
3000字详解Pandas数据查询,建议收藏
DataFrame数据集中筛选符合指定条件的数据,希望会对读者朋友有所帮助。导入数据集和模块
我们先导入pandas模块,并且读取数据,代码如下
import pandas as pd
df = pd.read_csv("netflix_titles.csv")
df.head()
根据文本内容来筛选
True如果文本内容是相匹配的,False如果文本内容是不匹配的,代码如下mask = df['type'].isin(['TV Show'])
mask.head()
output
0 False
1 True
2 True
3 True
4 True
Name: type, dtype: bool
mask作用到整个数据集当中,返回的则是满足与True条件的数据df[mask].head()
output
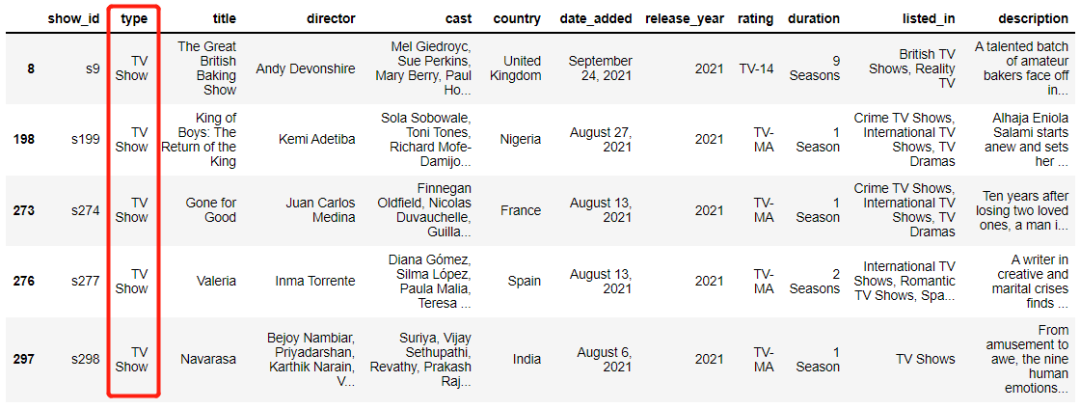
.loc方法来相结合,只挑选少数的几个指定的列名,代码如下df.loc[mask, ['title','country','duration']].head()
output
title country duration
1 Blood & Water South Africa 2 Seasons
2 Ganglands NaN 1 Season
3 Jailbirds New Orleans NaN 1 Season
4 Kota Factory India 2 Seasons
5 Midnight Mass NaN 1 Season
mask = df['type'].isin(['Movie','TV Show'])
True,要是文本内容全部都匹配,要是出现一个不匹配的现象则返回的是False根据关键字来筛选
listed-in包含的是每部电影的种类,当然很多电影并不只有一个种类,而是同时涉及到很多个种类,例如某一部电影既有“科幻”元素,也有“爱情”元素同时还包含了部分“动作片”的元素。mask = df['listed_in'].str.contains('horror', case=False, na=False)
case=False表明的是忽略字母的大小写问题,na=False表明的是对于缺失值返回的是False,df[mask].head()
output

+、^以及=等符号时,我们可以将regex参数设置成False(默认的是True),这样就不会被当做是正则表达式的符号,代码如下df['a'].str.contains('^', regex=False)
#或者是
df['a'].str.contains('\^')
根据多个关键字来筛选
当关键字不仅仅只有一个的时候,就可以这么来操作
pattern = 'horror|stand-up'
mask = df['listed_in'].str.contains(pattern, case=False, na=False)
df[mask].sample(5)
output

|来表示“或”的意思,将电影类别包含“horror”或者是“stand-up”这两类的电影筛选出来除此之外,我们还可以这么来做
mask1 = df['listed_in'].str.contains("horror", case=False)
mask2 = df['listed_in'].str.contains("stand-up", case=False)
df[mask1 | mask2].sample(5)
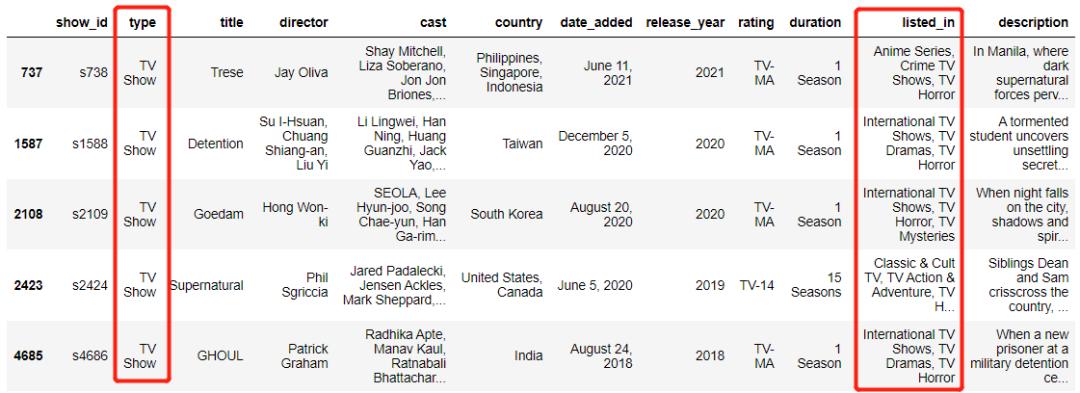
|表示的是“或”之外,也有表示的是和,也就是&标识符,意味着条件全部都需要满足即可,例如mask1 = (df['listed_in'].str.contains('horror', case=False, na=False))
mask2 = (df['type'].isin(['TV Show']))
df[mask1 & mask2].head(3)
output
我们可以添加多个条件在其中,多个条件同时满足,例如
mask1 = df['rating'].str.contains('tv', case=False, na=False)
mask2 = df['listed_in'].str.contains('tv', case=False, na=False)
mask3 = df['type'].str.contains('tv', case=False, na=False)
df[mask1 & mask2 & mask3].head()
output

正则表达式在pandas筛选数据中的应用
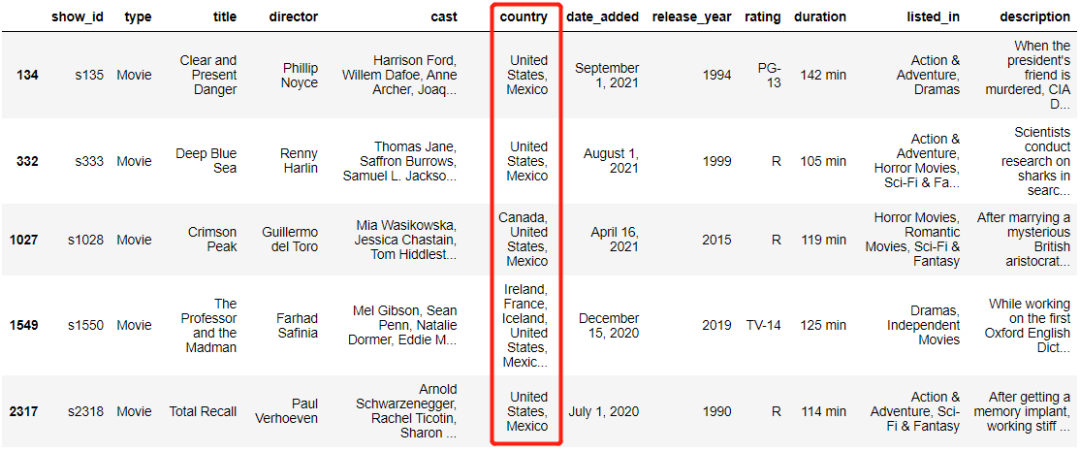
str.contains('str1.*str2')代表的是文本数据是否以上面的顺序呈现,pattern = 'states.*mexico'
mask = data['country'].str.contains(pattern, case=False, na=False)
data[mask].head()
output
.*在正则表达式当中表示匹配除换行符之外的所有字符,我们需要筛选出来包含states以及mexico结尾的文本数据,我们再来看下面的例子pattern = 'states.*mexico|mexico.*states'
mask = data['country'].str.contains(pattern, case=False, na=False)
data[mask].head()
output

lambda方法来筛选文本数据中的应用
lambda方法的介入,例如cols_to_check = ['rating','listed_in','type']
pattern = 'tv'
mask = data[cols_to_check].apply(
lambda col:col.str.contains(
pattern, na=False, case=False)).all(axis=1)
rating、listed_in以及type这三列当中筛选出包含tv的数据,我们来看一下结果如何df[mask].head()
output

我们再来看下面的这个例子,
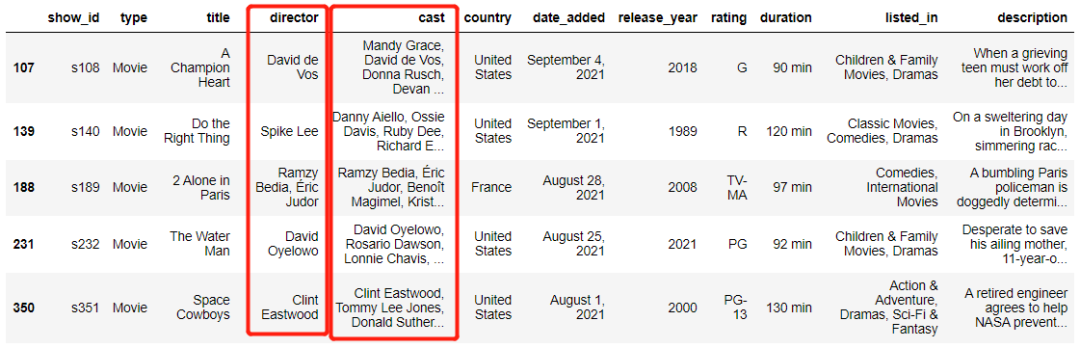
mask = df.apply(
lambda x: str(x['director']) in str(x['cast']),
axis=1)
director这一列是否被包含在了cast这一列当中,结果如下df[mask].head()
output
filter方法
filter方法来筛选文本的数据,例如筛选出列名包含in的数据,代码如下df.filter(like='in', axis=1).head(5)
output

当然我们也可以用.loc方法来实现,代码如下
df.loc[:, df.columns.str.contains('in')]
出来的结果和上述的一样
axis改成0,就意味着是针对行方向的,例如筛选出行索引中包含Love的影片,代码如下df_1 = df.set_index('title')
df_1.filter(like='Love', axis=0).head(5)
output

当然我们也可以通过.loc方法来实现,代码如下
df_1.loc[df_1.index.str.contains('Love'), :].head()
筛选文本数据的其他方法
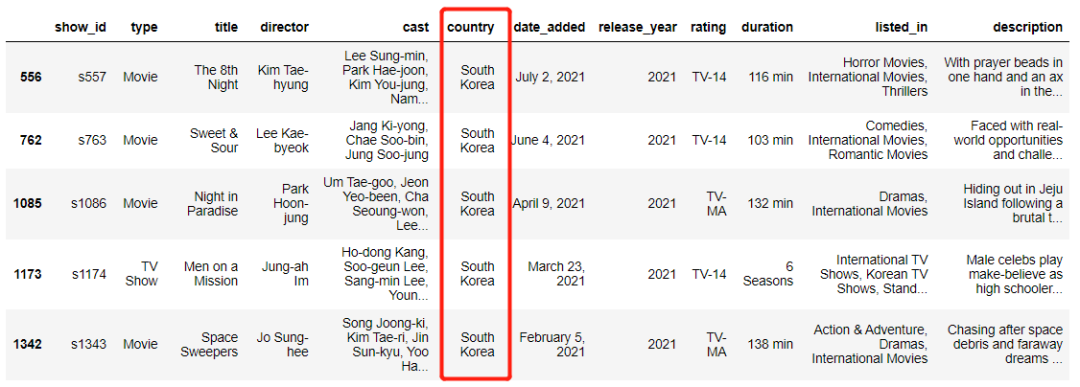
我们可以使用query方法,例如我们筛选出国家是韩国的影片
df.query('country == "South Korea"').head(5)
output
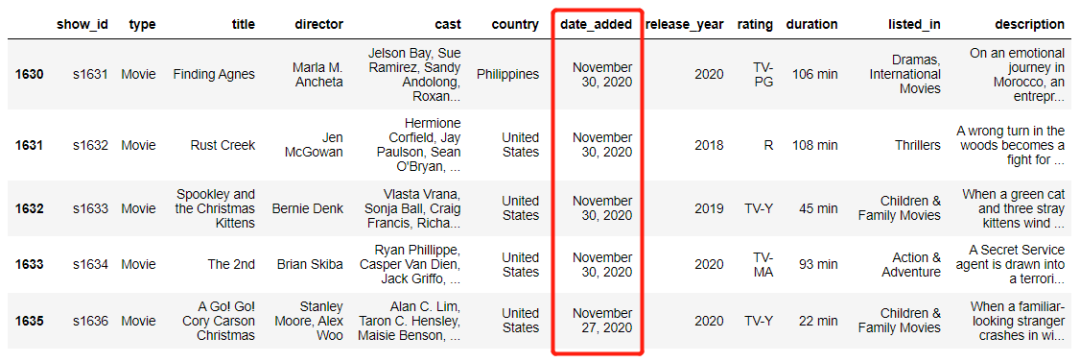
例如筛选出影片的添加时间是11月的,代码如下
mask = df["date_added"].str.startswith("Nov")
df[mask].head()
output
那既然用到了startswith方法,那么就会有endswith方法,例如
df['col_name'].str.endswith('2019')
除此之外还有这些方法可以用来筛选文本数据
df['col_name'].str.len()>10df['col_name'].str.isnumeric()df[col_name].str.isupper()df[col_name].str.islower()
本文为转载分享&推荐阅读,若侵权请联系后台删除
对比Excel系列图书累积销量达15w册,让你轻松掌握数据分析技能,可以在全网搜索书名进行了解:

评论