
普通高中选课数据分析和可视化(3)
前情回顾:
3.5 绘制各学科关联度散点图
和前面几个图表不一样,这里不需要对df按学校分组计数,而是构造一个反映各学科关联度的DataFrame对象zuhe(所谓关联度就是某学生同时选择了该两个科目),再遍历每一门学科,绘制其与其他学科关联度散点图。我们既可以在同一个区域绘制各学科关联度散点图,也可以分成多个子图,分别绘制各学科关联度散点图(如下图所示)。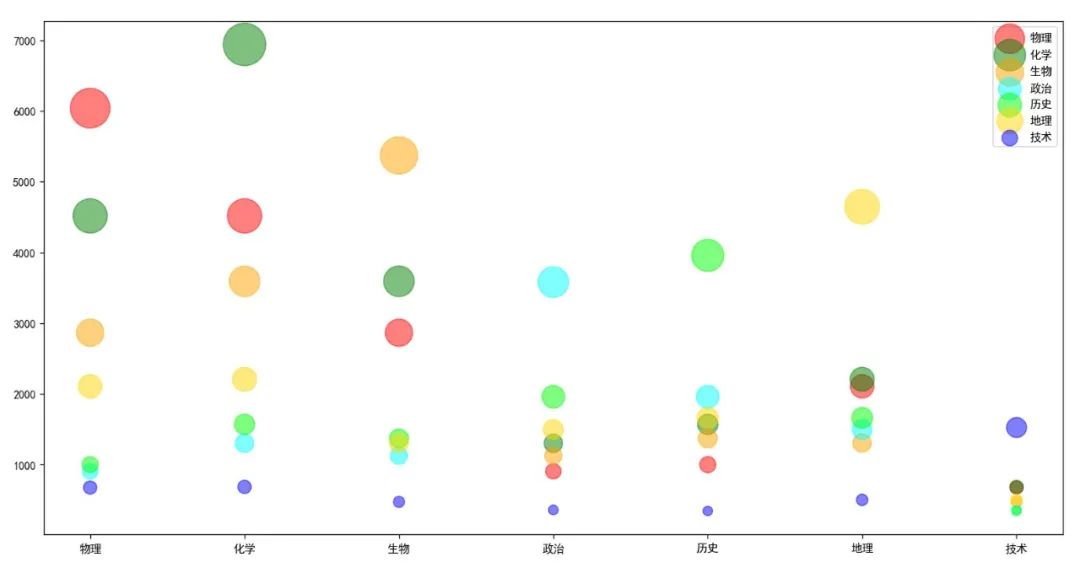
图9 各学科关联度散点图
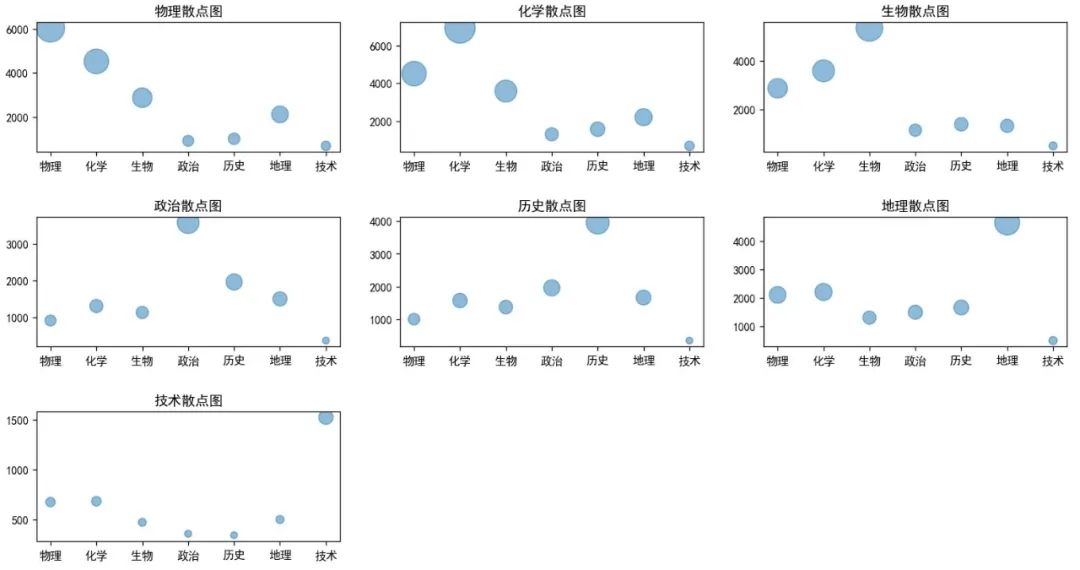
图10 各学科关联度散点图(多子图)
核心代码(完整代码详见源代码文件“7选3绘制各学科关联度散点图.py”):
#在同一个区域绘制各学科关联度散点图colors = ('red','green','orange','cyan','lime','gold','blue')fig, ax = plt.subplots(figsize=(10,12),dpi=120)for i, k in enumerate(kms, start=0): #遍历每一门学科,绘制其与其他学科关联度散点图nums = zuhe.loc[k].tolist()area = [j*0.2 for j in nums]ax.scatter(x=kms,y=nums,s=area,c=colors[i],label=k,alpha=0.5)ax.legend()#分别绘制各学科关联度散点图plt.figure(figsize=(10,10),dpi=120) #生成新的figure,并设置各个子图的宽、高和绘图分辨率for i, k in enumerate(kms, start=1): #遍历每一门学科,绘制其与其他学科关联度散点图#subplot将整个绘图区域等分为Rows行*Cols列个子区域,按照从左到右,从上到下的顺序对每个子区域进行编号plt.subplot(3, 3, i) #划分子图,分成3*3个区域plt.subplots_adjust(hspace = 0.5) #为子图之间的空间保留的高度plt.title(f"{k}散点图") #为每个子图设置标题nums = zuhe.loc[k].tolist()area = [j*0.1 for j in nums]plt.scatter(x=kms,y=nums,s=area,alpha=0.5)plt.show()
3.6 7选3选课组合数据处理
标准库中的itertools包提供了很多灵活的生成循环器的工具,主要分为无限迭代器、输入序列迭代器、组合生成器。其中函数combinations(iterable,r)属于组合生成器,用来生成指定数目r的元素不重复的所有组合。
我们使用语句import itertools引入库,设置各科简称字符串kms = "物化生政史地技",然后生成选课组合名称列表kmzh_3 = [''.join(km) for km initertools.combinations(kms,3)];接下来打开"xk73.csv"文件,读取某市普通高中选课汇总数据,存储到DataFrame对象df中;再遍历每一所学校,为每位学生生成选课组合信息,并统计各校各选课组合数量(如下图所示)。
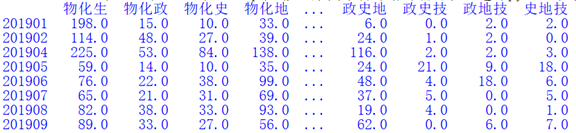
图11 各校各选课组合人数统计图
核心代码(完整代码详见源代码文件“7选3选课组合数据处理.py”):
kms = "物化生政史地技"kmzh_3 = [''.join(km) for km in itertools.combinations(kms,3)]kms_dic = {"物理":"物","化学":"化","生物":"生","政治":"政","历史":"史","地理":"地","技术":"技"}#读数据到 Pandas的DataFrame 结构中source_df =pd.read_csv("xk73.csv",sep=',',header='infer',encoding='utf-8')schools = sorted(source_df['学校代码'].unique()) #生成学校代码名称列表zuhe_df = pd.DataFrame(index=schools, columns=kmzh_3)
3.7 绘制各校各选课组合人数柱状图
我们统计好各校各选课组合数据以后,就可以调用DataFrame.plot方法绘制各校各选课组合人数堆积柱状图了,还可以分成多个子图,分别绘制各校各选课组合人数柱状图(如下图所示)。
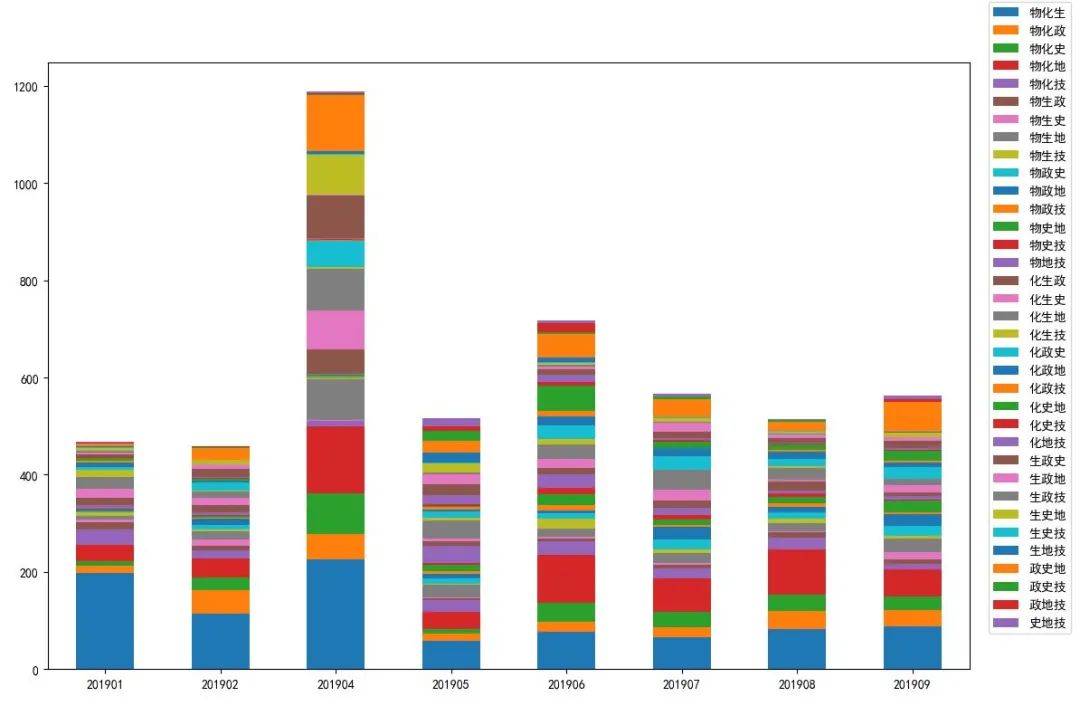
图12 各校各选课组合人数堆积柱状图
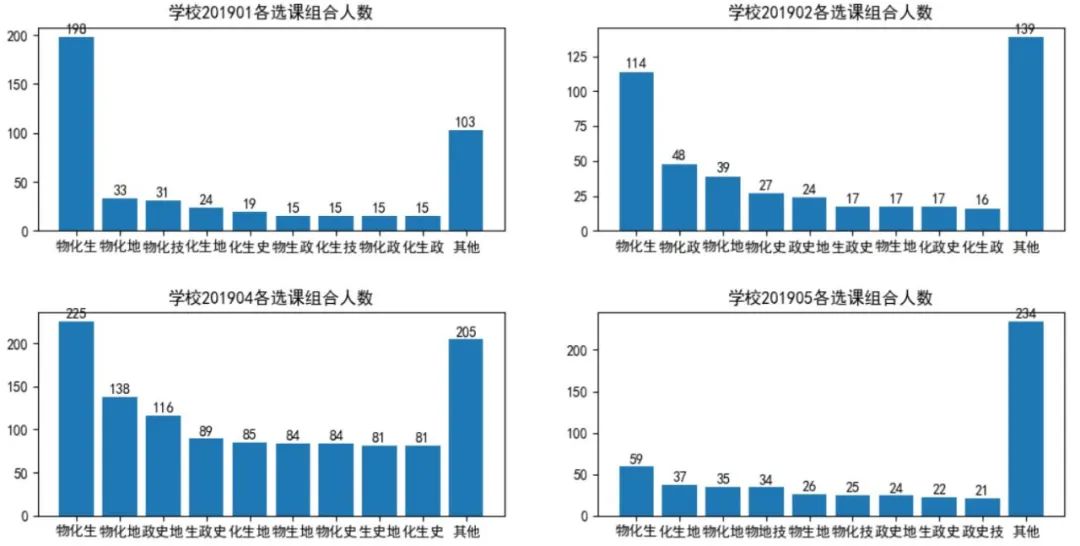
图13 各校各选课组合人数柱状图(多子图)
核心代码(完整代码详见源代码文件“7选3选课组合数据可视化.py”):
#调用DataFrame.plot方法绘制全市各选课组合人数柱状图plt.bar(df_sum.columns, df_sum.loc[0])plt.xticks(rotation = 90)x = list(range(len(df_sum.columns)))y = list(df_sum.loc[0])for a,b in zip(x, y): #控制标签位置plt.text(a,b+1.5,'%.0f'%b,ha = 'center',va = 'bottom')plt.show()
3.8 绘制各校各选课组合人数占比饼图
和绘制柱状图一样,我们需要先统计好各校各选课组合数据,再分别去绘制各校各选课组合人数占比饼图(如下图所示)。
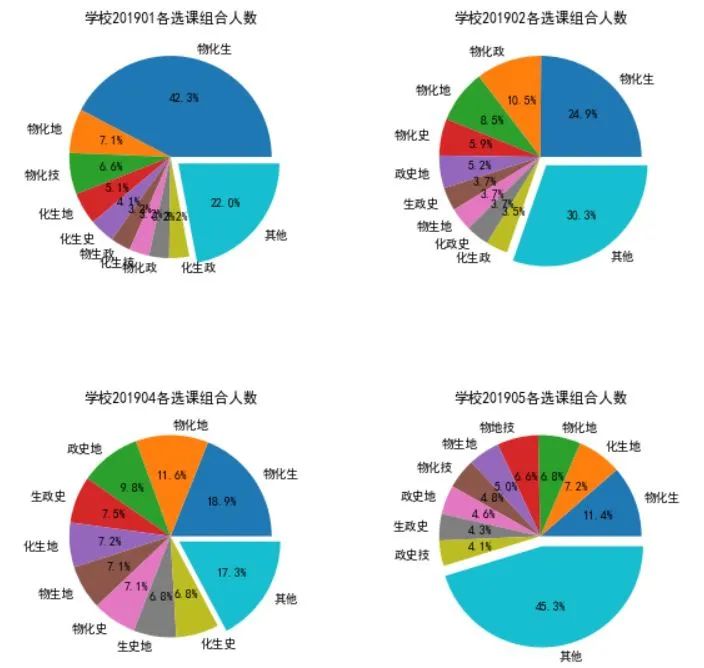
图14 各校各选课组合人数占比饼图(多子图)
核心代码(完整代码详见源代码文件“7选3选课组合数据可视
化.py”):
#分别绘制各校各选课组合人数占比饼图i = 1for r in zuhe_df.index: #遍历每一所学校,绘制各校各选课组合人数占比饼图if i % 4 == 1: #每页生成4张子图,每画完4张子图就生成新的窗体plt.figure(figsize=(10,10),dpi=70) #生成新的figure,并设置各个子图的宽、高和绘图分辨率i = 1#subplot将整个绘图区域等分为Rows行*Cols列个子区域,按照从左到右,从上到下的顺序对每个子区域进行编号plt.subplot(2, 2, i) #划分子图,分成2*2个区域i += 1plt.subplots_adjust(hspace = 0.5) #为子图之间的空间保留的高度plt.title(f"学校{r}各选课组合人数") #为每个子图设置标题plt.xticks(fontsize=10) #标签字体大小show_zuhe_df = zuhe_df.sort_values(by=r, axis=1, ascending=False)zuhe_nums = 9 #只输出人数最多的前9个组合show_zuhe_df.insert(zuhe_nums, '其他', show_zuhe_df.loc[r, show_zuhe_df.columns[zuhe_nums:]].sum()) #插入其他列labels = show_zuhe_df.columns[:zuhe_nums+1]sizes = show_zuhe_df.loc[r, show_zuhe_df.columns[:zuhe_nums+1]]explode = [0] * len(sizes)explode[-1] = 0.1plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False)plt.show()
说明:因为本项目内容较多,故写成系列文章分成多次分享,请大家稍安勿躁哦。
需要本文word版或者相关源代码的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章: