这里是码农充电第一站,回复“666”,获取一份专属大礼包
线上故障主要会包括 CPU、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。同时例如 jstack、jmap 等工具也是不囿于一个方面的问题的,基本上出问题就是 df、free、top 三连,然后依次 jstack、jmap 伺候,具体问题具体分析即可。
CPU
一般来讲我们首先会排查 CPU 方面的问题。CPU 异常往往还是比较好定位的。原因包括业务逻辑问题(死循环)、频繁 gc 以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用 jstack 来分析对应的堆栈情况。我们先用 ps 命令找到对应进程的 pid(如果你有好几个目标进程,可以先用 top 看一下哪个占用比较高)。接着用top -H -p pid来找到 CPU 使用率比较高的一些线程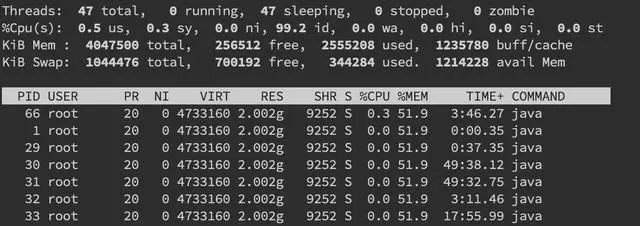
然后将占用最高的 pid 转换为 16 进制printf '%x\n' pid得到 nid
接着直接在 jstack 中找到相应的堆栈信息jstack pid |grep 'nid' -C5 –color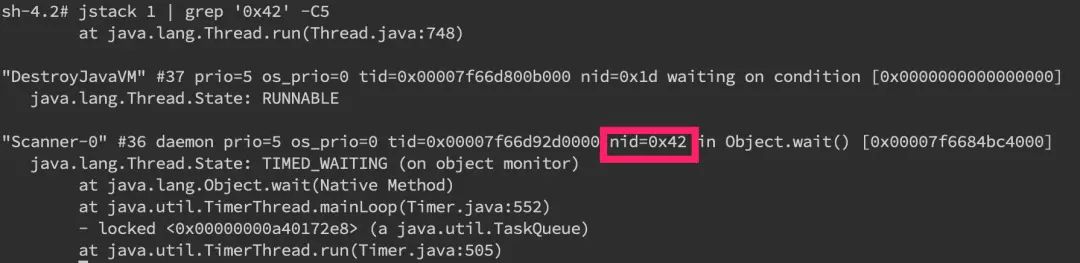
可以看到我们已经找到了 nid 为 0x42 的堆栈信息,接着只要仔细分析一番即可。当然更常见的是我们对整个 jstack 文件进行分析,通常我们会比较关注 WAITING 和 TIMED_WAITING 的部分,BLOCKED 就不用说了。我们可以使用命令cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c来对 jstack 的状态有一个整体的把握,如果 WAITING 之类的特别多,那么多半是有问题啦。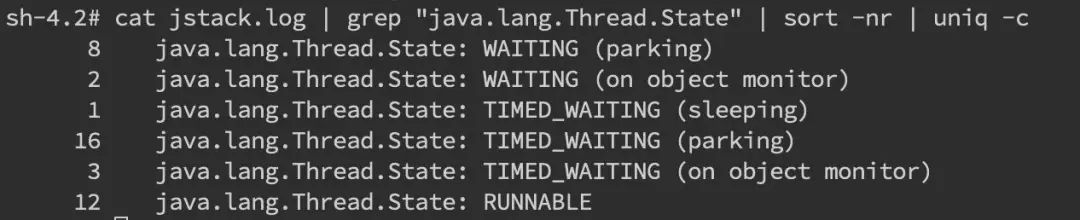
当然我们还是会使用 jstack 来分析问题,但有时候我们可以先确定下 gc 是不是太频繁,使用jstat -gc pid 1000命令来对 gc 分代变化情况进行观察,1000 表示采样间隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU 分别代表两个 Survivor 区、Eden 区、老年代、元数据区的容量和使用量。YGC/YGT、FGC/FGCT、GCT 则代表 YoungGc、FullGc 的耗时和次数以及总耗时。如果看到 gc 比较频繁,再针对 gc 方面做进一步分析,具体可以参考一下 gc 章节的描述。
针对频繁上下文问题,我们可以使用vmstat命令来进行查看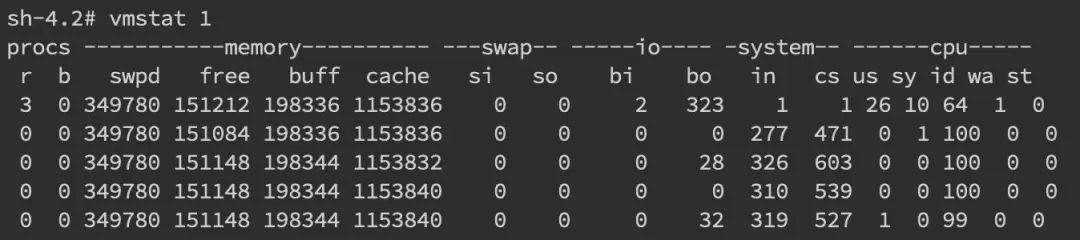
cs(context switch)一列则代表了上下文切换的次数。如果我们希望对特定的 pid 进行监控那么可以使用 pidstat -w pid命令,cswch 和 nvcswch 表示自愿及非自愿切换。
磁盘
磁盘问题和 CPU 一样是属于比较基础的。首先是磁盘空间方面,我们直接使用df -hl来查看文件系统状态
更多时候,磁盘问题还是性能上的问题。我们可以通过 iostatiostat -d -k -x来进行分析
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。另外我们还需要知道是哪个进程在进行读写,一般来说开发自己心里有数,或者用 iotop 命令来进行定位文件读写的来源。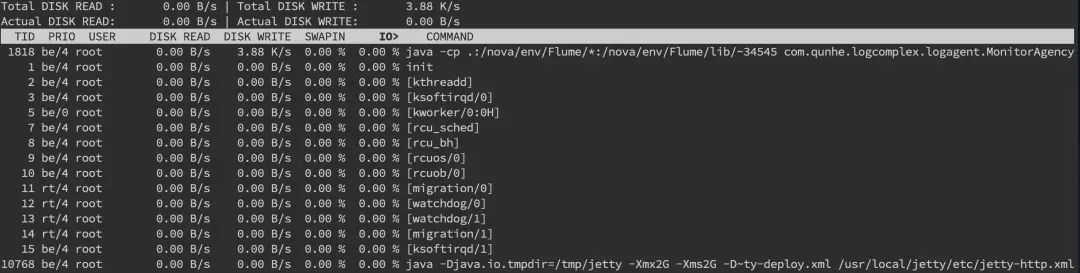
不过这边拿到的是 tid,我们要转换成 pid,可以通过 readlink 来找到 pidreadlink -f /proc/*/task/tid/../..。
找到 pid 之后就可以看这个进程具体的读写情况cat /proc/pid/io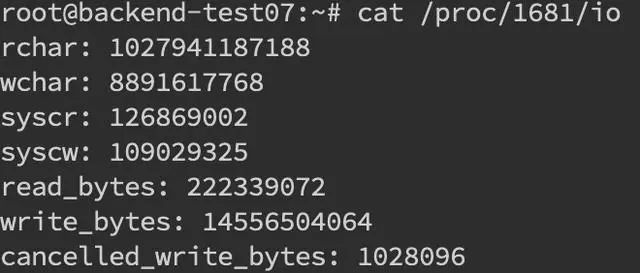
我们还可以通过 lsof 命令来确定具体的文件读写情况lsof -p pid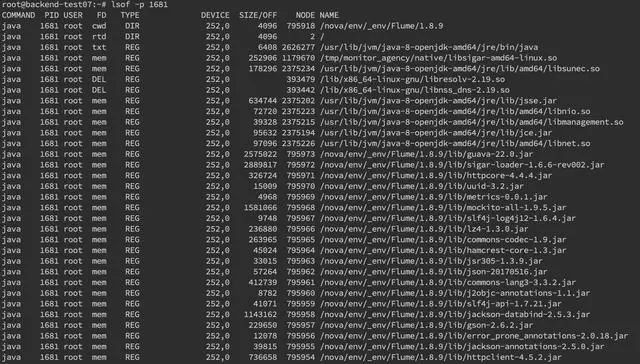
内存
内存问题排查起来相对比 CPU 麻烦一些,场景也比较多。主要包括 OOM、GC 问题和堆外内存。一般来讲,我们会先用free命令先来检查一发内存的各种情况。
内存问题大多还都是堆内内存问题。表象上主要分为 OOM 和 Stack Overflo。JMV 中的内存不足,OOM 大致可以分为以下几种:Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread这个意思是没有足够的内存空间给线程分配 Java 栈,基本上还是线程池代码写的有问题,比如说忘记 shutdown,所以说应该首先从代码层面来寻找问题,使用 jstack 或者 jmap。如果一切都正常,JVM 方面可以通过指定Xss来减少单个 thread stack 的大小。另外也可以在系统层面,可以通过修改/etc/security/limits.confnofile 和 nproc 来增大 os 对线程的限制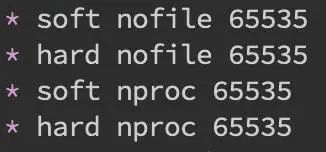
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space这个意思是堆的内存占用已经达到-Xmx 设置的最大值,应该是最常见的 OOM 错误了。解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过 jstack 和 jmap 去定位问题。如果说一切都正常,才需要通过调整Xmx的值来扩大内存。Caused by: java.lang.OutOfMemoryError: Meta space这个意思是元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,排查思路和上面的一致,参数方面可以通过XX:MaxPermSize来进行调整(这里就不说 1.8 以前的永久代了)。Exception in thread "main" java.lang.StackOverflowError表示线程栈需要的内存大于 Xss 值,同样也是先进行排查,参数方面通过Xss来调整,但调整的太大可能又会引起 OOM。上述关于 OOM 和 Stack Overflo 的代码排查方面,我们一般使用 JMAPjmap -dump:format=b,file=filename pid来导出 dump 文件
通过 mat(Eclipse Memory Analysis Tools)导入 dump 文件进行分析,内存泄漏问题一般我们直接选 Leak Suspects 即可,mat 给出了内存泄漏的建议。另外也可以选择 Top Consumers 来查看最大对象报告。和线程相关的问题可以选择 thread overview 进行分析。除此之外就是选择 Histogram 类概览来自己慢慢分析,大家可以搜搜 mat 的相关教程。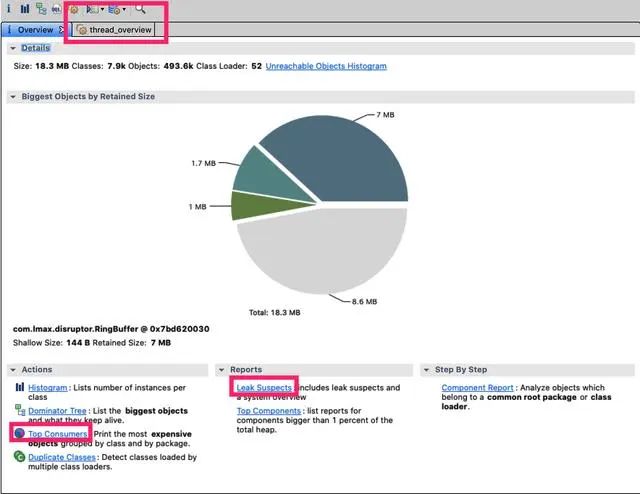
日常开发中,代码产生内存泄漏是比较常见的事,并且比较隐蔽,需要开发者更加关注细节。比如说每次请求都 new 对象,导致大量重复创建对象;进行文件流操作但未正确关闭;手动不当触发 gc;ByteBuffer 缓存分配不合理等都会造成代码 OOM。另一方面,我们可以在启动参数中指定-XX:+HeapDumpOnOutOfMemoryError来保存 OOM 时的 dump 文件。gc 问题除了影响 CPU 也会影响内存,排查思路也是一致的。一般先使用 jstat 来查看分代变化情况,比如 youngGC 或者 fullGC 次数是不是太多呀;EU、OU 等指标增长是不是异常呀等。线程的话太多而且不被及时 gc 也会引发 oom,大部分就是之前说的unable to create new native thread。除了 jstack 细细分析 dump 文件外,我们一般先会看下总体线程,通过pstreee -p pid |wc -l。
或者直接通过查看/proc/pid/task的数量即为线程数量。
如果碰到堆外内存溢出,那可真是太不幸了。首先堆外内存溢出表现就是物理常驻内存增长快,报错的话视使用方式都不确定,如果由于使用 Netty 导致的,那错误日志里可能会出现OutOfDirectMemoryError错误,如果直接是 DirectByteBuffer,那会报OutOfMemoryError: Direct buffer memory。堆外内存溢出往往是和 NIO 的使用相关,一般我们先通过 pmap 来查看下进程占用的内存情况pmap -x pid | sort -rn -k3 | head -30,这段意思是查看对应 pid 倒序前 30 大的内存段。这边可以再一段时间后再跑一次命令看看内存增长情况,或者和正常机器比较可疑的内存段在哪里。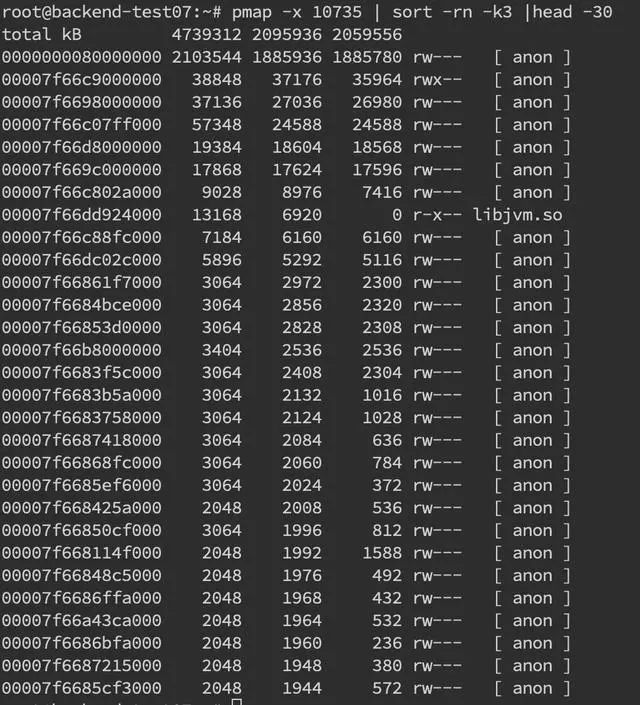
我们如果确定有可疑的内存端,需要通过 gdb 来分析gdb --batch --pid {pid} -ex "dump memory filename.dump {内存起始地址} {内存起始地址+内存块大小}"
获取 dump 文件后可用 heaxdump 进行查看hexdump -C filename | less,不过大多数看到的都是二进制乱码。NMT 是 Java7U40 引入的 HotSpot 新特性,配合 jcmd 命令我们就可以看到具体内存组成了。需要在启动参数中加入 -XX:NativeMemoryTracking=summary 或者 -XX:NativeMemoryTracking=detail,会有略微性能损耗。一般对于堆外内存缓慢增长直到爆炸的情况来说,可以先设一个基线jcmd pid VM.native_memory baseline。
然后等放一段时间后再去看看内存增长的情况,通过jcmd pid VM.native_memory detail.diff(summary.diff)做一下 summary 或者 detail 级别的 diff。

可以看到 jcmd 分析出来的内存十分详细,包括堆内、线程以及 gc(所以上述其他内存异常其实都可以用 nmt 来分析),这边堆外内存我们重点关注 Internal 的内存增长,如果增长十分明显的话那就是有问题了。detail 级别的话还会有具体内存段的增长情况,如下图。
此外在系统层面,我们还可以使用 strace 命令来监控内存分配 strace -f -e "brk,mmap,munmap" -p pid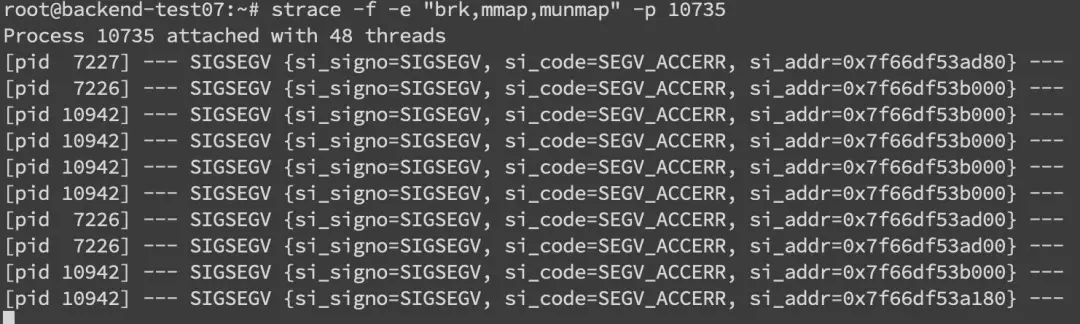
不过其实上面那些操作也很难定位到具体的问题点,关键还是要看错误日志栈,找到可疑的对象,搞清楚它的回收机制,然后去分析对应的对象。比如 DirectByteBuffer 分配内存的话,是需要 full GC 或者手动 system.gc 来进行回收的(所以最好不要使用-XX:+DisableExplicitGC)。那么其实我们可以跟踪一下 DirectByteBuffer 对象的内存情况,通过jmap -histo:live pid手动触发 fullGC 来看看堆外内存有没有被回收。如果被回收了,那么大概率是堆外内存本身分配的太小了,通过-XX:MaxDirectMemorySize进行调整。如果没有什么变化,那就要使用 jmap 去分析那些不能被 gc 的对象,以及和 DirectByteBuffer 之间的引用关系了。GC 问题
堆内内存泄漏总是和 GC 异常相伴。不过 GC 问题不只是和内存问题相关,还有可能引起 CPU 负载、网络问题等系列并发症,只是相对来说和内存联系紧密些,所以我们在此单独总结一下 GC 相关问题。我们在 CPU 章介绍了使用 jstat 来获取当前 GC 分代变化信息。而更多时候,我们是通过 GC 日志来排查问题的,在启动参数中加上-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps来开启 GC 日志。常见的 Young GC、Full GC 日志含义在此就不做赘述了。针对 gc 日志,我们就能大致推断出 youngGC 与 fullGC 是否过于频繁或者耗时过长,从而对症下药。我们下面将对 G1 垃圾收集器来做分析,这边也建议大家使用 G1-XX:+UseG1GC。youngGC 频繁一般是短周期小对象较多,先考虑是不是 Eden 区/新生代设置的太小了,看能否通过调整-Xmn、-XX:SurvivorRatio 等参数设置来解决问题。如果参数正常,但是 young gc 频率还是太高,就需要使用 Jmap 和 MAT 对 dump 文件进行进一步排查了。耗时过长问题就要看 GC 日志里耗时耗在哪一块了。以 G1 日志为例,可以关注 Root Scanning、Object Copy、Ref Proc 等阶段。Ref Proc 耗时长,就要注意引用相关的对象。Root Scanning 耗时长,就要注意线程数、跨代引用。Object Copy 则需要关注对象生存周期。而且耗时分析它需要横向比较,就是和其他项目或者正常时间段的耗时比较。比如说图中的 Root Scanning 和正常时间段比增长较多,那就是起的线程太多了。
G1 中更多的还是 mixedGC,但 mixedGC 可以和 youngGC 思路一样去排查。触发 fullGC 了一般都会有问题,G1 会退化使用 Serial 收集器来完成垃圾的清理工作,暂停时长达到秒级别,可以说是半跪了。fullGC 的原因可能包括以下这些,以及参数调整方面的一些思路:并发阶段失败:在并发标记阶段,MixGC 之前老年代就被填满了,那么这时候 G1 就会放弃标记周期。这种情况,可能就需要增加堆大小,或者调整并发标记线程数-XX:ConcGCThreads。
晋升失败:在 GC 的时候没有足够的内存供存活/晋升对象使用,所以触发了 Full GC。这时候可以通过-XX:G1ReservePercent来增加预留内存百分比,减少-XX:InitiatingHeapOccupancyPercent来提前启动标记,-XX:ConcGCThreads来增加标记线程数也是可以的。
大对象分配失败:大对象找不到合适的 region 空间进行分配,就会进行 fullGC,这种情况下可以增大内存或者增大-XX:G1HeapRegionSize。
程序主动执行 System.gc():不要随便写就对了。
另外,我们可以在启动参数中配置-XX:HeapDumpPath=/xxx/dump.hprof来 dump fullGC 相关的文件,并通过 jinfo 来进行 gc 前后的 dumpjinfo -flag +HeapDumpBeforeFullGC pidjinfo -flag +HeapDumpAfterFullGC pidjinfo -flag +HeapDumpBeforeFullGC pidjinfo -flag +HeapDumpAfterFullGC pid这样得到 2 份 dump 文件,对比后主要关注被 gc 掉的问题对象来定位问题。网络
涉及到网络层面的问题一般都比较复杂,场景多,定位难,成为了大多数开发的噩梦,应该是最复杂的了。这里会举一些例子,并从 tcp 层、应用层以及工具的使用等方面进行阐述。超时错误大部分处在应用层面,所以这块着重理解概念。超时大体可以分为连接超时和读写超时,某些使用连接池的客户端框架还会存在获取连接超时和空闲连接清理超时。读写超时。readTimeout/writeTimeout,有些框架叫做 so_timeout 或者 socketTimeout,均指的是数据读写超时。注意这边的超时大部分是指逻辑上的超时。soa 的超时指的也是读超时。读写超时一般都只针对客户端设置。
连接超时。connectionTimeout,客户端通常指与服务端建立连接的最大时间。服务端这边 connectionTimeout 就有些五花八门了,Jetty 中表示空闲连接清理时间,Tomcat 则表示连接维持的最大时间。
其他。包括连接获取超时 connectionAcquireTimeout 和空闲连接清理超时 idleConnectionTimeout。多用于使用连接池或队列的客户端或服务端框架。
我们在设置各种超时时间中,需要确认的是尽量保持客户端的超时小于服务端的超时,以保证连接正常结束。在实际开发中,我们关心最多的应该是接口的读写超时了。如何设置合理的接口超时是一个问题。如果接口超时设置的过长,那么有可能会过多地占用服务端的 tcp 连接。而如果接口设置的过短,那么接口超时就会非常频繁。服务端接口明明 rt 降低,但客户端仍然一直超时又是另一个问题。这个问题其实很简单,客户端到服务端的链路包括网络传输、排队以及服务处理等,每一个环节都可能是耗时的原因。tcp 队列溢出是个相对底层的错误,它可能会造成超时、rst 等更表层的错误。因此错误也更隐蔽,所以我们单独说一说。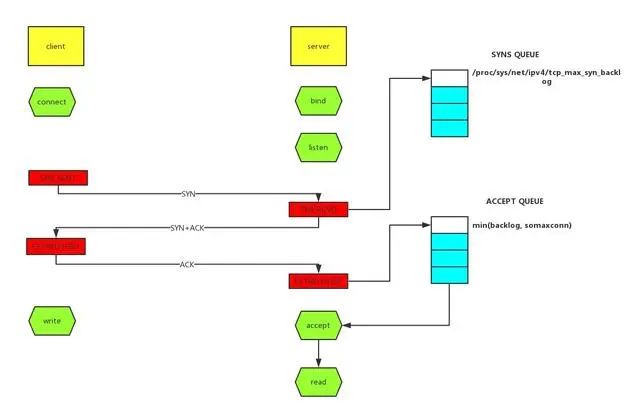
如上图所示,这里有两个队列:syns queue(半连接队列)、accept queue(全连接队列)。三次握手,在 server 收到 client 的 syn 后,把消息放到 syns queue,回复 syn+ack 给 client,server 收到 client 的 ack,如果这时 accept queue 没满,那就从 syns queue 拿出暂存的信息放入 accept queue 中,否则按 tcp_abort_on_overflow 指示的执行。tcp_abort_on_overflow 0 表示如果三次握手第三步的时候 accept queue 满了那么 server 扔掉 client 发过来的 ack。tcp_abort_on_overflow 1 则表示第三步的时候如果全连接队列满了,server 发送一个 rst 包给 client,表示废掉这个握手过程和这个连接,意味着日志里可能会有很多connection reset / connection reset by peer。那么在实际开发中,我们怎么能快速定位到 tcp 队列溢出呢?netstat 命令,执行 netstat -s | egrep "listen|LISTEN"
如上图所示,overflowed 表示全连接队列溢出的次数,sockets dropped 表示半连接队列溢出的次数。
上面看到 Send-Q 表示第三列的 listen 端口上的全连接队列最大为 5,第一列 Recv-Q 为全连接队列当前使用了多少。全连接队列的大小取决于 min(backlog, somaxconn)。backlog 是在 socket 创建的时候传入的,somaxconn 是一个 os 级别的系统参数。而半连接队列的大小取决于 max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。在日常开发中,我们往往使用 servlet 容器作为服务端,所以我们有时候也需要关注容器的连接队列大小。在 Tomcat 中 backlog 叫做acceptCount,在 Jetty 里面则是acceptQueueSize。RST 包表示连接重置,用于关闭一些无用的连接,通常表示异常关闭,区别于四次挥手。在实际开发中,我们往往会看到connection reset / connection reset by peer错误,这种情况就是 RST 包导致的。如果像不存在的端口发出建立连接 SYN 请求,那么服务端发现自己并没有这个端口则会直接返回一个 RST 报文,用于中断连接。一般来说,正常的连接关闭都是需要通过 FIN 报文实现,然而我们也可以用 RST 报文来代替 FIN,表示直接终止连接。实际开发中,可设置 SO_LINGER 数值来控制,这种往往是故意的,来跳过 TIMED_WAIT,提供交互效率,不闲就慎用。客户端或服务端有一边发生了异常,该方向对端发送 RST 以告知关闭连接我们上面讲的 tcp 队列溢出发送 RST 包其实也是属于这一种。这种往往是由于某些原因,一方无法再能正常处理请求连接了(比如程序崩了,队列满了),从而告知另一方关闭连接。比如,一方机器由于网络实在太差 TCP 报文失踪了,另一方关闭了该连接,然后过了许久收到了之前失踪的 TCP 报文,但由于对应的 TCP 连接已不存在,那么会直接发一个 RST 包以便开启新的连接。一方长期未收到另一方的确认报文,在一定时间或重传次数后发出 RST 报文这种大多也和网络环境相关了,网络环境差可能会导致更多的 RST 报文。之前说过 RST 报文多会导致程序报错,在一个已关闭的连接上读操作会报connection reset,而在一个已关闭的连接上写操作则会报connection reset by peer。通常我们可能还会看到broken pipe错误,这是管道层面的错误,表示对已关闭的管道进行读写,往往是在收到 RST,报出connection reset错后继续读写数据报的错,这个在 glibc 源码注释中也有介绍。我们在排查故障时候怎么确定有 RST 包的存在呢?当然是使用 tcpdump 命令进行抓包,并使用 wireshark 进行简单分析了。tcpdump -i en0 tcp -w xxx.cap,en0 表示监听的网卡。
接下来我们通过 wireshark 打开抓到的包,可能就能看到如下图所示,红色的就表示 RST 包了。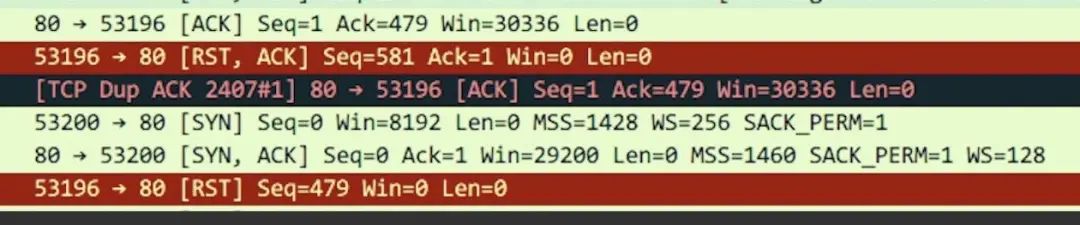
TIME_WAIT 和 CLOSE_WAIT 是啥意思相信大家都知道。在线上时,我们可以直接用命令netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'来查看 time-wait 和 close_wait 的数量用 ss 命令会更快ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}'
time_wait 的存在一是为了丢失的数据包被后面连接复用,二是为了在 2MSL 的时间范围内正常关闭连接。它的存在其实会大大减少 RST 包的出现。过多的 time_wait 在短连接频繁的场景比较容易出现。这种情况可以在服务端做一些内核参数调优:#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭net.ipv4.tcp_tw_reuse = 1#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭net.ipv4.tcp_tw_recycle = 1#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭net.ipv4.tcp_tw_reuse = 1#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭net.ipv4.tcp_tw_recycle = 1当然我们不要忘记在 NAT 环境下因为时间戳错乱导致数据包被拒绝的坑了,另外的办法就是改小tcp_max_tw_buckets,超过这个数的 time_wait 都会被干掉,不过这也会导致报time wait bucket table overflow的错。close_wait 往往都是因为应用程序写的有问题,没有在 ACK 后再次发起 FIN 报文。close_wait 出现的概率甚至比 time_wait 要更高,后果也更严重。往往是由于某个地方阻塞住了,没有正常关闭连接,从而渐渐地消耗完所有的线程。想要定位这类问题,最好是通过 jstack 来分析线程堆栈来排查问题,具体可参考上述章节。这里仅举一个例子。开发同学说应用上线后 CLOSE_WAIT 就一直增多,直到挂掉为止,jstack 后找到比较可疑的堆栈是大部分线程都卡在了countdownlatch.await方法,找开发同学了解后得知使用了多线程但是确没有 catch 异常,修改后发现异常仅仅是最简单的升级 sdk 后常出现的class not found。

