
绕过 Docker ,大规模杀死容器

要让所有人都能在 Replit 上使用 Web 浏览器编写代码,我们的后端基础设施就是在可抢占的虚拟机上运行。也就是说,运行你代码的计算机可以随时关闭!当这种情况发生时,我们就用 REPL(Read-Eval-Print Loop,读取 - 求值 - 输出循环)快速重新连接。虽然我们已经尽了最大的努力,但人们还是会发现 REPL 连接被卡了很久。通过分析和挖掘 Docker 源代码,我们发现并解决了这一问题。我们的会话连接错误率从 3% 降到了 0.5% 以下,99 百分位会话启动时间从 2 分钟降到了 15 秒。
造成 REPL 卡死有多种原因,其中有机器故障、竞争条件导致死锁、容器关机慢等原因。本文主要介绍我们如何修复最后一个原因,即容器关机速度慢。缓慢的容器关机几乎影响到每个使用该平台的人,并导致 REPL 无法访问长达一分钟。
你需要对 Replit 的架构有一些了解,然后才能深入研究如何解决容器关机缓慢的问题。
打开 REPL 后,浏览器将打开 websocket,将其连接到在可抢占虚拟机上运行的 Docker 容器。每一台虚拟机都运行着我们称为 conman 的东西,这是容器管理器(container manager)的简称。
要确保每一个 REPL 在任何时候都只有一个单一的容器。容器被设计用于促进多人游戏的功能,因此 REPL 的重要性在于, REPL 中的每个用户都连接到同一个容器。
当托管这些 Docker 容器的机器关机时,我们必须等待每个容器都被销毁,然后才能在其他机器上再次启动它们。这一过程经常发生,因为我们使用的是可抢占实例。
以下是尝试在 mid-shutdown 实例上访问 REPL 的典型流程。
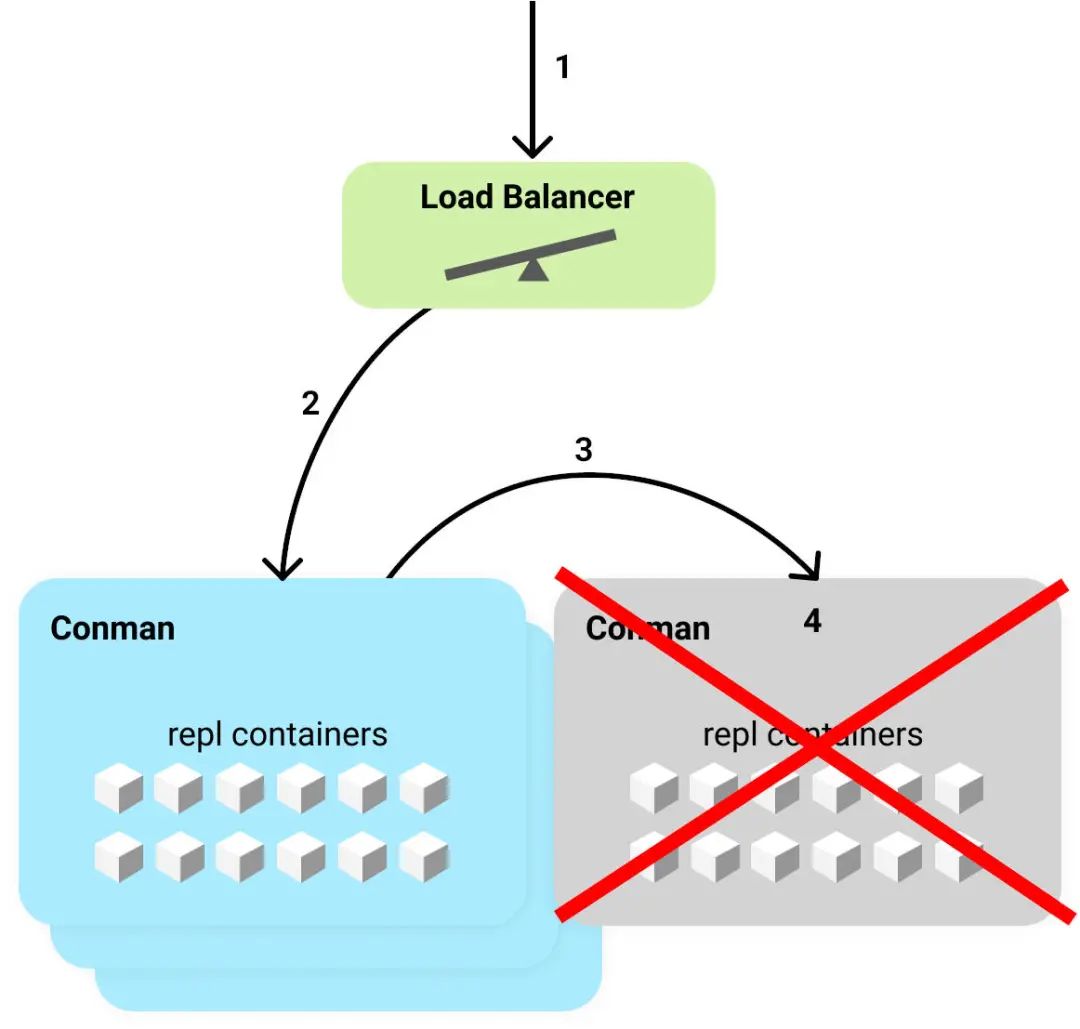
用户打开他们的 REPL,该 REPL 打开 IDE,然后尝试通过 WebSocket 连接到后端评估服务器。
该请求命中负载均衡器,负载均衡器根据 CPU 使用情况选择一个 conman 实例作为代理。
一个健康的、运行的 conman 收到了这个请求。conman 注意到,该请求是针对一个存在于不同 conman 上的容器的,并在那里代理该请求。
遗憾的是,这个 conman 关闭了 WebSocket 连接并且拒绝了!
该请求将一直失败,直到:
docker 容器被关闭,全局存储中的 REPL 容器项被删除。
conman 完成关闭,不再能访问。在这种情况下,第一个 conman 将删除旧的 REPL 容器项,并启动一个新的容器。
在强制终止可抢占虚拟机之前,将有 30 秒的时间完全关闭虚拟机。通过研究,我们发现,很少能在 30 秒内完成关机。因此,我们必须进一步研究并检测机器关机例程。
通过添加有关机器关机的日志和指标,显然 docker kill 被调用的时间比预期要长得多。正常运行时,docker kill 杀死 REPL 容器通常只需几毫秒,但是,在关机期间,我们同时杀死 100~200 个容器却要花费 20 多秒的时间。
Docker 提供了两种停止容器的方法:docker stop 和 docker kill。Docker stop 会向容器发送一个 SIGTERM 信号,并给容器一个宽限期,让它优雅地关机。如果容器没有在宽限期内关机,就会向容器发送 SIGKILL。我们并不在乎宽限期关闭容器,而是希望 docker kill 发送 SIGKILL,这样它就会立即杀死容器。出于某些原因,docker kill 并不能在几秒钟内完成容器的 SIGKILL,这一理论与现实不符,肯定还有别的原因。
要深入探讨这个问题,这里有一个脚本,可以创建 200 个 docker 容器,同时计算出需要多长时间才能杀死它们。
COUNT=200echo "Starting $COUNT containers..."for i in $(seq 1 $COUNT); doprintf .docker run -d --name test-$i nginx > /dev/null 2>&1doneecho -e "\nKilling $COUNT containers..."time $(docker kill $(docker container ls -a --filter "name=test" --format "{{.ID}}") > /dev/null 2>&1)echo -e "\nCleaning up..."docker rm $(docker container ls -a --filter "name=test" --format "{{.ID}}") > /dev/null 2>&1
对于生产中运行的同一类型的虚拟机,即 GCEn1-highmem-4 实例,将会生成如下结果:
Starting 200 containers...................................<trimmed>Killing 200 containers...real 0m37.732suser 0m0.135ssys 0m0.081sCleaning up...
我们认为, Docker 运行时发生了一些内部事件,导致关机速度非常缓慢,这就证实了我们的怀疑。现在要挖掘 Docker 本身。
Docker 守护进程有一个启用调试日志记录的选项。通过这些日志,我们可以了解 dockerd 内部发生了什么,并且每个条目都有一个时间戳,因此可以对这些时间所花费的位置提供一些信息。
在启用了调试日志之后,让我们重新运行脚本,看看 dockerd 的日志。因为要处理的容器有 200 个,它会输出大量的日志信息,所以我手工选择了一些有意义的日志。
2020-12-04T04:30:53.084Z dockerd Calling GET /v1.40/containers/json?all=1&filters=%7B%22name%22%3A%7B%22test%22%3Atrue%7D%7D2020-12-04T04:30:53.084Z dockerd Calling HEAD /_ping2020-12-04T04:30:53.468Z dockerd Calling POST /v1.40/containers/33f7bdc9a123/kill?signal=KILL2020-12-04T04:30:53.468Z dockerd Sending kill signal 9 to container 33f7bdc9a1239a3e1625ddb607a7d39ae00ea9f0fba84fc2cbca239d73c7b85c2020-12-04T04:30:53.468Z dockerd Calling POST /v1.40/containers/2bfc4bf27ce9/kill?signal=KILL2020-12-04T04:30:53.468Z dockerd Sending kill signal 9 to container 2bfc4bf27ce93b1cd690d010df329c505d51e0ae3e8d55c888b199ce0585056b2020-12-04T04:30:53.468Z dockerd Calling POST /v1.40/containers/bef1570e5655/kill?signal=KILL2020-12-04T04:30:53.468Z dockerd Sending kill signal 9 to container bef1570e5655f902cb262ab4cac4a873a27915639e96fe44a4381df9c11575d0...
在这里,我们可以看到杀死每个容器的请求,并且 SIGKILL 几乎是立即发送到每个容器。
以下是执行 docker kill 后 30 秒左右看到的一些日志记录:
...2020-12-04T04:31:32.308Z dockerd Releasing addresses for endpoint test-1's interface on network bridge2020-12-04T04:31:32.308Z dockerd ReleaseAddress(LocalDefault/172.17.0.0/16, 172.17.0.2)2020-12-04T04:31:32.308Z dockerd Released address PoolID:LocalDefault/172.17.0.0/16, Address:172.17.0.2 Sequence:App: ipam/default/data, ID: LocalDefault/172.17.0.0/16, DBIndex: 0x0, Bits: 65536, Unselected: 65529, Sequence: (0xfa000000, 1)->(0x0, 2046)->(0x1, 1)->end Curr:2022020-12-04T04:31:32.308Z dockerd Releasing addresses for endpoint test-5's interface on network bridge2020-12-04T04:31:32.308Z dockerd ReleaseAddress(LocalDefault/172.17.0.0/16, 172.17.0.6)2020-12-04T04:31:32.308Z dockerd Released address PoolID:LocalDefault/172.17.0.0/16, Address:172.17.0.6 Sequence:App: ipam/default/data, ID: LocalDefault/172.17.0.0/16, DBIndex: 0x0, Bits: 65536, Unselected: 65530, Sequence: (0xda000000, 1)->(0x0, 2046)->(0x1, 1)->end Curr:2022020-12-04T04:31:32.308Z dockerd Releasing addresses for endpoint test-3's interface on network bridge2020-12-04T04:31:32.308Z dockerd ReleaseAddress(LocalDefault/172.17.0.0/16, 172.17.0.4)2020-12-04T04:31:32.308Z dockerd Released address PoolID:LocalDefault/172.17.0.0/16, Address:172.17.0.4 Sequence:App: ipam/default/data, ID: LocalDefault/172.17.0.0/16, DBIndex: 0x0, Bits: 65536, Unselected: 65531, Sequence: (0xd8000000, 1)->(0x0, 2046)->(0x1, 1)->end Curr:2022020-12-04T04:31:32.308Z dockerd Releasing addresses for endpoint test-2's interface on network bridge2020-12-04T04:31:32.308Z dockerd ReleaseAddress(LocalDefault/172.17.0.0/16, 172.17.0.3)2020-12-04T04:31:32.308Z dockerd Released address PoolID:LocalDefault/172.17.0.0/16, Address:172.17.0.3 Sequence:App: ipam/default/data, ID: LocalDefault/172.17.0.0/16, DBIndex: 0x0, Bits: 65536, Unselected: 65532, Sequence: (0xd0000000, 1)->(0x0, 2046)->(0x1, 1)->end Curr:202
这些日志并不能全面说明 dockerd 所做的一切工作,但是它让人感觉 dockerd 可能花费了大量时间来释放网络地址。
到了这个时候,我决定要开始挖掘 docker 引擎的源代码,创建自己的 dockerd 版本,并添加一些额外的日志记录。
首先找出处理容器终止请求的代码路径。我增加了一些额外的日志信息,这些信息包含不同长度的时间,最后我发现这些时间都用在:
该引擎会将 SIGKILL 发送到容器,然后等待容器停止运行才对 HTTP 请求作出响应。(来源)。
<-container.Wait(context.Background(), containerpkg.WaitConditionNotRunning)container.Wait 函数返回一个通道,该通道接收容器的退出代码和任何错误。不幸的是,要获得退出代码和错误,就必须获得内部容器结构的锁。(来源)
...go func() {select {case <-ctx.Done():// Context timeout or cancellation.resultC <- StateStatus{exitCode: -1,err: ctx.Err(),}returncase <-waitStop:case <-waitRemove:}s.Lock() // <-- Time is spent waiting hereresult := StateStatus{exitCode: s.ExitCode(),err: s.Err(),}s.Unlock()resultC <- result}()return resultC...事实证明,在清理网络资源时持有这个容器锁,而上面的 s.Lock() 结束了长时间的等待。这种情况发生在 handleContainerExit 里面。容器锁在该函数的持续时间内保持不变。这个函数调用容器的 Cleanup 方法,以释放网络资源。
那么为什么清理网络资源需要这么长时间呢?网络资源是通过 netlink 来处理的。netlink 是用来在用户和内核空间进程之间进行通信的,在这种情况下,使用 netlink 与内核空间进程进行通信,配置网络接口。不幸的是,netlink 是通过串行接口工作的,而释放每个容器地址的所有操作都受到 netlink 瓶颈的限制。
这里的情况开始让人觉得有些绝望。我们似乎没有什么办法可以改变,以逃避等待网络资源被清理的命运。但我们或许可以完全绕过 Docker 而杀死容器。
对我们来说,我们可以杀死容器,而不必等到网络资源被清理。关键是容器不会产生任何副作用。举例来说,我们不想让容器获得更多的文件系统快照。
我采用的解决方案是通过直接杀死容器的 pid 来绕过 docker。在容器启动之后, conman 记录下容器的 pid,然后在需要终止时向容器发送 SIGKILL。因为容器形成了 pid 命名空间,所以容器 /pid 命名空间中的所有其他进程在容器的 pid 终止时也终止。
来自 pid_namespaces 手册页:
当 PID 命名空间的 “init” 进程终止时,内核就会通过 SIGKILL 信号终止该命名空间的所有进程。
考虑到这一点,我们有理由相信,在将 SIGKILL 发送到容器之后,它不再产生任何副作用。
实施此更改后,在关机期间,REPL 的控制权将在数秒内被放弃。与之前的 30 多秒相比,这是一个巨大的改进,会话连接错误率从大约 3% 降低到 0.5% 以下。另外,会话启动时间的第 99 个百分比从约 2 分钟降至约 15 秒。
总结一下,我们发现,虚拟机关机缓慢会导致 REPL 卡住和糟糕的用户体验。经过研究,我们发现 Docker 花了超过 30 秒的时间在虚拟机上杀死所有容器。我们通过绕过 Docker 和自己杀死容器来解决这个问题。这样就减少了 REPL 卡住的次数,加速了会话启动时间。但愿这会给 Replit 带来更加流畅的体验!
原文链接:https://blog.repl.it/killing-containers-at-scale
关注「开源Linux」加星标,提升IT技能
