
从零开始搭建公司后台技术栈,这套架构绝了...
AI全套:Python3+TensorFlow打造人脸识别智能小程序
最新人工智能资料-Google工程师亲授 Tensorflow-入门到进阶
黑马头条项目 - Java Springboot2.0(视频、资料、代码和讲义)14天完整版
转自 : http://ju.outofmemory.cn/entry/351897 前言
图 1
有点眼晕,以下只是我们会用到的一些语言的合集,而且只是语言层面的一部分,就整个后台技术栈来说,这只是一个开始,从语言开始,还有很多很多的内容。今天要说的后台是大后台的概念,放在服务器上的东西都属于后台的东西,比如使用的框架,语言,数据库,服务,操作系统等等。
整个后台技术栈我的理解包括 4 个层面的内容:
结合以上的的 4 个层面的内容,整个后台技术栈的结构如图 2 所示:
以上的这些内容都需要我们从零开始搭建,在创业公司,没有大公司那些完善的基础设施,需要我们从开源界,从云服务商甚至有些需要自己去组合,去拼装,去开发一个适合自己的组件或系统以达成我们的目标。咱们一个个系统和组件的做选型,最终形成我们的后台技术栈。
各系统组件选型
1、项目管理/Bug管理/问题管理
项目管理软件是整个业务的需求,问题,流程等等的集中地,大家的跨部门沟通协同大多依赖于项目管理工具。有一些 SaaS 的项目管理服务可以使用,但是很多时间不满足需求,此时我们可以选择一些开源的项目,这些项目本身有一定的定制能力,有丰富的插件可以使用,一般的创业公司需求基本上都能得到满足,常用的项目如下:
Redmine:用 Ruby 开发的,有较多的插件可以使用,能自定义字段,集成了项目管理,Bug 问题跟踪,WIKI 等功能,不过好多插件 N 年没有更新了; Phabricator:用 PHP 开发的,Facebook 之前的内部工具,开发这工具的哥们离职后自己搞了一个公司专门做这个软件,集成了代码托管, Code Review,任务管理,文档管理,问题跟踪等功能,强烈推荐较敏捷的团队使用; Jira:用 Java 开发的,有用户故事,task 拆分,燃尽图等等,可以做项目管理,也可以应用于跨部门沟通场景,较强大; 悟空 CRM :这个不是项目管理,这个是客户管理,之所以在这里提出来,是因为在 To B 的创业公司里面,往往是以客户为核心来做事情的,可以将项目管理和问题跟进的在悟空 CRM 上面来做,他的开源版本已经基本实现了 CR< 的核心 功能,还带有一个任务管理功能,用于问题跟进,不过用这个的话,还是需要另一个项目管理的软件协助,顺便说一嘴,这个系统的代码写得很难维护,只能适用于客户规模小(1万以内)时。 2、DNS
DNS 是一个很通用的服务,创业公司基本上选择一个合适的云厂商就行了,国内主要是两家:
在国外还是选择亚马逊吧,阿里的 DNS 服务只有在日本和美国有节点,东南亚最近才开始部点, DNSPod 也只有美国和日本,像一些出海的企业,其选择的云服务基本都是亚马逊。
如果是线上产品,DNS 强烈建议用付费版,阿里的那几十块钱的付费版基本可以满足需求。如果还需要一些按省份或按区域调试的逻辑,则需要加钱,一年也就几百块,省钱省力。
3、LB(负载均衡)
LB(负载均衡)是一个通用服务,一般云厂商的 LB 服务基本都会如下功能:
支持四层协议请求(包括 TCP、UDP 协议);
支持七层协议请求(包括 HTTP、HTTPS 协议);
集中化的证书管理系统支持 HTTPS 协议;
健康检查;
如果你线上的服务机器都是用的云服务,并且是在同一个云服务商的话,可以直接使用云服务商提供的 LB 服务,如阿里云的 SLB,腾讯云的 CLB,亚马逊的 ELB 等等。如果是自建机房基本都是 LVS + Nginx。
4、CDN
CDN 现在已经是一个很红很红的市场,基本上只能挣一些辛苦钱,都是贴着成本在卖。国内以网宿为龙头,他们家占据整个国内市场份额的 40% 以上,后面就是腾讯,阿里。网宿有很大一部分是因为直播的兴起而崛起。
国内出海的 CDN 厂商,更多的是为国内的出海企业服务,三家大一点的 CDN 服务商里面也就网宿的节点多一些,但是也多不了多少。阿里和腾讯还处于前期阶段,仅少部分国家有节点。
5、RPC 框架
维基百科对 RPC 的定义是:远程过程调用(Remote Procedure Call,RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。
通俗来讲,一个完整的 RPC 调用过程,就是 Server 端实现了一个函数,客户端使用 RPC 框架提供的接口,调用这个函数的实现,并获取返回值的过程。
业界 RPC 框架大致分为两大流派,一种侧重跨语言调用,另一种是偏重服务治理。
Hprose(High Performance Remote Object Service Engine)是一个 MIT 开源许可的新型轻量级跨语言跨平台的面向对象的高性能远程动态通讯中间件。
服务治理型的 RPC 框架的特点是功能丰富,提供高性能的远程调用、服务发现及服务治理能力,适用于大型服务的服务解耦及服务治理,对于特定语言(Java)的项目可以实现透明化接入。缺点是语言耦合度较高,跨语言支持难度较大。国内常见的冶理型 RPC 框架如下:
6、名字发现/服务发现
名字发现和服务发现分为两种模式,一个是客户端发现模式,一种是服务端发现模式。
框架中常用的服务发现是客户端发现模式。
所谓服务端发现模式是指客户端通过一个负载均衡器向服务发送请求,负载均衡器查询服务注册表并把请求路由到一台可用的服务实例上。现在常用的负载均衡器都是此类模式,常用于微服务中。
所有的名字发现和服务发现都要依赖于一个可用性非常高的服务注册表,业界常用的服务注册表有如下三个:
etcd,一个高可用、分布式、一致性、key-value 方式的存储,被用在分享配置和服务发现中。两个著名的项目使用了它:Kubernetes 和 Cloud Foundry。 Consul,一个发现和配置服务的工具,为客户端注册和发现服务提供了API,Consul还可以通过执行健康检查决定服务的可用性。 Apache ZooKeeper,是一个广泛使用、高性能的针对分布式应用的协调服务。Apache ZooKeeper 本来是 Hadoop 的子工程,现在已经是顶级工程了。
除此之外也可以自己实现服务实现,或者用 Redis 也行,只是需要自己实现高可用性。
7、关系数据库
关系数据库分为两种,一种是传统关系数据,如 Oracle,MySQL,Maria,DB2,PostgreSQL 等等,另一种是 NewSQL,即至少要满足以下五点的新型关系数据库:
传统关系数据库用得最多的是 MySQL,成熟,稳定,一些基本的需求都能满足,在一定数据量级之前基本单机传统数据库都可以搞定,而且现在较多的开源系统都是基于 MySQL,开箱即用,再加上主从同步和前端缓存,百万 pv 的应用都可以搞定了。不过 CentOS 7 已经放弃了 MySQL,而改使用 MariaDB。MariaDB 数据库管理系统是 MySQ L的一个分支,主要由开源社区在维护,采用 GPL 授权许可。开发这个分支的原因之一是:甲骨文公司收购了 MySQL 后,有将 MySQL 闭源的潜在风险,因此社区采用分支的方式来避开这个风险。
在 Google 发布了 F1: A Distributed SQL Database That Scales 和 Spanner: Google’s Globally-Distributed Databasa 之后,业界开始流行起 NewSQL。于是有了 CockroachDB,于是有了奇叔公司的 TiDB。国内已经有比较多的公司使用 TiDB,之前在创业公司时在大数据分析时已经开始应用 TiDB,当时应用的主要原因是 MySQL 要使用分库分表,逻辑开发比较复杂,扩展性不够。
8、NoSQL
NoSQL 顾名思义就是 Not-Only SQL,也有人说是 No – SQL,个人偏向于 Not-Only SQL,它并不是用来替代关系库,而是作为关系型数据库的补充而存在。
常见 NoSQL 有4个类型:
除了以上4种类型,还有一些特种的数据库,如对象数据库,XML 数据库,这些都有针对性对某些存储类型做了优化的数据库。
在实际应用场景中,何时使用关系数据库,何时使用 NoSQL,使用哪种类型的数据库,这是我们在做架构选型时一个非常重要的考量,甚至会影响整个架构的方案。
9、消息中间件
消息中间件在后台系统中是必不可少的一个组件,一般我们会在以下场景中使用消息中间件:
异步处理:异步处理是使用消息中间件的一个主要原因,在工作中最常见的异步场景有用户注册成功后需要发送注册成功邮件、缓存过期时先返回老的数据,然后异步更新缓存、异步写日志等等;通过异步处理,可以减少主流程的等待响应时间,让非主流程或者非重要业务通过消息中间件做集中的异步处理。 系统解耦:比如在电商系统中,当用户成功支付完成订单后,需要将支付结果给通知ERP系统、发票系统、WMS、推荐系统、搜索系统、风控系统等进行业务处理;这些业务处理不需要实时处理、不需要强一致,只需要最终一致性即可,因此可以通过消息中间件进行系统解耦。通过这种系统解耦还可以应对未来不明确的系统需求。 削峰填谷:当系统遇到大流量时,监控图上会看到一个一个的山峰样的流量图,通过使用消息中间件将大流量的请求放入队列,通过消费者程序将队列中的处理请求慢慢消化,达到消峰填谷的效果。最典型的场景是秒杀系统,在电商的秒杀系统中下单服务往往会是系统的瓶颈,因为下单需要对库存等做数据库操作,需要保证强一致性,此时使用消息中间件进行下单排队和流控,让下单服务慢慢把队列中的单处理完,保护下单服务,以达到削峰填谷的作用。
业界消息中间件是一个非常通用的东西,大家在做选型时有使用开源的,也有自己造轮子的,甚至有直接用 MySQL 或 Redis 做队列的,关键看是否满足你的需求,如果是使用开源的项目,以下的表格在选型时可以参考:
图 3
以上图的纬度为:名字、成熟度、所属社区/公司、文档、授权方式、开发语言、支持的协议、客户端支持的语言、性能、持久化、事务、集群、负载均衡、管理界面、部署方式、评价。
10、代码管理
代码是互联网创业公司的命脉之一,代码管理很重要,常见的考量点包括两块:
11、持续集成
持续集成简,称 CI(continuous integration),是一种软件开发实践,即团队开发成员经常集成他们的工作,每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错误。持续集成为研发流程提供了代码分支管理/比对、编译、检查、发布物输出等基础工作,为测试的覆盖率版本编译、生成等提供统一支持。
业界免费的持续集成工具中系统我们有如下一些选择:
12、日志系统
日志系统一般包括打日志,采集,中转,收集,存储,分析,呈现,搜索还有分发等。一些特殊的如染色,全链条跟踪或者监控都可能需要依赖于日志系统实现。日志系统的建设不仅仅是工具的建设,还有规范和组件的建设,最好一些基本的日志在框架和组件层面加就行了,比如全链接跟踪之类的。
对于常规日志系统ELK能满足大部分的需求,ELK 包括如下组件:
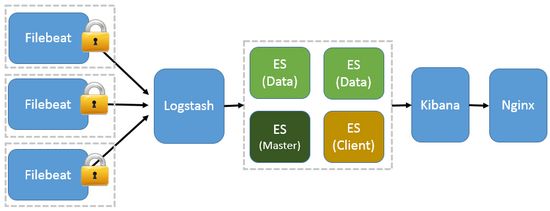
因为免费的 ELK 没有任何安全机制,所以这里使用了 Nginx 作反向代理,避免用户直接访问 Kibana 服务器。加上配置 Nginx 实现简单的用户认证,一定程度上提高安全性。另外,Nginx 本身具有负载均衡的作用,能够提高系统访问性能。ELK 架构如图4所示:
图 4,ELK 流程图
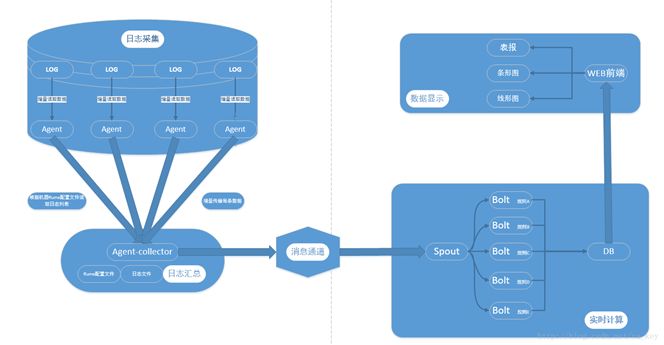
对于有实时计算的需求,可以使用 Flume + Kafka + Storm + MySQL 方案,一 般架构如图 5 所示:
图 5,实时分析系统架构图
其中:
Kafka 追求的是高吞吐量、高负载,Flume 追求的是数据的多样性,二者结合起来简直完美。
13、监控系统
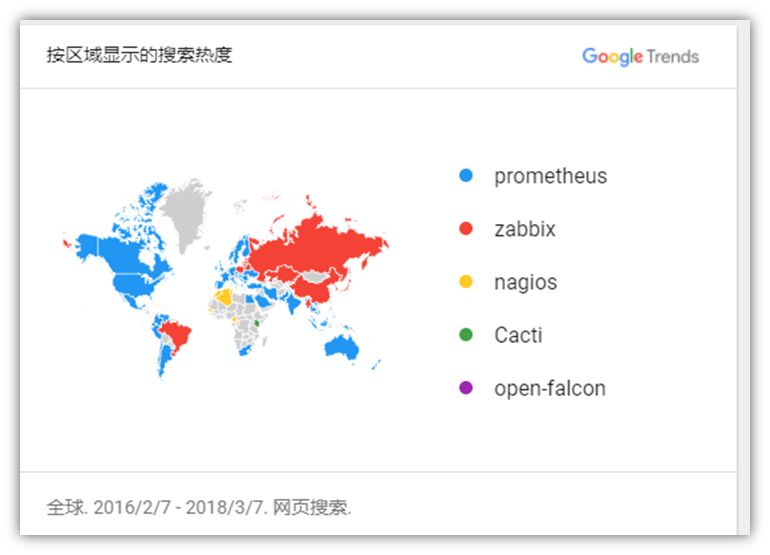
图 6,监控系统分布
亚洲区域使用 Zabbix 较多,而美洲和欧洲,以及澳大利亚使用 Prometheus 居多,换句话说,英文国家地区(发达国家?)使用 Prometheus 较多。
图 7,Prometheus 架构图
如上图所示,Prometheus 包含的主要组件如下:
创业公司选择 Prometheus + Grafana 的方案,再加上统一的服务框架(如 gRPC),可以满足大部分中小团队的监控需求。
14、配置系统
随着程序功能的日益复杂,程序的配置日益增多:各种功能的开关、降级开关,灰度开关,参数的配置、服务器的地址、数据库配置等等,除此之外,对后台程序配置的要求也越来越高:配置修改后实时生效,灰度发布,分环境、分用户,分集群管理配置,完善的权限、审核机制等等,在这样的大环境下,传统的通过配置文件、数据库等方式已经越来越无法满足开发人员对配置管理的需求,业界有如下两种方案:
创业公司前期不需要这种复杂,直接上 zk,弄一个界面管理 zk 的内容,记录一下所有人的操作日志,程序直连 zk,或者或者用 Qconf 等基于 zk 优化后的方案。
15、发布系统/部署系统
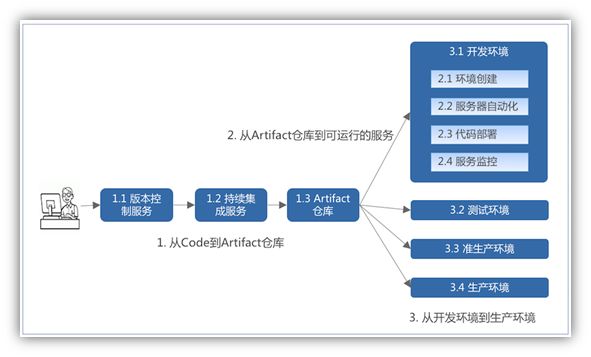
从软件生产的层面看,代码到最终服务的典型流程如图 8 所示:
图 8,流程图
从上图中可以看出,从开发人员写下代码到服务最终用户是一个漫长过程,整体可以分成三个阶段:
16、跳板机
跳板机面对的是需求是要有一种能满足角色管理与授权审批、信息资源访问控制、操作记录和审计、系统变更和维护控制要求,并生成一些统计报表配合管理规范来不断提升IT内控的合规性,能对运维人员操作行为的进行控制和审计,对误操作、违规操作导致的操作事故,快速定位原因和责任人。其功能模块一般包括:帐户管理、认证管理、授权管理、审计管理等等。
开源项目中,Jumpserver 能够实现跳板机常见需求,如授权、用户管理、服务器基本信息记录等,同时又可批量执行脚本等功能;其中录像回放、命令搜索、实时监控等特点,又能帮助运维人员回溯操作历史,方便查找操作痕迹,便于管理其他人员对服务器的操作控制。
17、机器管理
机器管理的工具选择的考量可以包含以下三个方面:
如图9所示:
图 9,机器管理软件对比
创业公司的选择
1、选择合适的语言
2、选择合适的组件和云服务商
关于开源组件,尽可能选择成熟的,成熟的组件经历了时间的考验,基本不会出大的问题,并且有成套的配套工具,出了问题在网上也可以很快的找到答案,你所遇到的坑基本上都有人踩过了。
3、制定流程和规范
制定开发的规范,代码及代码分支管理规范,关键性代码仅少数人有权限;
制定发布流程规范,从发布系统落地;
制定运维规范;
制定数据库操作规范,收拢数据库操作权限;
制定告警处理流程,做到告警有人看有人处理;
制定汇报机制,晨会/周报;
4、自研和选型合适的辅助系统
所有的流程和规范都需要用系统来固化,否则就是空中楼阁,如何选择这些系统呢?参照上个章节咱们那些开源的,对比一下选择的语言,组件之类的,选择一个最合适的即可。
比如项目管理的,看下自己是什么类型的公司,开发的节奏是怎样的,瀑布,敏捷的 按项目划分,还是按客户划分等等,平时是按项目组织还是按任务组织等等。
比如日志系统,之前是打的文本,那么上一个 ELK,规范化一些日志组件,基本上很长一段时间内不用考虑日志系统的问题,最多拆分一下或者扩容一下。等到组织大了,自己搞一个日志系统。
比如代码管理,项目管理系统这些都放内网,安全,在互联网公司来说,属于命脉了,命脉的东西还是放在别人拿不到或很难拿到的地方会比较靠谱一些。
5、选择过程中需要思考的问题
技术栈的选择有点像做出了某种承诺,在一定的时间内这种承诺没法改变,于是我们需要在选择的时候有一些思考。
向未来看一眼,在一年到三年内,我们需要做出改变吗?技术栈要做根本性的改变吗?如果组织发展很快,在 200 人,500 人时,现有的技术栈是否需要大动?
创业过程中需要考虑成本,这里的成本不仅仅是花费多少钱,付出多少工资,有时更重要的是时间成本,很多业务在创业时大家拼的就是时间,就是一个时间窗,过了就没你什么事儿了。
结合上面内容的考量,在对一个个系统和组件的做选型之后,以云服务为基础,一个创业公司的后台技术架构如图10所示:
图 10,后台技术架构
参考资料
http://database.51cto.com/art/201109/291781.htm
https://zh.wikipedia.org/wiki/Kafka
https://prometheus.io/docs/introduction/overview/
http://deadline.top/2016/11/23/配置中心那点事/
http://blog.fit2cloud.com/2016/01/26/deployment-system.html
全栈架构社区交流群





「全栈架构社区」建立了读者架构师交流群,大家可以添加小编微信进行加群。欢迎有想法、乐于分享的朋友们一起交流学习。
看完本文有收获?请转发分享给更多人
往期资源: