
HBase 实践 | HBase 在人资数据预处理平台中的实践

Tech
导读

物流人资数据预处理平台,负责接收一线几十万员工不同条线的工作量,每日数据量约2000w,系统负责加工转换并提供数据查询的同时,还需保证查询性能,以及修改单个业务量功能。本文通过HBase在物流人资数据预处理平台中实践,讲解HBase集群如何协同工作,并概述读取数据以及存储数据的原理,以及使用HBase注意事项。
人资绩效数据预处理平台,负责接收所有上游业务量数据(工作内容数据),用于一线几十万员工薪资计算。平台单日接收量可达2000w,月度数据超5亿。目前已有超过100种业务量接入,各业务量具有字段不一,数据格式不一致等特点。同时平台还需对业务量更新以及高性能查询有较高要求。通常技术上可以选择OSS、MySql数据库、ES,CK等方案。其中OSS云存储方案,高并发下查询性能以及单业务量字段更新无法满足。MySql数据库很难处理超过上亿数据量。而ES存储与查询都可以满足,对单个字段更新不够友好,且ES成本较高。CK更适合做OLAP。
基于以上背景,技术选型时,充分考虑到人资数据预处理平台的特性,数据量大、数据非结构化、高性能、开源稳定等要求,选型HBase。
HBase是一个分布式的、面向列的开源数据库,它是一个适合于非结构化数据存储的数据库,它在Hadoop之上提供了类似于Bigtable的能力,同时又是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,同时HBase技术可在廉价PC Server上搭建起大规模结构化存储集群,性价比非常高。
京东内部提供JDNosql即通过HBase搭建,参考文档http://doc.nosql.jd.com/
对象存储:不少的头条类、新闻类的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中。
时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求。
时空数据:不少车联网企业,数据都是存在HBase之中。
消息/订单:Facebook用HBase存储在线消息,每天数据量近百亿,每月数据量250 ~ 300T, HBase读写比基本在1:1,吞吐量150w qps。
Feeds流:典型的应用如微信朋友圈。
命名空间:类比MySql中数据库库名。
表名:类比MySql中表名。
列族:一组列的集合为列族。列族下的列可以N个。
列名称:存在列族下的单个列,列族下的名称。
RowKey:HBase存储采用 key-value方式,Key即为RowKey,所有的修改查询等操作只能基于RowKey,必须唯一。
HBase由三种类型的服务器以主从模式构成。
Region Server:负责数据的读写服务,用户通过与Region Server交互来实现对数据的访问。每个Region服务器中包含最多1000个Region,每个Region里面包含了StartKey到EndKey的一个区间数据。
HBase HMaster:分组分配Region和操作DDL,在集群处于数据恢复或者动态调整时,监控所有Region Server的状态。
ZooKeeper:负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及HMaster的选举等)。
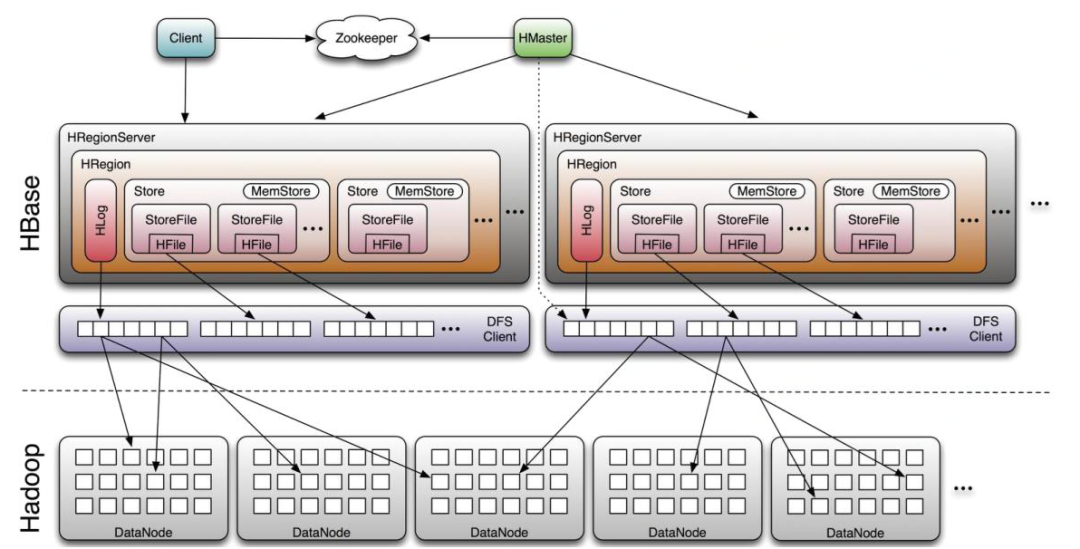
图一 HBase整体架构图
Region Server,会通过心跳方式与ZooKeeper保持连接,并创建一个临时节点,当无法监听到心跳时,会通知ZooKeeper,同时删除临时节点,而HMaser会通过ZooKeeper得到Region Server服务器的状态,当服务器下线时,会进行数据恢复、容灾等操作。HMaster同样会同ZooKeeper保持心跳,用于监控HMaster状态,当HMaster下线时,会通过选举方式,将HMaster集群中的一台机器设置成Active,其他机器设置成InActive状态,来保证整个集群的高可用性。
数据读取过程——
客户端发起请求,从Zooeeper中获取一个叫MetaTable的元数据。
注:如果本地有缓存会优先读取本地缓存。
客户端通过MetaTable,得知RowKey所有在的Region Server服务器得到Region位置。
客户端优先从Region中的BlockCache(读取缓存)中获取数据,如果BlockCache中不存在,会通过MemStore(写入缓存)中获取数据,如果还不存在,会通过HFile中读取,并将数据返回给客户端。
读取HFile时,会通过尾部指针中布隆过滤区域与时间区域,可以快读定位RowKey是否在HFile文件当中。
HFile读取后,会将多级索引加载在BlockCache中,用于读加速。
数据写入过程——
HBase客户端发起Put请求时,会先将数据写入预写日志(WAL)中,将操作记录写入WAL末尾。WAL用于Region Server服务器崩溃时,恢复MemStore中数据,WAL存储在Hadoop的HDFS中。
数据在写入Wal后,会将数据先写入Region Server下Region中MemStore中(写入缓存,内存级别)。
在写入MemStore成功后,反馈给客户端本次写入已经完成。
当MemStore达到一定量级时,会通过Flush方式,生成HFile,存入Hadoop的HDFS中。HFile在生成前,会在内存中对Key进行升序排序,将排序好的数据顺序写入HFile中,并在HFile中生成一个多级索引,还有一个尾部指针。
HBase主要特点(人资绩效数据预处理平台实践适配的特点)——
HBase为分布式列式数据库,可以横向进行扩展,解决系统存储数据超2000w的问题。
HBase为列式存储数据库,一个列族下可以支持成百上千列,解决系统对非结构化数据存储与单个数据列更新等问题。
HBase具备毫秒级读写,随机读写,实时读写,无线存储拓展,数据高可用,多级缓存,服务不中断,主备自动切换,异地双活等特性,解决系统高可用等问题。
HBase存储自带多种压缩算法,降低数据存储量。
HBase数据支持多版本,对修改的数据可以支持多个版本数据。
HBase自带数据有效期功能,对于冷数据可以定期删除。
HBase优点——
列可以动态增加,并且列为空就不存储数据,节省存储空间。
HBase自动切分数据,使得数据存储自动具有水平扩展能力。
HBase可以提供高并发读写操作的支持。
HBase缺点——
不能支持条件查询,只支持按照RowKey来查询。
不适合于大范围扫描查询。
不支持事务。
HBase注意事项——
1.数据热点问题以及解决方法
HBase创建表时会使用多个Region,如果使用不正确会导致所有数据写入同一个Region服务器下,造成数据热点问题,解决数据热点问题一共需要注意两个方面。
第一方面是建表时(预分区建表),要根据自己的RowKey特性选择正确的分区规则,人资数据预处理平台采用 HexStringSplit这种方式。
第二方面是RowKey的设计,需要保证唯一的同时尽量散列。人资侧采用雪花算法生成唯一ID,对唯一ID高位进行MD5转16进制加上反转后的唯一ID作为RowKey,可以将数据均匀的分散到多个Region中,避免数据热点问题。
2.HBase批量获取数据大小建议
对HBase进行批量查询时,将批量数据控制到100KB以内,超过后性能下降非常明显。
3.单行数据大小限制
单行不建议超过400KB,KV存储系统非对象存储系统。如果Value过大会导致处理性能直线下降。
4.Scan使用
Scan属于不稳定接口,如扫描范围过大或设置不准会导致性能下降,使用时必须设置startKey与endKey,同时start与end之间不要超过100条数据。
5.HBase连接事项
HBase每次连接耗时较高,构建Connect对象时,需要在程序启动时进行,避免使用时创建。
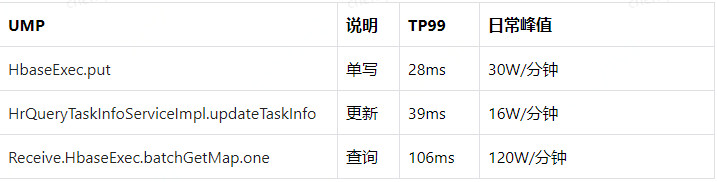
图2 HBase在人资绩效数据预处理平台中的性能参考
HBase写入最近30天TP99
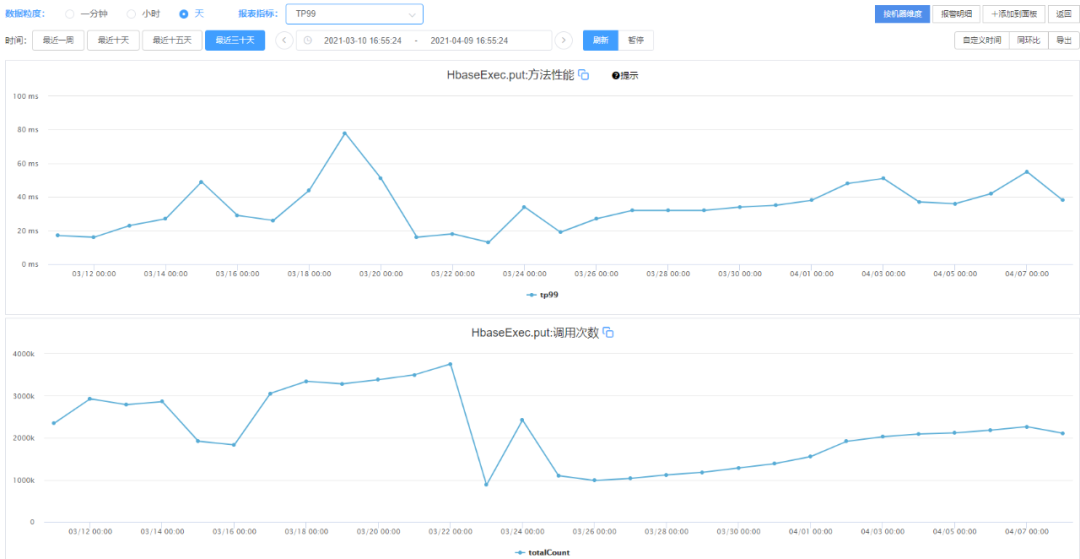
图3 HBase写入最近30天TP99
HBase更新性能
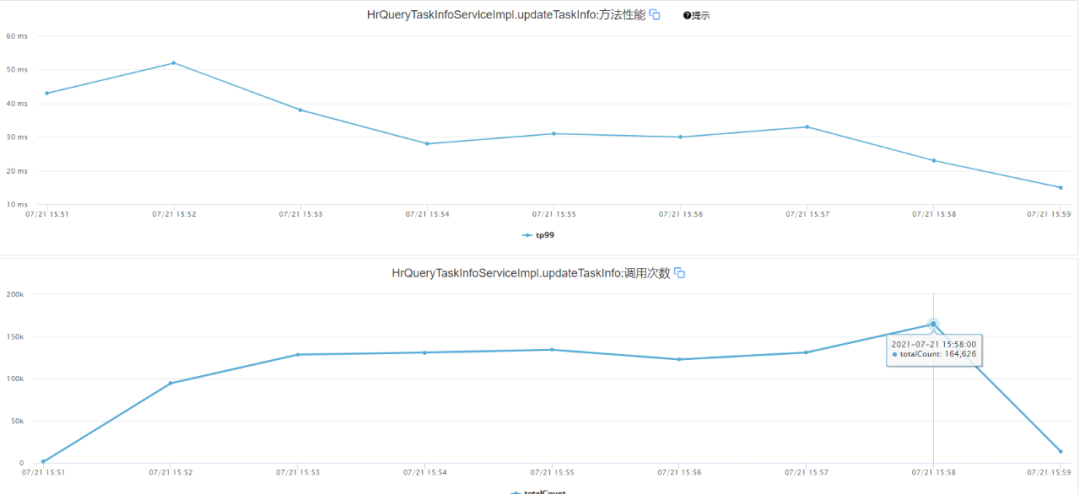
图4 HBase更新性能
HBase查询速度TP99

图5 HBase查询速度TP99

KDD 2021:基于Seq2Seq多任务学习的路网轨迹恢复
