
Selenium自动登录淘宝,我无意间发现了登录漏洞!
回复“书籍”即可获赠Python从入门到进阶共10本电子书
这篇文章是一个很好的学习例子,作者能够在学习过程中,不断发现、不断总结,并且能够坚持不懈。
希望大家读完了作者的这篇文章,能够在学习道路上 ,更有冲劲儿,更有动力。
一、前言
之前写过一篇爬取淘宝商品信息的博客(原来文章的链接如下),当时还是新手,急于完成爬取目标,干脆手动登录淘宝使浏览器保存我的信息,然后使用本地用户配置控制浏览器,投机取巧地解决了登录问题。
原来文章链接:http://suo.im/67AJKM
虽然这不失为一种方法,但这却让selenium的全自动变成了半自动,不配Python之美。
那么如何全自动登录淘宝呢?起初我是在互联网上找一些资源项目,直接拿来分析,但随着淘宝的反爬机制的增强,他们的这些方法都行不通了。于是我决定,自己动手!
二、分析
为了方便使用,我将整个代码进行了封装,文件名为login,类名为Login,请大家接着往下看。
1)相关依赖
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
2)构造函数
def __init__(self, username, password):
"""
初始化浏览器配置和登录信息
"""
self.url = 'https://login.taobao.com/member/login.jhtml'
# 初始化浏览器选项
options = webdriver.ChromeOptions()
# 禁止加载图片
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 设置为开发者模式
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 加载浏览器选项
self.browser = webdriver.Chrome(options=options)
# 设置显式等待时间40s
self.wait = WebDriverWait(self.browser, 40)
self.username = username # 用户名
self.password = password # 密码
3)原始登录,使用淘宝账号或手机号登录
def original(self):
"""
直接使用淘宝账号登录
:return: None
"""
self.browser.get(url=self.url)
try:
input_username = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.fm-field > div.input-plain-wrap.input-wrap-loginid > input'
)))
input_password = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.fm-field > div.input-plain-wrap.input-wrap-password > input'
)))
# 等待滑块按钮加载
div = self.wait.until(EC.presence_of_element_located((
By.ID, 'nc_1__bg'
)))
input_username.send_keys(self.username)
input_password.send_keys(self.password)
# 休眠2s,等待滑块按钮加载
time.sleep(2)
# 点击并按住滑块
ActionChains(self.browser).click_and_hold(div).perform()
# 移动滑块
ActionChains(self.browser).move_by_offset(xoffset=300, yoffset=0).perform()
# 等待验证通过
self.wait.until(EC.text_to_be_present_in_element((
By.CSS_SELECTOR, 'div#nc_1__scale_text > span.nc-lang-cnt > b'), '验证通过'
))
# 登录
input_password.send_keys(Keys.ENTER)
print('Successful !')
except TimeoutException as e:
print('Error:', e.args)
self.original()
其它的结点元素的定位我就不多说了,主要说一下滑块的定位。
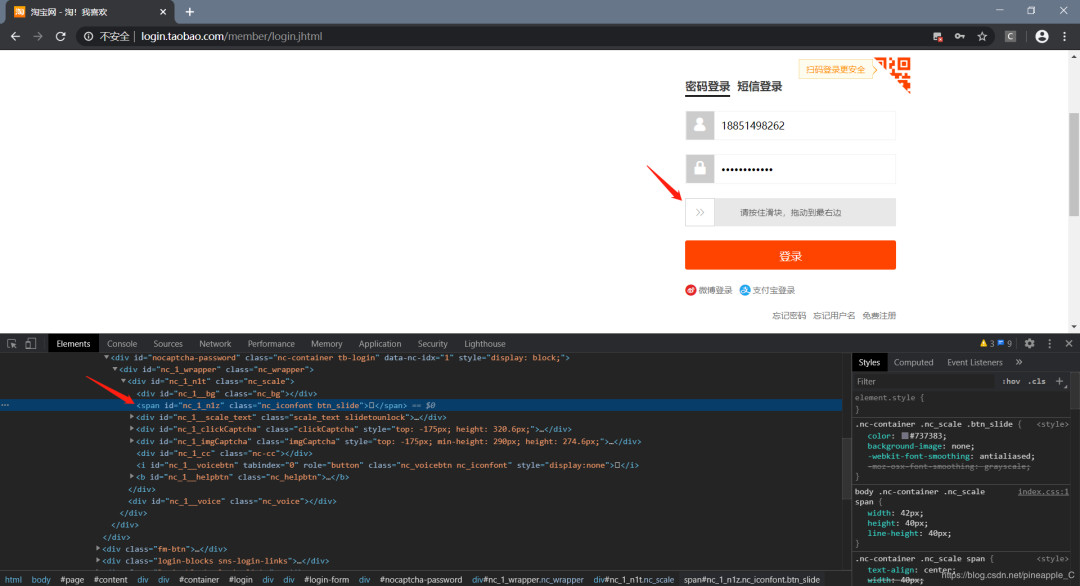
利用浏览器定位的话,会定位到 span这个结点,但经过我模仿单击按住,拖拽后滑块一动不动,参数也没有任何改变。于是我尝试了一下它的父节点div还是按住后拖拽,这次成功了。所以有时候不要怀疑自己的代码,有可能是其它方面的问题。
还有关于拖拽还要说明一下,淘宝的登录验证不是极验验证码,不是拖动滑块拼图的操作,而是将滑块拖到最右端。所以,至于这个最右端,只要距离够长,且不超出界面范围,长度随便定!
最后补充一下,偶尔会出现这种情况。
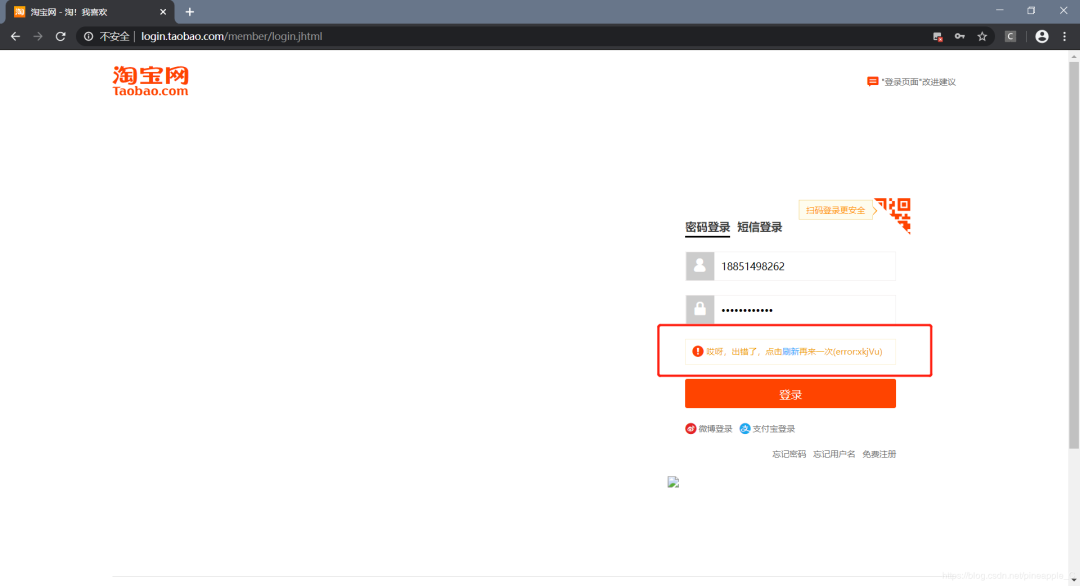
得到这张图也是很不容易啊,因为这种情况真的是太少了。经过反复实验,大概是因为滑动的轨迹不是基本水平导致的,就是说朝着斜下方滑动,虽然也能到达最右端,但会给出这个错误。我的程序是让它水平方向滑动300,竖直方向坐标为0。虽然是水平滑动,但是为了提高程序的容错率,还是加上了一个验证通过的等待。
4)使用新浪微博账号登录,巧妙利用漏洞
提示:在用新浪微博登录之前,请在淘宝上绑定你的新浪账号。
def sina(self):
"""
使用新浪微博账号登录(提前绑定新浪账号)
:return: None
"""
self.browser.get(url=self.url)
try:
# 等待新浪登录链接加载
weibo_login = self.wait.until(EC.element_to_be_clickable((
By.CSS_SELECTOR, '#login-form a.weibo-login'
)))
weibo_login.click()
input_username = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.info_list > div.inp.username > input.W_input'
)))
input_password = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.info_list > div.inp.password > input.W_input'
)))
input_username.send_keys(self.username)
input_password.send_keys(self.password)
input_password.send_keys(Keys.ENTER)
# 等待浏览器保存我方信息,网速不好可以设置长一点
time.sleep(5)
# 刷新页面
self.browser.refresh()
# 等待快速登录按钮加载
quick_login = self.wait.until(EC.element_to_be_clickable((
By.CSS_SELECTOR, 'div.info_list > div.btn_tip > a.W_btn_g'
)))
quick_login.click()
print('login successful !')
except TimeoutException as e:
print('Error:', e.args)
self.sina()
关于结点元素的定位我就不多说了,主要说一下这个漏洞。
正常情况下,输入完信息后点击登录,就该进入淘宝页面了,但是这个登录按钮不管怎么点,页面都是无动于衷。
定位一下,可以发现:
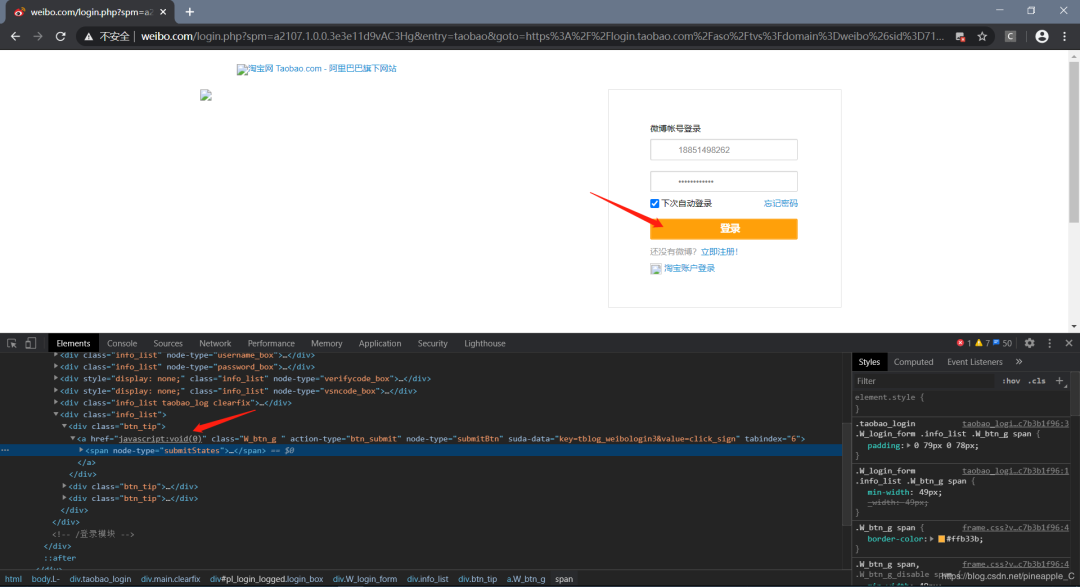
这个按钮的链接是javascript:void(0),假链接!!!
由于我的前端基础不好,不知道这啥意思。我疯狂的在互联网上查找如何使用selenium点击这种链接,可依旧没找到解决的办法。有没有人知道如何处理这种,请给原文作者留言!
然而就在我快放弃的时候,按了下F5刷新,奇迹出现了!
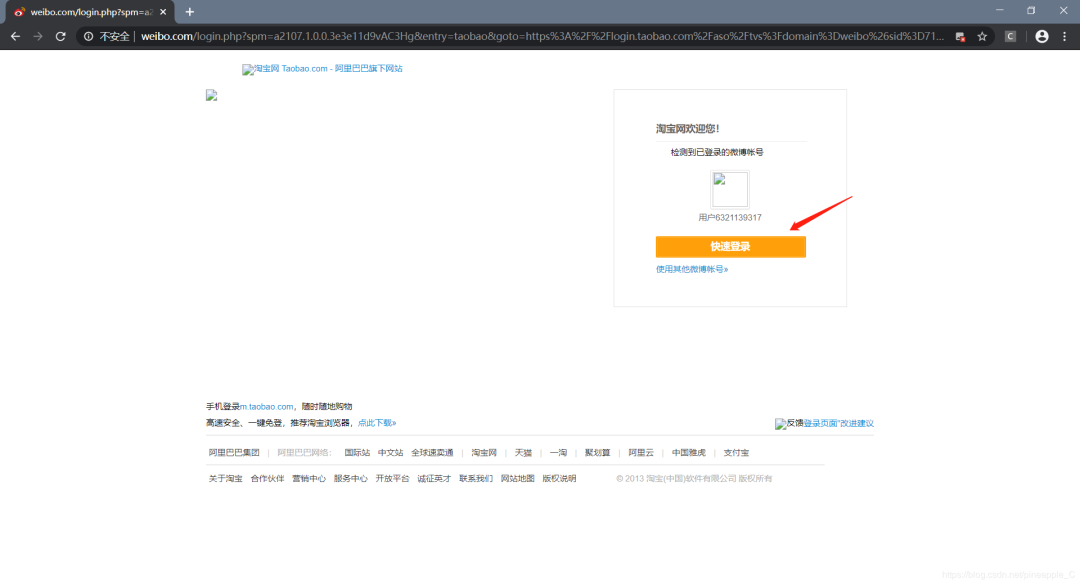
检测到已登录的微博账号,快速登录???原来虽然我没有进入淘宝,但是浏览器左下角一直在显示如:等待**相应,正在解析主机等信息。所以淘宝还是保存了我的账号信息,只要下次自动登录的勾打上(默认打勾),它就会保存账号信息。
这就是为什么上面的代码,在输入好信息并回车登录后,要等待5秒,就是让它保存我的账号信息。
最后刷新页面,点击快速登录,大功告成!
三、完整代码及使用方法
1)完整代码
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:cppjavapython@foxmail.com
@time:2020/7/28 9:09
@file:login.py
@desc: login taobao .
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
class Login:
def __init__(self, username, password):
"""
初始化浏览器配置和登录信息
"""
self.url = 'https://login.taobao.com/member/login.jhtml'
# 初始化浏览器选项
options = webdriver.ChromeOptions()
# 禁止加载图片
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 设置为开发者模式
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 加载浏览器选项
self.browser = webdriver.Chrome(options=options)
# 设置显式等待时间40s
self.wait = WebDriverWait(self.browser, 40)
self.username = username # 用户名
self.password = password # 密码
def original(self):
"""
直接使用淘宝账号登录
:return: None
"""
self.browser.get(url=self.url)
try:
input_username = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.fm-field > div.input-plain-wrap.input-wrap-loginid > input'
)))
input_password = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.fm-field > div.input-plain-wrap.input-wrap-password > input'
)))
# 等待滑块按钮加载
div = self.wait.until(EC.presence_of_element_located((
By.ID, 'nc_1__bg'
)))
input_username.send_keys(self.username)
input_password.send_keys(self.password)
# 休眠2s,等待滑块按钮加载
time.sleep(2)
# 点击并按住滑块
ActionChains(self.browser).click_and_hold(div).perform()
# 移动滑块
ActionChains(self.browser).move_by_offset(xoffset=300, yoffset=0).perform()
# 等待验证通过
self.wait.until(EC.text_to_be_present_in_element((
By.CSS_SELECTOR, 'div#nc_1__scale_text > span.nc-lang-cnt > b'), '验证通过'
))
# 登录
input_password.send_keys(Keys.ENTER)
print('Successful !')
except TimeoutException as e:
print('Error:', e.args)
self.original()
def sina(self):
"""
使用新浪微博账号登录(提前绑定新浪账号)
:return: None
"""
self.browser.get(url=self.url)
try:
# 等待新浪登录链接加载
weibo_login = self.wait.until(EC.element_to_be_clickable((
By.CSS_SELECTOR, '#login-form a.weibo-login'
)))
weibo_login.click()
input_username = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.info_list > div.inp.username > input.W_input'
)))
input_password = self.wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, 'div.info_list > div.inp.password > input.W_input'
)))
input_username.send_keys(self.username)
input_password.send_keys(self.password)
input_password.send_keys(Keys.ENTER)
# 等待浏览器保存我方信息,网速不好可以设置长一点
time.sleep(5)
# 刷新页面
self.browser.refresh()
# 等待快速登录按钮加载
quick_login = self.wait.until(EC.element_to_be_clickable((
By.CSS_SELECTOR, 'div.info_list > div.btn_tip > a.W_btn_g'
)))
quick_login.click()
print('login successful !')
except TimeoutException as e:
print('Error:', e.args)
self.sina()
2)使用
在使用的时候要导入这个Login类,然后初始化这个类,最后登录方法使用相应的函数,文件名为login,类名为Login。
from login import Login
username = '******' # 账号
password = '******.' # 密码
# 初始化Login类
login = Login(username, password)
# 使用淘宝账号或手机号登录
login.original()
# 使用新浪微博账号登录
# login.sina()
四、结语
本篇说的是淘宝自动登录,其实还是用了很多投机取巧的方法,比如:拖动滑块的位置没有确定,没有解决javascript:void(0)假链接的问题。
若是淘宝加强了反爬机制,使用极验验证码等,这里的最新版,可能也要被淘汰了,所以还是要接着解决极验验证码啊,以备后续更新!
如有错误,欢迎私信纠正!
技术永无止境,谢谢支持!
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~