
k8s技术圈一周精选[第7期]

1. HPA 控制器算法
HPA 控制器与聚合 API 获取到 Pod 性能指标数据之后,基于下面的算法计算出目标 Pod 副本数量,与当前运行的 Pod 副本数量进行对比,决定是否需要进行扩缩容操作:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]即当前副本数 * (当前指标值/期望的指标值),将结果向上取整
以 CPU 请求数量为例,如果用户设置的期望指标值为 100m,当前实际使用的指标值为 200,则结果得到期望的 Pod 副本数量应为两个(200/100=2)。如果设置的期望指标值为 50m,计算结果为 0.5,则向上取整为 1,得到目标 Pod 副本数量应为 1 个。当结果计算与 1 非常接近时,可以设置一个容忍度让系统不做扩缩容操作。容忍度通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-tolerance 进行设置,默认值为 0.1(即 10%),表示基于上述算法得到的结果在 [-10% + 10% ] 区间内,即 [ 0.9 - 1.1],控制器都不会进行扩缩容操作。
也可以将期望指标值设置为指标的平均值类型,例如 targetAverageValue 或 targetAverageUtilization,此时当前指标值的算法为所有 Pod 副本当前指标值的总和除以 Pod 副本数量得到的平均值。此外,存在几种 Pod 异常的情况,如下所述。
Pod 正在被删除:将不会计入目标 Pod 副本数量。
Pod 的当前指标值无法获得:本次探测不会将这个 Pod 纳入目标 Pod 副本数量,后续的探测会被重新纳入计算范围。
如果指标类型是 CPU 使用率,则对于正在启动但是还未达到 Ready 状态的 Pod,也暂时不会纳入目标副本数量范围。可以通过 kube-controller-manager 服务的启动参数
--horizontal-pod-autoscaler-initial-readiness-delay设置首次探测 Pod 是否 Ready 的延时时间,默认值为 30s。另一个启动参数--horizontal-pod-autoscaler-cpu-initialization-period用于标记刚启动一定时间内的 Pod 为 ignoredPod,实时获取不到信息的 Pod 被标记为 missingPod,默认为5min。
在计算 "当前指标值/期望的指标值" 时将不会包括上述这些异常 Pod。当存在缺失指标的 Pod 时,系统将更保守地重新计算平均值。系统会假设这些 Pod 在需要缩容时消耗了期望指标值的 100%,在需要扩容时消耗了期望指标值的 0%,这样可以抑制潜在额扩缩容操作。此外,如果存在未达到 Ready 状态的 Pod,并且系统原来会在不考虑缺失指标或 NotReady 的 Pod 情况下进行扩展,则系统仍会保守地假设这些 Pod 消耗期望指标值的 0%,从而进一步抑制扩容操作。如果在 HPA 中设置了多个指标,系统就会对每个指标都执行上面的算法,在全部结果中以期望副本数的最大值为最终结果。如果这些指标中的任意一个都无法转换为期望的副本数(例如无法获取指标的值),系统就会跳过扩缩容操作。最后,在 HPA 控制器执行扩缩容操作之前,系统会记录扩缩容建议信息。控制器会在操作时间窗口中考虑所有的建议信息,并从中选择得分最高的建议。这个值可通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-downscale-stabilization-window 进行配置,默认值为 5min。这个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
2. CGroup Driver 区别
我们在安装 Kubernetes 的时候知道有一个强制要求就是 Docker 和 kubelet 的 cgroup driver 必须保持一致,要么都使用 systemd,要都使用 cgroupfs,官方是推荐使用 systemd 的,但是一直搞不清楚这两个驱动到底有什么区别。首先我们要弄明白 cgroup 的概念,cgroup 是 control group 的缩写,是 linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源的机制,其中物理资源包含 cpu/memory/io 等等。cgroup 是将任意进程进行分组化管理的 linux 内核功能,cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 cgroup 子系统或控制器。cgroup 子系统有控制内存的 Memory 控制器、控制进程调度的 CPU 控制器等。那么 systemd 和 cgroupfs 这两种驱动有什么区别呢?
systemd cgroup driver 是 systemd 本身提供了一个 cgroup 的管理方式,使用systemd 做 cgroup 驱动的话,所有的 cgroup 操作都必须通过 systemd 的接口来完成,不能手动更改 cgroup 的文件。
cgroupfs 驱动就比较直接,比如说要限制内存是多少、要用 CPU share 为多少?直接把 pid 写入对应的一个 cgroup 文件,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了
所以 systemd 更加安全,因为不能手动去更改 cgroup 文件,当然我们也推荐使用 systemd 驱动来管理 cgroup。
3. LeastRequestedPriority 调度算法
在研究 k8s 调度器里面的优选算法的时候有一个 LeastRequestedPriority 算法:通过计算 CPU 和内存的使用率来决定权重,使用率越低权重越高,当然正常肯定也是资源是使用率越低权重越高,能给别的 Pod 运行的可能性就越大。计算的算法也很简单:
(cpu((capacity-sum(requested))*10/capacity) + memory((capacity-sum(requested))*10/capacity))/2就是查看节点上剩下的 CPU 和 内存资源(百分比)来计算权重,但是需要注意的是在计算节点上 requested 的值的时候是当前节点上已经 requested 的值加上当前待调度的 Pod 的 requested 的值的:(nodeInfo.NonZeroRequest().MilliCPU + podRequest)不过在计算 podRequest 的值的时候也需要注意,如果你待调度的 Pod 没有设置 requests 资源,则会使用默认值(CPU:100m,内存:200M),如果设置了 requests 值即使是声明的0,那么也是使用设置的值进行计算。
4. go-template 获取 ca.crt
我们可以使用 go-template 获取 YAML 文件中的某个字段的数据,比如我们要获取某个 Secret 对象的 token 或者 ca.crt 的值:
$ kubectl get secret -n kubernetes-dashboard |grep adminadmin-token-scj2m kubernetes.io/service-account-token 3 215distio.admin istio.io/key-and-cert 3 158d
比如要获取 admin-token-scj2m 这个对象的数据,首先我们要查看该对象的结构:
kubectl get secret -n kubernetes-dashboard admin-token-scj2m -o yamlapiVersion: v1data:ca.crt:namespace: a3ViZXJuZXRlcy1kYXNoYm9hcmQ=token:kind: Secret......
要获取 token 的值比较简单,直接使用下面的命令即可:
$ kubectl get secret -n kubernetes-dashboard admin-token-scj2m -o go-template='{{.data.token}}'但是要获取 ca.crt 的值就要稍微麻烦点,因为对应的 key 是 ca.crt,如果我们改成 .data.ca\.crt 去获取是识别不了的,这个时候我们可以使用 go-template 里面的 index 函数来获取这个字段的值:
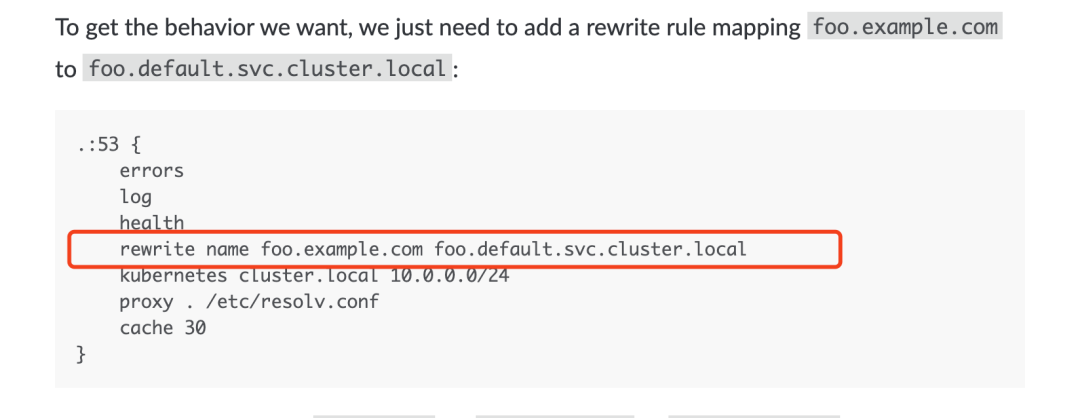
$ echo $(kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get secret | grep admin | awk 'NR==1{print $1}') -o go-template='{{index .data "ca.crt"}}')5. CoreDNS 做 CNAME 解析
如何在 K8S 中做 cname,这个其实 coredns 中就可以直接支持,如下图所示
6. 强制删除 namespace
有时候在 K8S 中删除一个 namespace 会卡住,强制删除也没用,前面我们介绍了可以去 etcd 里面去删除对应的数据,这种方式比较暴力,除此之外我们也可以通过 API 去删除。首先执行如下命令开启 API 代理:
$ kubectl proxy然后在另外一个终端中执行如下所示的命令:(将 monitoring 替换成你要删除的 namespace 即可)
$ kubectl get namespace monitoring -o json | jq 'del(.spec.finalizers[] | select("kubernetes"))' | curl -s -k -H "Content-Type: application/json" -X PUT -o /dev/null --data-binary @- http://localhost:8001/api/v1/namespaces/monitoring/finalize7. 调度器调优
微信群有群友咨询 kube-scheduler 预选输入的是所有节点吗,如果节点非常多岂不是性能比较差?这个其实和版本有关系,在 Kubernetes 1.12 版本之前,kube-scheduler 会检查集群中所有节点的可调度性,并且给可调度节点打分。Kubernetes 1.12 版本添加了一个新的功能,允许调度器在找到一定数量的可调度节点之后就停止继续寻找可调度节点。该功能能提高调度器在大规模集群下的调度性能,这个数值是集群规模的百分比,这个百分比通过 percentageOfNodesToScore 参数来进行配置,其值的范围在 1 到 100 之间,最大值就是 100%,如果设置为 0 就代表没有提供这个参数配置。Kubernetes 1.14 版本又加入了一个特性,在该参数没有被用户配置的情况下,调度器会根据集群的规模自动设置一个集群比例,然后通过这个比例筛选一定数量的可调度节点进入打分阶段。该特性使用线性公式计算出集群比例,比如100个节点的集群下会取 50%,在 5000节点的集群下取 10%,这个自动设置的参数的最低值是 5%,换句话说,调度器至少会对集群中 5% 的节点进行打分,除非用户将该参数设置的低于 5。
8. DNS 5s 解析问题
由于 Linux 内核中的缺陷,在 Kubernetes 集群中你很可能会碰到恼人的 DNS 间歇性 5 秒延迟问题。原因是镜像底层库 DNS 解析行为默认使用 UDP 在同一个 socket 并发 A 和 AAAA 记录请求,由于 UDP 无状态,两个请求可能会并发创建 conntrack 表项,如果最终 DNAT 成同一个集群 DNS 的 Pod IP 就会导致 conntrack 冲突,由于 conntrack 的创建和插入是不加锁的,最终后面插入的 conntrack 表项就会被丢弃,从而请求超时,默认 5s 后重试,造成现象就是 DNS 5 秒延时。要避免 DNS 延迟的问题,有下面几种方法:
禁止并发 DNS 查询,比如在 Pod 配置中开启 single-request-reopen 选项强制 A 查询和 AAAA 查询使用相同的 socket:
dnsConfig:options:- name: single-request-reopen
禁用 IPv6 从而避免 AAAA 查询,比如可以给 Grub 配置
ipv6.disable=1来禁止 ipv6(需要重启节点才可以生效)。
使用 TCP 协议,比如在 Pod 配置中开启 use-vc 选项强制 DNS 查询使用 TCP 协议:
dnsConfig:options:- name: single-request-reopen- name: ndotsvalue: "5"- name: use-vc
使用 Nodelocal DNS Cache,所有 Pod 的 DNS 查询都通过本地的 DNS 缓存查询,避免了 DNAT,从而也绕开了内核中的竞争问题。相关链接:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns
9. 往期精选内容
K8S进阶训练营,点击下方图片了解详情
