
Python读取CVS文件不够灵活?那是没用对,来看看这5招!
今天我们就给大家分享5招,让你能优雅地读取CSV文件。
先来看一下一个典型的数据集stocks.csv:

这是一个股票的数据集,就是常见的表格数据,有股票代码,价格,日期,时间,价格变动和成交量。你也可以自己创建一个数据集,只要有自己的表头和数据即可。
第一招:简单的读取
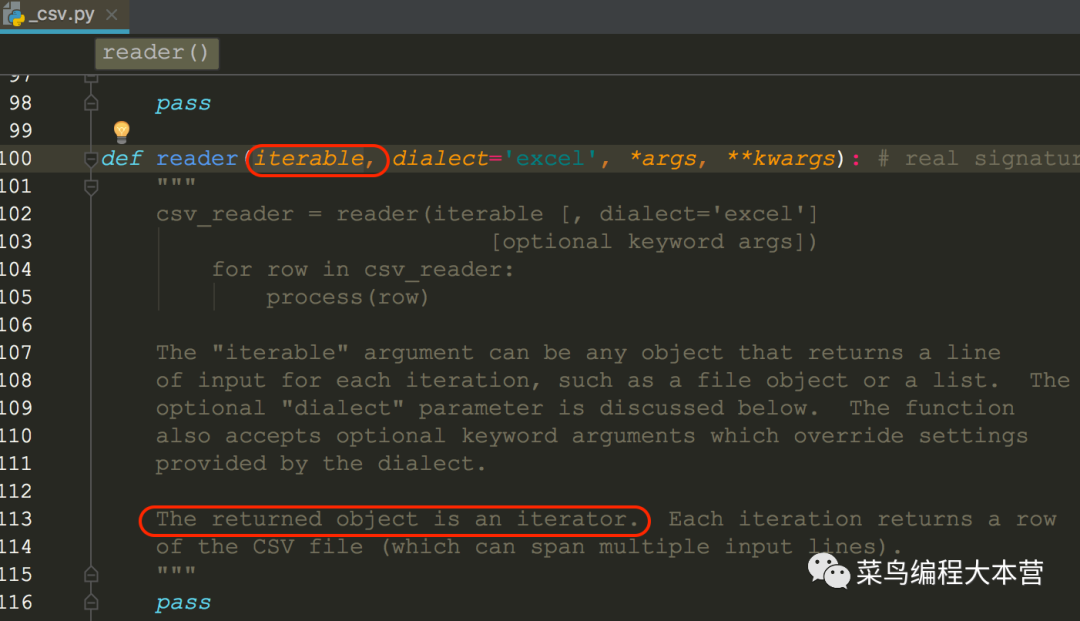
传给reader一个可迭代对象或者是文件的object,然后返回一个可迭代对象。

首先读取csv 文件,然后用csv.reader生成一个csv迭代器f_csv 然后利用迭代器的特性,next(f_csv)获取csv文件的头,也就是表格数据的头 接着利用for循环,一行一行打印row的内容,也就是表格数据的身体

这是最常见的csv读取方法,估计80%以上的人都只用这一招。但其实csv还有更灵活的读取方法。
第二招:用nametuple

nametuple其实是一个非常有用的类,这个类属于collections模块,而这个模块简直就是一个百宝箱,里面有非常多的实用的库; 这里我们用next(f_csv)其实就是获取表格的头部来初始化这个Row;

然后循环来构造这个Row的数据,把我们表格里面的每一行的数据都转成nametuple格式的row_info; 这样做的好处就是你可以随心所欲的访问这个row_info里面的数据,就想访问类数据一样,比如row_info.price
第三招:用tuple类型转换
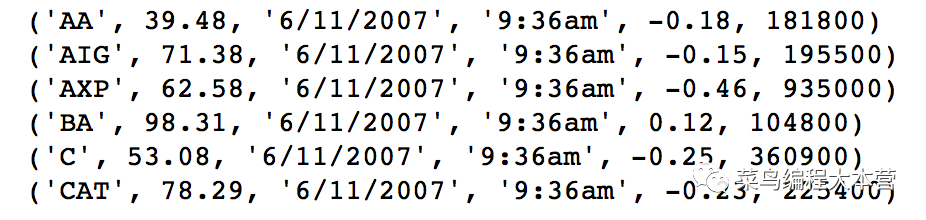
操作的步骤其实跟上面差不多,就是对数据结果的清洗处理稍微不一样。这里非常巧妙的zip来构造一个嵌套的数据列表,然后用convert(data)把csv文件里面每一行的数据进行类型转换,这招真的很好用!
看一下结果:
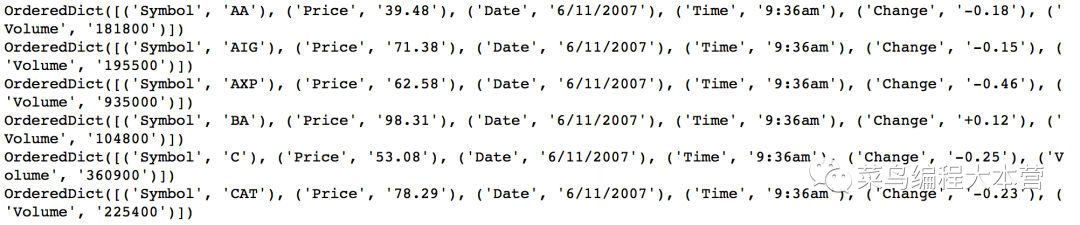
第四招:用DictReader
第五招:用字典转换

首先我们声明一个自定义的类型转换器field_types; 然后循环生成一个可迭代的对象(key,conversion(row[key]); 最后更新一下字典里面相同的key,比如row['price']的内容就会被更新了。
_往期文章推荐_
Python-Excel模块哪家强?
评论