
【网站搭建】列式数据库ClickHouse
Start:关注本公众号后,可直接联系后台获取排版美化的详细文档!
Hints:本篇文章所编纂的资料均来自网络,特此感谢参与奉献的有关人员。
Clickhouse的优点:
Ø 1.真正的面向列的DBMS
Ø 2.数据高效压缩
Ø 3.磁盘存储的数据
Ø 4.多核并行处理
Ø 5.在多个服务器上分布式处理
Ø 6.SQL语法支持
Ø 7.向量化引擎
Ø 8.实时数据更新
Ø 9.索引
Ø 10.适合在线查询
Ø 11.支持近似预估计算
Ø 12.支持嵌套的数据结构
Ø 支持数组作为数据类型
Ø 13.支持限制查询复杂性以及配额
Ø 14.复制数据复制和对数据完整性的支持
Clickhouse的缺点:
Ø 1.不支持事物。
Ø 2.不支持Update/Delete操作。
Ø 3.支持有限操作系统。
现在支持ubuntu,centos 需要自己编译,不过有热心人已经编译好了,拿来用就行。
Clickhouse的应用:
1.电信行业用于存储数据和统计数据使用。
2.新浪微博用于用户行为数据记录和分析工作。
3.用于广告网络和RTB,电子商务的用户行为分析。
4.信息安全里面的日志分析。
5.检测和遥感信息的挖掘。
6.商业智能。
7.网络游戏以及物联网的数据处理和价值数据分析。
8.最大的应用来自于Yandex的统计分析服务Yandex.Metrica,类似于谷歌Analytics(GA),或友盟统计,小米统计,帮助网站或移动应用进行数据分析和精细化运营工具,据称Yandex.Metrica为世界上第二大的网站分析平台。
Clickhouse的案例:
-今日头条内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
-腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
-携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
-快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
-在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。
-国内云计算的领导厂商阿里云 率先推出了自己的ClickHouse托管产品,产品首页地址为 云数据库ClickHouse,可以点击链接申请参加免费公测,一睹为快!
Clickhouse的分析:
OLAP场景的特点
-读多于写
不同于事务处理(OLTP)的场景,比如电商场景中加购物车、下单、支付等需要在原地进行大量insert、update、delete操作,数据分析(OLAP)场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。数据一次性写入后,分析师需要尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息。这是一个需要反复试错、不断调整、持续优化的过程,其中数据的读取次数远多于写入次数。这就要求底层数据库为这个特点做专门设计,而不是盲目采用传统数据库的技术架构。
-大宽表,读大量行但是少量列,结果集较小
OLTP类业务对于延时(Latency)要求更高,要避免让客户等待造成业务损失;而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐(Throughput),要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新、删除操作。
-无需事务,数据一致性要求低
OLAP类业务对于事务需求较少,通常是导入历史日志数据,或搭配一款事务型数据库并实时从事务型数据库中进行数据同步。多数OLAP系统都支持最终一致性。
-灵活多变,不适合预先建模
分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
Clickhouse的架构
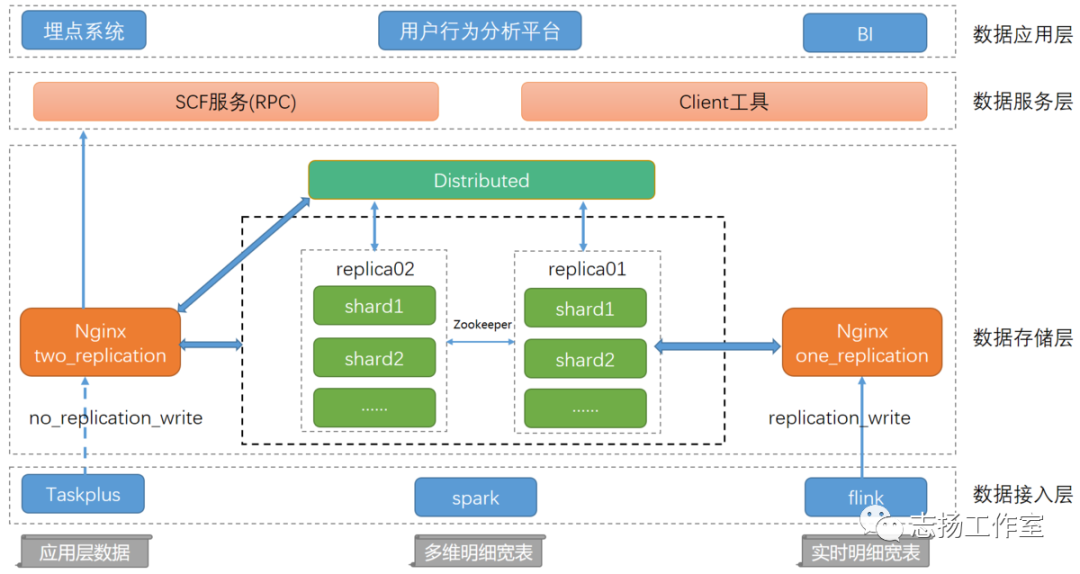
数据接入层
提供了数据导入相关的服务及功能,按照数据的量级和特性我们抽象出三种Clickhouse导入数据的方式。
方式一:数仓应用层小表导入
这类数据量级相对较小,且分布在不同的数据源如hdfs、es、hbase等,这时我们提供基于DataX自研的TaskPlus数据流转+调度平台导入数据,单分区数据无并发写入,多分区数据小并发写入,且能和线上任务形成依赖关系,确保导入程序的可靠性。方式二:离线多维明细宽表导入
这类数据一般是汇总层的明细数据或者是用户基于Hadoop生产的大量级数据,我们基于Spark开发了一个导入工具包,用户可以根据配置直接拉取hdfs或者hive上的数据到clickhouse,同时还能基于配置sql对数据进行ETL处理,工具包会根据配置集群的节点数以及Clickhouse集群负载情况(merges、processes)对local表进行高并发的写入,达到快速导数的目的。方式三:实时多维明细宽表导入
实时数据接入场景比较固定,我们封装了通用的ClickhouseSink,将app、pc、m三端每日百亿级的数据通过Flink接入clickhouse,ClickhouseSink也提供了batchSize(单次导入数据量)及batchTime(单次导入时间间隔)供用户选择。数据存储层
数据存储层这里我们采用双副本机制来保证数据的高可靠,同时用nginx代理clickhouse集群,通过域名的方式进行读写操作,实现了数据均衡及高可靠写入,且对于域名的响应时间及流量有对应的实时监控,一旦响应速度出现波动或异常我们能在第一时间收到报警通知。
nginx_one_replication:代理集群一半节点即一个完整副本,常用于写操作,在每次提交数据时由nginx均衡路由到对应的shard表,当某一个节点出现异常导致写入失败时,nginx会暂时剔除异常节点并报警,然后另选一台节点重新写入。
nginx_two_replication:代理集群所有节点,一般用作查询和无副本表数据写入,同时也会有对于异常节点的剔除和报警机制。
数据服务层
对外:将集群查询统一封装为scf服务(RPC),供外部调用。
对内:提供了客户端工具直接供分析师及开发人员使用。
数据应用层
埋点系统:对接实时clickhouse集群,提供秒级别的OLAP查询功能。
用户分析平台:通过标签筛选的方式,从用户访问总集合中根据特定的用户行为捕获所需用户集。
BI:提供数据应用层的可视化展示,对接单分片多副本Clickhouse集群,可横向扩展。
Clickhouse的存储:
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
列式存储
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储。
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的datasize,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sortby。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block,大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
主键索引
ClickHouse支持主键索引,它将每列数据按照indexgranularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。
数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQLPattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1)random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2)constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题;
ClickHouse的计算
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个indexgranularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗
动态代码生成Runtime Codegen
在经典的数据库实现中,通常对表达式计算采用火山模型,也即将查询转换成一个个operator,比如HashJoin、Scan、IndexScan、Aggregation等。为了连接不同算子,operator之间采用统一的接口,比如open/next/close。在每个算子内部都实现了父类的这些虚函数,在分析场景中单条SQL要处理数据通常高达数亿行,虚函数的调用开销不再可以忽略不计。另外,在每个算子内部都要考虑多种变量,比如列类型、列的size、列的个数等,存在着大量的if-else分支判断导致CPU分支预测失效。
近似计算
近似计算以损失一定结果精度为代价,极大地提升查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse 和一些技术的比较
1.商业OLAP数据库
例如:HP Vertica, Actian the Vector,
区别:ClickHouse是开源而且免费的
2.云解决方案
例如:亚马逊RedShift和谷歌的BigQuery
区别:ClickHouse可以使用自己机器部署,无需为云付费
3.Hadoop生态软件
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
区别:
ClickHouse支持实时的高并发系统
ClickHouse不依赖于Hadoop生态软件和基础
ClickHouse支持分布式机房的部署
4.开源OLAP数据库
例如:InfiniDB, MonetDB, LucidDB
区别:这些项目的应用的规模较小,并没有应用在大型的互联网服务当中,相比之下,ClickHouse的成熟度和稳定性远远超过这些软件。
5.开源分析,非关系型数据库
例如:Druid , Apache Kylin
区别:ClickHouse可以支持从原始数据的直接查询,ClickHouse支持类SQL语言,提供了传统关系型数据的便利。
ClickHouse 快速的原因
有如下几点:
只需要读取要计算的列数据,而非行式的整行数据读取,降低 IO cost。
同列同类型,有十倍压缩提升,进一步降低 IO。
Clickhouse 根据不同存储场景,做个性化搜索算法。
参考资料:
ClickHouse概述
https://www.jianshu.com/p/350b59e8ea68
Clickhouse深度揭秘
https://zhuanlan.zhihu.com/p/98135840
Clickhouse教程
https://clickhouse.tech/docs/zh/getting-started/tutorial/
https://www.jianshu.com/p/350b59e8ea68
https://blog.csdn.net/likun557/article/details/109733541
Clickhouse架构概述
https://clickhouse.tech/docs/zh/development/architecture/
Clickhouse实践之路
https://www.jianshu.com/p/fca68daf4cbf
公众号二维码
End:如果有兴趣了解金融量化交易和其他数据分析的实用技术,欢迎关注本公众号