一个让 git clone 提速几十倍的小技巧
不知道大家有没有遇到比较大的项目,git clone 很慢很慢,甚至会失败的那种。大家会怎么处理的呢?
可能会考虑换一个下载源,可能会通过一些手段提高网速,但是如果这些都试过了还是比较慢呢?
今天我就遇到了这个问题,我需要把 typescript 代码从 gitlab 下载下来,但是速度特别慢:
git clone https://github.com/microsoft/TypeScript ts
等了很久还是没下载完,于是我加了一个参数:
git clone https://github.com/microsoft/TypeScript --depth=1 ts
这样速度提高了几十倍,瞬间下载完了。
加上 --depth 会只下载一个 commit,所以内容少了很多,速度也就上去了。
而且下载下来的内容是可以继续提交新的 commit、创建新的分支的。不影响后续开发,只是不能切换到历史 commit 和历史分支。
我用我的一个项目测试过,我首先下载了一个 commit:
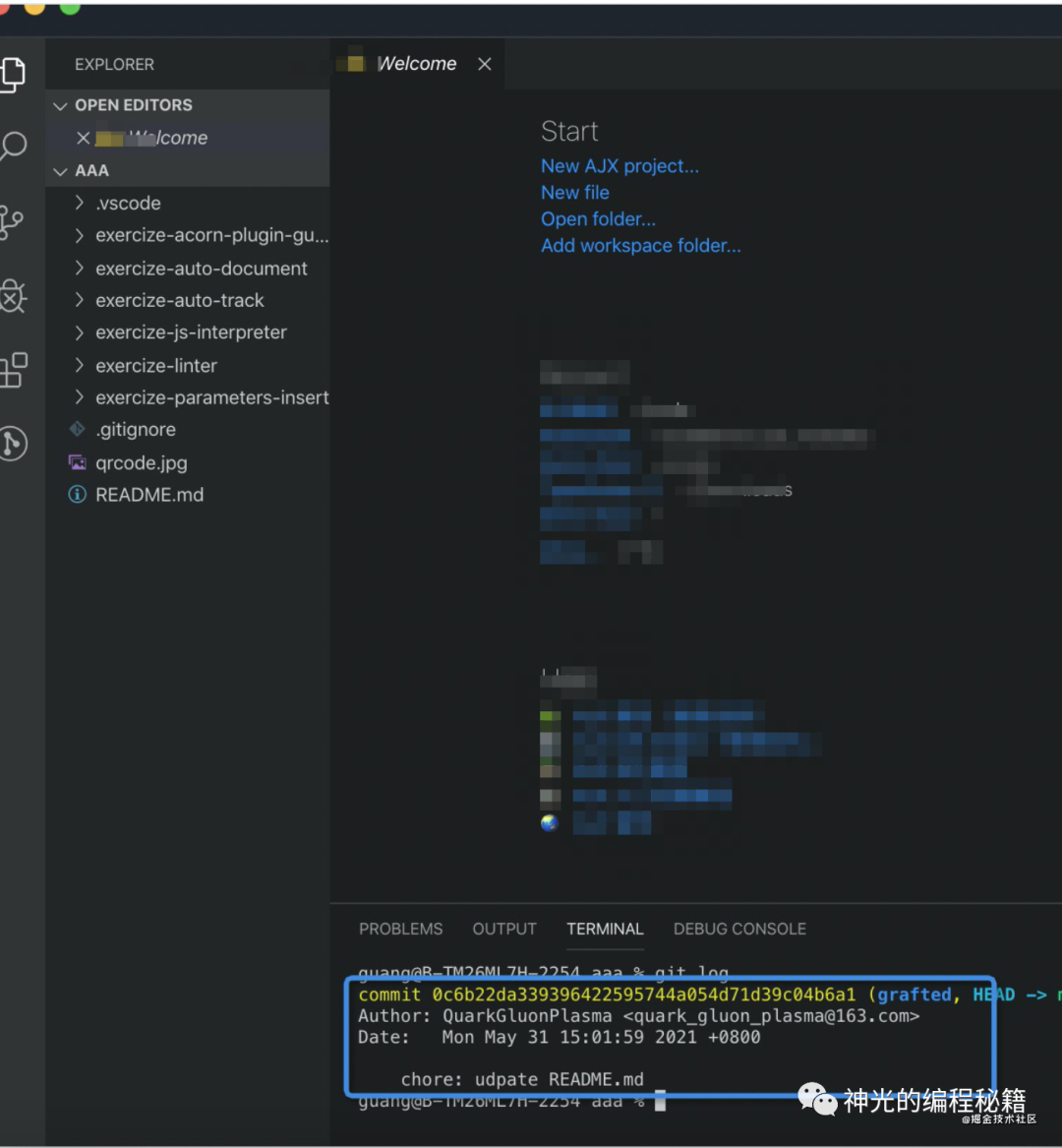
然后做一下改动,之后 git add、commit、push,能够正常提交:
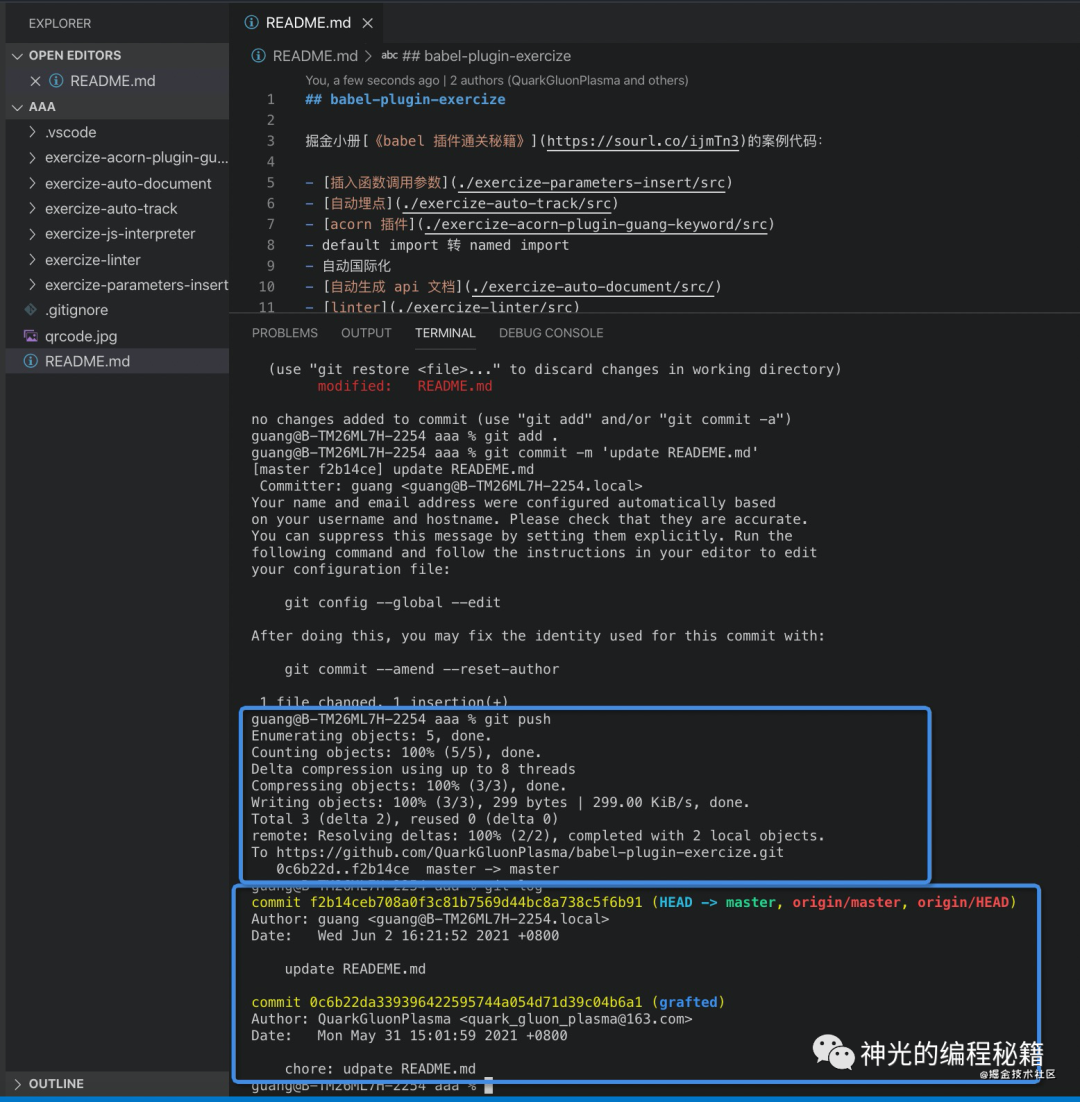
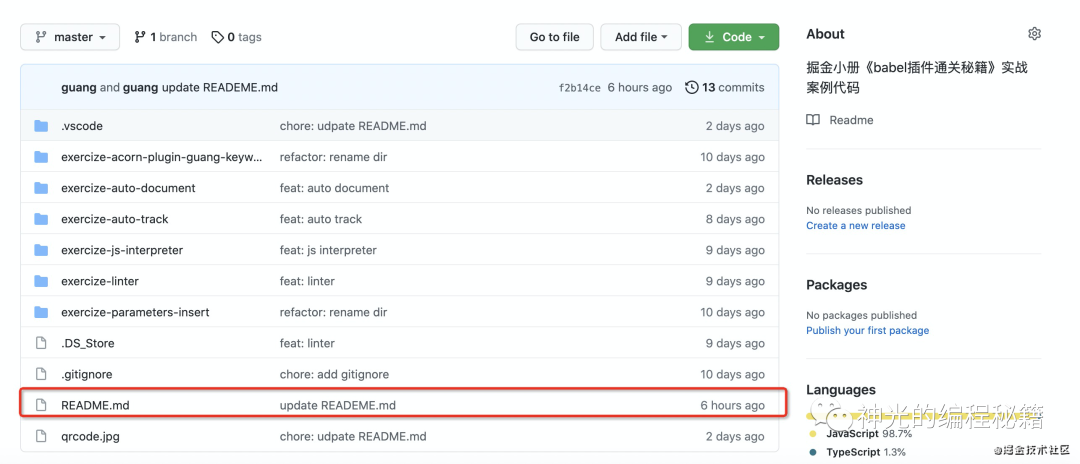
创建新分支也能正常提交。唯一的缺点就是不能切换到历史 commit 和历史分支。
在一些场景下还是比较有用的:当需要切换到历史分支的时候也可以计算需要几个 commit,然后再指定 depth,这样也可以提高速度。
大家有没有想过,这样能行的原理是什么?
git 原理
git 是通过一些对象来保存信息的:
glob 对象存储文件内容 tree 对象存储文件路径 commit 对象存储 commit 信息,关联 tree
以一个 commit 为入口,关联的所有的 tree 和 blob,就是这个 commit 的内容。
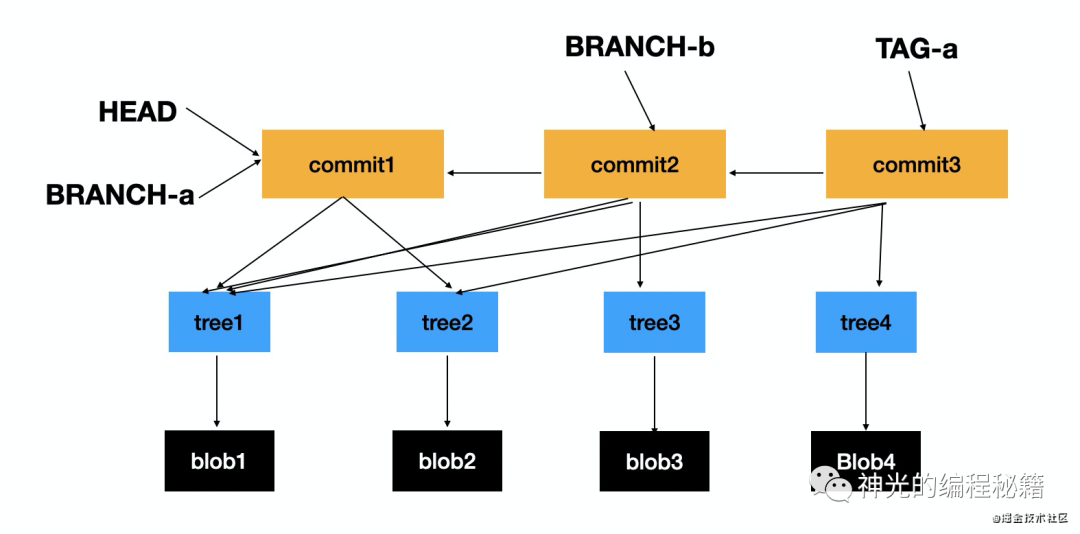
commit 之间相互关联,而 head、branch、tag 等是指向具体 commit 的指针。可以在 .git/refs 下看到。这样就基于 commit 实现了分支、tag 等概念。
git 就是通过这三个对象来实现的版本管理和分支切换的功能,所有 objects 可以在 .git/objects 下看到。
这就是 git 的原理。
主要理解 blob、tree、commit 这三个 object,还有 head、tag、branch、remote 等 ref。
能下载单个 commit 的原理
我们知道了 git 是通过某一个 commit 做为入口来关联所有的 object,那如果我们不需要历史自然就可以只下载一个 commit。
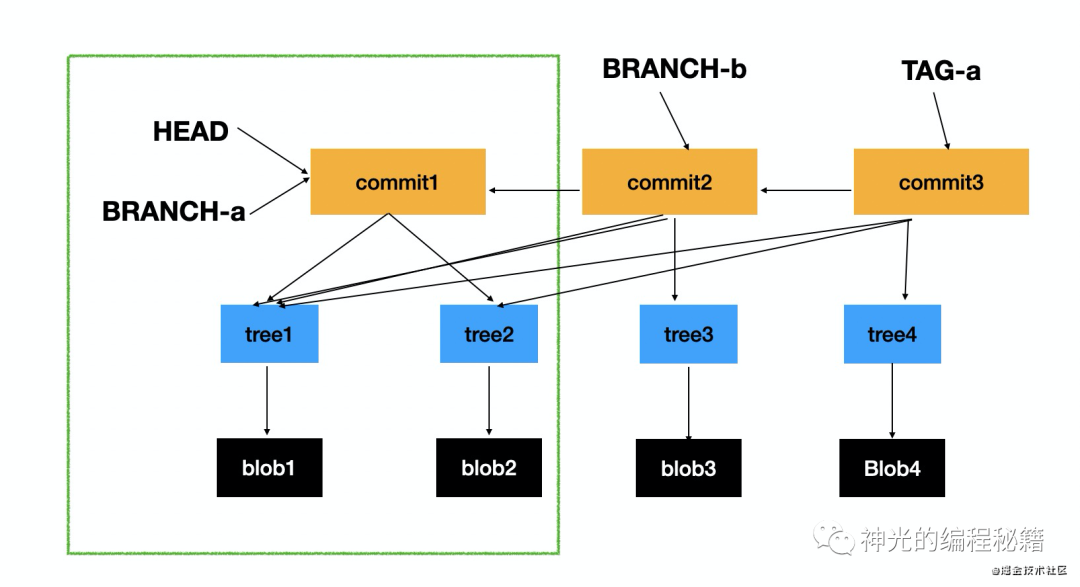
这样依然基于那个 commit 创建新的 commit,关联新的 blob、tree 等。但是历史的 commit、tree、blob 因为都没有下载下来所以无法切回去,相应的 tag、branch 等指针也不行。这就是我们下载了单个 commit 却依然可以创建新的分支、commit 等的原理。
总结
遇到大的 git 项目的时候,可以通过添加 --depth 参数使得速度极大提升,历史 commit 越多,下载速度提升越大。
而且下载下来的项目依然可以进行后续开发,可以创建新的 commit 和新的分支、tag,只是不能切换到历史 commit、分支、tag。
我们梳理了 git 的原理:通过 tree、blob、commit 这三个 object 来存储文件和提交信息,通过 commit 之间的关联来实现分支、标签等功能。commit 是入口,关联所有的 tree 和 blob。
我们下载了一个 commit,就是下载了他关联的所有 tree、blob,还有一些 refs (包括tag、branch 等),这就是 --depth 的原理。
希望大家在不需要切换到历史 commit 和分支的场景下可以用这个技巧来提升大项目的 git clone 速度。
往期推荐

Vite 太快了,烦死了,是时候该小睡一会了。

如何实现比 setTimeout 快 80 倍的定时器?

万字长文!总结Vue 性能优化方式及原理

90 行代码的 webpack,你确定不学吗?
最后
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
欢迎加我微信「huab119」拉你进技术群,长期交流学习...
关注公众号「前端劝退师」,持续为你推送精选好文,也可以加我为好友,随时聊骚。