
彻底搞懂容器技术的基石: cgroup
大家好,我是张晋涛。
目前我们所提到的容器技术、虚拟化技术(不论何种抽象层次下的虚拟化技术)都能做到资源层面上的隔离和限制。
对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
我们先对这两项技术的作用做个概括:
cgroup 的主要作用:管理资源的分配、限制; namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源;
本篇,我们重点来聊 cgroup 。
为什么要关注 cgroup & namespace
云原生/容器技术的井喷式增长
自 1979年,Unix 版本7 在开发过程中引入 Chroot Jail 以及 Chroot 系统调用开始,直到 2013 年开源出的 Docker,2014 年开源出来的 Kubernetes,直到现在的云原生生态的火热。容器技术已经逐步成为主流的基础技术之一。
在越来越多的公司、个人选择了云服务/容器技术后,资源的分配和隔离,以及安全性变成了人们关注及讨论的热点话题。
其实容器技术使用起来并不难,但要真正把它用好,大规模的在生产环境中使用, 那我们还是需要掌握其核心的。
以下是容器技术&云原生生态的大致发展历程:

图 1 ,容器技术发展历程
从图中,我们可以看到容器技术、云原生生态的发展轨迹。容器技术其实很早就出现了,但为何在 Docker 出现后才开始有了较为显著的发展?早期的 chroot 、 Linux VServer 又有哪些问题呢?
Chroot 带来的安全性问题
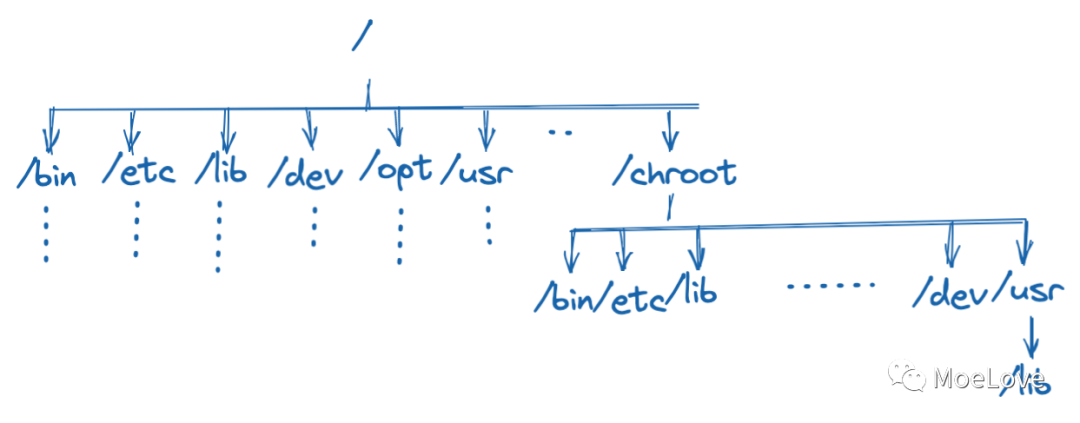
图 2 ,chroot 示例
Chroot 可以将进程及其子进程与操作系统的其余部分隔离开来。但是,对于 root process ,却可以任意退出 chroot。
package main
import (
"log"
"os"
"syscall"
)
func getWd() (path string) {
path, err := os.Getwd()
if err != nil {
log.Println(err)
}
log.Println(path)
return
}
func main() {
RealRoot, err := os.Open("/")
defer RealRoot.Close()
if err != nil {
log.Fatalf("[ Error ] - /: %v\n", err)
}
path := getWd()
err = syscall.Chroot(path)
if err != nil {
log.Fatalf("[ Error ] - chroot: %v\n", err)
}
getWd()
err = RealRoot.Chdir()
if err != nil {
log.Fatalf("[ Error ] - chdir(): %v", err)
}
getWd()
err = syscall.Chroot(".")
if err != nil {
log.Fatalf("[ Error ] - chroot back: %v", err)
}
getWd()
}
分别以普通用户和 sudo 的方式运行:
➜ chroot go run main.go
2021/11/18 00:46:21 /tmp/chroot
2021/11/18 00:46:21 [ Error ] - chroot: operation not permitted
exit status 1
➜ chroot sudo go run main.go
2021/11/18 00:46:25 /tmp/chroot
2021/11/18 00:46:25 /
2021/11/18 00:46:25 (unreachable)/
2021/11/18 00:46:25 /
可以看到如果是使用 sudo来运行的时候,程序在当前目录和系统原本的根目录下进行了切换。而普通用户则无权限操作。
Linux VServer 的安全漏洞
Linux-VServer 是一种基于 Security Contexts 的软分区技术,可以做到虚拟服务器隔离,共享相同的硬件资源。主要问题是 VServer 应用程序针对 "chroot-again" 类型的攻击没有很好的进行安全保护,攻击者可以利用这个漏洞脱离限制环境,访问限制目录之外的任意文件。(自 2004年开始,国家信息安全漏洞库就登出了相关漏洞问题)

图 3 ,国家信息安全漏洞库网站图标
现代化容器技术带来的优势
轻量级,基于 Linux 内核所提供的 cgroup 和 namespace 能力,创建容器的成本很低;
一定的隔离性;
标准化,通过使用容器镜像的方式进行应用程序的打包和分发,可以屏蔽掉因为环境不一致带来的诸多问题;
DevOps 支撑(可以在不同环境,如开发、测试和生产等环境之间轻松迁移应用,同时还可保留应用的全部功能);
为基础架构增添防护,提升可靠性、可扩展性和信赖度;
DevOps/GitOps 支撑 (可以做到快速有效地持续性发布,管理版本及配置);
团队成员间可以有效简化、加速和编排应用的开发与部署;
在了解了为什么要关注 cgroup 和 namespace 等技术之后,那我们就进入到本篇的重点吧,来一起学习下 cgroup 。
什么是 cgroup
cgroup 是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。它是由 Google 的两位工程师进行开发的,自 2008 年 1 月正式发布的 Linux 内核 v2.6.24 开始提供此能力。
cgroup 到目前为止,有两个大版本, cgroup v1 和 v2 。以下内容以 cgroup v2 版本为主,涉及两个版本差别的地方会在下文详细介绍。
cgroup 主要限制的资源是:
CPU
内存
网络
磁盘 I/O
当我们将可用系统资源按特定百分比分配给 cgroup 时,剩余的资源可供系统上的其他 cgroup 或其他进程使用。
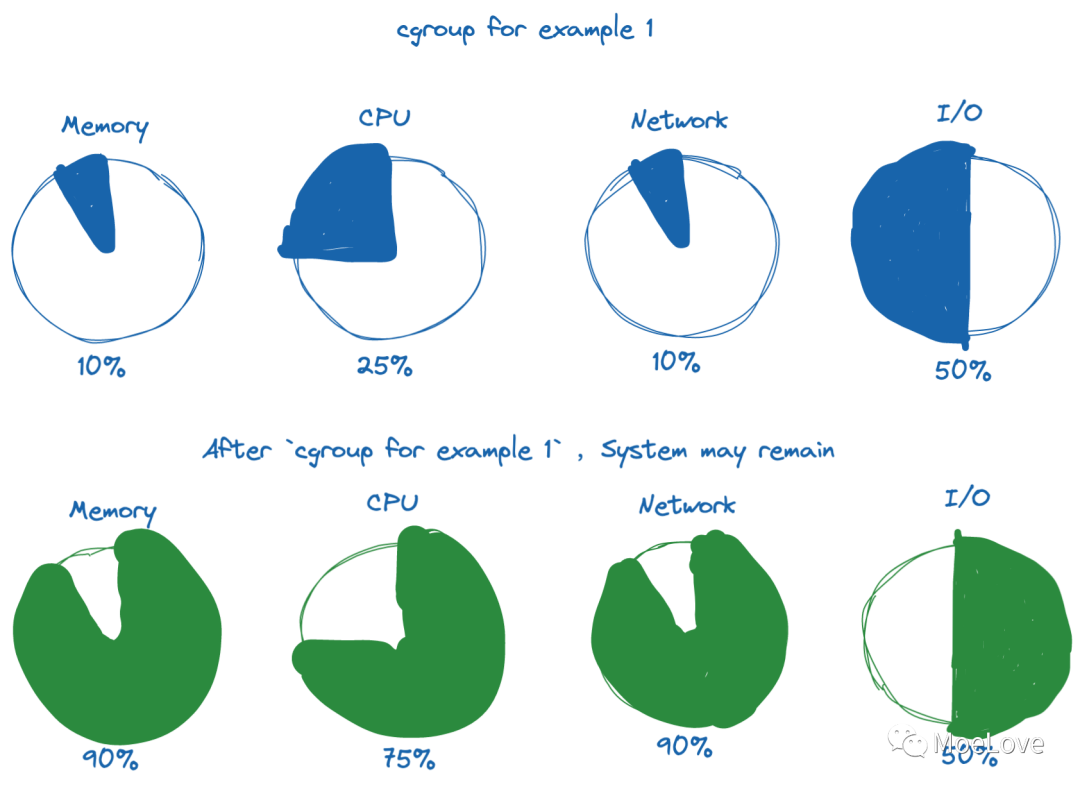
图 4 ,cgroup 资源分配及剩余可用资源示例
cgroup 的组成
cgroup 代表“控制组”,并且不会使用大写。cgroup 是一种分层组织进程的机制, 沿层次结构以受控的方式分配系统资源。我们通常使用单数形式用于指定整个特征,也用作限定符如 “cgroup controller” 。
cgroup 主要有两个组成部分:
core - 负责分层组织过程; controller - 通常负责沿层次结构分配特定类型的系统资源。每个 cgroup 都有一个 cgroup.controllers文件,其中列出了所有可供 cgroup 启用的控制器。当在cgroup.subtree_control中指定多个控制器时,要么全部成功,要么全部失败。在同一个控制器上指定多项操作,那么只有最后一个生效。每个 cgroup 的控制器销毁是异步的,在引用时同样也有着延迟引用的问题;
所有 cgroup 核心接口文件都以 cgroup 为前缀。每个控制器的接口文件都以控制器名称和一个点为前缀。控制器的名称由小写字母和“”组成,但永远不会以“”开头。
cgroup 的核心文件
cgroup.type - (单值)存在于非根 cgroup 上的可读写文件。通过将“threaded”写入该文件,可以将 cgroup 转换为线程 cgroup,可选择 4 种取值,如下:
domain - 一个正常的有效域 cgroup domain threaded - 线程子树根的线程域 cgroup domain invalid - 无效的 cgroup threaded - 线程 cgroup,线程子树 cgroup.procs - (换行分隔)所有 cgroup 都有的可读写文件。每行列出属于 cgroup 的进程的 PID。PID 不是有序的,如果进程移动到另一个 cgroup ,相同的 PID 可能会出现不止一次;
cgroup.controllers - (空格分隔)所有 cgroup 都有的只读文件。显示 cgroup 可用的所有控制器;
cgroup.subtree_control - (空格分隔)所有 cgroup 都有的可读写文件,初始为空。如果一个控制器在列表中出现不止一次,最后一个有效。当指定多个启用和禁用操作时,要么全部成功,要么全部失败。
以“+”为前缀的控制器名称表示启用控制器 以“-”为前缀的控制器名称表示禁用控制器 cgroup.events - 存在于非根 cgroup 上的只读文件。
populated - cgroup 及其子节点中包含活动进程,值为1;无活动进程,值为0. frozen - cgroup 是否被冻结,冻结值为1;未冻结值为0. cgroup.threads - (换行分隔)所有 cgroup 都有的可读写文件。每行列出属于 cgroup 的线程的 TID。TID 不是有序的,如果线程移动到另一个 cgroup ,相同的 TID 可能会出现不止一次。
cgroup.max.descendants - (单值)可读写文件。最大允许的 cgroup 子节点数量。
cgroup.max.depth - (单值)可读写文件。低于当前节点最大允许的树深度。
cgroup.stat - 只读文件。
nr_descendants - 可见后代的 cgroup 数量。 nr_dying_descendants - 被用户删除即将被系统销毁的 cgroup 数量。 cgroup.freeze - (单值)存在于非根 cgroup 上的可读写文件。默认值为0。当值为1时,会冻结 cgroup 及其所有子节点 cgroup,会将相关的进程关停并且不再运行。冻结 cgroup 需要一定的时间,当动作完成后, cgroup.events 控制文件中的 “frozen” 值会更新为“1”,并发出相应的通知。cgroup 的冻结状态不会影响任何 cgroup 树操作(删除、创建等);
cgroup.kill - (单值)存在于非根 cgroup 上的可读写文件。唯一允许值为1,当值为1时,会将 cgroup 及其所有子节点中的 cgroup 杀死(进程会被 SIGKILL 杀掉)。一般用于将一个 cgroup 树杀掉,防止叶子节点迁移;
cgroup 的归属和迁移
系统中的每个进程都属于一个 cgroup,一个进程的所有线程都属于同一个 cgroup。一个进程可以从一个 cgroup 迁移到另一个 cgroup 。进程的迁移不会影响现有的后代进程所属的 cgroup。
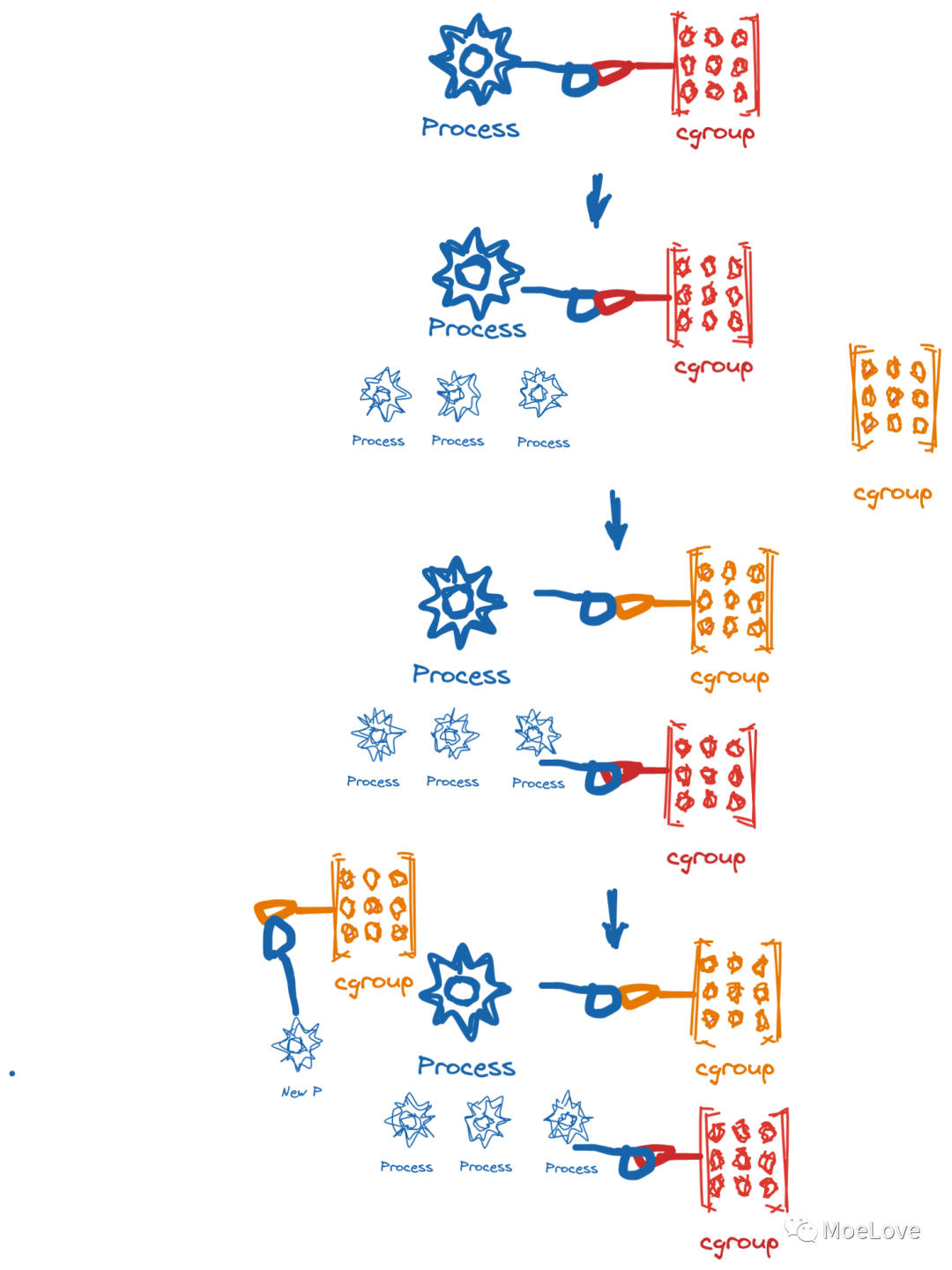
图 5 ,进程及其子进程的 cgroup 分配;跨 cgroup 迁移示例
跨 cgroup 迁移进程是一项代价昂贵的操作并且有状态的资源限制(例如,内存)不会动态的应用于迁移。因此,经常跨 cgroup 迁移进程只是作为一种手段。不鼓励直接应用不同的资源限制。
如何实现跨 cgroup 迁移
每个cgroup都有一个可读写的接口文件 “cgroup.procs” 。每行一个 PID 记录 cgroup 限制管理的所有进程。一个进程可以通过将其 PID 写入另一 cgroup 的 “cgroup.procs” 文件来实现迁移。
但是这种方式,只能迁移一个进程在单个 write(2) 上的调用(如果一个进程有多个线程,则会同时迁移所有线程,但也要参考线程子树,是否有将进程的线程放入不同的 cgroup 的记录)。
当一个进程 fork 出一个子进程时,该进程就诞生在其父亲进程所属的 cgroup 中。
一个没有任何子进程或活动进程的 cgroup 是可以通过删除目录进行销毁的(即使存在关联的僵尸进程,也被认为是可以被删除的)。
什么是 cgroups
当明确提到多个单独的控制组时,才使用复数形式 “cgroups” 。
cgroups 形成了树状结构。(一个给定的 cgroup 可能有多个子 cgroup 形成一棵树结构体)每个非根 cgroup 都有一个 cgroup.events 文件,其中包含 populated 字段指示 cgroup 的子层次结构是否具有实时进程。所有非根的 cgroup.subtree_control 文件,只能包含在父级中启用的控制器。
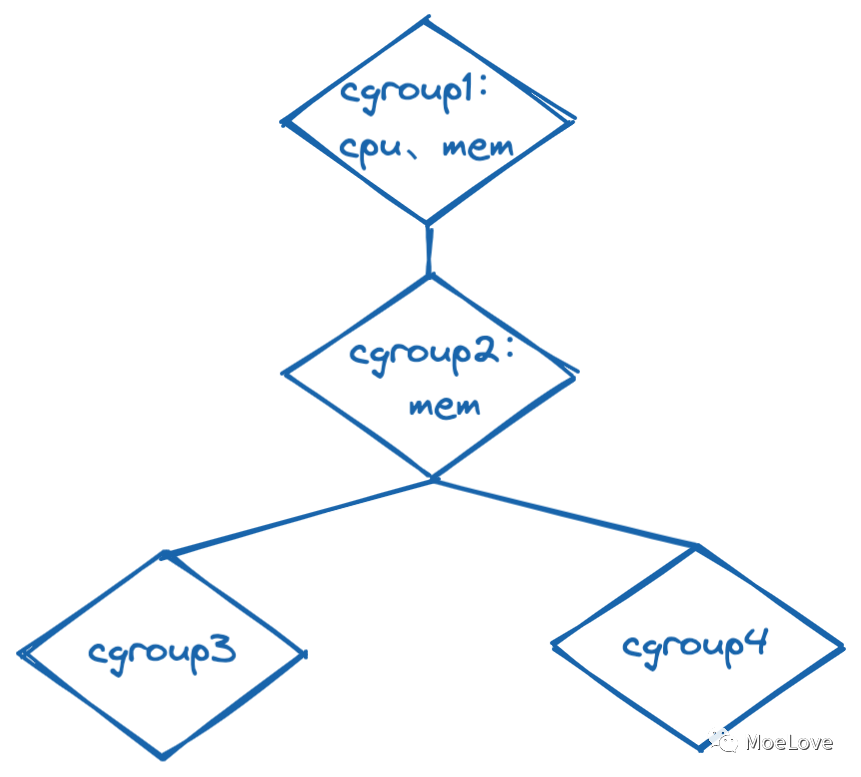
图 6 ,cgroups 示例
如图所示,cgroup1 中限制了使用 cpu 及 内存资源,它将控制子节点的 CPU 周期和内存分配(即,限制 cgroup2、cgroup3、cgroup4 中的cpu及内存资源分配)。cgroup2 中启用了内存限制,但是没有启用cpu的资源限制,这就导致了 cgroup3 和 cgroup4 的内存资源受 cgroup2中的 mem 设置内容的限制;cgroup3 和 cgroup4 会自由竞争在 cgroup1 的 cpu 资源限制范围内的 cpu 资源。
由此,也可以明显的看出 cgroup 资源是自上而下分布约束的。只有当资源已经从上游 cgroup 节点分发给下游时,下游的 cgroup 才能进一步分发约束资源。所有非根的 cgroup.subtree_control 文件只能包含在父节点的 cgroup.subtree_control 文件中启用的控制器内容。
那么,子节点 cgroup 与父节点 cgroup 是否会存在内部进程竞争的情况呢?
当然不会。cgroup v2 中,设定了非根 cgroup 只能在没有任何进程时才能将域资源分发给子节点的 cgroup。简而言之,只有不包含任何进程的 cgroup 才能在其 cgroup.subtree_control 文件中启用域控制器,这就保证了,进程总在叶子节点上。
挂载和委派
cgroup 的挂载方式
memory_recursiveprot - 递归地将 memory.min 和 memory.low 保护应用于整个子树,无需显式向下传播到叶节点的 cgroup 中,子树内叶子节点可以自由竞争;
memory_localevents - 只能挂载时设置或者通过从 init 命名空间重新挂载来修改,这是系统范围的选项。只用当前 cgroup 的数据填充 memory.events,如果没有这个选项,默认会计数所有子树;
nsdelegate - 只能挂载时设置或者通过从 init 命名空间重新挂载来修改,这也是系统范围的选项。它将 cgroup 命名空间视为委托边界,这是两种委派 cgroup 的方式之一;
cgroup 的委派方式
设置挂载选项 nsdelegate ; 授权用户对目录及其 cgroup.procs、cgroup.threads和cgroup.subtree_control文件的写访问权限
两种方式的结果相同。一旦被委派,用户就可以在目录下建立子层次结构,所有的资源分配都受父节点的制约。目前,cgroup 对委托子层次结构中的 cgroup 数量或嵌套深度没有任何限制(之后可能会受到明确限制)。
前面提到了跨 cgroup 迁移,从委派中,我们可以很明确的得知跨 cgroup 迁移对于普通用户来讲,是有限制条件的。即,是否对目前 cgroup 的 “cgroup.procs” 文件具有写访问权限以及是否对源 cgroup 和目标 cgroup 的共同祖先的 “cgroup.procs” 文件具有写访问权限。
委派和迁移
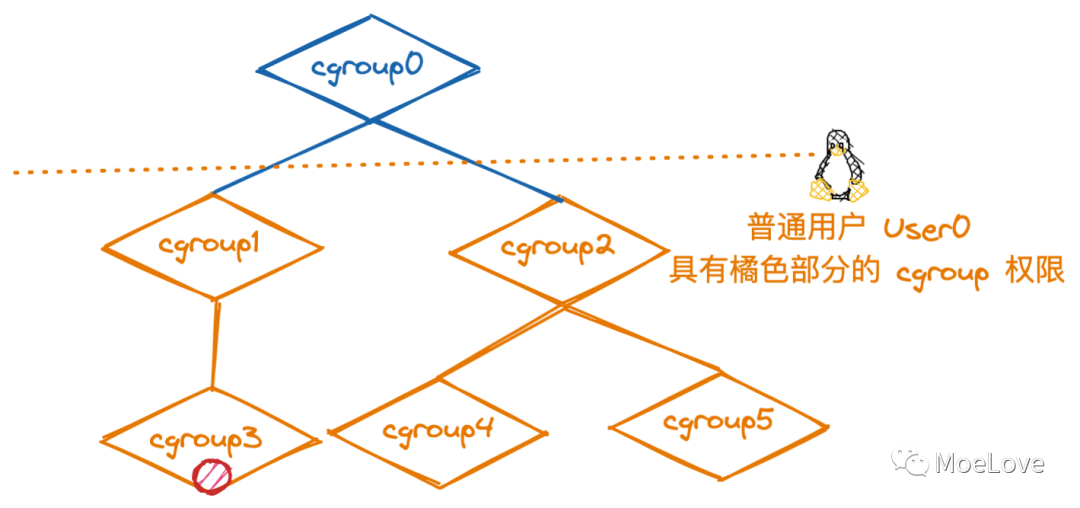
图 7 ,委派权限示例
如图,普通用户 User0 具有 cgroup[1-5] 的委派权限。
为什么 User0 想将进程 从 cgroup3 迁移至 cgroup5会失败呢?
这是由于 User0 的权限只到 cgroup1 和 cgroup2 层,并不具备 cgroup0 的权限。而委派中的授权用户明确指出需要共同祖先的 “cgroup.procs” 文件具有写访问权限!(即,需要图中 cgroup0 的权限,才可以实现)
资源分配模型及功能
以下是 cgroups 的资源分配模型:
权重 - (例如,cpu.weight) 所有权重都在 [1, 10000] 范围内,默认值为 100。按照权重比率来分配资源。
限制 - [0, max] 范围内,默认为“max”,即 noop(例如,io.max)。限制可以被过度使用(子节点限制的总和可能超过父节点可用的资源量)。
保护 - [0, max] 范围内,默认为 0,即 noop(例如,io.low)。保护可以是硬保证或尽力而为的软边界,保护也可能被过度使用。
分配 - [0, max] 范围内,默认为 0,即没有资源。分配不能被过度使用(子节点分配的总和不能超过父节点可用的资源量)。
cgroups 提供了如下功能:
资源限制 - 上面 cgroup 部分已经示例,cgroups 可以以树状结构来嵌套式限制资源。
优先级 - 发生资源争用时,优先保障哪些进程的资源。
审计 - 监控及报告资源限制及使用。
控制 - 控制进程的状态(起、停、挂起)。
cgroup v1 与 cgroup v2
被弃用的核心功能
cgroup v2 和 cgroup v1 有很大的不同,我们一起来看看在 cgroup v2 中弃用了哪些 cgroup v1 的功能:
不支持包括命名层次在内的多个层次结构;
不支持所有 v1 安装选项;
“tasks” 文件被删除,“cgroup.procs” 没有排序
在 cgroup v1 中线程组 ID 的列表。不保证此列表已排序或没有重复的 TGID,如果需要此属性,用户空间应排序/统一列表。将线程组 ID 写入此文件会将该组中的所有线程移动到此 cgroup 中; cgroup.clone_children被删除。clone_children 仅影响 cpuset controller。如果在 cgroup 中启用了 clone_children (设置:1),新的 cpuset cgroup 将在初始化期间从父节点的 cgroup 复制配置;/proc/cgroups 对于 v2 没有意义。改用根目录下的“cgroup.controllers”文件;
cgroup v1 的问题
cgroup v2 和 v1 中最显著的不同就是 cgroup v1 允许任意数量的层次结构, 但这会带来一些问题的。我们来详细聊聊。
挂载 cgroup 层次结构时,你可以指定要挂载的子系统的逗号分隔列表作为文件系统挂载选项。默认情况下,挂载 cgroup 文件系统会尝试挂载包含所有已注册子系统的层次结构。
如果已经存在具有完全相同子系统集的活动层次结构,它将被重新用于新安装。
如果现有层次结构不匹配,并且任何请求的子系统正在现有层次结构中使用,则挂载将失败并显示 -EBUSY。否则,将激活与请求的子系统相关联的新层次结构。
当前无法将新子系统绑定到活动 cgroup 层次结构,或从活动 cgroup 层次结构中取消绑定子系统。当 cgroup 文件系统被卸载时,如果在顶级 cgroup 之下创建了任何子 cgroup,即使卸载,该层次结构仍将保持活动状态;如果没有子 cgroup,则层次结构将被停用。
这就是 cgroup v1 中的问题,在 cgroup v2 中就很好的进行了解决。
cgroup 和容器的联系
这里我们以 Docker 为例。创建一个容器,并对其可使用的 CPU 和内存进行限制:
➜ ~ docker run --rm -d --cpus=2 --memory=2g --name=2c2g redis:alpine
e420a97835d9692df5b90b47e7951bc3fad48269eb2c8b1fa782527e0ae91c8e
➜ ~ cat /sys/fs/cgroup/system.slice/docker-`docker ps -lq --no-trunc`.scope/cpu.max
200000 100000
➜ ~ cat /sys/fs/cgroup/system.slice/docker-`docker ps -lq --no-trunc`.scope/memory.max
2147483648
➜ ~
➜ ~ docker run --rm -d --cpus=0.5 --memory=0.5g --name=0.5c0.5g redis:alpine
8b82790fe0da9d00ab07aac7d6e4ef2f5871d5f3d7d06a5cdb56daaf9f5bc48e
➜ ~ cat /sys/fs/cgroup/system.slice/docker-`docker ps -lq --no-trunc`.scope/cpu.max
50000 100000
➜ ~ cat /sys/fs/cgroup/system.slice/docker-`docker ps -lq --no-trunc`.scope/memory.max
536870912
从上面的示例可以看到,当我们使用 Docker 创建出新的容器并且为他指定 CPU 和 内存限制后,其对应的 cgroup 配置文件的 cpu.max 和 memory.max都设置成了相应的值。
如果你想要对一些已经在运行的容器进行资源配额的检查的话,也可以直接去查看其对应的配置文件中的内容。
总结
以上就是关于容器技术的基石之一的 cgroup 的详细介绍了。接下来我还会写关于 namespace 以及其他容器技术相关的内容,敬请关注!