
数据架构变革进行时:现代化应用需要怎样的数据策略?
现有数据架构难以支撑现代化应用的实现。
现代化应用开发之难
亦是数据架构创新之难
企业被传统商业数据库束缚,而难以开展创新。传统商业数据库不仅价格昂贵,还有专有技术及许可条款,需要经常进行审计。虽然越来越多的企业转向了 MySQL 和 PostgreSQL 等开源数据库,但他们仍需要商用数据库的性能。
无法满足特定场景需求。随着应用场景的不断增加,不同应用程序有了自己特定的需求。现在,开发人员越来越多地使用微服务架构来构建应用程序,并且选择新一代的关系型和非关系型数据库。但关系型数据库的结构数据耦合性大,不利于扩展分布式部署。非关系型数据库没有事务处理,复杂查询方面略微欠缺。
传统数据库运维模式仍旧需要耗费精力和成本。运维耗时但价值输出较低,但企业又不得不在这方面耗费精力和成本。
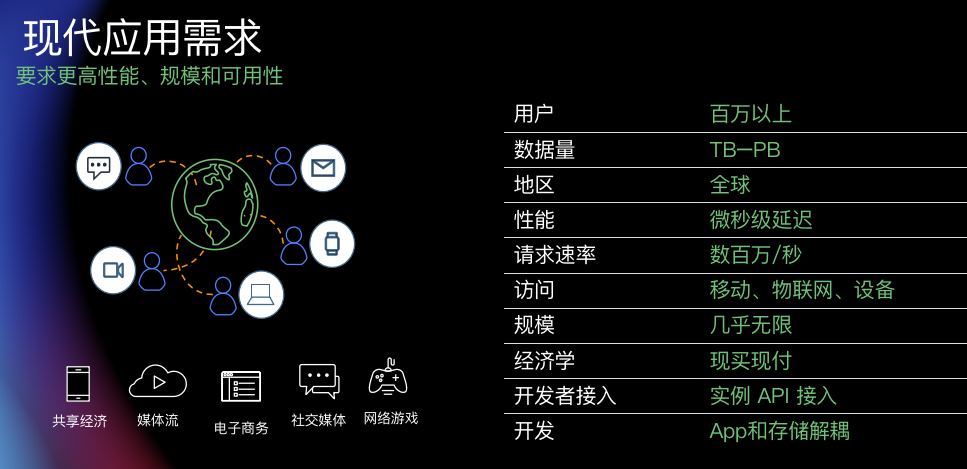
现代化应用需要什么样的数据架构
作为支撑?
如何实现架构现代化?
结束语
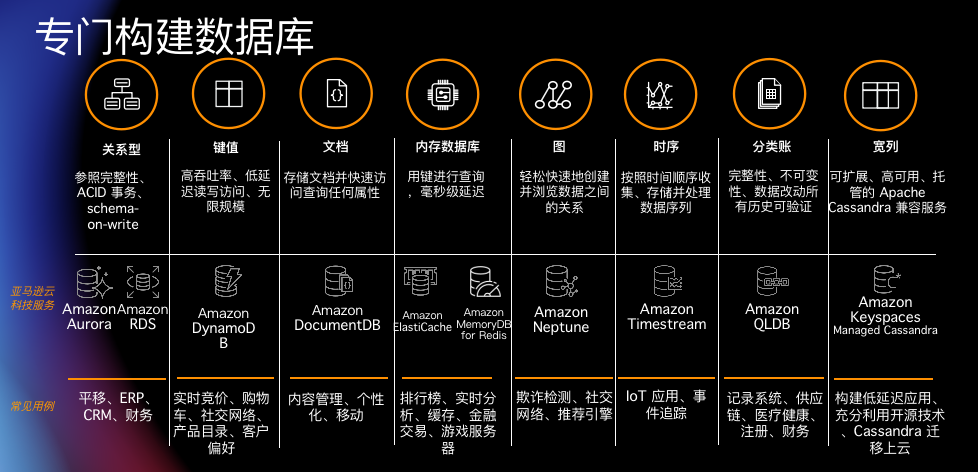
首先是我们前文所述的数据架构现代化。架构现代化是一切创新的基石,其最重要的理念是“The right tool for the job”,即在不同的场景使用专门构建的工具,而专门的工具需要专业的现代化托管平台,这些都可以大量节省企业的时间、金钱和精力。
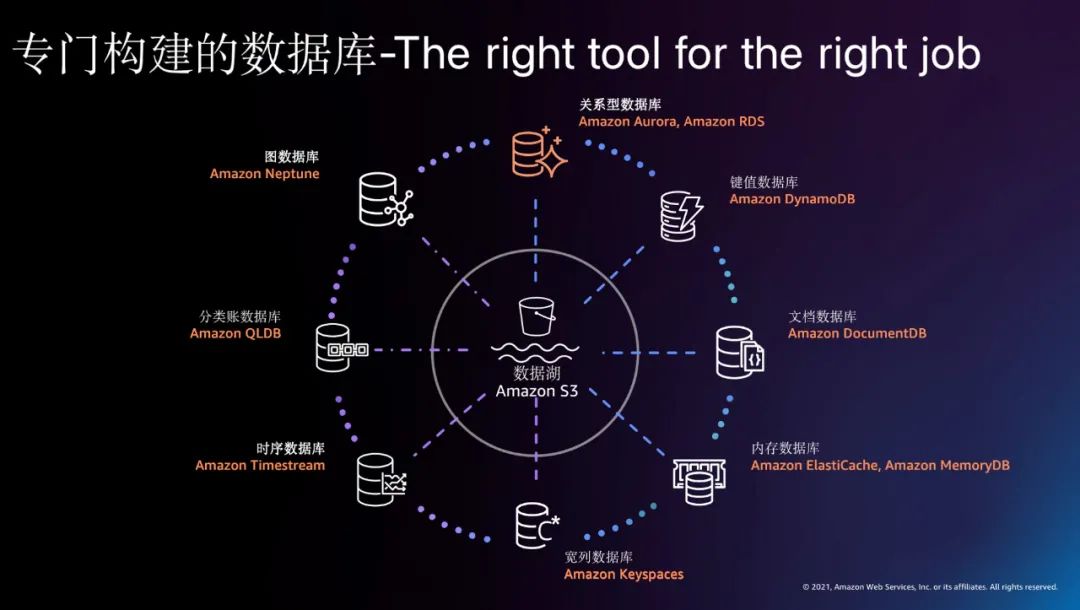
统一分析数据。统一分析数据则是通过云上专门工具实现数据有机整合与统一,将所有数据连接到一个安全且管理良好的连贯系统中,使企业拥有灵活扩展与极致性能。企业在获得实时反馈和数据后,可以很快地扩大服务规模。
基于数据进行业务创新。“蓬勃发展的公司与艰难求生的公司之间的关键区别在于是否将创建一个数据驱动型组织视为当务之急。”Amazon 机器学习副总裁 Swami Sivasubramanian 在亚马逊云科技 re:Invent 全球大会上说道。企业植根于自身业务的创新诉求是创新的原动力,其中训练与调优、模型部署与管理都涉及到了基础设施层面的创新。
