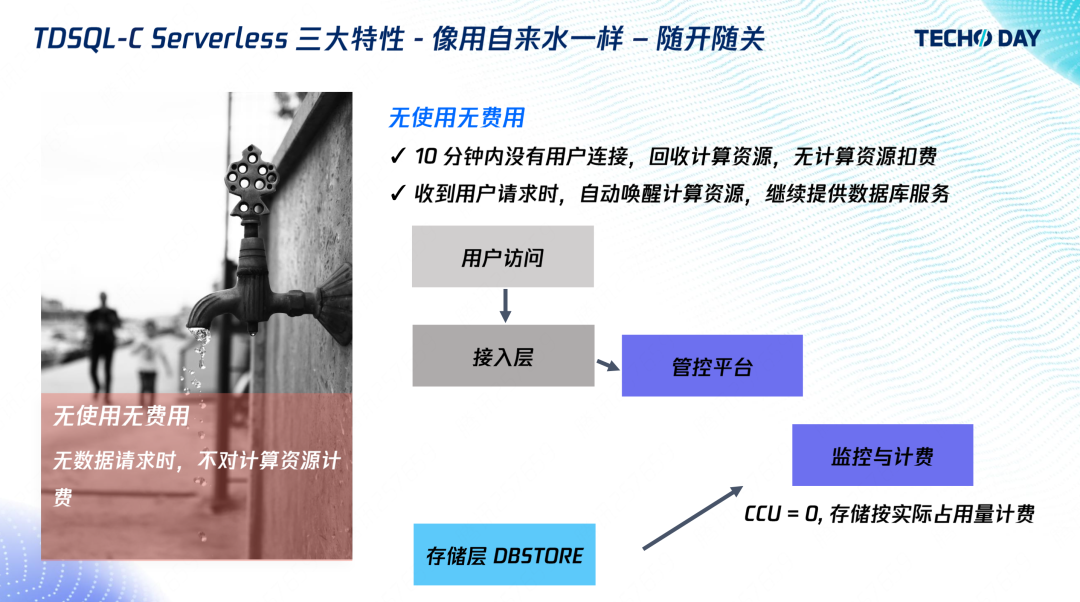
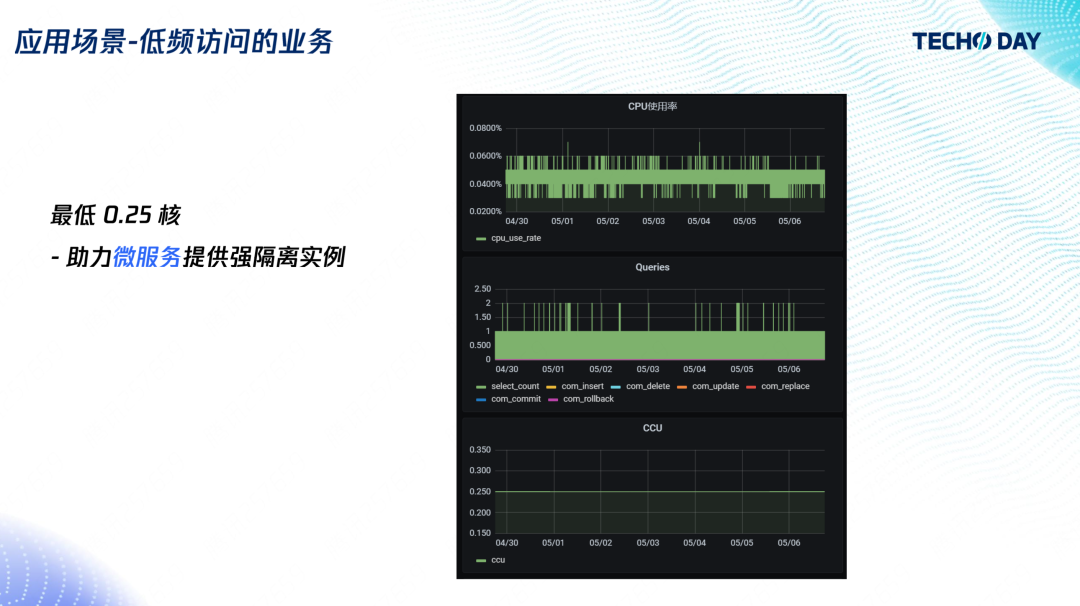
如何像用自来水一样使用数据库?腾讯云数据库关注共 4098字,需浏览 9分钟 ·2022-08-02 10:40 “如果说中小企业是一片片沿溪而耕的农田,那么我们的愿景就是建一座大坝来管理好上游的水资源,来灌溉下游企业。”腾讯云数据库高级工程师杨珏吉说这是他投身数据库领域的初衷。初创企业、中小企业在数据库层面的最大需求就是低成本。助力企业降本增效是腾讯云数据库一直在努力的方向,尤其在疫情冲击下的经济社会中,更是一份社会责任。在技术上深研,突破极致弹性,让客户像使用自来水一样的使用数据库,用多少、怎么用由客户决定,计费由使用量决定,这是杨珏吉及其团队给出的答案。TDSQL-C Serverless 数据库通过使用计算存储分离架构,实现自动扩缩容、按使用量计费、无使用无计费功能,从而实现大幅降低成本,下面将详细介绍功能实现背后的架构原理及应用场景。产品特点Serverless 分为 FaaS 和 BaaS,其中 FaaS 是函数即服务,也就是我们熟悉的云函数,可以理解成是云主机的一种抽象,免去了复杂的运维,帮助开发者自动扩缩容,实现服务的高可用,并按使用量计费。BaaS 是后端即服务,比如对象存储,它也免去了开发者的文件存储管理的负担,能提供足够的弹性能力,实现按照使用量计费,所以它也满足 Serverless 的要求。目前云数据库的售卖方式还是与云主机类似,开发者需要购买一个固定规格的云数据库,比如CPU 4 核内存 8G,即使开发者没有 SQL 请求,也将按照 4 核 8G 进行计费。业界场景的云数据库,确实帮助开发者实现了高可用和自动备份,减少了运维负担,但开发者需要提前预测业务请求量,并发起扩缩容,也无法在没有使用的时候不收费。传统云数据库同机部署计算和存储,内核进程直接写本地数据文件。当一台机器的存储使用已经接近 90%,即使整机存量实例的计算资源负载再低,也无法再分配新实例了。在这种情况下,该机器上存量实例的用户,虽然没有使用计算资源,CPU 内存都是 0,也依然要承担此机器计算资源的费用。反过来也一样,计算使用 90%,而存储使用量较少,也将导致剩余存储无法再售卖。按实际用量付费的问题本质是按实际用量分配资源。所以云数据库如果要迈向 Serverless 这个目标,要做的就是计算存储分离。计算存储分离的优势很多,比如存储空间和写带宽能突破单机上限,更强的容灾能力等等,本文重点讲解资源分配弹性灵活的特点。计算存储分离能使计算和存储解耦,任意计算节点能访问任务的存储节点。计算和存储维护各自的资源池,分别最大化、最灵活地进行资源分配。存储层按存放的数据量收费,计算层按真正的负载收费。另一方面,传统云数据库扩缩容需要搬迁数据到另一台物理设备,所以耗时长。而计算存储分离架构,计算层扩缩容不需要搬迁存储层的数据,直接分配计算层资源即可,秒级完成扩缩容。在计算存储分离之上,TDSQL-C 完成了 Serverless 产品功能的设计,让我们来看看具体是怎么做的。架构设计上图是开发者访问的全链路,应用程序通过接入层访问计算层,计算层从存储层返回数据。我们的 Serverless 形态是利用监控计算层实现的。通过监控,我们对计算资源进行自动扩缩容,并对该时刻所消耗的资源进行计费。当发现没有请求时,监控服务就会触发计算资源的回收,并通知接入层。用户再次访问时,接入层则会唤醒实例,再次提供访问。从客户角度总结起来就是三大特点:自动扩缩容:根据业务负载扩缩容实例,开发者无需预测负载并提前扩容资源;按使用量计费:以实际使用的负载进行计费,开发者无需为自己没有使用到的资源付费;无使用无费用:无数据请求时,不对计算资源计费。1. 自动扩缩容自动扩缩容的目标是让客户可以像使用自来水那样使用数据库,既可以一滴一滴,也可以像瀑布一样倾泻地用。开发者在购买一个 Serverless 实例时,需要指定扩缩容的范围,也就是最小和最大规格。比如开发者购买了一个最小 1 核 2G 最大 2 核 4G 的实例。我们对 CPU 和内存限制到最大规格,也就是说 CPU 和内存不存在扩容的时间,而 Buffer Pool 根据 CPU 负载定时调整。这是一个我们最开始考虑的方案,也是比较业界常见的扩缩容方案。上图纵轴表示 CPU,横轴表示内存(Mem),矩形框代表资源限制。实例闲时,就限制实例的规格为 1 核 2G,负载来临时,CPU 迅速打满,监控发现后,再触发扩容,扩成 2 核 4G,其中缓存也是 BP 大小也相应增加,可以看到在扩容发生之前,用户的 CPU 使用是受到限制的,限制的时间取决于触发扩容的阈值。我们后来采用的方案则是一开始就限制到最大规格,负载来临时,可以一下子使用到更多的资源,然后根据 CPU 的使用量来触发缓存大小的更新。在这个方案下用户使用数据库可以无感知进行 CPU 扩容,并且也不会因为链接突增导致实例 OOM。2. 按使用量计费使用量计费的目标是秒级别的计费粒度,以及任意单位的资源规格,比如用到 0.7 核,就按 0.7 核收费,而不是不足 1 核算 1 核。我们的监控室每 5 秒采集一次,采集结果统一使用 CCU(TDSQL-C Compute Unit)作为统一的算力单位,其计算方法为 CPU、内存的1/2以及最小规格三者取最大值。以上图为例,闲时以最小规格 0.25 CCU 计费,负载来临时以 CPU 进行收费,即为 3;当负载结束时,内存还在释放,为内存的1/2 ,也就是 0.8。3. 无使用无计费问题来了,大家可能觉得闲时按最小 0.25 CCU 计费也还是多了,于是我们推出无使用无费用的功能。10 分钟没有收到用户连接,就将回收计算节点,转为暂停的实例。暂停的实例收到用户请求后,启动计算节点,恢复为运行中的实例。我们通过监控计算的连接数,没有连接则向管控发起暂停。暂停后,我们回收了计算层所有资源,不再对计算资源收费,仅对存储资源进行收费。接入层收到用户请求后,管控则会启动实例,提供给用户访问。这当中比较重要的是恢复时间,也就是冷启动时间。在恢复时间上,我们做了相当多的优化,包括找持久化的日志位点以及 BP 和事务系统的初始化。目前,恢复时间能做到仅需2秒。有的读者可能会感兴趣计算存储分离的架构细节,接下来简要分享一下架构细节。在计算层,我们使用的是的 TXSQL,完全兼容 MySQL 协议,能够复用社区的 bugfix 和特性。主从复制使用 redo 复制,优点是延迟低。redo 日志不落在本地,而是发送给存储层。在存储层,我们使用的是云硬盘的 HiStore 存储平台,保障了数据安全、GB 级别的备份回档、以及性能与成本的多种存储选择方案,我们在 HiStore 中加入数据库的逻辑,实现日志回放以及算子下推。大家如果不熟悉数据库也不要被这个这些名词吓到,我们对外其实就是提供的是与 MySQL 一致的数据库服务,区别是内部我们做了计算存储分离,分离之后计算层的资源可以更自由、灵活地分配。应用场景应用场景是广大开发者比较关心的,接下来给大家分享六类场景的实际应用。1. 慢查询当开发者的 SQL 优化得不够好,或者偶尔需要全表扫描分析数据时,就会出现慢查询,与慢查询相伴的往往是 CPU 使用率高(因为扫描的数据比较多)。这也是用户能切实感知到的,从上图的监控中可以看到慢查询与 CPU 是正相关的。如果用户购买一个比较大的固定规格的实例,那么将承担额外的成本;如果购买的是小规格实例,那么在慢查询到来时用户的 CPU 会被占满,进而影响业务。使用Serverless 数据库就不用担心这个问题,大部分时间Serverless 数据库以低 CCU 进行付费,慢查询来临的时候可以立刻用到额外的 CPU,所以整体上也只是影响慢查询时刻的计费。2. 定时任务与慢查询类似,有相当多的业务都有定时处理逻辑,包括定时清理旧数据、定时生成前一天的报表等。上图可以看到,用户在每天 0 点会跑非常多的请求,但平时大部分时间是一个低负载。用户使用了 Serverless 数据库之后,也不用去对规格和费用做权衡了,和上一个例子一样,用多少就计费多少。3. 归档数据库如果长时间不用数据库,就不用对 CPU 和内存进行收费。这类通常见于一些档案数据库、机器学习的样本数据库、个人家庭的历史传感器数据库等,不会经常使用,而是偶尔访问的状态。这类数据的常见的做法是直接存在 COS 里,需要的时候去下载。而Serverless 数据库有一个很大的优点就是需要的时候立刻能够提供索引,且拥有强大的分析功能,开发者不需要自己去写代码就能搜索到需要的数据。4. 低频访问的业务对于平均每天的访问量小于 10 次的低频访问业务,例如个人博客、垂直社区论坛、微信小程序,我们与云函数、云开发、微信云托管有深入合作,能实现访问结束后就停止计费。5. 开发测试环境上图可以看到在一周时间内,用户在晚上、周末都没有访问和使用。用户通过 TDSQL-C Serverless 数据库的自动暂停功能,节省了大量研发测试成本。6. 微服务场景随着微服务越来越流行,每个单独的服务负责的功能也越来越小,随之对应的是微服务后端的数据库的负载也会变小。一种做法是多个微服务共用一个大的数据库,但这会带来相互影响的问题。所以,Serverless 数据库提供小规格的数据库实例,来保证微服务之间的隔离性。总结与展望TDSQL-C Serverless 补充了数据库领域中 Serverless 的空白。在自动扩缩容上,可以使 CPU 瞬间用到最大规格,按使用量计费上能够按 CPU 实时的使用量进行计费,不使用不计费上冷启动时间是 2 秒,目前在 Serverless 数据库中是绝对领先的。未来我们也会在冷启动上做进一步的优化,以及帮助客户进一步降低使用成本。﹀﹀﹀-- 更多精彩 --腾讯云原生数据库TDSQL-C入选信通院《云原生产品目录》新一代云原生数据库畅想↓↓点击阅读原文,了解更多优惠 浏览 71点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 cym1102-sqlHelper像 MongoDB 一样使用 SQL 数据库本项目是基于spring-data-jdbc的orm,支持sqlite、mysql、postgresql三种数据库,主要特点是像mongodb一样使用sql数据库。sqlHelper为 mongoHe如何像黑客一样优雅的使用命令行Python技术0【译】像大佬一样使用 Google大海我来了0【译】像大佬一样使用 Google前端杂货铺0牛逼!像使用Activity一样使用Fragment刘望舒0【工具】像大佬一样使用 Google前端杂货铺0像 Keras 一样优雅地使用 pytorch-lightningPython与算法之美0像Excel一样使用SQL进行数据分析SQL数据库开发0如何像算法工程师一样,看待这个世界?数据派THU0韭菜如何像Redis一样抗住压力Java3y0点赞 评论 收藏 分享 手机扫一扫分享分享 举报














 下载APP
下载APP